1.本发明涉及音域检测技术领域,具体涉及一种基于音频特征的最适歌唱音域检测方法。
背景技术:
2.歌手在演唱不同音高的音符时,其最高演唱音高与最低演唱音高之间的范围被称为音域,在演唱时,不同的音表现出不同的演唱质量,如演唱音域中段的音时,歌手的演唱气息充沛,音色饱满,表现的游刃有余;在演唱靠近音域两端的音时,发声开始变得不稳定;当到达音域边界时,会出现破音的现象,这一现象与歌手在不同频段发声时的声带、共鸣腔状况有关。
3.现有的技术文献[1][2][3][4]在进行音域研究时(其中,[1]y.yu,w.lin,d.y.huanget al.performance scoring of singing voice.ieee international conference on asian language processing,2016,pp.119
‑
122;[2]c.gupta,h.li,y.wang.perceptual evaluation of singing quality.asia
‑
pacific signal and information processing association,2017;[3]n.siupsinskiene,h.lycke.effects of vocal training on singing and speaking voice characteristics in vocally healthy adults and children based on choral and nonchoral data.journal of voice,2011,vol.25,no.4,pp.177
‑
189;[4]c.gupta,h.li,y.wang.a technical framework for automatic perceptual evaluation of singing quality.apsipa transactions on signal and information processing,2018),只关注与音高有关的信息,即记录歌手所能发出的最高频率与最低频率,而不在意音符级别的发声质量,在音域评价任务中,现有方法只关注歌唱者极限能达到的音高频率范围,但人类专家再进行音域判断时,会综合判断各音区发声质量,如气息是否稳定、音色是否饱满等,进行最适音域检测,比起极限音域检测(文献[1][2][4]采用极值音域法,即通过提取基频极高值点与极低值点作为歌唱人音域特征,计算待测人的两个极值点分别与原唱的极值点的距离作为音域差异度量),最适音域检测更能描述歌唱者的歌唱能力,从而为歌唱训练、歌曲推荐给出更有意义的参考,为此,我们提出最适歌唱音域检测算法。
技术实现要素:
[0004]
为了解决上述问题,本发明将综合音高、能量、音色特征,试验不同机器学习方法的分类效果,提出一种基于音频特征的最适歌唱音域检测方法,这种方法对于歌唱者在音域中演唱的每个音符进行质量判断,克服了以往极限音域法的缺陷。
[0005]
为了实现上述技术目的,本发明采用如下技术方案:
[0006]
一种基于音频特征的最适歌唱音域检测方法,其检测方法包括以下步骤:
[0007]
a、构建歌声数据库:录制演唱者跟随钢琴伴奏的清唱音阶数据,进行有声片段检测,去除空白部分,形成歌唱片段;
[0008]
b、对歌唱片段进行音符级别音域与发声质量的等级标注:
[0009]
c、提取歌唱片段的经典音频特征和深度音频特征;
[0010]
d、训练最适音域检测模型:使用步骤(a)中所述的演唱者歌声数据集训练机器学习分类模型,通过输入的经典音频特征和深度音频特征对音符级别内的音频进行音域合适度的分类;
[0011]
e、通过对上述音阶内各音符分类结果的计算,检测并判断演唱者的最适歌唱音域。
[0012]
优选地,所述步骤(a)中,录制清唱音阶数据时,采用16bit量化、44.1khz采样、wav格式记录音频文件,要求演唱者先从中音区开始,跟随钢琴演奏的半音阶向高音区逐个演唱长音,至自身最高音高极限,然后再跟随钢琴演奏的半音阶,向下演唱至最低音高极限。
[0013]
优选地,所述步骤(b)具体为,将歌声数据库中的半音阶演唱数据分割为音符级别片段,每个音的长度在0.5
‑
1.2s之间;对每个音符级别片段进行标注,标注“音域合适发声质量好”为类别代码2、“音域不合适发声质量一般”为类别代码1、“音域不合适破音”为类别代码0。
[0014]
优选地,所述经典音频特征分为音高、能量、音色三类,总计包含134维特征;其中音高特征2维,包括音高数组的标准差与基频抖动率;能量特征3维,包括短时幅度均值、标准差与振幅扰动度;音色特征129维,包括谱特征:spr、谱质心,声道特征:lpc、lpcc,人耳感知类特征:mfcc、
△
mfcc、plp,在每个音频提取6种音色特征后,除计算均值外,还计算其每一维的标准差,共得到129维音色特征。
[0015]
优选地,所述深度音频特征是采用五层卷积神经网络产生的5*32=160维深度音频特征连接构成。
[0016]
所述步骤(e)中,将划分为“音域合适发声质量好”类别音符的音高边界作为歌手的最适音域,通过下边公式将检测出的音高频率转换为midi音高键号,
[0017]
midi_semitone=(log2pitch
‑
log2440)
×
12+81
[0018]
其中,pitch代表音高频率,midi_semitone的含义为,以440hz标准音高a4的键号记为81,每高半音键号加一,每低半音键号减一。
[0019]
本发明的技术效果:
[0020]
1、在音域检测任务中,不宜简单采用极限音高频率范围进行度量;本发明综合判断各音符级别音区的发声质量,如气息是否稳定、音色是否饱满等因素,进行最适音域检测;
[0021]
2、本发明使用音频片段的134维包含音高、能量、音色特征的经典音频特征集与160维深度音频特征集来表征音区内音符的发声质量,从而进行音域是否合适的判断;
[0022]
3、本发明以音符为级别,通过提取歌唱片段的经典音频特征和深度音频特征,使用机器学习分类方法对该音符内的音域合适程度进行判断,通过对音阶内各音符分类结果的计算,判断用户的合适音域;
[0023]
综上所述,本发明与极限音域检测方法相比,最适音域检测法更接近人类描述歌唱者歌唱能力的方式,从而为歌唱训练、歌曲推荐给出更有意义的参考。
附图说明
[0024]
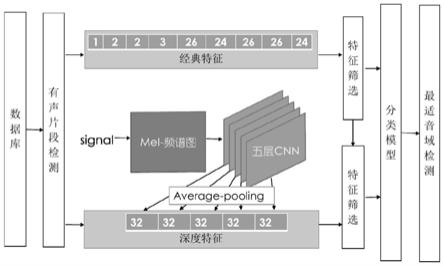
图1是本发明的方法示意图。
[0025]
图2是本发明提取深度音频特征使用的cnn网络结构。
具体实施方式
[0026]
下面结合附图,对本发明做进一步说明。
[0027]
一种基于音频特征的最适歌唱音域检测方法,如图1所示,其检测方法包括以下步骤:
[0028]
a、构建歌声数据库:在专业录音棚中录制歌手不含其它乐器伴奏的清唱音阶数据,采用16bit量化、44.1khz采样、wav格式记录音频文件;录制要求演唱者从中音区开始,跟随钢琴演奏的半音阶向高音区逐个演唱长音,至自身最高音高极限,再跟随钢琴演奏的半音阶,向下演唱至最低音高极限。为保证“音域不合适发声质量一般”与“音域不合适破音”类数据相对平衡,每个演唱者被要求再次在高音区与低音区进行一次半音阶演唱,接着进行有声片段检测,去除空白部分,形成歌唱片段。
[0029]
b、对歌唱片段进行音符级别音域与发声质量的等级标注:将上述歌声数据库中半音阶演唱数据分割为音符级别片段,每个音的长度在0.5
‑
1.2s之间。由音乐专业本科以上资历人类专家对每个片段进行标注,标签为“音域合适发声质量好”(类别代码2)、“音域不合适发声质量一般”(类别代码1)与“音域不合适破音”(类别代码0)共三类。
[0030]
c、提取歌唱片段的经典音频特征和深度音频特征:
[0031]
在进行最适音域检测任务中,使用的经典音频特征分为音高、能量、音色三类,总计包含134维特征。其中音高特征2维(音高数组的标准差与基频抖动率);能量特征3维(短时幅度均值、标准差与振幅扰动度);音色特征129维(谱特征:spr、谱质心,声道特征:lpc、lpcc,人耳感知类特征:mfcc、
△
mfcc、plp。在每个音频提取6种音色特征后,除计算均值外,还计算其每一维的标准差,共得到129维音色特征)。其中,
[0032]
spr(singing power ratio):歌唱功率比。spr的意义为2
‑
4khz内最高的频谱峰与0
‑
2khz内最高频谱峰之比,主要用于衡量歌手共振峰的突出程度。计算公式为:
[0033][0034]
sc(spectral centroid):谱质心。谱密度函数的中点,即频率成分的重心。单位为hz。
[0035]
lpc(linear predictive coding):线性预测编码。
[0036]
lpcc(linear predictive cepstral coefficient):线性预测倒谱系数。
[0037]
mfcc(mel
‑
frequency cepstral coefficient):,梅尔频率倒谱系数。
[0038]
mfcc_delta:
△
mfcc,在计算出一段音频的mfcc后,沿时间方向对mfcc向量进行局部求导。
[0039]
plp(perceptual linear predictive):感知线性预测系数。
[0040]
表1.经典音频特征
[0041]
特spr谱质心音高特能量特征lpclpccmfcc
△
mfccplp维12232624262624
[0042]
本发明采用文献[5](k.choi,g.fazekas,m.sandler et al.transfer learning for music classification and regression tasks.2017.)中提出的用于音乐内容标注任务的卷积神经网络cnn(convolutional neural network)提取深度音频特征来表征音色,如图2所示。
[0043]
文献[5]在百万歌曲数据集msd(million song dataset)(包含244,224首音频片段)上训练音乐信息标注任务。此任务需要将音频分类到50个标签上,标签内容包括音乐流派、年代、乐器、情绪。其使用的网络为5层cnn结构,使用二维3*3的卷积核对每层信息进行二维卷积。网络输入为整段音频,以音频的梅尔频谱图片输入五层卷积网络,通道数为32。在第一至四层卷积完成后,每层网络输出通过平均池化下采样至32维特征,第五层卷积后特征保留其32维不变。浅层特征偏向于表示音频音高、共振峰、时域变化等基础音频信息,越深层产生的特征抽象度越高,与原音乐信息标注任务相关度也越高。
[0044]
本发明将该五层卷积神经网络产生的5*32=160维深度音频特征连接作为深度音频特征。
[0045]
表格2.深度音频特征
[0046]
深度音频特征第一层第二层第三层第四层第五层维数3232323232
[0047]
d、训练最适音域检测模型:使用步骤(a)中所述的演唱者歌声数据集训练机器学习分类模型,如adaboost(自适应提升方法,是机器学习方法中一种分类模型),通过输入的经典音频特征和深度音频特征对音符级别内的音频进行音域合适度的分类,得到最适音域检测模型。类别包括“音域合适发声质量好”(类别代码2)、“音域不合适发声质量一般”(类别代码1)与“音域不合适破音”(类别代码0)三类。
[0048]
e、通过对上述音阶内各音符分类结果的计算,检测并判断演唱者的最适歌唱音域。
[0049]
本发明将划分为“音域合适发声质量好”类别音符的音高边界作为歌手的最适音域,通过下边公式将检测出的音高频率转换为midi音高键号,
[0050]
midi_semitone=(log2pitch
‑
log2440)
×
12+81
[0051]
其中,pitch代表音高频率。midi_semitone的含义为,以440hz标准音高a4的键号记为81,每高半音键号加一,每低半音键号减一。