1.本发明属于信息处理的领域,具体涉及一种基于语音频谱域稀疏性约束的在线语音分离方法和装置。
背景技术:
2.基于麦克风阵列作为语音信号采集设备的在线会议系统得到了越来越充分的应用。实际使用中,会议室存在显著的噪声、混响等因素会降低语音质量,进一步降低在线会议的听感。基于麦克风阵列多阵元进行波束生成是降低信号噪声、提高通讯质量最常用的方法。更进一步,在会议通话时,常存在多个说话人同时说话,如何有选择性的提取某一个人的声音,可以进一步降低竞争说话人的干扰,提升会议质量。更进一步,在自动会议纪要生成等应用技术中,提取一个目标说话人声音对提升语音识别率、会议纪要的准确率更为重要。
3.基于独立矢量分析(independent vector analysis,iva)是目前最常用的盲源分离技术。该项技术,首先把所有阵元拾取的时域信号通过短时傅里叶变化转化到时频域,随后基于分离语音互熵最小的原则构建优化函数,基于该优化函数迭代更新分离矩阵,估计出分离矩阵之后,可以得到目标信号的频域估计,最后基于傅里叶逆变换得到时域估计。
4.现有技术的主要缺点如下:
5.1)基于互熵最小原则优化函数,需要缓冲很长一段时间信号才能保证互熵计算的准确性,因此现有iva技术延时较大,无法保证实时通讯。
6.2)现有iva技术需要首先做预白化处理,以保证所有频带可以均等的参与分离矩阵的更新,而预白化技术也需要缓冲一段时间数据,无法保证实时性。。
7.有鉴于此,特提出本发明。
技术实现要素:
8.本发明的目的是提供一种基于语音频谱域稀疏性约束的在线语音分离方法和装置,其基于语音信号在频谱域的稀疏性的特点,设计了新的优化函数,不需要预白化处理,可以保证会议通讯的实时性。
9.为了实现上述目的,本发明提供的一种基于语音频谱域稀疏性约束的在线语音分离方法,应用于基于麦克风阵列的系统,包括以下步骤:
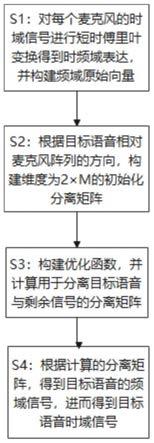
10.s1:对每个麦克风的时域信号进行短时傅里叶变换得到时频域表达,并构建频域原始向量;
11.s2:根据目标语音相对麦克风阵列的方向,构建维度为2
×
m的初始化分离矩阵;
12.s3:构建优化函数,并计算用于分离目标语音与剩余信号的分离矩阵;
13.s4:根据计算的分离矩阵,得到目标语音的频域信号,进而得到目标语音时域信号。
14.进一步地,所述步骤s1之前还包括:获取每个麦克风的时域信号x
m
(n);
15.所述步骤s1包括:
16.对时域信号x
m
(n)进行短时傅里叶变换得到时频域表达:
[0017][0018]
对每一个频带k,构建一个频域原始向量x(l,k):
[0019]
x(l,k)=[x1(l,k),x2(l,k),
…
,x
m
(l,k)]
t
。
[0020]
进一步地,所述步骤s2中,初始化的分离矩阵为:
[0021][0022]
其中,目标语音分离矩阵初始化为:
[0023][0024][0025]
q(θ)=[cos(θ),sin(θ)]:
[0026]
剩余信号分离矩阵初始化为0向量:
[0027]
g2(0,k)=[0,0,....,0]。
[0028]
进一步地,所述步骤s3包括:
[0029]
s301:构建新的优化函数j(g(k)):
[0030][0031]
y1(l,k)=g1(k)x(l,k),y2(l,k)=g2(k)x(l,k)
[0032]
其中,y1(l,k)和y2(l,k)分别代表基于分离矩阵得到目标语音和剩余信号频域估计;
[0033]
s302:计算优化函数的梯度向量:
[0034][0035][0036]
s303:根据上一帧分离矩阵和梯度下降法更新分离矩阵:
[0037]
g1(l,k)=g1(l
‑
1,k)
‑
εδ(g1(k))
[0038]
g2(l,k)=g2(l
‑
1,k)
‑
εδ(g2(k))
[0039]
其中,g1(l,k)和g2(l,k)分别为用于分离目标语音与剩余信号的分离矩阵。
[0040]
更进一步地,所述步骤s4包括:
[0041]
s401:根据求解得到的分离矩阵,得到目标语音的频域估计:
[0042][0043]
s402:对频域估计进行傅里叶逆变换得到目标语音的时域信号:
[0044][0045]
本发明还提供了一种基于语音频谱域稀疏性约束的在线语音分离装置,应用于基于麦克风阵列的系统,包括初始化模块、信号分解模块、分离滤波器计算模块和目标语音估计模块:
[0046]
初始化模块用于对每个麦克风的时域信号进行短时傅里叶变换得到时频域表达,并构建频域原始向量;
[0047]
信号分解模块用于根据目标语音相对麦克风阵列的方向,构建维度为 2
×
m的初始化分离矩阵;
[0048]
分离滤波器计算模块用于构建优化函数,并计算用于分离目标语音与剩余信号的分离矩阵;
[0049]
目标语音估计模块用于根据计算的分离矩阵,得到目标语音的频域信号,进而得到目标语音时域信号。
[0050]
进一步地,所述初始化模块还用于获取每个麦克风的时域信号x
m
(n);
[0051]
所述信号分解模块用于对时域信号x
m
(n)进行短时傅里叶变换得到时频域表达:
[0052][0053]
对每一个频带k,构建一个频域原始向量x(l,k):
[0054]
x(l,k)=[x1(l,k),x2(l,k),
…
,x
m
(l,k)]
t
。
[0055]
进一步地,所述信号分解模块中,初始化的分离矩阵为:
[0056][0057]
其中,目标语音分离矩阵初始化为:
[0058][0059][0060]
q(θ)=[cos(θ),sin(θ)];
[0061]
剩余信号分离矩阵初始化为0向量:
[0062]
g2(0,k)=[0,0,....,0]。
[0063]
进一步地,所述分离滤波器计算模块的操作步骤如下:
[0064]
首先,构建新的优化函数j(g(k)):
[0065][0066]
y1(l,k)=g1(k)x(l,k),y2(l,k)=g2(k)x(l,k)
[0067]
其中,y1(l,k)和y2(l,k)分别代表基于分离矩阵得到目标语音和剩余信号频域估计;
[0068]
其次,计算优化函数的梯度向量:
[0069][0070][0071]
最后,根据上一帧分离矩阵和梯度下降法更新分离矩阵:
[0072]
g1(l,k)=g1(l
‑
1,k)
‑
εδ(g1(k))
[0073]
g2(l,k)=g2(l
‑
1,k)
‑
εδ(g2(k))
[0074]
其中,g1(l,k)和g2(l,k)分别为用于分离目标语音与剩余信号的分离矩阵。
[0075]
更进一步地,所述语音估计模块的操作步骤如下:
[0076]
首先,根据求解得到的分离矩阵,得到目标语音的频域估计:
[0077][0078]
其次,对频域估计进行傅里叶逆变换得到目标语音的时域信号:
[0079][0080]
本发明提供的一种基于语音频谱域稀疏性约束的在线语音分离方法和装置,具有如下有益效果:
[0081]
1、相比于传统iva,本发明基于稀疏性约束优化目标函数,不需要预白化处理,因此不需要缓冲一段时间数据,可以支持实时通讯需求。
[0082]
2、本发明所采用的目标函数,符合语音信号稀疏性假设,分离语音包含更少的噪音与竞争说话人的声音,可以显著提升语音通讯质量。
附图说明
[0083]
图1为本具体实施方式中的基于语音频谱域稀疏性约束的在线语音分离方法的流程图。
[0084]
图2为本具体实施方式中的使用的汉明窗函数的示意图。
[0085]
图3为本具体实施方式中的基于语音频谱域稀疏性约束的在线语音分离装置的示意图。
具体实施方式
[0086]
为了使本技术领域的人员更好地理解本发明方案,下面结合具体实施方式对本发明作进一步的详细说明。
[0087]
如图1所示,本发明的一实施方式为一种基于语音频谱域稀疏性约束的在线语音分离方法,其能够应用于麦克风阵列的语音会议系统,可以实时提取某个方向的语音信号,有助于提升会议语音通讯质量,也可以和语音识别技术结合以自动记录会议纪要。
[0088]
具体包括以下四个实施步骤:
[0089]
s1:对每个麦克风的时域信号进行短时傅里叶变换得到时频域表达,并构建频域原始向量。
[0090]
在步骤s1之前,还包括获取每个麦克风的语音信号,获取的语音信号如下:假设x
m
(n)代表m个麦克风阵元实时拾取的原始时域信号,其中,m代表麦克风序号标签,其取值从1到m,n代表时间标签。
[0091]
具体地,进行短时傅里叶变换的方法如下:
[0092]
对时域信号x
m
(n)进行短时傅里叶变换得到时频域表达:
[0093][0094]
其中,n为帧长,n=512;w(n)为长度512的汉明窗,其中,n代表时间上的序号,因此w(n)代表每一个对应时间序号n上的值;1为时间帧序号,以帧为单位;k为频带序号,其中,频带是指某个频率对应的信号分量;j代表虚数单位x
m
(l,k)为第m个麦克风信号,在第1帧,第k个频带的频谱。本发明中,使用的汉明窗函数如图2所示。
[0095]
构建频域原始向量的方法如下:
[0096]
对每一个频带k,构建一个频域原始向量x(l,k):
[0097]
x(l,k)=[x1(l,k),x2(l,k),
…
,x
m
(l,k)]
t
[0098]
其中,上标t代表转置运算符,可见该原始向量为m维度列向量。
[0099]
通过上述步骤s1,能够完成时域信号到时频域的变换。
[0100]
s2:根据目标语音相对麦克风阵列的方向,构建维度为2
×
m的初始化分离矩阵。
[0101]
其中,目标语音相对麦克风阵列的方向为θ,目标语音是指对应目标方向的语音信号,对于语音分离任务而言,目标方向通常根据实际应用作为先验信息,是根据所提取的信号提前知晓的,比如对于大屏语音通讯设备,希望分离的是90度方位的语音信号。
[0102]
因此,初始化分离矩阵为:
[0103][0104]
其中,为了提取目标方向的语音,目标语音分离矩阵初始化为:
[0105][0106][0107]
q(θ)=[cos(θ),sin(θ)]
[0108]
其中,f
k
为第k个频带的频率,k=1,2,...k,其中k的取值是根据后续傅里叶变换来确定,如果帧长为512,那么k的取值为帧长的一半;c为声速, c=340m/s;d
m
为第m个麦克风的二维坐标值;q(θ)为方向矢量,ω
k
为频带圆频率。
[0109]
为了提取剩余信号,剩余信号分离矩阵初始化为0向量:
[0110]
g2(0,k)=[0,0,....,0]
[0111]
通过上述步骤s2,能够完成分离矩阵的初始化。
[0112]
s3:构建优化函数,并计算用于分离目标语音与剩余信号的分离矩阵。
[0113]
具体的,本步骤s3包括以下步骤:
[0114]
s301:构建新的优化函数j(g(k)):
[0115][0116]
y1(l,k)=g1(k)x(l,k),y2(l,k)=g2(k)x(l,k)
[0117]
其中,α为权重因子,|.|代表取一个复数的模,上标*代表取复数的共轭。 y1(l,k)和y2(l,k)分别代表基于分离矩阵得到目标语音和剩余信号的频域估计。其中,g1(0,k)和g2(0,k)分别代表g1(k)和g2(k)的初始值。
[0118]
在上述优化函数公式中,函数的第一项约束了分离出的两路信号之和与 x1(l,k)尽可能接近,第二项约束分离信号y1(l,k)和y2(l,k)的相关性尽可能小。即该优化函数的原理是在y1(l,k)和y2(l,k)相关性尽可能小的同时也需要保证,y1(l,k)与y2(l,k)之和与x1(l,k)的差异尽可能的小。
[0119]
其中,剩余信号是相对于y1(l,k)、y2(l,k)和x1(l,k)而言。如前所述,优化函数j(g(k))中做了约束让y1(l,k)与y2(l,k)之和与x1(l,k)的差异尽可能小,即从x1(l,k)中分离出y1(l,k)和y2(l,k)。y1(l,k)代表目标语音,y2(l,k)则是从 x1(l,k)中分离出y1(l,k)之后的剩余信号。剩余信号与背景信号并不相同,背景信号是指声源之外的背景噪声信号。
[0120]
该优化函数j(g(k))中的第一项保证了分离出两路信号尽可能与麦克风录制信号相等,第二项约束了输出两路信号尽可能稀疏。
[0121]
权重因子α的值越大,代表稀疏性的约束越强,让分离语音更加稀疏,但是会导致分离两个信号和麦克风原始信号的不一致变高。本发明中,推荐参考值为1到10之间,优选的,本发明采用α=3,优选该阈值,会达到信号一致性与分离有效性的平衡。
[0122]
s302:计算优化函数的梯度向量:
[0123][0124][0125]
由于步骤s301中的优化函数无解析解,采用步骤s302来计算梯度向量,进而可以逐步实现优化函数的求解,分离效果更符合稀疏性约束。其中, g(0,k)代表g(k)的初始化。
[0126]
s303:根据上一帧分离矩阵和梯度下降法更新分离矩阵:
[0127]
g1(l,k)=g1(l
‑
1,k)
‑
εδ(g1(k))
[0128]
g2(l,k)=g2(l
‑
1,k)
‑
εδ(g2(k))
[0129]
其中,g1(l,k)和g2(l,k)分别为用于分离目标语音与剩余信号的分离矩阵;∈代表每一次更新的步长,取值范围参考为0.05到0.2之间。
[0130]
优选的,本发明中,步长取值为∈=0.1。如果步长过大,会带来更新的不稳定(鲁棒性差),如果步长过小,收敛速度会变慢;本发明优选0.1作为步长,可以达到在收敛速度
和鲁棒性之间较好的平衡。
[0131]
在公式中,目标语音分离矩阵初始化为g1(0,k),第一帧的目标语音的分离矩阵为g1(1,k),即可以从g1(0,k)更新,第二帧从第一帧更新,以此类推,得到目标语音的分离矩阵g1(l,k)。剩余信号的分离矩阵的计算过程同上。
[0132]
通过上述步骤,能够实现分离矩阵的优化与求解,可以直接用于下一步骤提取目标语音频谱和时域信号。
[0133]
s4:根据计算的分离矩阵,得到目标语音的频域信号,进而得到目标语音时域信号。
[0134]
具体包括以下步骤:
[0135]
s401:根据求解得到的分离矩阵,得到目标语音的频域估计:
[0136][0137]
s402:对频域估计进行傅里叶逆变换得到目标语音的时域信号:
[0138][0139]
通过该步骤s4,能够实现目标语音的时域信号的获取。
[0140]
通过本发明的上述步骤s1
‑
s4,可以实现麦克风矩阵信号的初始化、信号分解、分离矩阵更新和目标语音估计,最终提取目标语音。
[0141]
如图3所示,本发明的一实施方式为一种基于语音频谱域稀疏性约束的在线语音分离装置,应用于基于麦克风阵列的系统,其包括初始化模块1、信号分解模块2、分离滤波器计算模块3和目标语音估计模块4。
[0142]
初始化模块1,用于对每个麦克风的时域信号进行短时傅里叶变换得到时频域表达,并构建频域原始向量。
[0143]
初始化模块1还能够用于获取每个麦克风的语音信号,获取的语音信号如下:假设x
m
(n)代表m个麦克风阵元实时拾取的原始时域信号,其中,m代表麦克风序号标签,其取值从1到m,n代表时间标签。
[0144]
具体地,进行短时傅里叶变换的方法如下:
[0145]
对时域信号x
m
(n)进行短时傅里叶变换得到时频域表达:
[0146][0147]
其中,n为帧长,n=512;w(n)为长度512的汉明窗,其中,n代表时间上的序号,因此w(n)代表每一个对应时间序号n上的值;l为时间帧序号,以帧为单位;k为频带序号,其中,频带是指某个频率对应的信号分量;j代表虚数单位x
m
(l,k)为第m个麦克风信号,在第l帧,第k个频带的频谱。本发明中,使用的汉明窗函数如图2所示。
[0148]
构建频域原始向量的方法如下:
[0149]
对每一个频带k,构建一个频域原始向量x(l,k):
[0150]
x(l,k)=[x1(l,k),x2(l,k),
…
,x
m
(l,k)]
t
[0151]
其中,上标t代表转置运算符,可见该原始向量为m维度列向量。
[0152]
通过初始化模块1,能够完成时域信号到时频域的变换。
[0153]
信号分解模块2,用于根据目标语音相对麦克风阵列的方向,构建维度为 2
×
m的
初始化分离矩阵。
[0154]
其中,目标语音相对麦克风阵列的方向为θ,目标语音是指对应目标方向的语音信号,对于语音分离任务而言,目标方向通常根据实际应用作为先验信息,是根据所提取的信号提前知晓的,比如对于大屏语音通讯设备,希望分离的是90度方位的语音信号。
[0155]
因此,初始化分离矩阵为:
[0156][0157]
其中,为了提取目标方向的语音,g1初始化为:
[0158][0159][0160]
q(θ)=[cos(θ),sin(θ)]
[0161]
其中,f
k
为第k个频带的频率,k=1,2,...k,其中k的取值是根据后续傅里叶变换来确定,如果帧长为512,那么k的取值为帧长的一半;c为声速, c=340m/s;d
m
为第m个麦克风的二维坐标值;q(θ)为方向矢量,ω
k
为频带圆频率。
[0162]
为了提取剩余信号,g2初始化为0向量:
[0163]
g2(0,k)=[0,0,....,0]
[0164]
通过信号分解模块2,能够完成分离矩阵的初始化。
[0165]
分离矩阵计算模块3用于构建优化函数,并计算用于分离目标语音与剩余信号的分离矩阵。
[0166]
具体地,分离滤波器计算模块3的操作步骤如下:
[0167]
首先,构建新的优化函数j(g(k)):
[0168][0169]
y1(l,k)=g1(k)x(l,k),y2(l,k)=g2(k)x(l,k)
[0170]
其中,α为权重因子,|.|代表取一个复数的模,上标*代表取复数的共轭。 y1(l,k)和y2(l,k)分别代表基于分离矩阵得到目标语音和剩余信号频域估计。其中,g1(0,k)和g2(0,k)分别代表g1(k)和g2(k)的初始值。
[0171]
该优化函数j(g(k))中的第一项保证了分离出两路信号尽可能与麦克风录制信号相等,第二项约束了输出两路信号尽可能稀疏。
[0172]
权重因子α的值越大,代表稀疏性的约束越强,让分离语音更加稀疏,但是会导致分离两个信号和麦克风原始信号的不一致变高。本发明中,推荐参考值为1到10之间,优选的,本发明采用α=3,优选该阈值,会达到信号一致性与分离有效性的平衡。
[0173]
其次,计算优化函数的梯度向量:
[0174]
[0175][0176]
由于构建的优化函数无解析解,采用上述方法来计算梯度向量,进而可以逐步实现优化函数的求解,分离效果更符合稀疏性约束。
[0177]
最后,根据上一帧分离矩阵和梯度下降法更新分离矩阵:
[0178]
g1(l,k)=g1(l
‑
1,k)
‑
εδ(g1(k))
[0179]
g2(l,k)=g2(l
‑
1,k)
‑
εδ(g2(k))
[0180]
其中,g1(l,k)和g2(l,k)分别为用于分离目标语音与剩余信号的分离矩阵;∈代表每一次更新的步长,取值范围参考为0.05到0.2之间。
[0181]
优选的,本发明中,步长取值为∈=0.1。如果步长过大,会带来更新的不稳定(鲁棒性差),如果步长过小,收敛速度会变慢;本发明优选0.1作为步长,可以达到在收敛速度和鲁棒性之间较好的平衡。
[0182]
在公式中,目标语音分离矩阵初始化为g1(0,k),第一帧的目标语音的分离矩阵为g1(1,k),即可以从g1(0,k)更新,第二帧从第一帧更新,以此类推,得到目标语音的分离矩阵g1(l,k)。剩余信号的分离矩阵的计算过程同上。
[0183]
通过分离矩阵计算模块3,能够实现分离矩阵的优化与求解,可以直接用于下一步骤提取目标语音频谱和时域信号。
[0184]
目标语音估计模块4,用于根据计算的分离矩阵,得到目标语音的频域信号,进而得到目标语音时域信号。
[0185]
具体地,目标语音估计模块4的操作步骤如下:
[0186]
首先,据求解得到的分离矩阵,得到目标语音的频域估计:
[0187][0188]
其次,对频域估计进行傅里叶逆变换得到目标语音的时域信号:
[0189][0190]
通过目标语音估计模块4,能够实现目标语音的时域信号的获取。
[0191]
上述实施方式中,括初始化模块1、信号分解模块2、分离滤波器计算模块3和目标语音估计模块4的这4个模块缺一不可,任一模块的缺失,都会导致目标语音无法提取。
[0192]
本文中应用了具体个例对发明构思进行了详细阐述,以上实施例的说明只是用于帮助理解本发明的核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离该发明构思的前提下,所做的任何显而易见的修改、等同替换或其他改进,均应包含在本发明的保护范围之内。