一种基于深度神经网络的语音环境气氛识别方法
1.技术领域
2.本发明属于语言和语音识别领域。
背景技术:
3.语言和语音识别在各个领域已经被越来越广泛地被应用。
4.所谓气氛,是指在对话过程中,双方或多方共同感知的情感和心理特征。例如紧张、轻松、热情、冷漠。
5.在交流过程中,识别出对话过程中的整体气氛有助于提高服务质量。例如在多人语音会议中,当气氛紧张时,可以通过系统界面和背景音的调整来缓和气氛;在视频教学过程中,气氛过于轻松时,可以对老师进行提醒。
6.现有技术方案一般通过隐马尔可夫模型或神经网络方法对音频进行检测,发现一些特殊的语音符号,例如哭泣、大笑。或识别出发音者的情绪。
7.无论是采用神经网络方法还是隐马尔可夫模型,一般是针对单方甚至仅仅是单个语句进行情绪判断。而个人及单个语句的情绪不能表征整体对话气氛。
8.另外在多人同时说话时,常常出现混淆、误检测。
技术实现要素:
9.本发明基于语音识别和自然语言处理技术,识别不同说话人,感知语义情绪,设计了一种回归方法对整体对话气氛进行判断。
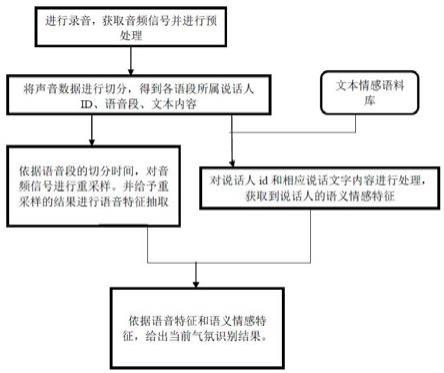
10.1.一种基于深度神经网络的语音环境气氛识别方法,其特征在于包括以下模块:模块1:获取音频信号并进行预处理;将音频信号进行预处理得到声音数据;包括预加重、分帧、短时傅里叶变换;模块2:将模块1输出的声音数据进行切分,得到各语段所属说话人id、语音段的起始时间和结束时间、文本内容;模块2的主体为一种深度神经网络,该深度神经网络具体参数通过训练获得;训练过程为:2.1 获取训练数据集,2.2 对训练数据中,说话人、文本内容进行分段标注;标注内容为每一段的开始时间、结束时间、说话人、说话内容的文本;2.3 采用梯度下降方式进行拟合使用过程中,将声音数据输入给训练好的深度神经网络模型,该模型给出对每个时间步的概率预测结果,即每个时间步所属说话人的概率分布、说话内容的概率分布;将声音数据的全部时间步输出综合起来,按照说话人的连续说话进行切分,生成各段起始截止时间,各段的说话人、各段的文本内容;
模块3:将模块2输出的语音段进行语音特征提取;依据语音段的切分时间,对原始音频信号进行重采样;并给予重采样的结果进行语音特征抽取;模块4:依据文本情感语料库,将模块2输出的各个说话人的文本内容编码为语义情感特征;模块4为具有记忆功能的时序神经网络,记忆有一定时序限度内的情感特征;对于每一个说话人进行单独运算;对最新文本内容进行分词,去停用词,依据文本情感语料库将词语转换为情感特征;将情感特征输入时序神经网络,并获取到最新的情感特征结果;模块5:依据模块3和模块4输出的语音特征和情感特征,进行气氛判断;气氛使用一个实数值来进行度量;实数取值范围为[0,1],0表示非常轻松,1表示非常紧张;模块5为一个卷积神经网络和时序循环神经网络相结合的深度神经网络,将语音特征和情感特征输入到模型中,通过卷积神经网络抽取深层次特征,再将抽取出来的特征输入到时序循环神经网络,输出对气氛的预测结果;在训练过程中通过这个数值和人工标记值的差距来进行梯度下降。
[0011]
2.进一步,文本情感语料库描述了在不同语境下,各个词汇具有的不同的情感特征及相应强度;情感分类采用parrott分类法,共115个类别;每个分类用长度为30的向量表示。
[0012]
3.进一步,在重采样时,采用4khz,每帧窗口为60ms;梅尔倒谱系数提取:梅尔倒谱系数为26维度:12维倒谱系数、12维倒谱系数差分、1维能量和1维能量差分;输出矩阵:因为每段最大长度为6秒,每帧窗口为60ms,所以最大帧数为100;故输出特征矩阵格式为 100 * 26 , 不足100帧的部分补0。
[0013]
4.进一步,对文本进行分词,去除掉停用词,对剩下的词在文本情感语本实施料库中进行查找;忽略不在语料库中的词;每段文字通常不超过30字;经过分词、去除停用词等操作后,有效词一般不超过20个,如果超过,则抛弃;将每个有效词查找到的向量进行堆叠,形成一个20*30的二维矩阵;不足20个词的补0。
[0014]
5.进一步,模块5中深度神经网络的描述整个网络结构包括a) 针对音频特征的卷积神经网络b) 针对文本情感特征的卷积神经网络 c) 时序循环神经网络5.1 针对音频特征的卷积神经网络音频特征的输入为100 x 26的矩阵, 卷积核需要与输入特征等宽;具体卷积核尺寸如下:;卷积核为: 5个1x26,5个2x26, 3个4x26, 3个8x26,3个16x26,1个32*26;所有卷积核padding为1,步长为1,卷积核个数为20个;对应k x 26的卷积核,输出尺寸为(100-k +1) x 1,
使用同尺寸的最大池化,变为标量;对全部20个卷积核输出的标量进行拼接,得到尺寸为1 x 20 的向量e1;此向量进行tanh激活层,结果为1 x 20 的向量e2;5.2 针对文本情感特征的卷积神经网络文本情感特征的输入为20 x 30的矩阵, 卷积核需要与输入特征等宽;具体卷积核尺寸如下:卷积核为: 5个1x30,5个2x30, 3个4x30, 3个8x30;所有卷积核padding为1,步长为1,卷积核个数为16个;对应j x 30的卷积核,输出尺寸为(20-j +1) x 1,使用同尺寸的最大池化,变为标量;对全部16个卷积核输出的标量进行拼接,得到尺寸为1 x 16 的向量f1;此向量进行tanh激活层,结果为1 x 16 的向量f2;5.3 联合音频特征和文本特征,计算气氛对上述向量e2、f2进行水平拼接,作为联合特征;采用时序循环神经网络即可。
[0015]
本发明的回归模型的均方误差低于0.01。
[0016]
本发明的创新之处在于:1 整体技术框架。对单个模块进行简单调整也属于保护范围2 在提取语义情感特征的过程中使用文本情感语料库3 联合语言特征和语义特征进行气氛识别4 本方案中包含了多个神经网络。这些神经网络可以分开单独训练,也可以进行联合训练,也可以部分联合训练。这些情况均在保护范围。
附图说明
[0017]
图1是本发明示意图图2是模块2功能图图3是模块3功能图图4是模块4功能图图5是模块5功能图。
具体实施方式
[0018]
1 模块1:获取音频信号并进行预处理。
[0019]
音频信号来源可以是现场录音,可以是其它方式获得的音频信号将音频信号进行处理得到声音数据。具体来说,包括预加重、分帧、短时傅里叶变换。
[0020]
2 模块2:将模块1输出的声音数据进行切分,得到各语段所属说话人、语音段的起始时间和结束时间、文本内容。
[0021]
参见“模块2功能图”模块2的主体为一种深度神经网络。该深度神经网络具体参数通过训练获得。
[0022]
训练过程为:2.1 获取训练数据集,
2.2 对训练数据中,说话人、文本内容进行分段标注。标注内容为每一段的开始时间、结束时间、说话人、说话内容的文本2.3 采用梯度下降方式进行拟合使用过程中,将声音数据输入给训练好的深度神经网络模型,该模型给出对每个时间步的概率预测结果,即每个时间步所属说话人的概率分布、说话内容的概率分布。
[0023]
将声音数据的全部时间步输出综合起来,按照说话人的连续说话进行切分,生成各段起始截止时间,各段的说话人、各段的文本内容。
[0024]
3 模块3:将模块2输出的语音段进行语音特征提取。
[0025]
参见“模块3功能图”依据语音段的切分时间,对原始音频信号进行重采样。并按预设的方法给予重采样的结果进行语音特征抽取。
[0026]
4 模块4:依据文本情感语料库,将模块2输出的各个说话人的文本内容编码为语义情感特征。
[0027]
参见“模块4功能图”文本情感语料库为公司长期积累、自行研发的自然语言特征数据集。描述了在不同语境下,各个词汇具有的不同的情感特征及相应强度。情感分类采用parrott分类法,共115个类别。每个分类用长度为30的向量表示。
[0028]
模块4为具有记忆功能的时序神经网络,记忆有一定时序限度内的情感特征。对于每一个说话人进行单独运算。模块3对最新文本内容进行分词,去停用词,依据文本情感语料库将词语转换为情感特征。将情感特征输入时序神经网络,并获取到最新的情感特征结果。
[0029]
5 模块5:依据模块2和模块3输出的语音特征和情感特征,进行气氛判断。
[0030]
模块5输入输出见图5气氛使用一个实数值来进行度量。实数取值范围为[0,1],0表示非常轻松,1表示非常紧张。
[0031]
模块5为一个独创的卷积神经网络和时序循环神经网络相结合的深度神经网络,将语音特征和情感特征输入到模型中,通过卷积神经网络抽取深层次特征,再将抽取出来的特征输入到时序循环神经网络,输出对气氛的预测结果。在训练过程中通过这个数值和人工标记值的差距来进行梯度下降。
[0032]
1 在模块2中采用常见的rnn-t模型。
[0033]
输出结果格式为:段起始时刻:段结束时刻:说话人id:说话文本在此基础上,对连续的同一说话人的段落进行合并。最大段落长度不超过k秒。
[0034]
本实施例中k值取6秒。原因为:文本模型最大长度一般不超过30字,当文字长度超过30字的时候,效果会较快降低。依据汉语常见语速推断及实验结果,将每段最大长度限制为6秒。
[0035]
2 模块32.1 重采样在重采样时,采用4khz,每帧窗口为60ms。通常音频采样不会低于8khz,但因为只
需要理解气氛,所以降低采样频率不影响最终效果,而且会降低对算力的要求。在同等算力的情况下,实际上提升了性能。
[0036]
2.2 梅尔倒谱系数提取依据实验结果,不考虑二阶差分的情况下,性能变化很小。采用不含二阶差分的梅尔倒谱系数。这样梅尔倒谱系数为26维度:12维倒谱系数、12维倒谱系数差分、1维能量和1维能量差分。
[0037]
2.3 输出矩阵的格式每段最大长度为6秒,每帧窗口为60ms,最大帧数为100。
[0038]
输出特征矩阵为 100 * 26 , 不足100帧,则补03 模块4中将词语转换为情感特征的方法:情感分类采用parrott分类法,共115个类别。每个分类用长度为30的向量表示。
[0039]
对文本进行分词,去除掉停用词,对剩下的词在文本情感语本实施料库中进行查找。忽略不在语料库中的词。如前文所述,每段文字通常不超过30字。经过分词、去除停用词等操作后,有效词一般不超过20个,如果超过,则抛弃。
[0040]
将每个有效词查找到的向量进行堆叠,形成一个20*30的二维矩阵。不足20个词的补04 模块5中深度神经网络的描述整个网络结构包括a) 针对音频特征的卷积神经网络b) 针对文本情感特征的卷积神经网络 c) 时序循环神经网络4.1 针对音频特征的卷积神经网络音频特征的输入为100 x 26的矩阵, 卷积核需要与输入特征等宽。
[0041]
具体卷积核尺寸如下:。
[0042]
本实施例中卷积核为: 5个1x26,5个2x26, 3个4x26, 3个8x26,3个16x26,1个32*26。
[0043]
所有卷积核padding为1,步长为1,卷积核个数为20个。
[0044]
对应k x 26的卷积核,输出尺寸为(100-k +1) x 1,使用同尺寸的最大池化,变为标量。
[0045]
对全部20个卷积核输出的标量进行拼接,得到尺寸为1 x 20 的向量e1。
[0046]
此向量进行tanh激活层,结果为1 x 20 的向量e2。
[0047]
4.2 针对文本情感特征的卷积神经网络文本情感特征的输入为20 x 30的矩阵, 卷积核需要与输入特征等宽。
[0048]
具体卷积核尺寸如下:。
[0049]
本实施例中卷积核为: 5个1x30,5个2x30, 3个4x30, 3个8x30。
[0050]
所有卷积核padding为1,步长为1,卷积核个数为16个。
[0051]
对应j x 30的卷积核,输出尺寸为(20-j +1) x 1,使用同尺寸的最大池化,变为标量。
[0052]
对全部16个卷积核输出的标量进行拼接,得到尺寸为1 x 16 的向量f1。
[0053]
此向量进行tanh激活层,结果为1 x 16 的向量f2。
[0054]
4.3 联合音频特征和文本特征,计算气氛
对上述向量e2、f2进行水平拼接,作为联合特征。采用一般的时序循环神经网络即可。
[0055]
本实施例中采用lstm模型。
[0056]
更详细的说,在每个时间步输出一个气氛预测值。
[0057]
在训练过程中,将每个时间步的气氛预测值和对应的标记值对应,使用均方误差作为损失,进行梯度下降。