1.本技术涉及但不限于实时通信技术,尤指一种单通道语音增强方法及装置。
背景技术:
2.随着实时通信(rtc,real-time communications)技术应用广泛,声学场景日趋复杂,相关技术中的前处理增强算法能力无法满足所有场景的需求,如嘈杂环境中对非平稳噪声的抑制问题、在线教育场景中音质的损伤问题等。在前处理增强算法中,直接影响语音质量和清晰度的语音增强算法吸引了大量学者和企业的关注,同时得益于深度学习类算法的发展,在过去几年中语音增强算法取得了长足的进步,还可以在相关语音业务如视频会议、在线教育等场景中极大地提升语音音质和可懂度,带来更极致的音质体验。其中,语音增强是指当语音信号被各种各样的噪声干扰、甚至淹没后,从噪声背景中提取有用的语音信号,抑制、降低噪声干扰的技术。即从含噪语音中提取尽可能纯净的原始语音。
3.相关技术中的语音增强算法多以频域特征的学习为主,导致增强后的语音音质受损,难以大规模应用于实际场景中。
技术实现要素:
4.本技术提供一种单通道语音增强方法及装置,能够大大提升降噪性能,改善听感体验。
5.本发明实施例提供了一种单通道语音增强方法,包括:
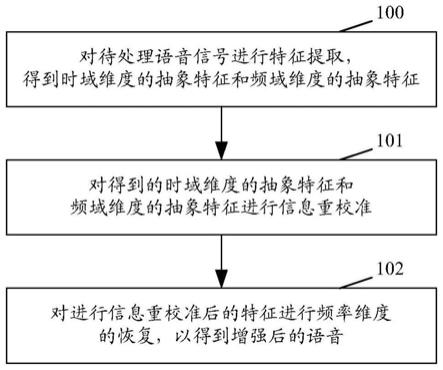
6.对待处理语音信号进行特征提取,得到时域维度的抽象特征和频域维度的抽象特征;
7.对得到的时域维度的抽象特征和频域维度的抽象特征进行信息重校准;
8.对进行信息重校准后的特征进行频率维度的恢复,以得到增强后的语音。
9.在一种示例性实例中,所述对待处理语音信号进行特征提取,包括:
10.对所述待处理语音信号进行特征预提取,之后进行抽象特征的提取,以得到所述时域维度的抽象特征和所述频域维度的抽象特征。
11.在一种示例性实例中,所述对待处理语音信号进行特征预提取,包括:
12.将所述待处理语音信号的频域幅度谱输入全连接层网络,并经过批处理归一化层、整流线性单元层的处理以进行所述特征预提取。
13.在一种示例性实例中,所述进行抽象特征的提取,包括:
14.采用多个块,按照不同比例和不同卷积核大小的对所述预提取的特征分别进行卷积运算,获取多级抽象特征;其中,抽象特征包括所述时域维度的抽象特征和所述频域维度的抽象特征。
15.在一种示例性实例中,所述对得到的时域维度的抽象特征和频域维度的抽象特征进行信息重校准,包括:
16.对卷积运算后得到的各级抽象特征进行感知层面的信息重校准。
17.在一种示例性实例中,所述对卷积运算后得到的各级抽象特征进行感知层面的信息重校准,包括:
18.对每个块的最后一层抽象特征分别进行时域和频域的聚合特征提取;
19.产生一组调制后的注意力权重,分别作用于每个块的最后一层卷积所产生的特征图,得到经时频联合域感知权重修正后的特征图。
20.在一种示例性实例中,所述进行时域和频域的聚合特征提取,包括:
21.对所述每个块的最后一层抽象特征进行全局平均池化操作;
22.通过聚合时间维度的抽象特征产生频率维度的描述算子,该描述算子用于获取全部时间帧范围内的频率维度的抽象特征的统计特性。
23.在一种示例性实例中,还包括:
24.对所述统计信息进行非线性处理,使得在估计每一个频点的特征值时使用到其他频点的信息。
25.在一种示例性实例中,所述产生一组调制后的注意力权重,包括:
26.根据所述聚合得到的全部时间帧范围内的频率维度的抽象特征的统计特性,产生一组所述调制后的频率维度的注意力权重。
27.本技术还提供一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行上述任一项所述单通道语音增强方法。
28.本技术又提供一种实现单通道语音增强的设备,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:用于执行上述任一项所述的单通道语音增强方法的步骤。
29.本技术再提供一种单通道语音增强装置,包括:提取模块、校准模块、恢复模块;其中,
30.提取模块,用于对待处理语音信号进行特征提取,得到时域维度的抽象特征和频域维度的抽象特征;
31.校准模块,用于对得到的时域维度的抽象特征和频域维度的抽象特征进行信息重校准;
32.恢复模块,用于对进行信息重校准后的特征进行频率维度的恢复,以得到增强后的语音。
33.通过本技术实施例提供的单通道语音增强方法及装置,结合时频联合域感知技术,允许语音增强网络执行各层抽象特征的重新校准,起到了增强降噪能力,提高人声保真度的作用,有助于网络通过学习全局信息来实现有选择地强调重要的抽象特征,并抑制不太有用的特征。本技术实施例通过利用包括时域维度和频域维度的全部感受野,考虑了语音帧内不同频带的分布差异及时间帧维度语音特性分布的差异,大大提升了单通道语音增强中的降噪性能,从而改善了听感体验。
34.本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
附图说明
35.附图用来提供对本技术技术方案的进一步理解,并且构成说明书的一部分,与本技术的实施例一起用于解释本技术的技术方案,并不构成对本技术技术方案的限制。
36.图1为本技术实施例中单通道语音增强方法的流程示意图;
37.图2为本技术实施例中时频联合域特征校准的过程示意图;
38.图3为本技术实施例中以频域为例的特征校准的过程示意图;
39.图4为本技术实施例中单通道语音增强装置的组成结构示意图。
具体实施方式
40.为使本技术的目的、技术方案和优点更加清楚明白,下文中将结合附图对本技术的实施例进行详细说明。需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互任意组合。
41.在本技术一个典型的配置中,计算设备包括一个或多个处理器(cpu)、输入/输出接口、网络接口和内存。
42.内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flash ram)。内存是计算机可读介质的示例。
43.计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括非暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
44.在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行。并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
45.随着近些年视频会议、在线教育等业务的兴起,实时通信的场景变得愈加复杂,需要提供一种降噪能力强、人声保真度高的语音增强算法,但是,相关技术中多以频域特征的学习为主,增强后的语音音质受损,难以大规模应用于实际场景中。为此,本技术发明人提出,如果在语音增强算法中,考虑纯净人声与噪声在时域和频域的不均匀分布特性,即提出一种基于时频联合域感知技术语音增强算法,那么,可以在几乎不引入额外计算复杂度的同时提升深度学习类语音增强算法的降噪性能,从而达到大大提升降噪性能,改善听感体验的目的。其中,时域(time domain)是描述数学函数或物理信号对时间的关系,本文可以指声音信号的时域波形随着时间的变化;频域(frequency domain)是指在对函数或信号进行分析时,分析其和频率有关的部分,而不是和时间有关的部分,和时域一词相对,本文可以指声音信号分布在哪些频率及其比例;时频联合域指将时域和频域的信息进行综合,既考虑声音信号随时间的变化,也考虑声音信号在频率维度的分布及比例。感知技术则多指
以人观感相关的技术,本文可以指有利于人耳主观听感的技术。
46.图1为本技术实施例中单通道语音增强方法的流程示意图,如图1所示,至少包括:
47.步骤100:对待处理语音信号进行特征提取,得到时域维度的抽象特征和频域维度的抽象特征。
48.在一种示例性实例中,步骤100可以包括:
49.对待处理语音信号进行特征预提取,之后进行抽象特征的提取,以得到时域维度的抽象特征和频域维度的抽象特征。
50.在一种示例性实例中,待处理语音信号为带噪语音的频域幅度谱(noisy speech magnitude spectrum)。
51.在一种示例性实例中,步骤100中的对待处理语音信号进行特征预提取可以包括如:将带噪语音的频域幅度谱输入全连接层网络,并经过批处理归一化层、整流线性单元(relu,rectified linear unit)层的处理以进行特征的预提取。本步骤的具体实现并不用于限定本技术的保护范围。
52.在一种示例性实例中,步骤100中的进行抽象特征的提取可以包括:
53.采用n个块,按照不同比例和不同卷积核大小对预提取的特征分别进行卷积运算,获取多级抽象特征;其中,抽象特征包括时域维度的抽象特征和频域维度的抽象特征。本步骤的具体实现并不用于限定本技术的保护范围。
54.步骤101:对得到的时域维度的抽象特征和频域维度的抽象特征进行信息重校准。
55.在一种示例性实例中,本步骤可以包括:
56.对卷积运算后得到的各级抽象特征进行感知层面的信息重校准。这样,可以在语音增强过程中充分利用到时域和频域的感知类信息。
57.在一种示例性实例中,如图2所示,步骤101可以包括:
58.对每个块的最后一层抽象特征分别进行时域和频域的聚合特征提取;
59.产生一组调制后的注意力权重,分别作用于每个块的最后一层卷积所产生的特征图,得到经时频联合域感知权重修正后的特征图。
60.在一种实施例中,如图2所示,对每个块的最后一层抽象特征分别进行时域和频域的聚合特征提取;分别对时域和频域提取到的聚合特征经过一系列的非线性变换,依次包括全连接层(fc)、整流线性单元(relu)、全连接层(fc)、s型函数层后,得到两组(时域和频域)调制后的注意力权重;使用一个简单的自门控(self-gating)机制完成对两组时域和频域调制后的注意力权重的融合;将融合后的注意力权重作用于每个块的最后一层抽象特征,得到校准后的特征。
61.通过本步骤,使得本技术的运算过程中利用到了包括时域维度和频域维度的全部感受野,为大大提升降噪性能,改善听感体验提供了保障。
62.如图3所示,以频域为例,步骤101的实现可以包括:
63.首先,对每个块的最后一层抽象特征进行全局平均池化(gap,global average pooling)操作;
64.然后,通过聚合时间维度的抽象特征可以产生一个频率维度的描述算子,该描述算子用于获取全部时间帧范围内的频率维度的抽象特征的统计特性(embedding),这样,对每一时间帧中的频率维度的特征值的求取都可以利用到全部时间维度的感受野;
65.根据聚合得到的全部时间帧范围内的频率维度的抽象特征的统计特性,产生一组调制后的频率维度的注意力权重,其中,注意力权重用于作用于每个块的最后一层卷积所产生的特征图,得到经频率维度注意力权重修正后的特征图。
66.本技术实施例中,将语音在不同频带中的分布差异这一固有属性,与注意力机制进行了巧妙融合,实现了有选择地强调重要的抽象特征,并抑制不太有用的特征,为提升单通道语音增强中的降噪性能,改善听感体验提供了保障。
67.在一种示例性实例中,对每个块的最后一层抽象特征进行gap操作,通过聚合时间维度的抽象特征可以产生一个频率维度的描述算子,从而得到频率维度的统计信息。计算公式如公式(1)所示:
[0068][0069]
公式(1)中,t表示总时间帧数,o表示每个块中最后一个卷积层的输出,z表示频率维度的统计信息,下标f表示频域索引。
[0070]
通过公式(1)得到的频率维度的统计信息利用到了全部时间维度的信息。
[0071]
在上述频率维度的统计信息中,频率维度之间还没有产生直接的关系,特征图中只隐含了语谱结构中时间维度的信息,本技术实施例中,为了增强网络对语谱结构的表征能力,还需要在频率维度之间产生相互依赖关系,在一种实施例中,还可以包括:
[0072]
对全局的频率通道统计信息进行非线性处理,使得在估计每一个频点的特征值时都可以使用到其他频点的信息。与此同时,随着网络的加深,每一次所进行的频率维度特征值的校准操作引起的影响都会被累积,这样带来的好处是降噪效果越来越好。
[0073]
在一种示例性实例中,对全局的频率通道统计信息进行非线性处理,可以由两层全连接层(fc)网络来实现,同时,为了保证这两层全连接层网络能够学习频率维度之间的非线性相互作用,并得到一个非互斥关系的频率维度特征值,还可以进一步包括:如图3所示,分别在两层全连接网络中包括relu和s型函数如sigmoid激活函数。
[0074]
如图3所示,最后将得到的频域维度的注意力权重作用于每个块中最后一个卷积层输出的特征图,以完成频域相互关系的补充。
[0075]
步骤103:对进行信息重校准后的特征进行频率维度的恢复,以得到增强后的语音。
[0076]
本步骤的具体实现并不用于限定本技术的保护范围,这里不再赘述。
[0077]
本技术实施例提供的单通道语音增强方法,结合时频联合域感知技术,允许语音增强网络执行各层抽象特征的重新校准,起到了增强降噪能力,提高人声保真度的作用,有助于网络通过学习全局信息来实现有选择地强调重要的抽象特征,并抑制不太有用的特征。本技术实施例通过利用包括时域维度和频域维度的全部感受野,考虑了语音帧内不同频带的分布差异及时间帧维度语音特性分布的差异,大大提升了单通道语音增强中的降噪性能,从而改善了听感体验。
[0078]
在一种示例性实例中,选取语音质量的感知评估(pesq,perceptual evaluation of speech quality)和短时客观可懂度(stoi,short-time objective intelligibility)作为评估语音增强后效果的客观指标,如表1(a)、表1(b)所示,显示了不同信噪比(snr)条件及不同学习目标下的结果,表1(a)中描述了在不同信噪比条件及不同学习目标下语音质
量的感知评估(pesq,perceptual evaluation of speech quality)的对比结果,pesq值越大,表明语音质量越高,值域范围在0.5-4.5之间;表1(b)中描述了在不同信噪比条件及不同学习目标下语音的短时客观可懂度(stoi,short-time objective intelligibility)的对比结果,stoi值越大,表明语音可懂度越高,值域范围在0-1之间,表格中呈现的数值是%分数,例如60.2%。从上述结果可见,基于本技术实施例提供的结合时频联合域感知技术的时域卷积网络(tcn-tfanet,temporal convolutional network)的单通道语音增强方法,明显提升了增强后语音的质量和可懂度,综合结论为pesq提升了10.3%,stoi提升了4.2%。
[0079][0080]
表1(a)
[0081][0082]
表1(b)
[0083]
为了验证本技术实施例提供的基于时频联合域感知技术的的单通道语音增强方法在增强后语音语谱图完整性上的优势,本技术实施例中还通过录制几十条真实场景下的带噪语音来进行实验,在本实验中,噪声环境主要包括街道、集市等,实验结果表明,在执行本技术实施例的各层抽象特征的重新校准后,不仅增强了降噪能力,同时语谱结构还保持得更完整,尤其是高频部分,几乎没有损伤。
[0084]
从上面的实验数据可见,本技术实施例提供的单通道语音增强方法,成功应用于tcn网络中,提出了结合时频联合域感知技术的tcn-tfanet,最终获得了更为完整的增强后语谱结构,实际评测结果显示,客观指标和主观听感均表明,本技术实施例提供的单通道语音增强方法在降噪能力更强的情况下语音损伤更小,而且增强后的语音语谱图结构更完整,并有更好的主观听感,同时功耗低,尤其适用于直播等实时通信类场景。
[0085]
本技术还提供一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行上述任一项所述的单通道语音增强方法。
[0086]
本技术再提供一种实现单通道语音增强的设备,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:用于执行上述任一项所述的单通道语音增强方法的步骤。
[0087]
图4为本技术实施例中单通道语音增强装置的组成结构示意图,如图4所示,至少包括:提取模块、校准模块、恢复模块;其中,
[0088]
提取模块,用于对待处理语音信号进行特征提取,得到时域维度的抽象特征和频域维度的抽象特征;
[0089]
校准模块,用于对得到的时域维度的抽象特征和频域维度的抽象特征进行信息重校准;
[0090]
恢复模块,用于对进行信息重校准后的特征进行频率维度的恢复,以得到增强后的语音。
[0091]
在一种示例性实例中,提取模块具体用于:
[0092]
对待处理语音信号进行特征预提取,之后进行抽象特征的提取,以得到时域维度的抽象特征和频域维度的抽象特征。
[0093]
在一种示例性实例中,提取模块中的对待处理语音信号进行特征预提取可以包括如:将带噪语音的频域幅度谱输入全连接层网络,并经过批处理归一化层、relu层的处理以进行特征的预提取。
[0094]
在一种示例性实例中,提取模块中的进行抽象特征的提取可以包括:采用n个块,按照不同比例和不同卷积核大小的对预提取的特征分别进行卷积运算,获取多级抽象特征;其中,抽象特征包括时域维度的抽象特征和频域维度的抽象特征。
[0095]
在一种示例性实例中,校准模块具体用于:
[0096]
对每个块的最后一层抽象特征分别进行时域和频域的聚合特征提取;
[0097]
产生一组调制后的注意力权重,分别作用于每个块的最后一层卷积所产生的特征图,得到经时频联合域感知权重修正后的特征图。
[0098]
在一种实施例中,可以使用一个简单的自门控(self-gating)机制来产生一组调制后的注意力权重。
[0099]
本技术实施例提供的单通道语音增强装置,结合时频联合域感知技术,允许语音增强网络执行各层抽象特征的重新校准,起到了增强降噪能力,提高人声保真度的作用,有助于网络通过学习全局信息来实现有选择地强调重要的抽象特征,并抑制不太有用的特征。本技术实施例通过利用包括时域维度和频域维度的全部感受野,考虑了语音帧内不同频带的分布差异及时间帧维度语音特性分布的差异,大大提升了单通道语音增强中的降噪性能,从而改善了听感体验。
[0100]
虽然本技术所揭露的实施方式如上,但所述的内容仅为便于理解本技术而采用的实施方式,并非用以限定本技术。任何本技术所属领域内的技术人员,在不脱离本技术所揭露的精神和范围的前提下,可以在实施的形式及细节上进行任何的修改与变化,但本技术的专利保护范围,仍须以所附的权利要求书所界定的范围为准。