1.本发明涉及系统场景的控制技术领域,具体涉及一种语音控制场景方法和语音控制场景系统。
背景技术:
2.现有的移动设备设有系统锁定状态和系统解锁状态,当所述移动设备在识别到语言命令后,需要将移动设备的系统从系统锁定状态切换成系统解锁状态后,才可以顺利执行语言命令对应的场景消息。然而,移动设备现有的解锁方式是通过密码解锁、指纹解锁和人脸识别解锁,因此当移动设备处于锁定状态情况下,用户还需要配合其他解锁方式或解锁行为才能顺利通过语音控制移动设备的场景,导致语音控制移动设备的场景的效率慢,大大降低了用户操作使用移动设备的体验。
技术实现要素:
3.本发明的目的在于克服现有技术中的缺点与不足,提供一种语音控制场景方法和语音控制场景系统,可以提高语音控制移动设备的场景的效率,提升用户操作使用移动设备的体验。
4.本发明的一个实施例提供一种语音控制场景方法,包括以下步骤:
5.实时获取语音数据;
6.根据预训练的语音
‑
声学神经网络模型,从所述语音数据中获取声学特征;
7.检测所述声学特征,若所述声学特征包含了预设的系统唤醒声学特征,唤醒所述移动设备的系统;
8.根据预训练的语音
‑
声纹神经网络模型,从所述语音数据中获取声纹特征;
9.检测所述声纹特征,若所述声纹特征与预设置的用户解锁声纹相同,解锁唤醒后的所述移动设备的系统;
10.根据预训练的语音
‑
文字神经网络模型,将所述语音数据转换成文字数据;
11.根据所述文字数据和预训练的事件数据库进行场景事件消息匹配,获得对应的场景事件消息并执行。
12.相对于现有技术,本发明的语音控制场景方法从所述语音数据中获取声学特征,根据所述声学特征唤醒所述移动设备的系统,然后从所述语音数据中获取声纹特征,根据所述声纹特征解锁唤醒后的所述移动设备的系统,再将所述语音数据转换成文字数据,根据所述文字数据获得对应的场景事件消息并执行,可以提高语音控制移动设备的场景的效率,提升用户操作使用移动设备的体验。
13.进一步,所述根据预训练的语音
‑
文字神经网络模型,将所述语音数据转换成文字数据之前,还包括以下步骤:
14.对所述语音数据进行帧切割,得到多帧分段语音信号;
15.采用滤波器过滤各帧所述分段语音信号中干扰噪声;
16.采用高频滤波器对所述分段语音信号中高频部分进行预加重。提高语音数据转换成文字数据的准确性。
17.进一步,所述语音
‑
声学神经网络模型的训练过程包括以下步骤:
18.获取第一语音训练样本,所述第一语音训练样本包括第一语音训练数据和声学训练特征;
19.利用所述第一语音训练样本对初始的语音
‑
声学神经网络模型进行训练,得到训练好的语音
‑
声学神经网络模型。通过训练得到所述语音
‑
声学神经网络模型。
20.进一步,所述语音
‑
声纹神经网络模型的训练过程包括以下步骤:
21.获取第二语音训练样本,所述第二语音训练样本包括第二语音训练数据和声纹训练特征;
22.利用所述第二语音训练样本对初始的语音
‑
声纹神经网络模型进行训练,得到训练好的语音
‑
声纹神经网络模型。通过训练得到所述语音
‑
声纹神经网络模型。
23.进一步,所述语音
‑
文字神经网络模型的训练过程包括以下步骤:
24.获取第三语音训练样本,所述第三语音训练样本包括第三语音训练数据和文字训练数据;
25.利用所述第三语音训练样本对初始的语音
‑
文字神经网络模型进行训练,得到训练好的语音
‑
文字神经网络模型。通过训练得到所述语音
‑
文字神经网络模型。
26.进一步,所述第一语音训练数据、第二语音训练数据和第三语音训练数据为相同内容的语音训练数据。通过应用相同内容的语音训练数据分别训练所述语音
‑
声学神经网络模型、语音
‑
声纹神经网络模型和语音
‑
文字神经网络模型,提高各个神经网络模型的适配性。
27.本发明还提供一种语音控制场景系统,包括:语音数据获取模块、声学特征获取模块、系统唤醒模块、声纹特征获取模块、系统解锁模块、文字数据获取模块和执行模块;
28.所述语音数据获取模块用于实时获取语音数据;
29.所述声学特征获取模块用于根据预训练的语音
‑
声学神经网络模型,从所述语音数据中获取声学特征;
30.所述系统唤醒模块用于检测所述声学特征,若所述声学特征包含了预设的系统唤醒声学特征,唤醒所述移动设备的系统;
31.所述声纹特征获取模块用于根据预训练的语音
‑
声纹神经网络模型,从所述语音数据中获取声纹特征;
32.所述系统解锁模块用于检测所述声纹特征,若所述声纹特征与预设置的用户解锁声纹相同,解锁唤醒后的所述移动设备的系统;
33.所述文字数据获取模块用于根据预训练的语音
‑
文字神经网络模型,将所述语音数据转换成文字数据;
34.所述执行模块用于根据所述文字数据和预训练的事件数据库进行场景事件消息匹配,获得对应的场景事件消息并执行。
35.相对于现有技术,本发明的语音控制场景系统从所述语音数据中获取声学特征,根据所述声学特征唤醒所述移动设备的系统,然后从所述语音数据中获取声纹特征,根据所述声纹特征解锁唤醒后的所述移动设备的系统,再将所述语音数据转换成文字数据,根
据所述文字数据获得对应的场景事件消息并执行,可以提高语音控制移动设备的场景的效率,提升用户操作使用移动设备的体验。
36.进一步,所述语音
‑
声学神经网络模型的训练过程包括以下步骤:
37.获取第一语音训练样本,所述第一语音训练样本包括第一语音训练数据和声学训练特征;
38.利用所述第一语音训练样本对初始的语音
‑
声学神经网络模型进行训练,得到训练好的语音
‑
声学神经网络模型。通过训练得到所述语音
‑
声学神经网络模型。
39.进一步,所述语音
‑
声纹神经网络模型的训练过程包括以下步骤:
40.获取第二语音训练样本,所述第二语音训练样本包括第二语音训练数据和声纹训练特征;
41.利用所述第二语音训练样本对初始的语音
‑
声纹神经网络模型进行训练,得到训练好的语音
‑
声纹神经网络模型。通过训练得到所述语音
‑
声纹神经网络模型。
42.进一步,所述语音
‑
文字神经网络模型的训练过程包括以下步骤:
43.获取第三语音训练样本,所述第三语音训练样本包括第三语音训练数据和文字训练数据;
44.利用所述第三语音训练样本对初始的语音
‑
文字神经网络模型进行训练,得到训练好的语音
‑
文字神经网络模型。过训练得到所述语音
‑
文字神经网络模型。
45.为了能更清晰的理解本发明,以下将结合附图说明阐述本发明的具体实施方式。
附图说明
46.图1为本发明一个实施例的语音控制场景方法的流程图。
47.图2为本发明一个实施例的语音控制场景系统的模块连接图。
48.1、语音数据获取模块;2、声学特征获取模块;3、系统唤醒模块;4、声纹特征获取模块;5、系统解锁模块;6、文字数据获取模块;7、执行模块。
具体实施方式
49.为使本技术的目的、技术方案和优点更加清楚,下面将结合附图对本技术实施例方式作进一步地详细描述。
50.应当明确,所描述的实施例仅仅是本技术实施例一部分实施例,而不是全部的实施例。基于本技术实施例中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本技术实施例保护的范围。
51.下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。在本技术的描述中,需要理解的是,术语“第一”、“第二”、“第三”等仅用于区别类似的对象,而不必用于描述特定的顺序或先后次序,也不能理解为指示或暗示相对重要性。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本技术中的具体含义。在本技术和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。在此所使用的词语“如果”/“若”可以被解释成为“在
……
时”或“当
……
时”或“响应于确定”。
52.此外,在本技术的描述中,除非另有说明,“多个”是指两个或两个以上。“和/或”,
描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。
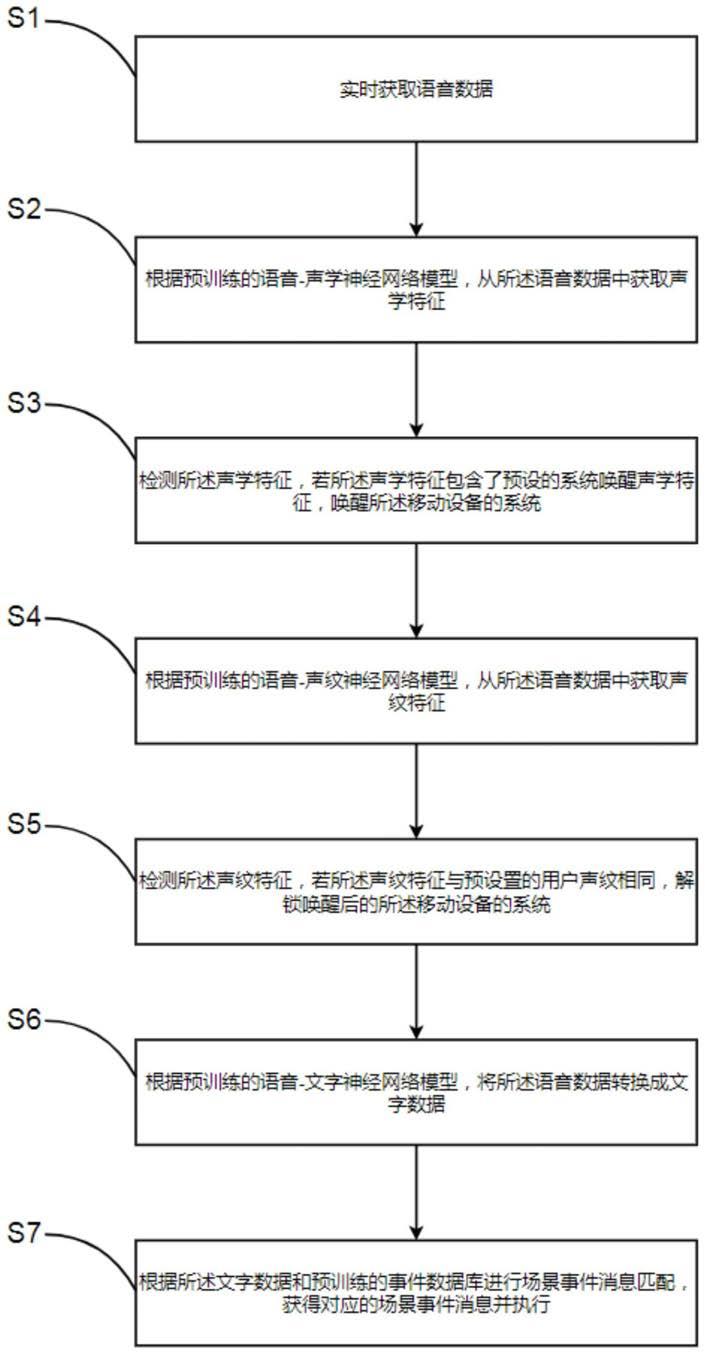
53.请参阅图1,其是本发明一个实施例的语音控制场景方法的流程图,所述语音控制场景方法应用于应用于移动设备的系统,包括以下步骤:
54.s1、实时获取语音数据。所述步骤s1是通过所述移动设备上的语音数据获取模块获取的。所述移动设备为智能电子设备,如智能手机、智能平板等。
55.s2、根据预训练的语音
‑
声学神经网络模型,从所述语音数据中获取声学特征。
56.其中,所述声学特征为所述语音数据的发音数据。
57.s3、检测所述声学特征,若所述声学特征包含了预设的系统唤醒声学特征,唤醒所述移动设备的系统。
58.所述预设的系统唤醒声学特征为,用于唤醒所述移动设备的系统的词语的发音数据或音调数据。例如所述系统唤醒声学特征可以是所述移动设备的语音助手的名称,也可以是用户自行设置的昵称的发音数据。其中语音助手的名称与所述移动设备的品牌或型号相关联,以市面上较为知名的智能手机品牌为例,如苹果手机iphone的语音助手是siri、三星手机的语音助手是bixby、华为手机的语音助手叫小艺、小米的语音助手叫小爱、vivo手机的语音助手叫小v、oppo的语音助手叫小o等。而用户自行设置的昵称可以是根据用户输入的中文字、英文单词、日文字、韩文字、法文字、德文字等各国文字的发音数据,可以是用户输入的数字的发音数据,还可以是将用户的录音作为自行设置的昵称的发音数据,例如用户用中国大陆内较为常见的语言,如国语、北方方言、吴方言、湘方言、赣方言、客家方言、粤方言、闽北方言、闽南方言、莆仙方言等,或者国外较为常见的语言,如英语、日语、汉语、法语、德语的各种语言的录音作为自行设置的昵称的发音数据。当自行设置的昵称时根据英文或英语设置时,所述昵称可以通过美式发音和英式发硬的发音数据唤醒系统。
59.s4、根据预训练的语音
‑
声纹神经网络模型,从所述语音数据中获取声纹特征。
60.s5、检测所述声纹特征,若所述声纹特征与预设置的用户解锁声纹相同,解锁唤醒后的所述移动设备的系统。
61.其中,如果用户是将自己的录音作为所述预设的系统唤醒声学特征,则直接从用户自己的录音中提取出录音声纹特征,并将所述录音声纹特征作为预设置的用户解锁声纹。否则,需要用户预先录制一段语音,然后从录制的录音中提取出所述录音声纹特征,再将所述录音声纹特征作为预设置的用户解锁声纹。其中,用户预先录制的一段语音可以是一句话,也可以是简单的单词或短语。优选地,用户预先录制的一段语音的内容包含有所述预设的系统唤醒声学特征对应的内容,以便于通过所述语音数据的发音数据唤醒所述移动设备的系统时,可以将所述语音数据的声纹与预设置的用户解锁声纹比对,且由于两者之间含有了相同的内容,因此可以提高声纹对比的效率和对比结果的准确性。
62.s6、根据预训练的语音
‑
文字神经网络模型,将所述语音数据转换成文字数据。
63.s7、根据所述文字数据和预训练的事件数据库进行场景事件消息匹配,获得对应的场景事件消息并执行。
64.所述场景时间消息可以是所述移动设备的系统中自带的应用程序的启动指令、场景状态切换指令,也可以是所述移动设备通过本地、第三方设备或网络线上安装的应用程序。所述移动设备的系统中自带的应用程序的启动指令可以是智能手机或智能平板的相机
的启动指令、日历的启动指令、相簿的启动指令、计算器的启动指令、闹钟设置界面的打开指令、电话通讯录的打开指令、短信功能的打开指令和设置界面的打开指令等。所述场景状态切换指令可以是智能手机或智能平板的静音场景的启闭状态切换、飞行模式的启闭状态切换、蓝牙模式的启闭状态切换、wifi模式的启闭状态切换、数据流量的启闭状态切换和屏幕方向的横竖状态切换等。其中,安装的应用程序包括微信、qq、高德地图、uc浏览器、抖音、优酷视频播放器、腾讯视频播放器、百度浏览器、美团外卖、拼多多、手机淘宝、支付宝以及各种游戏娱乐用的应用程序,如王者荣耀、原神、阴阳师、妖怪屋、和平精英等。
65.相对于现有技术,本发明的语音控制场景方法从所述语音数据中获取声学特征,根据所述声学特征唤醒所述移动设备的系统,然后从所述语音数据中获取声纹特征,根据所述声纹特征解锁唤醒后的所述移动设备的系统,再将所述语音数据转换成文字数据,根据所述文字数据获得对应的场景事件消息并执行,可以提高语音控制移动设备的场景的效率,提升用户操作使用移动设备的体验。
66.在一个可行的实施例中,所述根据预训练的语音
‑
文字神经网络模型,将所述语音数据转换成文字数据之前,还包括以下步骤:
67.s11、对所述语音数据进行帧切割,得到多帧分段语音信号;
68.s12、采用滤波器过滤各帧所述分段语音信号中干扰噪声;
69.s13、采用高频滤波器对所述分段语音信号中高频部分进行预加重。提高语音数据转换成文字数据的准确性。
70.在一个可行的实施例中,所述语音
‑
声学神经网络模型的训练过程包括以下步骤:
71.获取第一语音训练样本,所述第一语音训练样本包括第一语音训练数据和声学训练特征;
72.利用所述第一语音训练样本对初始的语音
‑
声学神经网络模型进行训练,得到训练好的语音
‑
声学神经网络模型。通过训练得到所述语音
‑
声学神经网络模型。
73.在一个可行的实施例中,所述语音
‑
声纹神经网络模型的训练过程包括以下步骤:
74.获取第二语音训练样本,所述第二语音训练样本包括第二语音训练数据和声纹训练特征;
75.利用所述第二语音训练样本对初始的语音
‑
声纹神经网络模型进行训练,得到训练好的语音
‑
声纹神经网络模型。通过训练得到所述语音
‑
声纹神经网络模型。
76.在一个可行的实施例中,所述语音
‑
文字神经网络模型的训练过程包括以下步骤:
77.获取第三语音训练样本,所述第三语音训练样本包括第三语音训练数据和文字训练数据;
78.利用所述第三语音训练样本对初始的语音
‑
文字神经网络模型进行训练,得到训练好的语音
‑
文字神经网络模型。通过训练得到所述语音
‑
文字神经网络模型。
79.在一个可行的实施例中,所述第一语音训练数据、第二语音训练数据和第三语音训练数据为相同内容的语音训练数据。通过应用相同内容的语音训练数据分别训练所述语音
‑
声学神经网络模型、语音
‑
声纹神经网络模型和语音
‑
文字神经网络模型,提高各个神经网络模型的适配性。优选地,所述语音训练数据来源于不同地域、性别和年龄段的人群。
80.请参阅图2,本发明还提供一种语音控制场景系统,包括:语音数据获取模块1、声学特征获取模块2、系统唤醒模块3、声纹特征获取模块4、系统解锁模块5、文字数据获取模
块6和执行模块7。
81.所述语音数据获取模块1用于实时获取语音数据。
82.所述声学特征获取模块2用于根据预训练的语音
‑
声学神经网络模型,从所述语音数据中获取声学特征。
83.所述系统唤醒模块3用于检测所述声学特征,若所述声学特征包含了预设的系统唤醒声学特征,唤醒所述移动设备的系统。
84.所述声纹特征获取模块4用于根据预训练的语音
‑
声纹神经网络模型,从所述语音数据中获取声纹特征。
85.所述系统解锁模块5用于检测所述声纹特征,若所述声纹特征与预设置的用户解锁声纹相同,解锁唤醒后的所述移动设备的系统。
86.所述文字数据获取模块6用于根据预训练的语音
‑
文字神经网络模型,将所述语音数据转换成文字数据。
87.所述执行模块7用于根据所述文字数据和预训练的事件数据库进行场景事件消息匹配,获得对应的场景事件消息并执行。
88.其中所述预设的系统唤醒声学特征为,用于唤醒所述移动设备的系统的词语的发声数据或音调数据。
89.所述移动设备为智能电子设备,如智能手机、智能平板等。
90.所述预设的系统唤醒声学特征为,用于唤醒所述移动设备的系统的词语的发音数据或音调数据。例如所述系统唤醒声学特征可以是所述移动设备的语音助手的名称,也可以是用户自行设置的昵称的发音数据。其中语音助手的名称与所述移动设备的品牌或型号相关联,以市面上较为知名的智能手机品牌为例,如苹果手机iphone的语音助手是siri、三星手机的语音助手是bixby、华为手机的语音助手叫小艺、小米的语音助手叫小爱、vivo手机的语音助手叫小v、oppo的语音助手叫小o等。而用户自行设置的昵称可以是根据用户输入的中文字、英文单词、日文字、韩文字、法文字、德文字等各国文字的发音数据,可以是用户输入的数字的发音数据,还可以是将用户的录音作为自行设置的昵称的发音数据,例如用户用中国大陆内较为常见的语言,如国语、北方方言、吴方言、湘方言、赣方言、客家方言、粤方言、闽北方言、闽南方言、莆仙方言等,或者国外较为常见的语言,如英语、日语、汉语、法语、德语的各种语言的录音作为自行设置的昵称的发音数据。当自行设置的昵称时根据英文或英语设置时,所述昵称可以通过美式发音和英式发硬的发音数据唤醒系统。
91.其中,如果用户是将自己的录音作为所述预设的系统唤醒声学特征,则直接从用户自己的录音中提取出录音声纹特征,并将所述录音声纹特征作为预设置的用户解锁声纹。否则,需要用户预先录制一段语音,然后从录制的录音中提取出所述录音声纹特征,再将所述录音声纹特征作为预设置的用户解锁声纹。其中,用户预先录制的一段语音可以是一句话,也可以是简单的单词或短语。优选地,用户预先录制的一段语音的内容包含有所述预设的系统唤醒声学特征对应的内容,以便于通过所述语音数据的发音数据唤醒所述移动设备的系统时,可以将所述语音数据的声纹与预设置的用户解锁声纹比对,且由于两者之间含有了相同的内容,因此可以提高声纹对比的效率和对比结果的准确性。
92.所述场景时间消息可以是所述移动设备的系统中自带的应用程序的启动指令、场景状态切换指令,也可以是所述移动设备通过本地、第三方设备或网络线上安装的应用程
序。所述移动设备的系统中自带的应用程序的启动指令可以是智能手机或智能平板的相机的启动指令、日历的启动指令、相簿的启动指令、计算器的启动指令、闹钟设置界面的打开指令、电话通讯录的打开指令、短信功能的打开指令和设置界面的打开指令等。所述场景状态切换指令可以是智能手机或智能平板的静音场景的启闭状态切换、飞行模式的启闭状态切换、蓝牙模式的启闭状态切换、wifi模式的启闭状态切换、数据流量的启闭状态切换和屏幕方向的横竖状态切换等。其中,安装的应用程序包括微信、qq、高德地图、uc浏览器、抖音、优酷视频播放器、腾讯视频播放器、百度浏览器、美团外卖、拼多多、手机淘宝、支付宝以及各种游戏娱乐用的应用程序,如王者荣耀、原神、阴阳师、妖怪屋、和平精英等。
93.相对于现有技术,本发明的语音控制场景系统从所述语音数据中获取声学特征,根据所述声学特征唤醒所述移动设备的系统,然后从所述语音数据中获取声纹特征,根据所述声纹特征解锁唤醒后的所述移动设备的系统,再将所述语音数据转换成文字数据,根据所述文字数据获得对应的场景事件消息并执行,可以提高语音控制移动设备的场景的效率,提升用户操作使用移动设备的体验。
94.优选地,所述文字数据获取模块6在将所述语音数据转换成文字数据之前,还对所述语音数据进行帧切割,得到多帧分段语音信号,然后采用滤波器过滤各帧所述分段语音信号中干扰噪声,再采用高频滤波器对所述分段语音信号中高频部分进行预加重,从而提高语音数据转换成文字数据的准确性。
95.在一个可行的实施例中,所述语音
‑
声学神经网络模型的训练过程包括以下步骤:
96.获取第一语音训练样本,所述第一语音训练样本包括第一语音训练数据和声学训练特征;
97.利用所述第一语音训练样本对初始的语音
‑
声学神经网络模型进行训练,得到训练好的语音
‑
声学神经网络模型。通过训练得到所述语音
‑
声学神经网络模型。
98.在一个可行的实施例中,所述语音
‑
声纹神经网络模型的训练过程包括以下步骤:
99.获取第二语音训练样本,所述第二语音训练样本包括第二语音训练数据和声纹训练特征;
100.利用所述第二语音训练样本对初始的语音
‑
声纹神经网络模型进行训练,得到训练好的语音
‑
声纹神经网络模型。通过训练得到所述语音
‑
声纹神经网络模型。
101.在一个可行的实施例中,所述语音
‑
文字神经网络模型的训练过程包括以下步骤:
102.获取第三语音训练样本,所述第三语音训练样本包括第三语音训练数据和文字训练数据;
103.利用所述第三语音训练样本对初始的语音
‑
文字神经网络模型进行训练,得到训练好的语音
‑
文字神经网络模型。过训练得到所述语音
‑
文字神经网络模型。
104.优选地,所述第一语音训练数据、第二语音训练数据和第三语音训练数据为相同内容的语音训练数据。通过应用相同内容的语音训练数据分别训练所述语音
‑
声学神经网络模型、语音
‑
声纹神经网络模型和语音
‑
文字神经网络模型,提高各个神经网络模型的适配性。优选地,所述语音训练数据来源于不同地域、性别和年龄段的人群。
105.在本发明的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗
示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。在本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上。
106.以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。