用量化的情感状态进行语音
‑
情感识别的装置和方法
技术领域
1.本发明涉及自动语音情感识别技术,特别涉及用于量化、预测、识别和区分语音(speech)中的情感状态的装置和方法。本发明还涉及自动语音情感识别(automatic speech emotion recognition,aser)机器学习模型、分类器、训练技术、自我更新和再训练。
背景技术:
2.近年来,自动语音情感识别(aser)在客户服务、心理健康诊断、咨询和各种人机交互界面等领域显示出很好的应用前景。在人类语音(speech)的情感识别系统和模型方面有大量学术研究,但现实世界的应用仍然具有挑战性,因为人类情感极难定义,在如何测量、量化和分类方面缺乏共同的共识。
3.迄今为止,大多数研究都是基于现有的人类语音录音数据库,着重于分析人类语音中的各种参数或特征中提取的特征,尤其是声学差异。其中许多研究还局限于对情感的定性描述,如积极、消极、高、低、中等分配。此外,大多数现有的人类语音记录数据库包含人工表演和静态语音(static speech),而不是取自在日常正常社交的自然和动态环境下的自发语音。然而,言语情感与说话者的人口、性别、年龄、文化背景以及口语时空变化的影响高度相关。因此,这些数据库很难提供涵盖人类各种情感的数据。如此,即使可以成功开发情感识别模型,也很少有这些模型的更新。
4.此外,这些记录人类的数据库在数据模式设计、来源和收集方面的数据质量在语音情感识别中起着至关重要的作用,因为分类过程通常依赖于标记数据;因此,数据的质量极大地影响了模型的建立和识别过程的性能。
5.此外,现有系统和模型在情感分类方面差别很大。情感最常被分类为愤怒、悲伤、喜悦等不同的类别。然而,目前还没有系统和有效的方法来区分情感状态的数量级(例如等级、水平、程度等)和每个识别的情感类别的强度或力度的尺度;也没有相对客观的方法将这些数量级分配给识别的各种语音情感。
6.因此,期望有一种支持模型自动更新、识别和定量测量语音情感的高效的系统或有效的方法,本领域的这种需求尚未得到满足。这样的系统或方法不仅在一般应用上有需求,而且在具体标定的目的上也有需要,例如个性化、驾驶员的安全、心理健康诊断等。
技术实现要素:
7.本发明提供了一种用于语音
‑
情感识别的装置和方法,其可以将语音情感量化为可测量的尺度和数值。本发明的另一个目的是提供这种基于连续自我更新和可重新训练的aser机器学习模型的语音
‑
情感识别装置和方法。
8.根据本发明的一方面,使用通过处理一个或多个人类语音源输入数据流的一个或多个音频信号及其相关文本而获得的训练数据,来训练语音
‑
情感识别分类器或混合分类器,该训练数据经过情感评估和评级过程、情感状态评级归一化过程、特征提取过程、特征
属性量化过程、以及可选的特征属性散列过程。其中,人类语音输入源数据流可以是但不限于现实生活中人与人之间的正常对话和争吵、日常用语、新闻报道、辩论和正式演讲的音轨或音频记录。
9.在一个实施例中,语音
‑
情感识别分类器是基于支持向量机(support vector machine,svm)实施的,混合分类器是基于具有局部敏感散列(locality
‑
sensitive hashing,lsh)的svm实施的。
10.在一个实施例中,情感评估和评级过程包括:通过一个人口样本组,来感知人类语音输入源数据流的每个音频信号(话语)及其相关文本,人口样本组是基于具有相似文化背景的个人对话语语言的掌握和理解来选择的,具有相似文化背景的个人的选取标准包括但不限于性别、年龄范围、职业、家庭背景和教育水平在内的一个或多个标准;通过该人口样本组,将话语中每个话语单元(例如,字符、单词或短语)的情感分配到其中一个情感类别中(例如,爱、喜悦、惊讶、愤怒、悲伤、恐惧、中性等);并通过该人口样本组,从话语的声学(包括音调)、词汇、语言特征和语义内容方面,对每个单独的话语单元的情感强度等级进行评级,以确定其情感状态(例如,
…
,
‑
3,
‑
2,
‑
1,0,+1,+2,+3,
…
等)。
11.在一个实施例中,情感状态评级归一化过程包括:获取每个话语的情感分配分布和评级分布;剔除情感分配分布中的奇异和极端情感分配以及评级分布中的奇异和极端评级值;以及确定剔除后的话语归一化情感分配和话语情感强度等级的归一化评级值。
12.在一个实施例中,特征提取过程从每个音频信号(话语)中提取一个或多个具有特征属性的特征,特征属性包括但不限于话语中每个单独话语单元(例如,字符、单词或短语)的音高(pitch)、音调(tone)、声音长度(length of sound)、响度(loudness)、基本频率(fundamental frequency)和语义串(semantic string)中的一个或多个、频率
‑
时间表示(frequency
‑
time representation)、语音振幅方差(variance of speech by amplitude)、话语单元节奏的语音方差(variance of speech by pacing of utterance units)、过零率(zero crossing rate)、基本估算及其推导(fundamental estimation and its derivation)、音频信号的频谱分布(spectral distribution of the audio signal)、语音中浊音与清音信号的比率(ratio of voiced vs.unvoiced signal in speech)、以及话语的语音韵律(prosody of speech of the utterance)。
13.特征提取过程之后是特征量化过程,其中提取的特征属性通过标签、标记和加权进行量化,它们的值在可测量的尺度下分配。
14.然后在特征属性散列过程中对提取的特征及其量化属性进行散列。之后,将量化的提取特征属性的散列值用于形成代表相应提取特征的特征向量,且话语的提取特征的特征向量形成话语的特征向量空间。
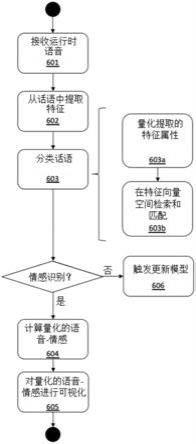
15.归一化的分配情感、情感强度等级、和提取特征及其各自音频信号的量化属性,构成训练数据,用于训练和测试语音
‑
情感识别分类器或混合分类器和识别模型。
16.根据本发明的另一方面,训练数据和散列值存储在训练数据储存库中,以便在其他语音
‑
情感识别系统中重复使用。
17.在运行时,语音
‑
情感识别装置被配置为执行根据本发明实施例的运行方法,以识别具有一个或多个音频信号(话语)的实时语音的语音情感。
18.根据本发明的另一方面,运行时语音
‑
情感识别方法包括:接收实时语音的音频信
号;从每个话语中提取一个或多个特征;由训练分类器或混合分类器对话语进行分类,包括:对提取的特征属性进行量化;在训练分类器或混合分类器形成的特征向量空间中搜索并匹配量化的提取特征属性,以获得识别的话语情感和每个话语单元(例如,字符、单词或短语)的情感强度等级。对于识别出其话语单元的情感和情感强度等级的话语,计算该话语的量化情感状态(例如,有点生气、非常生气或极度生气),并由具有显示器的电子设备(例如智能手机、平板电脑、个人电脑、电子信息亭等)以文本、图形(例如,图形均衡器)和/或其他数字格式进行可视化。
19.随着时间的推移和使用,经过训练的语音
‑
情感识别分类器或混合分类器可能会遇到无法识别的情感话语,例如,由于语言变化产生了新词和短语。一个无法识别情感的话语要么是具有无法提取和/或量化的特征和特征属性的话语(未标记数据),要么是具有无法匹配的量化的提取特征属性的话语。在连续的自我更新和可重新训练的aser机器学习模型下,未识别的情感话语以及量化的提取特征属性(如果有的话)被输入到更新模型中。
20.在更新模型中,带有未标记数据的未识别情感的话语首先通过上述特征提取过程和特征属性量化过程进行处理,以得到其量化的提取特征属性。在另一个实施例中,带有未标记数据的未识别情感的话语首先由人类智能进行标记(例如,手动标记未标记数据),然后由上述特征提取过程和特征属性量化过程进行处理。未识别情感的话语的量化的提取特征属性用于创建话语特征向量空间。然后,将特征向量空间被输入到执行一个或多个深度学习算法的深度学习机中,该算法被配置为从输入特征向量空间中确定话语中每个话语单元的预测情感和情感强度等级。预测的情感和情感强度等级由人类智能验证(例如,由操作人员手动验证)。
21.未识别情感的话语、其量化的提取特征属性、以及验证的预测情感和情感强度等级被反馈到语音
‑
情感识别分类器或混合分类器,以重新训练其识别模型,并更新训练数据存储库。
附图说明
22.下面参照附图更详细地描述本发明的实施例,其中:
23.图1显示根据本发明各个实施例的用于语音
‑
情感识别的方法的逻辑结构图和数据流图。
24.图2显示根据本发明一个实施例的用于训练语音
‑
情感识别分类器的方法的流程图;
25.图3显示用于训练语音
‑
情感识别分类器的方法的情感评估和评级过程的流程图。
26.图4显示用于训练语音
‑
情感识别分类器的方法的情感状态评级归一化过程流程图。
27.图5显示具有量化属性的提取特征及其相应散列值的一个示例;
28.图6显示根据本发明一个实施例的用于识别运行时语音中的语音情感的方法的流程图。
具体实施方式
29.在以下描述中,作为优选的例子阐述了用于语音
‑
情感识别和量化的装置和方法。
对本领域技术人员来说,显然可以在不偏离本发明的范围和精神的情况下进行修改,包括添加和/或替换。具体细节可以省略,以便不模糊本发明;然而,本公开内容是为了使本领域技术人员能够在不进行过度实验的情况下实践这里的教导。
30.根据本发明的各种实施例,提供了一种基于连续的自我更新和可重新训练的aser机器学习模式的语音
‑
情感识别和量化装置和方法。下面参照图1对本发明作进一步说明。语音
‑
情感识别装置的逻辑执行模块包括:语音接收器(101)、语音
‑
情感识别训练器(102)、训练数据存储库(103)、特征提取器(104)、语音
‑
情感识别分类器(105)、更新模型(106)、识别的语音
‑
情感量化器(107)、以及可选的量化语音
‑
情感可视化器(108)。
31.根据实施例的一种实现方式,所有逻辑执行模块都在单一计算设备中实施,例如智能手机、平板电脑或笔记本计算机、电子信息亭、个人计算机或服务器计算机,这些设备具有:内置或连接的外围麦克风,其为语音接收器(101)提供音频信号接收功能;输入用户界面,例如键盘、指针设备和/或触摸屏,其提供接收用户输入的功能;一个或多个处理器,其被配置为执行语音
‑
情感识别训练器(102)、训练数据存储库(103)、特征提取器(104)、语音
‑
情感识别分类器(105)和更新模型(106)的过程;内置或连接的计算机可读存储介质,其用于训练数据存储库(103)的数据存储功能;以及内置或连接的外围电子显示器,和/或电子视觉指示器如led,为语音
‑
情感可视化器(108)提供输出用户界面、信息显示和用户警报/通知功能。
32.在一个实施例中,用户警报/通知功能的作用是提醒/通知用户检测到某种量化的情感状态(例如,非常生气)的语音
‑
情感,这是预先定义的,作为早期警告。
33.逻辑执行模块还可以使用多个互连的计算设备来实施,例如具有麦克风、输入用户界面和显示器的智能手机,其连接到提供语音
‑
情感识别训练器(102)、训练数据存储库(103)、特征提取器(104)、语音
‑
情感识别分类器(105)和更新模型(106)的一个或多个功能的一个或多个云服务器。
34.训练数据储存库(103)可以被实施为关系数据库(例如,mysql)或平面文件数据库。
35.下面参考图1和2进一步描述本发明。根据本发明的一个方面,使用通过训练数据生成获得的训练数据来训练语音
‑
情感识别分类器(105),包括:由语音接收器(101)获得一个或多个人类语音源输入数据流(201)的一个或多个音频信号及其相关文本;由语音
‑
情感识别训练器(102)在情感评估和评级过程(202)中处理音频信号及其相关文本;由语音
‑
情感识别训练器(102)在情感状态评级归一化过程(203)中对情感评估和评级过程(202)的结果进行归一化处理;由特征提取器(104)在特征提取过程(204)中提取音频信号的特征;由特征提取器(104)在特征属性量化过程(205)中对特征属性进行量化;由特征提取器(104)在特征属性散列过程(206)中对量化的特征属性进行散列;其中,人类语音输入源数据流可以是但不限于现实生活中人与人之间的正常对话和争吵、日常用语、新闻报道、辩论和正式演讲的音轨或音频记录。
36.在一个实施例中,语音
‑
情感识别分类器(105)是基于一个或多个支持向量机(svm)来实施的。在另一实施例中,语音
‑
情感识别分类器是基于具有局部敏感散列(lsh)的一个或多个svm实施的混合分类器。本领域技术人员可能在语音
‑
情感识别分类器和/或混合分类器的实施中采用其他机器学习算法和技术,而无需过度实验或偏离本发明的精神。
37.下面参考图2和图3进一步描述本发明。在一个实施例中,情感评估和评级过程(202)包括:通过一个人口样本组来感知人类语音输入源数据流(301)中的每个音频信号(话语)及其相关文本,该人口样本组是根据具有相似文化背景的个人对话语(utterance)的掌握和理解来选择的,该具有相似文化背景的个人的选取标准包括但不限于性别、年龄范围、职业和教育水平的一项或多项标准;通过该人口样本组,将话语中每个话语单元(例如,字符、单词或短语)的情感分配到其中一个情感类别中(例如,爱、喜悦、惊讶、愤怒、悲伤、恐惧、中性等)(302);通过该人口样本组,根据话语的声学(包括音调)、词汇、语言特征和语义内容,对每个话语单元的情感强度等级进行评级,以确定其情感状态(例如
…
、
‑
3、
‑
2、
‑
1、0、+1、+2、+3、
…
等)(303)。情感评估和评级过程背后的基本原理是,语音
‑
情感是由一群人拥有和共享的集体认知,本发明通过确保训练数据由自然和自发的语音(speech)产生,解决现有数据库包含人工表演和静态语音的缺点。
38.下面参考图2和图4进一步描述本发明。在一个实施例中,情感状态评级归一化过程(203)包括:获取每个话语的情感分配分布和评级分布(401);剔除情感分配分布中的奇异(singular)和极端情感分配以及评级分布中的奇异和极端评级值(402);根据小组的大多数情感分配,确定每个话语单元的归一化情感分配,并根据剔除后的小组的分布密度或平均评级值,确定每个话语单元的情感强度等级的归一化评级值(403)。
39.在一个实施例中,特征提取过程(204)从每个音频信号(话语)中提取一个或多个特征,其特征属性包括但不限于话语中每个单独话语单元(例如,字符、单词或短语)的音高、音调、声音长度、响度、基本频率和语义串中的一个或多个、频率
‑
时间表示、语音振幅方差、话语单元节奏的语音方差、过零率、基本估算及其推导、音频信号的频谱分布、语音中浊音与清音信号的比率、以及话语的语音韵律。上述特征属性列表并非详尽无遗。本领域技术人员将理解,其他实施例可以包括对其他特征和特征属性的提取和处理,而无需过多的实验和偏离本发明的精神。此外,对aser机器学习模型的个性化,例如不同的语言和文化、不同的社会环境、不同的设备实施(例如,具有有限计算资源的独立的移动计算设备、高性能服务器等),可以通过调整被提取和处理的特征和特征属性、调整情感评估和评级、和/或使用自己的语音作为训练语音
‑
情感识别分类器的源输入,使之成为可能。
40.然后特征提取过程之后是特征量化过程(205),其中所提取的特征属性用标签、标记和加权进行量化,其值在可测量的尺度下分配。图5显示了一个带有量化属性(501)的提取特征的例子,其中“狗”代表提取的特征之一(话语中的一个词),“音高”、“音调”、“频率”等是其中一些量化的属性。
41.然后在特征属性散列过程(206)中对提取的特征及其量化属性进行散列(hash)。图5显示了一个具有量化属性(501)及其对应散列值(502)的提取特征的例子。在使用带有lsh混合分类器的svm的语音
‑
情感识别的实施例中,提取的特征及其量化属性通过使用lsh算法的特征属性散列过程(206)进行散列,以获得每个量化提取特征属性的散列值(hash value)。然后,量化提取特征属性的散列值用于形成代表相应提取特征的特征向量,提取的话语特征的特征向量形成话语的特征向量空间。
42.归一化的分配的情感和情感强度等级,以及具有各自音频信号的量化属性的提取特征,构成用于训练和测试识别模型(105a)和语音
‑
情感识别分类器(105)的训练数据。在语音
‑
情感识别使用一个具有lsh的svm作为混合分类器的实施例中,识别模型和混合分类
器的训练还包括在混合分类器中形成一个lsh协同模型,其特征向量的特征向量空间是从提取的特征的散列值以及每个音频信号的特征向量的一个或多个搜索索引中获得的。
43.根据本发明的另一方面,分配的情感和情感强度等级、具有量化属性的提取特征、以及各个音频信号的提取特征的散列值,被存储在训练数据存储库(103)中,以在其他语音
‑
情感识别系统中重复使用。
44.在运行时,语音
‑
情感识别装置被配置为执行根据本发明实施例的运行方法,以识别具有一个或多个音频信号(话语)的实时语音的语音情感。
45.下面参照图6对本发明作进一步说明。根据本发明的另一方面,该运行时语音
‑
情感识别方法包括:由语音接收器(101)接收实时语音的音频信号(话语)(601);由特征提取器(104)从每个话语中提取一个或多个具有特征属性的特征,包括话语中每个单独话语单元(例如,字符、单词或短语)的音高、音调、声音长度、响度、基本频率和语义串中的一个或多个、频率
‑
时间表示、语音振幅方差、话语单元节奏的语音方差、过零率、基本估算及其推导、音频信号的频谱分布、语音中浊音与清音信号的比率、以及话语的语音韵律(602);由经过训练的分类器(105)对话语进行分类(603),包括:对提取的特征属性进行量化(603a);在训练分类器(105)的特征向量空间中搜索和匹配量化的提取特征属性,以获得每个话语单元的识别情感和情感强度等级(603b);对于已识别出其话语单元的情感和情感强度等级的话语,由识别语音
‑
情感量化器(107),从识别的话语单元的情感和情感强度等级、以及量化的提取特征属性,计算话语的量化情感状态(例如,有点生气、非常生气、或超级生气)(604);对于已识别出其情感的话语,由语音
‑
情感可视化器(108)以文本、图形(例如,图形均衡器)和/或其他数字格式将话语的量化情感状态进行可视化(605);以及在无法识别话语的情感的情况下,触发更新模型(106)(606)。
46.随着时间的推移和使用,经过训练的语音
‑
情感识别分类器(105)可能会遇到由于例如语言变化产生新词和短语而无法识别的具有情感的话语。无法识别的情感话语要么是具有无法提取和/或量化的特征和特征属性的话语(未标记数据),要么是具有无法匹配的量化提取的特征属性的话语。在持续的自我更新和可重新训练的aser机器学习模型下,未识别的情感话语以及量化的提取特征属性(如果有的话),被输入到更新模型(106)。
47.在更新模型(106)中,带有未标记数据的未识别的情感话语首先通过上述特征提取过程和特征属性量化过程进行处理,以获得其量化的提取特征属性。在另一个实施例中,带有未标记数据的未识别的情感话语首先由人类智能进行标记(例如,手动标记未标记数据),然后由上述特征提取过程和特征属性量化过程进行处理。未识别的情感话语的提取特征和它们各自的量化提取特征属性,用于创建该话语的特征向量空间。然后将特征向量空间输入到更新模型(106)的深度学习机(106a),执行一个或多个深度学习算法,该算法被配置为从输入的特征向量空间确定每个话语单元的预测情感和情感强度等级。预测的情感和情感强度等级由人类智能验证(例如,由操作人员手动验证)。
48.深度学习机(106a)可以由卷积神经网络(cnn)和循环神经网络(rnn)中的一个或多个来实现。本领域技术人员可以采用其他深度学习机器实现方式,而无需过度实验或偏离本发明的精神。
49.提取的特征及其各自量化的提取特征属性、经验证的话语单元的预测的情感和情感强度等级被反馈给语音
‑
情感识别分类器(105),以重新训练其识别模型(105a),并更新
识别模型数据库和训练数据存储库(103)。
50.根据一个实施例,话语的量化情感状态的计算(604)包括:将识别的话语单元的情感和情感强度等级,以及量化的提取特征属性按各自的权重进行融合。
51.本公开的全部或部分实施例可以使用一个或多个特别配置的计算设备、计算机处理器或电子电路来实现,包括但不限于图形处理单元(gpu)、专用集成电路(asic)、现场可编程门阵列(fpga)、以及根据本公开的教导配置或编程的其他可编程逻辑器件。基于本公开的教导,软件或电子领域的技术人员可以容易地准备在计算设备、计算机处理器或可编程逻辑设备中运行的计算机指令或代码。上述一个或多个计算设备可以包括服务器计算机、个人计算机、笔记本电脑、移动计算设备如智能手机和平板电脑中的一个或多个。
52.电子实施例包括其中存储有计算机指令或代码的计算机可读存储介质,其可用于配置或编程计算设备、计算机处理器或电子电路以执行本发明的任何过程;以及存储由本发明的任何过程产生的数据。计算机可读存储介质包括但不限于软盘、光盘、蓝光光盘、dvd、cd
‑
rom、磁光盘、固态盘、rom、ram、sram、dram、闪存存储设备、电可编程只读存储器(eprom)、电可擦除可编程只读存储器(eeprom)或适合存储指令、代码和/或数据的任何类型的介质或设备。
53.本发明的各种实施例还可以在分布式计算环境和/或云计算环境中实施,其中计算机指令或代码的全部或部分由通过通信网络互连的一个或多个处理设备以分布式方式执行,通信网络包括例如内部网、广域网(wan)、局域网(lan)、互联网和其他形式的数据传输介质。
54.本发明的上述描述是为了说明和描述的目的而提供的。并不打算详尽无遗或将本发明限制在所公开的精确形式上。许多修改和变化对于本领域技术人员来说都是显而易见的。
55.选择的和描述的实施例是为了最好地解释本发明的原理及其实际应用,从而使本领域的其他技术人员能够理解本发明的各种实施例和适合于所设想的特定用途的各种修改。