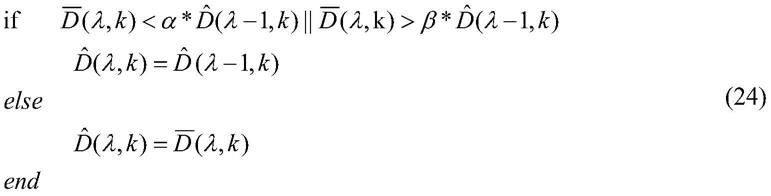
1.本发明属于噪声估计领域,具体涉及一种带噪语音的噪声估计方法和装置。
背景技术:
2.语音在是人与人之间传递信息最常用的方式。随着技术的发展,语音也被应用在许多方面,例如声纹识别可以用于解锁电子设备,语音内容识别可以用于控制智能家居,辅助输入法的输入。
3.在实际生活环境中,环境噪声会对语音产生严重影响。嘈杂的噪声会降低语音的可懂度,长时间置身于噪声环境中会使人感到压力和听觉疲劳。对于设备而言,噪声会干扰语音信号的采集与识别,影响设备的性能。
4.因为噪声对语音的影响极大,所以对降噪算法的研究就非常有意义,而降噪首先就需要对噪声的强度进行估计,噪声估计得越及时和准确,降噪效果就会越好。
技术实现要素:
5.本发明提供一种带噪语音的噪声估计方法和装置,对带噪语音中的噪声进行准确估计。为实现上述技术目的,本发明采用如下技术方案:
6.一种带噪语音的噪声估计方法,包括:
7.使用mcra算法对音频数据中的噪声进行初步估计;
8.利用初步估计的噪声计算音频数据的对数似然比特征,利用对数似然比特征和能熵比特征计算语音存在的先验概率,采用贝叶斯算法计算语音存在的后验概率;
9.根据语音存在的后验概率并使用递归平均算法估计噪声;
10.对噪声的波动进行控制,得到音频数据中最终估计的噪声。
11.进一步地,利用初步估计的噪声计算对数似然比特征的方法为:
12.(a1)将带噪语音表示为fft频域的幅度y(λ,k),初步估计得到的噪声为d
mcra
(λ,k),λ代表帧数,k代表频点;
13.(a2)通过计算先验信噪比ξ(λ,k)和后验信噪比γ(λ,k)计算似然比λ(λ,k),所述似然比表示一帧音频数据符合带噪语音信号分布的概率与符合噪声信号分布的概率的比值;
14.(a3)对(a2)计算得到的似然比取对数和进行前后帧平滑,得到平滑后的对数似然比loglrt(λ,k);
15.(a4)对平滑后的对数似然比在所有频点上取平均,得到当前帧音频的对数似然比特征lrtfeature(λ),简记为lrtfeature。
16.进一步地,用于计算语音存在先验概率的能熵比特征,其计算方法为:
17.(b1)利用幅度谱计算当前帧的能量e(λ),再计算对数能量le(λ):
18.19.le(λ)=ln(e(λ)+a)
‑
ln(a)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
20.其中,a为固定常数;
21.(b2)将每帧音频数据频带划分为n
b
个子带,分别记为:
22.(b3)求每个子带的子带谱及其概率,进而计算子带谱熵:
[0023][0024][0025][0026]
式中,e
b
(λ,m)为第λ帧音频数据的第m个子带的子带谱,m=1,2,
…
,n
b
;p
b
(λ,m)为子带谱e
b
(λ,m)对应的概率,h
b
(λ)为第λ帧音频数据的子带谱熵;
[0027]
(b4)根据子带谱熵计算子带能熵比:
[0028][0029]
(b5)对子带能熵比进行前后帧平滑,得到子带能熵比特征ehfeature(λ),简记为ehfeature。
[0030]
进一步地,所述利用对数似然比特征和能熵比特征计算语音存在的先验概率,具体计算方法为:
[0031]
(c1)根据对数似然比特征lrtfeature、子带能熵比特征ehfeature以及预先确定的似然比阈值threshlrt和能熵比阈值thresheh,分别计算基于似然比的概率problrt和基于能熵比的概率probeh:
[0032]
如果lrtfeature>threshlrt,则probeh=0.5*(tanh(k0*(ehfeature
‑
thresheh))+1),problrt=0.5*(tanh(k0*(lrtfeature
‑
threshlrt))+1);
[0033]
如果lrtfeature≤threshlrt,则probeh=0.5*(tanh(k1*(ehfeature
‑
thresheh))+1),problrt=0.5*(tanh(k1*(lrtfeature
‑
threshlrt))+1);
[0034]
其中,k0和k1为斜率系数,且k1>k0,设置原则是使得映射到的概率problrt和probeh的覆盖范围为[0,1];
[0035]
(c2)对基于似然比的概率problrt和基于能熵比的概率probeh进行融合,再使用得到的融合概率对前一帧音频数据中语音存在的先验概率进行平滑处理,得到当前帧音频数据中任意频点存在语音的先验概率p(h1);先验概率的平滑公式为:
[0036]
p(h1)=(1
‑
probtavg)*p
prev
(h1)+probtavg*tmpprob
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17)
[0037]
其中,p(h1)为当前帧音频数据中语音存在的先验概率,p
prev
(h1)表示前一帧音频数据中语音存在的先验概率;probtavg为平滑系数,tmpprob为融合概率。
[0038]
进一步地,对基于似然比的概率problrt和基于能熵比的概率probeh进行融合的方法为:
[0039]
(d1)将每hnfames帧作为一个统计周期进行直方图统计:将子带能熵比特征的覆
盖范围均分为若干个bin,每个bin的宽度为binsizeeh;判断当前统计周期内每帧音频数据的子带能熵比特征落在哪个bin内,则该bin的高度加1;
[0040]
(d2)寻找直方图中高度最高和第二高的bin,最高bin的位置和高度分别记为p1、h1,第二高bin的位置和高度分别记为p2、h2;再按以下判断方法对中间参数p和h进行定义:
[0041]
如果p1与p2相邻,且h1<2*h2,则p=(p1+p2)/2,h=h1+h2;
[0042]
如果p1与p2之间相差一个bin,将p1与p2之间的bin的高度记为h3,再判断是否满足h1<2*h2且h1<2*h3,若满足则p=(p1+p2)/2,h=h1+h2+h3;
[0043]
否则p=p1,h=h1;
[0044]
(d3)根据中间参数p确定能熵比阈值thresheh=δ*p,δ为能熵比阈值系数;
[0045]
(d4)如果h<eh_frames_factor*hnframes,则tmpprob=problrt,tmpprob为融合概率,eh_frames_factor表示一个无量纲的尺度系数;否则tmpprob=0.5*(problrt+probeh)。
[0046]
进一步地,似然比阈值的预先确定方法为:
[0047]
(e1)将每hnfames帧作为一个统计周期进行直方图统计:将对数似然比特征的覆盖范围均分为若干个bin,每个bin的宽度为binsizelrt;判断当前统计周期内每帧音频数据的对数似然比特征落在哪个bin内,则该bin的高度加1;
[0048]
(e2)如果最高的bin的高度大于hnfames的一半,则给似然比阈值赋值为threshlrt=binsizelrt;否则,对所有对数似然比特征进行加权平均,再乘以大于1的系数作为似然比阈值threshlrt。
[0049]
进一步地,所述采用贝叶斯算法计算语音存在的后验概率的方法为:
[0050][0051]
式中,表示音频数据在频点k存在语音的后验概率,λ(λ,k)为似然比,中间变量比,中间变量和分别表示音频数据在频点k存在语音和不存在语音,和分别表示音频数据在频点k存在语音的概率和不存在语音的概率,且分别表示音频数据在频点k存在语音的概率和不存在语音的概率,且
[0052]
进一步地,所述根据语音存在的后验概率并使用递归平均算法估计噪声的方法为:
[0053][0054]
式中,d(λ,k)表示使用递归平均算法对第λ帧音频数据在频点k估计出的噪声,和分别表示音频数据在频点k存在语音和不存在语音,表示音频数据在频点k存在语音的后验概率,表示音频数据在频点k不存在语音的后验概率,代表第λ
‑
1帧音频数据在频点k估计出的噪声,y(λ,k)为第λ帧音频数据在频点k的幅度。
[0055]
进一步地,所述对噪声的波动进行控制的方法为:
[0056]
(f1)根据语音存在的后验概率对使用递归平均算法估计得到的噪声d(λ,k)进行平滑处理:
[0057]
若则否则其中factornoise和factorspeech为平滑系数;
[0058]
(f2)然后对平滑后的噪声进行幅度控制,得到最终估计的噪声
[0059]
若或者则否则其中α和β为幅度控制系数。
[0060]
一种带噪语音的噪声估计装置,包括:噪声初步估计模块、语音存在概率估计模块、噪声二次估计模块和噪声波动控制模块;
[0061]
所述噪声初步估计模块用于:使用mcra算法对音频数据中的噪声进行初步估计;
[0062]
所述语音存在概率估计模块用于:利用初步估计的噪声计算音频数据的对数似然比特征,利用对数似然比特征和能熵比特征计算语音存在的先验概率,采用贝叶斯算法计算语音存在的后验概率;
[0063]
所述噪声二次估计模块用于:根据语音存在的后验概率并使用递归平均算法估计噪声;
[0064]
所述噪声波动控制模块用于:对噪声的波动进行控制,得到音频数据中最终估计的噪声。
[0065]
有益效果
[0066]
本发明利用对数似然比和子带能熵比来计算语音存在的先验概率,继而使用贝叶斯公式得到语音存在的后验概率,最后使用递归平均算法估计噪声。和最小值控制的递归平均
[1]
(minima controlled recursive averaging,mcra)算法相比,语音存在概率更加准确,能覆盖从0到1的大部分概率,而不仅仅是一个近似二值化的概率,得到的噪声估计也更加准确。通过对噪声的变化幅度进行控制,可以有效降低噪声过估计的发生。
附图说明
[0067]
图1是本技术实施例所述方法的流程图;
[0068]
图2是带噪语音的时域图;
[0069]
图3是对数似然比及其阈值,其中实线表示对数似然比特征,虚线表示阈值;
[0070]
图4是能熵比特征及其阈值,其中实线代表能熵比特征,虚线代表阈值;
[0071]
图5是语音存在先验概率分布图;
[0072]
图6是语音存在概率对比图;
[0073]
图7是噪声估计对比图,其中实线表示实际噪声,点线表示mcra算法估计的噪声,虚线表示本方案估计的噪声。
具体实施方式
[0074]
下面对本发明的实施例作详细说明,本实施例以本发明的技术方案为依据开展,给出了详细的实施方式和具体的操作过程,对本发明的技术方案作进一步解释说明。
[0075]
本发明提供一种带噪语音的噪声估计方法,参考图1所示,包括:使用mcra算法对音频数据中的噪声进行初步估计,利用初步估计的噪声计算音频数据的似然比和对数似然比特征,利用对数似然比特征和能熵比特征计算语音存在的先验概率,采用贝叶斯算法计算语音存在的后验概率,根据语音存在的后验概率并使用递归平均算法估计噪声,最终对估计的噪声的波动进行控制,得到音频数据中最终估计的噪声。
[0076]
(1)mcra初步估计噪声前的预处理
[0077]
在使用mcra算法对音频数据中的噪声进行初步估计之前,定义带噪语音信号为音频信号,对音频信号进行预处理:对于一帧长度为l的带噪语音信号x(n),n=1,2,3,....l进行长度为n的快速傅里叶变换,然后求幅度谱,记为y(λ,k),λ代表帧数,k代表频点,k=1,2,....n/2+1。然后使用现有的mcra算法对音频信号中的噪声进行初步估计,得到噪声记为d
mcra
(λ,k)。
[0078]
(2)似然比和对数似然比特征
[0079]
(2.1)计算先验信噪比ξ(λ,k),公式为:
[0080][0081]
其中,α为固定的系数,为第λ
‑
1帧带噪语音估计出的语音幅度,代表第λ
‑
1帧带噪语音估计出的噪声,y(λ,k)为第λ帧带噪语音的幅度;
[0082]
(2.2)利用先验信噪比和后验信噪比计算似然比λ(λ,k)
[0083][0084]
其中,后验信噪比的计算公式为:
[0085][0086]
(2.3)利用似然比计算对数似然比特征
[0087]
首先,将似然比取对数,得到当前帧的对数似然比loglrttmp:
[0088]
loglrttmp(λ,k)=ln(λ(λ,k))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0089]
然后,对当前帧的对数似然比进行前后帧平滑,得到平滑后的对数似然比loglrt:
[0090]
loglrt(λ,k)=(1
‑
lrttavg)*loglrt(λ
‑
1,k)+lrttavg*loglrttmp(λ,k)
ꢀꢀꢀꢀꢀ
(5)
[0091]
其中,平滑系数lrttavg可取0.3到0.5。
[0092]
最后,对平滑后的对数似然比在所有频点上取平均,得到当前帧的对数似然比特征lrtfeature(λ),后文为了方便书写,又记为lrtfeature。
[0093][0094]
(3)子带能熵比特征
[0095]
(3.1)计算短时对数能量。
[0096]
首先利用幅度谱计算当前帧的能量e(λ),公式如下:
[0097][0098]
然后计算对数能量le(λ),公式如下:
[0099]
le(λ)=ln(e(λ)+a)
‑
ln(a)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0100]
其中,a为固定的值,取值为105到109,本方案取值为106。
[0101]
(3.2)计算子带谱熵
[0102]
对频带进行均匀的子带划分,个数为n
b
,各个子带分别记为:
[0103]
求每个子带的子带谱,第m个子带的子带谱公式如下:
[0104][0105]
计算每个子带谱对应的概率:
[0106][0107]
子带谱熵的计算公式如下:
[0108][0109]
(3.3)计算子带能熵比eh(λ),公式如下:
[0110][0111]
对子带能熵比进行前后帧平滑就得到能熵比特征,公式如下:
[0112]
ehfeature(λ)=(1
‑
ehtavg)*ehfeature(λ
‑
1)+ehtavg*eh(λ)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0113]
其中,ehtavg为平滑系数,取值范围为0.3到0.5,典型值可以取0.3。后文为了方便,将能熵比特征简写为ehfeature。
[0114]
(4)计算先验概率
[0115]
(4.1)预先确定似然比阈值threshlrt
[0116]
将每hnfames帧作为一个统计周期进行直方图统计:将对数似然比特征的覆盖范围均分为若干个bin,每个bin的宽度为binsizelrt;判断当前统计周期内每帧音频数据的对数似然比特征落在哪个bin内,则该bin的高度加1;
[0117]
如果最高的bin的高度大于hnfames的一半,则给似然比阈值赋值为threshlrt=binsizelrt;否则,对所有对数似然比特征进行加权平均,再乘以大于1的系数作为似然比阈值threshlrt。
[0118]
(4.2)预先确定似然比阈值thresheh
[0119]
(d1)将每hnfames帧作为一个统计周期进行直方图统计:将子带能熵比特征的覆盖范围均分为若干个bin,每个bin的宽度为binsizeeh;判断当前统计周期内每帧音频数据的子带能熵比特征落在哪个bin内,则该bin的高度加1;
[0120]
(d2)寻找直方图中高度最高和第二高的bin,最高bin的位置和高度分别记为p1、h1,第二高bin的位置和高度分别记为p2、h2;再按以下判断方法对中间参数p和h进行定义:
[0121]
如果p1与p2相邻,且h1<2*h2,则p=(p1+p2)/2,h=h1+h2;
[0122]
如果p1与p2之间相差一个bin,将p1与p2之间的bin的高度记为h3,再判断是否满足h1<2*h2且h1<2*h3,若满足则p=(p1+p2)/2,h=h1+h2+h3;
[0123]
否则p=p1,h=h1;
[0124]
上述p值代表了最常出现的能熵比,应该是噪声的能熵比,因此,将p乘以一个系数作为阈值,记为thresheh。系数可以控制在1.05
‑
1.1中间,典型值可以取1.05。
[0125]
(d3)根据中间参数p确定能熵比阈值thresheh=δ*p,δ为能熵比阈值系数;
[0126]
(4.3)根据对数似然比特征lrtfeature、子带能熵比特征ehfeature以及预先确定的似然比阈值threshlrt和能熵比阈值thresheh,分别计算基于似然比的概率problrt和基于能熵比的概率probeh:
[0127][0128]
其中,k0和k1为斜率系数,且k1>k0,设置原则是使得映射到的概率problrt和probeh能覆盖0和1之间的大部分值。k0可以设为4,k1设为12。
[0129]
(4.4)对基于似然比的概率problrt和基于能熵比的概率probeh进行融合,再使用得到的融合概率对语音存在的先验概率进行平滑处理,得到音频数据中任意频点存在语音的先验概率p(h1):
[0130]
其中融合方法为:如果h<eh_frames_factor*hnframes,则不使用能熵比特征,只使用似然比一个特征,因此直接将基于似然比的概率作为融合概率tmpprob:
[0131]
tmpprob=problrt
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(15)
[0132]
其中eh_frames_factor表示一个无量纲的尺度系数,取值范围为0.15到0.3,典型值可以取0.2。
[0133]
否则,即h≥eh_frames_factor*hnframes,使用problrt和probeh加权融合融合概率tmpprob:
[0134]
tmpprob=0.5*(problrt+probeh)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(16)
[0135]
然后对先验概率进行前后帧的平滑,最后将概率控制在0.01到1之间,先验概率的平滑公式为:
[0136]
p(h1)=(1
‑
probtavg)*p
prev
(h1)+probtavg*tmpprob
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17)
[0137]
其中,p(h1)为当前信号帧语音存在的先验概率,p
prev
(h1)表示前一信号帧语音存在的先验概率;probtavg为平滑系数,取值范围为0.1
‑
0.2,典型值可以取0.15。
[0138]
(5)后验概率和噪声估计
[0139]
在得到语音存在的先验概率后,就可以使用贝叶斯公式计算后验概率,然后使用
递归平均算法估计噪声,过程如下所示:
[0140]
使用假设检验来判断某个频点语音是否存在,假设如下:
[0141]
频点k语音不存在;频点k语音存在。
[0142]
(5.1)每一帧,每个频点的语音存在和不存在的先验概率,分别记为:和在计算过程中,同一帧内所有频点的语音存在先验概率都是一样的。即
[0143][0144]
令:
[0145][0146]
(5.2)通过如下公式计算似然比λ(λ,k),和语音存在的后验概率其中λ表示帧数,k表示频点。ξ(λ,k)为先验信噪比,γ(λ,k)为后验信噪比
[0147][0148][0149]
(5.3)通过全概率公式估算噪声d(λ,k)。其中表示上一帧的噪声幅度,y(λ,k)表示当前帧的带噪语音幅度。
[0150][0151]
(6)噪声波动控制
[0152]
使用基于概率的递归平均算法得到估计的噪声后,为了防止噪声波动太大或者过估计,需要控制当前帧噪声相对于上一帧噪声的增加和降低的幅度,具体方式为:
[0153]
(6.1)先对噪声进行平滑,根据后验概率的不同,使用不同的公式进平滑:
[0154][0155]
其中factornoise和factorspeech为平滑系数;factornoise取值为0.85到0.95,典型值为0.95。factorspeech取值为0.9到0.999,典型值为0.99。
[0156]
(6.2)然后对平滑后的噪声进行幅度控制,得到最终估计的噪声
[0157][0158]
其中,其中α和β为幅度控制系数,α取值范围为0.7到0.95,β的取值范围为1.05到1.3。本方案取的α为0.85,β为1.15。
[0159]
按照上述本发明对噪声的波动进行控制后,就能得到较为准确的噪声估计。利用估计的噪声,就可以使用各种语音增强方法对带噪语音进行降噪处理,如谱减法或者维纳滤波法。
[0160]
实施例:
[0161]
本实施例利用能熵比特征计算语音先验概率的具体实现过程如下所示:
[0162]
(1)对于采样率为16k的带噪语音信号进行分帧,加窗。其中帧长为320个采样点,帧叠为50%,窗函数采用汉明窗。分帧加窗后得到的一帧数据记为x(n),n=1,2,....320。
[0163]
(2)对x(n)进行长度为1024个点的快速傅里叶变换,然后求绝对值,得到幅度谱y(λ,k),k=0,1,2,....512。
[0164]
(3)基于幅度谱y(λ,k)使用mcra算法对噪声进行估计。
[0165]
(4)使用公式(1)计算先验信噪比,其中初始语音幅度设为0。
[0166]
(5)使用公式(2)和(3)计算似然比。
[0167]
(6)使用公式(4),(5)和(6)计算对数似然比特征lrtfeature。
[0168]
(7)使用公式(7)计算能量,然后使用公式(8)计算对数能量。
[0169]
(8)将幅度谱y(λ,k)去掉直流频点,按频点均匀分成16个子带,记为其中:
[0170]
b1={y(λ,1),y(λ,2),....y(λ,32)},
[0171]
b2={y(λ,33),y(λ,34),....y(λ,64)},
[0172]
...
[0173]
b
16
={y(λ,481),y(λ,482),....y(λ,512)}
[0174]
(9)使用公式(9)和公式(10)计算每个子带对应的频率,使用公式(11)计算子带谱熵比。
[0175]
(10)使用公式(12)和(13)计算得到能熵比特征ehfeature。
[0176]
(11)统计对数似然比特征直方图和能熵比特征直方图,500帧重置一次。
[0177]
(12)达到500帧时,更新对数似然比阈值和能熵比阈值,重置特征直方图。
[0178]
(13)判断能熵比特征是否可用。
[0179]
(14)使用公式(14)计算两种特征对应的语音存在概率。
[0180]
(15)如果能熵比特征不可用,使用公式(15)和(17)计算语音存在的先验概率;如果能熵比特征可用,使用公式(16)和(17)计算语音存在的先验概率。
[0181]
(16)使用公式(18)和(19)计算中间变量r,使用公式(20)和(21)计算语音存在的后验概率。
[0182]
(17)使用递归平均算法的噪声估计公式(22)估计噪声。
[0183]
(18)使用公式(23)和(24)对噪声进行平滑和波动控制,得到最终的噪声。
[0184]
为了验证本方案的有效性,首先将babble噪声和纯净语音进行融合,得到带噪语音。然后使用本方案对带噪语音进行噪声估计。最后,将本方案估计的噪声,mcra算法估计的噪声以及实际噪声对比,并对结果进行分析与讨论。本方案噪声估计的关键结果展示如图2至7所示。
[0185]
其中,图3图4是对数似然比特征和能熵比特征,其中的虚线代表了阈值。如果某一帧的特征在阈值之上,则便是基于该特征的语音存在概率大于0.5。值越大,语音存在概率也越大。将图3、4和图2进行比较,可以发现,在语音存在部分,特征基本都是大于阈值的。这说明了特征的有效性。对基于似然比特征的概率和能熵比的概率进行融合,得到图5的语音存在先验概率,从中能明显地区分语音帧和非语音帧。因此语音存在的概率计算是有效的。
[0186]
在图6中,最上面一幅图是带噪语音的时域图,中间是本方案得到的在频点500hz的语音存在后验概率,最下面是mcra算法得到的500hz的语音存在概率。首先可以看出,mcra算法得到的语音存在概率基本都二值化,大部分是0和1。而本方案得到的语音存在概率还包含许多0和1之间的值,使用概率时会更加灵活。其次,通过与时域图比较可以发现,本方案得到的概率更加准确,如3.5s
‑
4s和6.5s
‑
7s中是不存在语音的,但mcra算法得到的语音存在概率却是1,本方案得到概率是0;在4.2s
‑
5s和7.2s
‑
8s中语音是有停顿的,mcra算法计算出的语音存在概率都是1,而本方案计算的语音存在概率在语音停顿处都非常低,且和时域图非常的吻合。因此相对于mcra算法,本方案得到的语音存在概率更加的准确。
[0187]
图7是500hz处的实际噪声,mcra估计噪声和本方案估计噪声的对比图。从整体上看,mcra得到的噪声比较平滑,波动比较小,不能很好的反应babble噪声的变化,这也是概率二值化造成的结果。从局部上看,在3.5s
‑
4s和6.5s
‑
7s,本方案估计的噪声有一个明显的增加,和实际噪声的变化较为接近,而mcra算法估计的噪声并没有变化。因此,相对于mcra算法,本方案估计的噪声更加准确。
[0188]
综上所述,本方案通过对数似然比特征和能熵比特征来计算语音存在概率,得到的概率更加准确,估计出来的噪声更能反应实际噪声的变化,更加及时和准确。
[0189]
以上实施例为本技术的优选实施例,本领域的普通技术人员还可以在此基础上进行各种变换或改进,在不脱离本技术总的构思的前提下,这些变换或改进都应当属于本技术要求保护的范围之内。