一种基于对抗迁移和frobenius范数的跨库语音情感识别方法
技术领域
1.本发明属于语音信号处理技术领域,具体涉及到一种基于对抗迁移和frobenius范数的跨库语音情感识别方法。
背景技术:
2.言语是人类表达情感最为自然的方式,近年来,语音情感识别领域得到了越来越广泛的关注,其应用价值也在众多人机交互应用中被证明,例如,心理健康诊断、移动交互、车载安全系统和自动翻译系统。经典语音情感识别系统首先从语音信号中提取语言和声学特征,然后在这些特征上进行分类以预测说话者的情绪。
3.随着深度学习的迅猛发展,研究人员提出了许多性能优异的语音情感识别方法,然而,大部分算法在开发时没有考虑到训练和测试语言信号来自不同语料库的问题。在这种情况下,训练数据和测试数据之间可能存在较大的特征分布差异,从而导致语音情感识别系统的性能迅速下降。因此,在当前的语音情感识别研究中,如何有效的实现跨库语音情感识别是一个重要且极具挑战性的问题。
4.迁移学习被提出用于知识迁移,将源域学习到的知识扩展到目标域,以在目标域上获得较好的学习效果,当目标域中无法获得大量带标签的数据来对模型进行训练时,可以通过训练与目标域数据相关的源域数据(带标签)来构建模型,然后采用特征分布对齐等域自适应方法,建立源域和目标域之间的联系,增强模型的泛化性,从而实现跨域语音情感识别。
5.因此,本发明主要关注如何解决跨库语音情感识别任务中的特征分布差异问题,进一步提高跨库语音情感识别效果,目标域和源域的数据之间存在特征分布差异。因此采用对抗域自适应的方法,减小域间特征分布差异,提出frobenius范数最大化的方法,在保证预测准确性的前提下增强模型预测的多样性,进一步提高了跨库语音情感识别的性能。
技术实现要素:
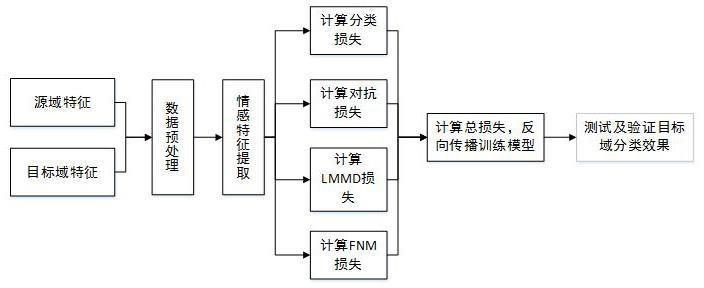
6.为了解决不同语料数据库之间特征分布差异的问题,更好地将带标记源域数据的知识迁移到无标记目标域,实现无标记数据的准确分类,提出了一种基于对抗迁移和frobenius范数的跨库语音情感识别方法。具体步骤如下:
7.(1)数据库:选取两个语音情感数据库,并挑选出它们相同情感类别的语音数据,分别作为源域数据库和目标域数据库,对两个语音库的语音信息制作对应的情感数字标签,然后对得到的源域和目标域的语音信号进行预加重、分帧和加窗等处理;
8.(2)特征提取:对步骤(1)预处理过的语音信号进行声学特征提取,该特征包括但不限于韵律特征、谱相关特征和质量特征;
9.(3)特征对抗学习:将步骤(2)所提取的情感特征x
i
输入对抗网络中的生成网络,利用对抗的方式训练域鉴别器和特征生成网络,当域鉴别器无法判断实例来自目标域还是
(6)的动态权重因子,直至模型最优;
27.(8)利用步骤(6)训练好的网络模型,使用sofmatx分类器预测步骤(4)中的目标域特征标签,最终实现语音情感在跨语料库条件下的情感识别。
附图说明
28.如附图所示,图1为一种基于对抗迁移和frobenius范数的跨库语音情感识别方法的框架图。
具体实施方式
29.下面结合具体实施方式对本发明做更进一步的说明。
30.(1)选择savee语音情感数据库和enterface数据库分别作为源域和目标域的数据库。
31.(2)选择上述两个语料库的5类相同情感语音作为数据集。
32.(3)使用开源工具包opensmile按照权利要求书1的步骤(3)中提取2009年国际语音情感识别挑战赛的标准特征集,每条语音提取出的特征都为384维。因此savee数据库共有300条语音,数据总量为300*384;enterface数据库的共有1072条语音,数据总量为1072*384。
33.(4)使用对抗网络来学习源域和目标域的域不变特征。对于生成网络的隐层数量为3,每层网络由1d
‑
cnn组成,其中每层过滤器数量设置为{50,100,150},另外在每层结构加入batchnorm层和dropout层,激活函数使用relu函数;鉴别器网络使用两层fc结构组成。
34.(5)在局部最大均值误差中,计算特征权重时,由于目标域特征是没有标签信息的,需要使用softmax计算的概率分布作为目标域的标签,即为伪标签;而源域特征使用的是真实标签。所有的标签信息需要转化成one
‑
hot向量。特征映射函数使用多核高斯函数,高斯核数量设置为5。
35.(6)将特征生成网络提取到的目标域特征进行softmax处理后,得到一个批次的预测概率矩阵,对预测概率矩阵p进行frobenius范数最大化处理,以保证模型的预测准确性,针对这种方法带来的模糊样本误判,使用输出的预测概率矩阵p构造样本间距度量矩阵d,对矩阵d进行frobenius范数最大化操作,可以有效的增加预测样本的间距,因此在不影响分类性能的前提下,最大化frobenius范数可以对样本较少的类别起到一定的保护作用。构造frobenius范数最大化损失函数,可以保证预测多样性,避免模型的预测坍缩到仅有大样本的类别。
36.(7)结合模型中的源域分类器损失l
y
、对抗损失l
adv
、特征分布差异损失l
lmd
和 frobenius范数最大化损失l
f
,对模型进行反向传播训练,迭代优化网络参数,提高跨库语音情感识别性能。
37.(8)模型的学习率和批处理大小都设置为0.0001和50,使用梯度下降法训练网络模型,模型迭代训练600次,分类器使用softmax。每一轮训练结束时,便会产生一组损失函数值,用于更新动态权重w
i
,实现损失权重的动态调节。
38.(9)将待识别的语音信号进行归一化处理,并输入训练好的深度网络模型,使用
softmax 分类器输出概率最大的类别即为识别的情感类别。
39.本发明请求保护的范围并不仅仅局限于本具体实施方式的描述。
技术特征:
1.一种基于对抗迁移和frobenius范数的跨库语音情感识别方法,其特征在于,包括以下步骤:(1)数据库:选取两个语音情感数据库,并挑选出它们相同情感类别的语音数据,分别作为源域数据库和目标域数据库,对两个语音库的语音信息制作对应的情感数字标签,然后对得到的源域和目标域的语音信号进行预加重、分帧和加窗等处理;(2)特征提取:对步骤(1)预处理过的语音信号进行声学特征提取,该特征包括但不限于韵律特征、谱相关特征和质量特征;(3)特征对抗学习:将步骤(2)所提取的情感特征x
i
输入对抗网络中的生成网络,利用对抗的方式训练域鉴别器和特征生成网络,当域鉴别器无法判断实例来自目标域还是源域时,则可以生成高级情感特征;域鉴别器损失如下:其中,e为交叉熵损失函数,f为特征学习网络,d为域鉴别器,d
i
为域标签;同时使用源域的真实标签y
s
与经过softmax分类器预测的源域特征概率作交叉熵运算:(4)特征迁移:为了进一步缓解特征分布差异,学习更多域不变特征,采用局部最大均值差异(local maximum mean discrepancy,lmmd)算法:其中x
s
和x
t
分别为步骤(3)中生成网络产生的源域和目标域高级情感特征,h为再生核希尔伯特空间(reproducing kernel hillbert space,rkhs),δ(
·
)为特征映射函数(高斯核函数);为源域样本x
s
中每个样本属于情感类别c的权重,为目标域样本x
s
中每个样本属于情感类别c的权重;(5)分类器优化:对步骤(3)中的目标域特征矩阵x
t
在经过softmax处理后成为预测概率矩阵p
i,j
,对其进行frobenius范数最大化操作,首先,frobenius范数最大化可以保证矩阵p
i,j
熵最小化,增加模型预测准确性,与此同时,为了弥补因熵最小化法带来的模糊样本误判,计算预测概率矩阵中的每一行与其下方所有行的差值,构造样本间距度量矩阵d,此时,最大化矩阵d的frobenius范数可以在保证模型预测精度的同时使得预测类别更丰富,保护了决策边界上的模糊样本,过程如下:了决策边界上的模糊样本,过程如下:了决策边界上的模糊样本,过程如下:其中,q为batchsize除以分类数j所得的商,r为batchsize除以分类数j所得的余数,d
的维度为分类数j列乘以行;(6)模型训练:根据上述步骤(3)、(4)和(5)得到的4个损失函数,再利用动态权重因子w
i
来调整不同损失函数对模型优化的贡献,进而得到模型整体的优化目标为:min l
sum
=w
s
l
s
+w
y
l
y
+w
lmmd
l
lmmd
‑
w
f
l
f
,w>0
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)动态权重因子表示为:其中i∈{s,t,y,lmmd,f};(7)重复步骤(3)、(4)和(5),通过梯度下降法迭代训练网络模型,不断更新步骤(6)的动态权重因子,直至模型最优;(8)利用步骤(6)训练好的网络模型,使用sofmatx分类器预测步骤(4)中的目标域特征标签,最终实现语音情感在跨语料库条件下的情感识别。
技术总结
本发明公开了一种基于对抗迁移和Frobenius范数的跨库语音情感识别方法,本发明包括以下步骤:首先,搭建基于对抗神经网络的深度生成网络模型,用来生成高级情感特征;然后,在子域自适应层实现无监督特征迁移;其次,为了提升分类器性能,在输出概率决策边界上使用Frobenius范数最大化来消除模糊预测;最后在训练阶段,根据不同损失函数对模型的贡献度,利用动态权重因子来调整模型优化进度。本发明提出的方法具有良好的鲁棒性,有效减小特征分布差异距离,且模型收敛快。且模型收敛快。
技术研发人员:汪洋 庄志豪 耿磊 刘曼 陶华伟 傅洪亮
受保护的技术使用者:河南工业大学
技术研发日:2021.09.25
技术公布日:2021/12/27