1.本发明属于音频处理技术领域,涉及复杂声音识别技术,特别涉及一种基于一维卷积神经网络的复杂声音识别方法。
背景技术:
2.复杂声音指环境中的非语言类声音,声源复杂且多样、信号本身具有非平稳性并且时常伴随极具干扰的背景噪声等,使得不同的声音场景的声音特征不够明显或者特征相似度非常高,复杂声音识别能够自动识别环境中复杂声音的具体种类,如小孩玩耍、汽车鸣笛和街头音乐等。在声音分类领域,诸如语音分类和音乐分类已经达到了非常高的准确率,但是在复杂声音识别领域中由于信号本身的非平稳性,语音或音乐分类方案显然不适合于解决此类问题,因此需要提出一种有效的针对复杂声音的识别模型。
3.目前结合神经网路解决复杂声音分类问题上,根据输入数据的不同主要有三种方法:基于原始信号、人工特征和多种输入数据。第一种是直接使用原始信号进行网络训练,这种方法的优点是不需要人工对信号进行特征提取,极大简化操作流程,模型简单方便普及;第二种方法是对原始数据进行处理,人工提取声音信号的某些特征,如频谱图和梅尔频率倒谱系数等,这种方法的优点是针对某些数据集准确率较高,但是泛化能力差,模型很难改变后续的识别结果。第三种是多输入的复杂网络,将原始声音信号和人工提取的特征共同作为网络的输入部分,优点是能够结合信号的原始特征(时序特征)和频域特征,弥补了单一数据特征不足的缺陷,但是该类模型比较复杂,对平台的硬件要求很高,不方便应用。
4.基于原始音频信号的深度学习模型被许多学者用来解决复杂声音识别问题,例如dai等人提出的基于一维卷积神经网络的复杂声音识别模型,取得了较好的识别准确率。但是由于深度学习模型很难有效提取原始信号的特征,并且现有技术提出的模型较为复杂,需要进一步优化。因而基于原始音频信号解决复杂声音问题是一个非常大的挑战。为达到好的识别效果,现有的方案中还存在以下问题:
5.(1)原始数据不一致的问题
6.在实际的数据处理过程中存在一些数据集(如urbansound8k数据集和实际环境采集的数据)中的音频时长不一致的情况,而一维卷积神经网络模型要求固定的输入数据长度,因此需要使用数据填充,常用的数据填充方法有三次样条插值、补零法等。数据集中会存在许多音频时长和目标长度相差很大,例如实际时长是1秒,目标长度是4秒,显然三次样条插值已经不适用此种情况,而补零方法过于简单,数据会丢失很多的信息,而且填充的零越多还可能掩盖有效信息。因此,本发明提出一种随机补齐算法,该方法基于原始数据,在填充数据的同时,能够丰富数据特征。
7.(2)注意力机制
8.注意力机制能够让模型关注有用的信息,能够进一步提升模型性能。卷积神经网络中常用的有senet、bam和cbam等注意力机制模块,但是这些模块都是面向二维卷积神经网络的,因此本发明提出了一个面向一维卷积神经网络的简化的注意力机制,该模块通过
对全局特征进行加权,再和原特征向量相乘得到带有注意力的特征向量。
技术实现要素:
9.针对现有技术存在的不足,本发明提供一种基于一维卷积神经网络的复杂声音识别方法,首先提出一种随机补齐算法将参差不齐的原始音频数据填充至相同的长度输入至网络模型中,然后优化网络模型,将预加重技术和简化的注意力机制引入神经网络进行训练,最终构建了复杂声音识别模型。
10.为了解决上述技术问题,本发明采用的技术方案是:
11.一种基于一维卷积神经网络的复杂声音识别方法,对复杂声音采用随机补齐算法处理,将原始数据填充至同一长度,用于一维卷积神经网络的输入;并在一维卷积神经网络的基本框架嵌入预加重模块和简化的注意力机制模块,所述预加重模块置于一维卷积神经网络的输入部分,用于对输入数据进行预加重和参与网络模型调优,所述简化的注意力机制模块置于一维卷积神经网络的深层,利用全局平均池化和sigmoid函数得到带有注意力的全局特征。
12.进一步的,所述的基于一维卷积神经网络的复杂声音识别方法详细步骤如下:
13.一、原始数据处理:采用随机补齐算法对原始数据进行填充,得到裁剪随机补齐后的长度一致的原始音频,将该原始音频作为一维卷积神经网络的输入数据;
14.二、预加重:通过预加重模块对输入数据进行预加重,再经过一层卷积层处理;
15.三、一维卷积神经网络:通过一维卷积神经网络处理,得到特征向量,其中,该一维卷积神经网络结构采用了两个通道数一样的卷积层后跟一层池化层,堆叠三次,共6层卷积结构;
16.四、注意力机制:特征向量输入到简化的注意力机制模块中,得到带有注意力的特征;
17.五、输出分类:最后通过两层全连接结构和softmax分类函数输出最终的识别结果。
18.进一步的,所述的随机补齐算法具体步骤如下:
19.(1)将所有样本划分成大于等于n/2秒和小于n/2秒两大类,其中样本的目标长度为n秒;
20.对大于等于n/2秒的样本,随机选取一个能够一次性补齐至n秒的起始点,然后截取起始点至所需的长度,最后将截取的音频段填充在原始音频的末端完成补齐;
21.(2)对小于n/2秒的样本,则直接复制整个样本直至长度大于等于n秒,最后再裁剪成n秒的样本。
22.进一步的,所述预加重模块共有两层卷积结构,第一层的卷积核的初值设置为
‑
0.97和1并不断堆叠,第二层的卷积核初值为1,进一步调整预加重系数。
23.进一步的,预加重模块每一层的卷积核的个数设置为1。
24.进一步的,所述简化的注意力机制是,首先使用全局平均池化将特征压缩成和通道数大小一致的一维特征,获取模型的全局特征,然后将该特征输入到sigmoid函数中得到每个通道对应的权重,最后将该权重和原全局平均池化得到的一维特征相乘得到新的全局特征,该特征就是带有注意力的特征;
25.注意力机制的表达式如下:
[0026][0027]
其中f为一维卷积神经网络深层的输出特征,w为权重向量,f
o
为带有注意力的全局特征。
[0028]
与现有技术相比,本发明优点在于:
[0029]
(1)本发明设计的随机补齐方法能够将参差不齐的原始数据填充至同一长度,便于网络模型的输入,并且弥补了补零方法的单一性,依靠原始数据补充原始数据,最大程度的保留了原始数据的时序性等特征,提供更多的有用特征显然有利于分类性能的提升。
[0030]
(2)本发明设计的预加重模块,利用卷积层的卷积操作将预加重技术结合到卷积神经网络中,通过加入一层卷积核初始值为1,核长为1的卷积层,为前面的预加重层提供了缓冲空间,能够进一步适当的调节网络,同时也减轻了接下来的一维卷积神经网络的调优负担,提高性能。
[0031]
(3)本发明设计的简化的注意力机制,利用全局平均池化和sigmoid函数得到带有注意力的全局特征,有利于模型分类。
[0032]
(4)将上述关键点结合并构建了端到端的基于一维卷积神经网络的复杂声音识别模型,该模型能够很好的获取原始复杂声音的特征,获得良好的识别效果。
附图说明
[0033]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0034]
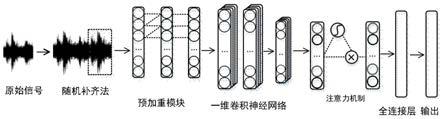
图1为本发明的复杂声音识别流程图;
[0035]
图2为本发明随机补齐法后的原始数据和填充零的方法对比图;
[0036]
图3为本发明预加重模块结构图;
[0037]
图4为本发明简化的注意力机制模型结构图。
具体实施方式
[0038]
下面结合附图及具体实施例对本发明作进一步的说明。
[0039]
本实施例提供一种基于一维卷积神经网络的复杂声音识别方法,包括两方面:一方面对复杂声音采用随机补齐算法处理,将原始数据填充至同一长度,用于一维卷积神经网络的输入。另一方面优化网络模型结构:在一维卷积神经网络的基本框架嵌入预加重模块和简化的注意力机制模块。预加重模块置于一维卷积神经网络的输入部分,用于对输入数据进行预加重和参与网络模型调优;简化的注意力机制模块置于一维卷积神经网络的深层,利用全局平均池化和sigmoid函数得到带有注意力的全局特征。
[0040]
结合图1所示的复杂声音识别流程图,详细步骤如下:
[0041]
一、原始数据处理:采用随机补齐算法对原始数据进行填充,得到裁剪随机补齐后的长度一致的原始音频,将该原始音频作为一维卷积神经网络的输入数据。
[0042]
随机补齐算法具体步骤如下:
[0043]
(1)假设样本的目标长度为4秒,将所有样本划分成大于等于2秒和小于2秒两大类;
[0044]
对大于等于2秒的样本,随机选取一个能够一次性补齐至4秒的起始点,然后截取起始点至所需的长度,最后将截取的音频段填充在原始音频的末端完成补齐;
[0045]
(2)对小于2秒的样本,则直接复制整个样本直至长度大于等于4秒,最后再裁剪成4秒的样本。
[0046]
经过随机补齐法后的原始数据和填充零的方法对比如图2所示。以下为随机补齐算法的伪代码。
[0047][0048]
二、预加重:通过预加重模块对输入数据进行预加重,再经过一层卷积核较大的卷积层处理。
[0049]
所述预加重模块共有两层卷积结构,第一层的卷积核的初值设置为
‑
0.97和1并不断堆叠,第二层的卷积核初值为1,能够进一步调整预加重系数。图3为预加重模块结构图,预加重模块的目的是对输入数据进行预加重,不需要提取特征,因此每一层的卷积核的个数设置为1即可。在模型学习的过程中,预加重模块也会参与到网络中进行调优。
[0050]
三、一维卷积神经网络:通过一维卷积神经网络处理,得到特征向量,其中,该一维卷积神经网络结构采用了两个通道数一样的卷积层后跟一层池化层,堆叠三次,共6层卷积结构。
[0051]
四、注意力机制:特征向量输入到简化的注意力机制模块中,得到带有注意力的特征。
[0052]
如图4所示,该注意力机制置于一维卷积神经网络的深层,首先使用全局平均池化(global average pooling,gap)将特征压缩成和通道数大小一致的一维特征,这一步能够
获取模型的全局特征,然后将该特征输入到sigmoid函数中得到每个通道对应的权重,最后将该权重和原gap得到的一维特征相乘得到新的全局特征,该特征就是带有注意力的特征。
[0053]
注意力机制的表达式如下:
[0054][0055]
其中f为一维卷积神经网络深层的输出特征,w为权重向量,f
o
为带有注意力的全局特征。
[0056]
五、输出分类:最后通过两层全连接结构和softmax分类函数输出最终的识别结果。
[0057]
结合图1所示,本发明将随机补齐算法、预加重模块、简化的注意力机制整合得到复杂声音识别模型,首先对输入音频数据进行随机补齐,得到裁剪补齐后原始音频,将该原始音频作为网络的输入数据;然后预加重模块对输入数据进行预加重,再经过一层卷积核较大的卷积层;接着是传统的一维卷积神经网络结构,该结构采用了两个通道数一样的卷积层后跟一层池化层,堆叠三次,共6层卷积结构。此外前三层分别使用扩张系数为2、3和4的扩张卷积进一步增加模型的感受野;然后特征向量输入到简化的注意力机制模块中得到带有注意力的特征;最后通过两层全连接结构和softmax分类函数输出最终的识别结果。
[0058]
模型的结构和参数如表1所示,以采样率为16khz,4秒的样本长度为例。
[0059]
表1模型结构和参数表
[0060][0061]
实验配置和结果:
[0062]
1、损失函数
[0063]
模型使用经典的交叉熵损失函数,公式如下:
[0064]
h(p,q)=
‑
∑
x
p(x)log q(x)
ꢀꢀꢀꢀꢀ
公式(2)
[0065]
其中,p表示真实样本的分布,q则为训练后的模型的样本预测分布。
[0066]
2、优化算法
[0067]
优化器算法使用动量为0.9的随机梯度下降法,加速度更新如下式:
[0068]
v
t
=γv
t
‑1+lr*grad
ꢀꢀꢀꢀꢀ
公式(3)
[0069]
其中v为加速度,γ为动量系数,一般设置为0.9,lr为学习率,grad为梯度。
[0070]
3、学习率
[0071]
学习率衰减采用离散下降,具体参数如下公式:
[0072][0073]
模型训练时batch设置为64,共训练200轮次。
[0074]
4、实验结果
[0075]
本发明提出的基于一维卷积神经网络的复杂声音识别模型在esc10、esc50和urbansound8k数据集上的识别准确率分别达到了84.4%、73.8%和88.6%,可见该发明方法是有效的。
[0076]
当然,上述说明并非是对本发明的限制,本发明也并不限于上述举例,本技术领域的普通技术人员,在本发明的实质范围内,做出的变化、改型、添加或替换,都应属于本发明的保护范围。