1.本发明涉及语音通信系统技术领域,尤其涉及一种用麦克风阵列进行噪声抑制的新方法和装置。
背景技术:
2.随着现代语音通信、自动语音识别、物联网和智能家居等应用技术的飞速发展,远距离拾音技术的研究越来越受到有关学术界和工业界的高度重视。在远距离拾音场景中,由于目标声源远离拾音的麦克风(传感器),那么麦克风拾取的信号中将存在混响和环境噪声等干扰信号。这些干扰信号的存在,通常使得拾取的信号中信噪比(下面简称snr)或信干比(下面简称sir)较低,从而严重影响了诸如语音通信和语音识别等后续处理系统的性能。
3.含噪语音信号的降噪技术通常分为两大类型:基于单麦克风的降噪技术和基于多麦克风(即麦克风阵列)的降噪技术,最为著名的单麦克风降噪技术有谱减法、wiener滤波法和最小均方误差(mmse)法,它们均利用语音的间歇性和噪声的平稳性之假设来估计含噪语音信号的snr,并据此来进行噪声抑制。这些算法复杂度低,易于实现,因而获得广泛使用。然而它们在实际应用中会产生音乐噪声和语音失真,特别是在非平稳和强干扰电平的噪声场景下。于是基于麦克风阵列的降噪技术便应运而生,其中最为代表性的方法有盲源分离(bbs)(独立分量分析(ica)为bbs中一种主要技术)和波束赋性技术,然而波束赋型技术在实际应用中,其性能通常要优于bbs方法。波束赋型技术是利用目标声源的方位信息,让麦克风阵列在目标声源方向上形成空间选择性,来选通目标声源而滤除噪声。众多的波束赋型算法中,广义旁边抵消器(gsc)算法和frost算法展现出可靠的性能。尽管基于麦克风阵列的多声道降噪算法的性能可以通过增加阵列的麦克风数目来进一步地加以改善,但大量的麦克风数目意味着波束赋型算法的计算复杂度剧烈增大,从而难以在现有的商用dsp芯片上实现。此外,波束赋型算法对麦克风阵列运行环境中的相干方向性噪声源具有良好的滤波或抑制能力,但对非相干噪声的抑制通常较差,因此波束赋型器对噪声的抑制量受限于其中的非相干噪声。为此,在波束赋型器的输出,需增加一个后处理来进一步滤除或抑制其残留的非相干噪声分量。simmer等提出波束赋型器
‑
wiener滤波的组合结构以消除或抑制非相干噪声,然而在实际的场景中,噪声通常具有“鸡尾酒会效应”(cocktail
‑
party
‑
effect)和散射场(diffuse)特性,在低频段呈现较强的相关性。有关学者提出在低频段采用谱减法技术而在其它频段采用wiener滤波方法或者通过考虑噪声场空间统计特性的先验知识来修正维纳滤波器(下面简称wiener滤波器)的估计以便处理散射噪声场,而maj等提出应用广义奇异值分解(gsvd)技术来估计wiener滤波器,与波束赋型器所不同的是该技术不仅可以消去相关噪声,而且还能消除散射噪声,但其巨大的计算负荷无法予以实时实现。而spriet等将maj方法在子带域里予以实现,显著地降低了原算法的计算复杂度,但仍离实时实现有相当的距离。
4.基于单麦克风的降噪技术虽然复杂度低、易于实现,但它们在实际应用中会产生音乐噪声和语音失真,特别是在非平稳和强干扰电平的噪声场景下以及远场条件下。现有
的波束赋型器,来增强麦克风阵列拾取的远场含噪语音信号;
16.噪声抑除模块,用所述波束赋型器输出的增强语音信号和波束赋型器中参考麦克风拾取的语音信号一起构造一个“双麦克风”降噪后处理器,去除或抑制运行环境中相关噪声和散射噪声,获得目标语音信号的估计值。
17.为了实现上述目的,根据本技术的第三方面,提供了一种电子设备,包括:
18.至少一个处理器;
19.以及与所述处理器连接的至少一个存储器、总线;其中,
20.所述处理器、存储器通过所述总线完成相互间的通信;
21.所述处理器用于调用所述存储器中的程序指令,以执行第一方面所述的一种用麦克风阵列进行噪声抑制的新方法。
22.为了实现上述目的,根据本技术的第四方面,提供了一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令使所述计算机执行第一方面所述的一种用麦克风阵列进行噪声抑制的新方法。
23.与现有的基于麦克风阵列噪声抑制技术相比,本发明提出的方法具有如下的有点:
24.1、较低的计算复杂度,便于在现有的商用dsp芯片上实时实现;
25.2、能有效地抑制非相关噪声和相关噪声,特别是“鸡尾酒会效应”和散射噪声。
附图说明
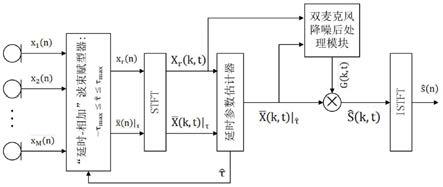
26.图1为本发明一种实施例的原理系统框图;
27.图2为麦克风阵列的延时参数估计算法流程图;
28.图3为一种用于双麦克风降噪的改进cpsds算法流程图。
具体实施方式
29.下文结合附图和具体实施例对本发明的技术方案做进一步说明。
30.实施例
31.首先应用一种低计算复杂度的“延时
‑
相加”波束赋型器来增强麦克风阵列拾取的远场含噪语音信号,然后用该波束赋型器输出的增强语音信号和波束赋型器中参考麦克风拾取的语音信号一起构造一个“双麦克风”降噪后处理器,来自适应地去除和抑制运行环境中的相关噪声和散射噪声,从而有效地提取目标声源信号。本发明提出的麦克风阵列降噪新方法的系统框图如图1所示,其中麦克风阵列为m个等间距麦克风单元构成的线性阵列,它用于设计构造“延时
‑
相加”波束赋型器,以便增强阵列拾取的含噪语音信号;该波束赋型器的输出增强语音信号stft频谱和麦克风阵列中的参考麦克风信号的stft频谱一起输至“双麦克风”降噪后处理器模块,用于计算设计一个后处理滤波器的传递,该对波束赋型器的输出信号频谱进行加权处理(即滤波),以去除和抑制运行环境中相关噪声和散射噪声,从而获得目标语音信号频谱的估计值;该频谱估计再经短时傅里叶逆变换(下面简称istft)后还原成时域的目标语音估计信号。
32.本实施例中,“延时
‑
相加”波束赋型器的设计原理如下:
33.假设阵列中麦克风单元间的距离为d(米,m),声音的传播速度为c(米/秒,m/s),阵
列信号的采样率为fs(赫兹,hz),每个麦克风接收到的数字信号为x
i
(n),i=1,2,...,m,本发明针对的是远距离拾音场景,麦克风阵列获取的是平面波信号,因而每相邻两个麦克风信号间的时延(单位:样本数)满足下式:
34.‑
τ
max
≤τ≤τ
max
ꢀꢀꢀꢀ
(1)
35.其中
36.这里函数ceil{x}表示不小于x的最小整数。
[0037]“延时
‑
相加”波束赋型器是通过同步麦克风阵元信号间的时延来增强所收到的含噪语音信号,本发明必须首先估计出时延参数。本发明基于阵列中参考麦克风信号x
r
(n)(设r=1,即麦克风1信号为参考信号)和“延时
‑
相加”波束赋型器在假定时延为时的输出信号之间的相干系数(coherence)的幅度平方(下面简称msc)来估计麦克风阵列的时延参数τ,其中可表示为:
[0038][0039]
事实上,和间的相干系数在数学上定义为:
[0040][0041]
其中为信号x
r
(n)和间的互功率谱,和分别是信号x
r
(n)和的自功率谱。那么其相应的msc则为:
[0042][0043]
显然有:
[0044]
在实际工程实现中,相干系数可以由相应信号x
r
(n)和的stft频谱x
r
(k,t)和来计算,即
[0045]
(这里*表示共轭运算)(7)
[0046]
那么msc即为:
[0047][0048]
其中k和t分别为stft频谱在频域的频点索引和进行stft变化的时域信号帧的索引。记在频域上的累加值为即:
[0049][0050]
这里设stft的窗口长度k为偶数,那么麦克风阵列的时延参数τ的估计可由下式确定:
[0051][0052]
该时延参数的估计值用来获取波束赋型器的输出频谱用于“延时
‑
相加”波束赋型器设计的麦克风阵列时延参数的估计算法流图如图2所示。
[0053]
本实施例中制得说明的是,“延时
‑
相加”波束赋型器的关键设计参数τ(即相邻麦克风单元所接收信号之间的相对时延)的求解方法;该方法的最优准则是使波束赋型器输出信号和麦克风阵列的参考麦克风信号x
r
(n)之间相干系数的幅度平方最大化
[0054]
本实施例中,“双麦克风”降噪后处理滤波器的设计原理如下:
[0055]
对双麦克风接收的两路观测信号而言,其间的相干系数在目标信号出现时具有较大的幅值(~0.9),而在目标信号缺席时,如果双麦克风声道中的噪声彼此不相关,那么此时其相干系数的幅值通常较小(~0.1),因此采用其两路观测信号间的相干系数作为滤波器的传递函数,对含噪语音进行增强处理,便是很自然的事。基于相干系数的双麦克风降噪滤波器在不相关噪声场景下等效于最佳wiener滤波器,因而取得了较为满意的结果,但是在相关噪声特别是“鸡尾酒会效应”和散射噪声的场景下,其性能将急剧恶化。maj等提出应用广义奇异值分解(gsvd)技术来估计基于双麦克风信号的wiener滤波器传递函数,该wiener滤波器不仅可以消去相关噪声,而且还能消除散射噪声,但其巨大的计算复杂度无法予以实际中实时实现。尽管目前已有将maj方法在子带域里予以实现,在一定程度上显著地降低了原算法的计算复杂度,但仍离实时实现有相当的距离,因而无法实际应用。为此,有关学者开展了一系列相关的研究,以寻求一种能实际实时应用与实现的解决方案。akbari azirani等提出一种基于两麦克风间噪声的互相关功率谱来设计降噪滤波器传递函数的方法(以下简称为互功率谱减法cpsds),该方法仅在噪声段对两麦克风噪声间的互功率谱进行自适应学习估计,这一估计将在目标信号出现时从两麦克风观测信号的互功率谱中减去,然后用修正的观测信号互功率谱来计算相干系数用于降噪使用的滤波器传递函数,该方法可以有效地抑制相关和不相关噪声。显然cpsds技术如同与传统单麦克风降噪的谱减法一样,需要一个性能稳健的语音活性检测器(下面简称vad),也会产生较多影响听觉效果的音乐噪声。guerin等应用基于“雄健”考虑(即:语音信号被认为是短时平稳的,而噪声信号通常考虑为长时平稳的,因此在相邻两帧观测信号有较大的能量增加时可视为有目标语音出现,否则便视为是噪声信号)的“模糊律”(fuzzy
‑
law)准则对噪声cpsd进行连续的自适应学习估计而无需vad,以便提高相关功率谱估计的精度,从而降低乃至消除音乐噪声的影响。但该技术在低snr和非平稳噪声场景下不能取得较为满意的结果。
[0056]
因此,本发明提出了用于双麦克风降噪后处理的改进cpsds新方法(以下简称mcpsds),在mcpsds方法中,首先采用基于语音出现概率(下面简称spp)的噪声cpsd无偏估计算法,对噪声cpsd进行估计,该算法能快速地跟踪噪声统计特性的变化,因而适合非平稳噪声场景;然后,根据这一噪声cpsd的无偏估计,应用决策引导(decision
‑
directed)技术来有效地估计观测信号cpsd中的先验snr,并用之设计一个wiener滤波器从观测信号的cpsd中提取语音信号的cpsd,最后用提取的语音信号cpsd代替cpsds算法中修正的观测信号cpsd来计算降噪滤波器的传递函数。
[0057]
具体地,设两个麦克风的观测信号x1(n)和x2(n)为:
[0058]
x1(n)=s1(n)+v1(n)
ꢀꢀꢀꢀꢀꢀ
(11)
[0059]
x2(n)=s2(n)+v2(n)
ꢀꢀꢀꢀꢀꢀ
(12)
[0060]
其中s
i
(n)和v
i
(n)分别为麦克风i的语音信号和噪声信号,i=1,2。那么在stft域,方程(11)
‑
(12)可表示为:
[0061]
x1(k,t)=s1(k,t)+v1(k,t)
ꢀꢀꢀꢀ
(13)
[0062]
x2(k,t)=s2(k,t)+v2(k,t)
ꢀꢀꢀꢀꢀꢀ
(14)
[0063]
假设语音与噪声不相关,那么两路观测信号间的cpsd近似满足下式:
[0064][0065]
现在设计一个wiener滤波器g
w
(k,t),用它从中提取即:
[0066][0067]
那么g
w
(k,t)可表示为:
[0068][0069]
用(16)式替换cpsds方法中的观测信号的修正cpsd可得本发明提出的降噪滤波器传递函数为:
[0070][0071]
用g
mcpsds
(k,t)在频域对麦克风观测信号频谱(比如x1(k,t))进行加权修正,然后再进行istft变换即可得降噪处理后的语音信号。(18)式表明,本发明提出的降噪滤波器传递函数g
mcpsds
(k,t)与两麦克风间的相干系数和用于估计语音信号cpsd的wiener滤波器g
w
(k,t)相关联。现在的问题是如何求解wiener滤波器g
w
(k,t),考察(15)和(17)式,不难发现,g
w
(k,t)与下述定义的观测信号cpsd中先验snr即snr
c_pri
(k,t)有关:
[0072][0073]
其中
[0074]
那么借助“决策
‑
导向”技术的思想,本发明提出用下述的递归方式来估计snr
c_pri
(k,t),即:
[0075][0076]
其中
[0077]
snr
c_prst
(k,t)是观测信号cpsd中后验snr;而递归系数λ(k,t)是按如下方式调节,以便自适应地跟踪运行环境的变化:
[0078]
λ(k,t)=0.98
‑
0.30
·
g
mcpsds
(k,t
‑
1)
ꢀꢀꢀꢀ
(23)
[0079]
由(22)式知,观测信号cpsd中后验信噪比snr
c_post
(k,t)的计算涉及两麦克风间噪声互功率谱的估计。本发明关于单麦克风中噪声功率无偏估计的思想,扩展到双麦克风中噪声互功率谱的无偏估计,其噪声互功率谱无偏估计算法如下:
[0080]
step 1
‑‑
初始化参数:
[0081]
置时域平滑参数β1=0.9,β2=0.8;设置最佳先验snr参数α
opt
=10
1.5
,初始化信号帧时间索引t:t=0;
[0082]
step 2
‑‑
对第t帧和所有的频点k,作下述处理:
[0083]
step 2.1、计算后验信号出现概率(spp):
[0084][0085]
这里为第t
‑
1帧噪声cpsd模的估计;
[0086]
step 2.2、计算平滑的后验spp:
[0087][0088]
step 2.3、为避免停滞发生,做如下检验校准:
[0089][0090]
step 2.4、更新噪声互功率谱估计的周期图(periodogram):
[0091][0092]
step 2.5、进行时域平滑获得第t帧的噪声cpsd估计的模:
[0093][0094]
step 3
‑‑
更新信号帧索引t:t=t+1,并检查估计算法是否需结束?
[0095]
如果是,则结束;否则,则跳转至step 2。
[0096]
另外,相干系数的确定涉及到观测信号的互功率谱密度和自功率谱密度与的计算,它们的估计在实际中可由下述的时间递归来工程实现,即:
[0097][0098]
其中λ(k,t)为(23)是定义的递归系数,x
i
(k,t)为麦克风i信号x
i
(n)的stft频谱。
[0099]
综上所述,该算法能快速地跟踪噪声统计特性的变化,因而适合非平稳噪声场景。本发明提出的这种用于双麦克风降噪的改进cpsds算法,其算法流程图如图3所示。
[0100]
此外,根据本技术实施例,还提供了一种电子设备,该电子设备包括:
[0101]
至少一个处理器;
[0102]
以及与所述处理器连接的至少一个存储器、总线;其中,
[0103]
所述处理器、存储器通过所述总线完成相互间的通信;
[0104]
所述处理器用于调用所述存储器中的程序指令,以执行上述图1中用麦克风阵列进行噪声抑制的新方法。
[0105]
根据本技术实施例,还提供了一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令使所述计算机执行图1中用麦克风阵列进行噪声抑制的新方法。
[0106]
显然,本领域的技术人员应该明白,上述的本技术的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本技术不限制于任何特定的硬件和软件结合。
[0107]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。