1.本发明涉及含次级通道在线辨识的反馈型主动噪声控制系统及方法,属于主动噪声控制技术领域。
背景技术:
2.主动噪声控制(active noise control,anc)利用声波相消干涉原理,针对目标噪声,产生一个与其幅度相同、相位相反的次级噪声,两声波相互叠加,以达到消声的目的。较传统的被动降噪技术,具有良好的低频噪声抑制性能,以及体积小、成本低等优点。
3.根据有无参考传感器(用于得到参考信号来控制次级噪声的产生),主动噪声控制系统可分为前馈型主动噪声控制系统和反馈型主动噪声控制系统两种。根据目标噪声频谱的特点,它们可进一步分为宽带主动噪声控制系统和窄带主动噪声控制系统(s.m.kuo and d.r.morgan,“active noise control:a tutorial review,”proc.ieee,vol.87,no.6,pp.943
‑
973,jun.1999.)。特别地,窄带主动噪声控制系统能够抑制实际应用中存在着大量的由切割机、风扇、引擎等旋转机械设备产生的周期性噪声或干扰。
4.在高温或严重污染的降噪场合中,反馈型主动噪声控制系统无需设置参考传感器,对物理空间的要求较低,同时减少硬件成本,因此具有更大的实际应用价值。
5.传统反馈型主动噪声控制系统主要包括次级扬声器(产生次级噪声)和误差传声器(检测系统残余噪声)。次级通道表示次级噪声到误差传感器之间的通道,在实际系统中包括次级扬声器、误差传声器以及两者之间的声学空间,由一系列电子设备、装置和物理通道组成。实际工况下次级通道往往具有复杂时变性,如噪声源移动,主动噪声控制装置的位置变化等导致实际次级通道模型的改变,这将会严重影响系统的稳定性。
6.因此,人们需要研究相应的次级通道辨识方法来估计实际次级通道模型,进而改善系统的稳定性。通常,次级通道辨识方法可分为次级通道离线辨识和次级通道在线辨识两种。次级通道在线辨识方法相较于传统的次级通道离线辨识方法,可以实时估计时变的次级通道,且具有适用于复杂应用场合的特点。
7.近年来,一些基于辅助高斯白噪声幅值调整策略的次级通道在线辨识方法被应用到反馈型主动噪声控制系统中。
8.学者xiao等人提出基于自适应陷波器的反馈型主动噪声控制系统,直接采用残余噪声有关的函数来调整辅助噪声幅值,但是该方案中引入的辅助噪声对残余噪声的贡献量大,会制约该系统的噪声抑制性能,而且系统的控制器与次级通道在线辨识模块之间相互耦合,即残余噪声分别用于控制器的更新、以及次级通道在线辨识模块的期望输入,导致残余噪声中的宽带分量制约控制器的更新速度、残余噪声中的窄带分量制约次级通道在线辨识的速度,最终影响整体系统的动态性能(x.tan,y.ma,y.xiao,l.ma,and k.khorasani,“a new feedback narrowband active noise control system with online secondary
‑
path modeling based on adaptive notch filtering,”proc.of icamechs,pp.78
‑
82,dec.2020.)。
9.学者akhtar提出了一种反馈型主动噪声控制,其采用延迟滤波器应用到次级通道在线辨识模块来监测次级通道在线辨识的收敛状态,并同时采用变步长算法来更新经过延迟之后的次级通道估计模型的系数,该系统可降低辅助噪声对残余噪声的贡献量,但是该系统难以适用当次级通道或目标噪声发生突变时的情形,且具有用户参数数目多且设置复杂、计算成本大的缺点,大大增加系统运行负担,不利于实际应用;另外,该系统的控制器与次级通道在线辨识模块之间的独立性较差,仍会制约整体系统的动态性能(m.t.akhtar,“narrowband feedback active noise control systems with secondary path modeling using gain
‑
controlled additive random noise,”digital signal processing,vol.111,2021,art.no.102976.)。
10.总之,上述传统的含次级通道在线辨识的反馈型主动噪声控制系统仍然存在着难以应对次级通道发生较大突变的情形、引入的辅助噪声对残余噪声的贡献量较大或系统参数数目多且设置复杂的问题,制约其实际应用,且其控制器与次级通道在线辨识模块之间独立性较差,严重影响系统的整体性能。
11.为解决上述问题,需要提供一种更有效且实用的含次级通道在线辨识的反馈型主动噪声控制系统。
技术实现要素:
12.为了解决目前的含次级通道在线辨识的反馈型主动噪声控制系统,存在着引入的辅助噪声对残余噪声的贡献量较大进而制约系统的降噪性能、控制器与次级通道在线辨识模块之间独立性差进而严重影响系统的整体动态性能的问题,本发明提供了一种含次级通道在线辨识的反馈型主动噪声控制系统及方法。
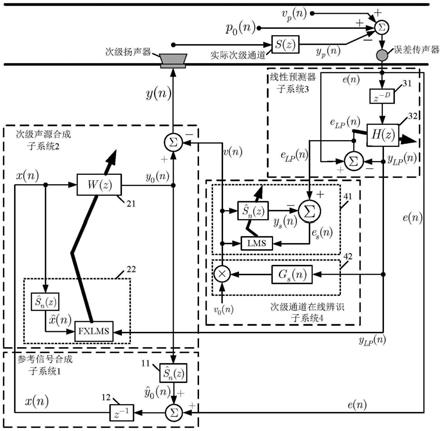
13.本发明的第一个目的在于提供一种含次级通道在线辨识的反馈型主动噪声控制系统,其特征在于,所述主动噪声控制系统包括:参考信号合成子系统(1)、次级声源合成子系统(2)、线性预测子系统(3)和次级通道在线辨识子系统(4);
14.所述参考信号合成子系统(1)分别与所述次级声源合成子系统(2)、所述线性预测子系统(3)连接;所述次级声源合成子系统(2)分别与所述参考信号合成子系统(1)、所述次级通道在线辨识子系统(4)连接;所述线性预测子系统(3)分别与所述参考信号合成子系统(1)、所述次级声源合成子系统(2)、次级通道在线辨识子系统(4)连接;所述次级通道在线辨识子系统(4)分别与所述次级声源合成子系统(2)、所述线性预测子系统(3)连接;
15.所述参考信号合成子系统(1)用于合成参考信号;所述次级声源合成子系统(2)用于合成次级声源;所述线性预测子系统(3)用于从残余噪声中分离出窄带分量和宽带分量;所述次级通道在线辨识子系统(4)用于实时在线地估计时变的次级通道估计模型。
16.可选的,所述线性预测子系统(3)包括:d阶延迟环节(31)和线性预测滤波器(32),所述d阶延迟环节(31)和线性预测滤波器(32)串联,所述线性预测滤波器(32)的系数和长度分别为和l,系数利用最小均方算法进行更新,更新公式为:
17.h
j
(n+1)=h
j
(n)+μ
h
e
lp
(n)e(n
‑
d
‑
j)
18.其中,μ
h
为线性预测滤波器更新步长,取值为正值;e
lp
(n)为所述线性预测子系统(3)分离出的宽带分量,e(n)为所述残余噪声;n为时刻,n≥0。
19.可选的,从所述残余噪声中分离出的宽带分量为:
20.e
lp
(n)=e(n)
‑
y
lp
(n)
[0021][0022]
其中,y
lp
(n)为从所述残余噪声中分离出的窄带分量。
[0023]
可选的,所述次级通道在线辨识子系统(4)包括:次级通道在线辨识模块(41)和辅助噪声调整模块(42);
[0024]
所述次级通道在线辨识模块(41)包括次级通道估计模型所述次级通道在线辨识模块(41)以所述宽带分量为期望输入、以高斯白噪声经所述辅助噪声调整模块(42)后产生的有色噪声v(n)为参考输入,并利用最小均方算法实时在线地估计并更新时变的次级通道估计模型;
[0025]
所述次级通道在线辨识模块(41)的次级通道估计模型的系数和长度分别为和系数更新公式为:
[0026][0027]
e
s
(n)=e
lp
(n)
‑
y
s
(n)
[0028]
其中,μ
s
为次级通道估计模型更新步长,取值为正值;y
s
(n)为所述次级通道在线辨识模块(41)的次级通道估计模型的输出;
[0029]
所述有色噪声v(n)为:
[0030]
v(n)=v0(n)g
s
(n)
[0031][0032]
其中,g
s
(n)为所述辅助噪声调整模块(42)的调整增益,辅助噪声调整模块遗忘因子λ∈(0,1),通常取值接近于1;v0(n)为均值为零、方差为的加性高斯白噪声。
[0033]
可选的,所述参考信号合成子系统(1)包括:次级通道估计模型(11)和一阶延迟环节(12),所述次级通道估计模型(11)由所述次级通道在线辨识模块(41)提供;
[0034]
所述参考信号为:
[0035][0036]
其中,e(n)为残余噪声,e(n
‑
1)为e(n)经过所述一阶延迟环节(12)的输出,为y0(n)经所述次级通道估计模型(11)的输出,为经过所述一阶延迟环节(12)的输出。
[0037]
可选的,所述次级声源合成子系统(2)包括:控制器(21)和滤波
‑
x最小均方算法模块(22);
[0038]
所述滤波
‑
x最小均方算法模块(22)采用从所述残余噪声中分离出的窄带分量y
lp
(n)作为误差输出,并用于更新控制器(21)的系数。
[0039]
可选的,所述控制器(21)采用线性滤波器,所述线性滤波器的系数和长度分别为和m
w
;
[0040]
所述控制器(21)的系数更新公式为:
[0041]
[0042]
其中,μ
w
为控制器更新步长,取值为正值;y
lp
(n)为所述线性预测子系统(3)分离出的窄带分量;为参考信号x(n)经所述滤波
‑
x最小均方算法模块(22)的次级通道估计模型的输出。
[0043]
可选的,次级声源为:
[0044]
y(n)=y0(n)
‑
v(n)
[0045]
其中,y0(n)为所述控制器(21)的输出。
[0046]
可选的,所述系统通过实时计算残余噪声经平滑滤波后的能量变化,监测次级通道或目标噪声可能发生的较大突变,并对所述线性预测滤波器(32)的系数、所述次级通道估计模型的系数、所述控制器(21)的系数和所述辅助噪声调整模块(42)的调整增益进行重新初始化;
[0047]
所述残余噪声经平滑滤波后的能量为:
[0048]
p
e
(n)=λ
m
p
e
(n
‑
1)+(1
‑
λ
m
)e2(n)
[0049]
其中,λ
m
∈(0,1)为平滑滤波遗忘因子,通常取接近于1的正值;
[0050]
在n
′
t
p
时刻,通过对残余噪声经平滑滤波后的能量p
e
(n),相继进行时间平均和平滑滤波后得到:
[0051][0052]
其中,n
′
为n整除t
p
时大于1的正整数,t
p
为时间平均窗的长度;
[0053]
当n时刻满足时,系统在n+1时刻进行重新初始化;其中,α∈(1,2)为阈值参数。
[0054]
本发明的第二个目的在于提供一种主动噪声控制方法,其特征在于,所述方法基于上述的含次级通道在线辨识的反馈型主动噪声控制系统实现,所述方法包括:
[0055]
步骤一:设置系统参数
[0056]
设置控制器(21)、线性预测滤波器(32)、次级通道估计模型的长度和更新步长;设置延迟环节的阶数d;设置辅助噪声调整模块(42)的遗忘因子;设置系统重新初始化所需的遗忘因子、阈值参数和时间平均窗的长度;设置控制器(21)、次级通道估计模型的系数、线性预测滤波器(32)的系数、以及辅助噪声调整模块(42)的调整增益的初始值均为零;
[0057]
步骤二:合成参考信号
[0058]
利用误差传声器获得的残余噪声e(n),与控制器(21)的输出y0(n)经次级通道估计模型(11)的输出进行相加,得到的信号经一阶延迟环节(12)后获得参考信号x(n):
[0059][0060]
即利用n
‑
1时刻的残余噪声和次级通道估计模型(11)输出信号求和,合成得到n时刻的参考信号;
[0061]
步骤三:在n时刻,首先,参考信号x(n)经控制器(21)得到y0(n);然后,利用辅助噪声调整模块(42)获得辅助噪声v(n),进而合成得到次级声源y(n);最后,残余噪声e(n)经线
性预测子系统(3)分离得到窄带分量y
lp
(n)和宽带分量e
lp
(n);
[0062]
步骤四:更新控制系统
[0063]
根据所述参考信号和所述窄带分量y
lp
(n)计算更新控制器(21)在n+1时刻的系数;
[0064]
根据残余噪声e(n)和窄带分量y
lp
(n)计算更新线性预测滤波器(32)在n+1时刻的系数;
[0065]
根据辅助噪声v(n)和宽带分量e
lp
(n)计算更新次级通道估计模型在n+1时刻的系数;
[0066]
根据窄带分量y
lp
(n)更新辅助噪声调整模块(42)在n+1时刻的调整增益;
[0067]
步骤五:实时计算残余噪声经平滑滤波后的能量变化,即:若满足步骤五:实时计算残余噪声经平滑滤波后的能量变化,即:若满足则在n+1时刻对线性预测滤波器(32)的系数、次级通道估计模型的系数、辅助噪声调整模块(42)的调整增益、控制器(21)的系数进行重新初始化,然后进入步骤六;若不满足则直接进入步骤六;
[0068]
步骤六:返回到步骤二,重复上述步骤二到步骤五,直至系统收敛并达到稳态。
[0069]
本发明有益效果是:
[0070]
1、本发明通过分离残余噪声的窄带分量和宽带分量,利用残余噪声的窄带分量调整辅助高斯白噪声的幅值,显著地降低引入的辅助噪声对残余噪声的贡献量,提升了系统的噪声抑制性能;
[0071]
2、利用从残余噪声分离出的宽带分量更新次级通道在线辨识模块,且利用从残余噪声分离出的窄带分量更新控制器,提升了控制器和次级通道在线辨识模块之间的独立性,改善了次级通道在线辨识的精度和速度,同时提升了系统动态性能;
[0072]
3、通过实时计算残余噪声经平滑滤波后的能量变化,监测次级通道或目标噪声可能发生的较大突变,并对系统重新初始化,提升了系统应对次级通道或目标噪声发生较大突变的能力,改善了系统的鲁棒性,适用于复杂降噪场合;
[0073]
此外,本发明无需设置参考传感器,降低了对物理空间的要求和系统硬件成本,不但具有良好的应对时变次级通道的性能,而且理论上可实现系统达到稳态后的残余噪声趋于环境水平,利于实际应用。
附图说明
[0074]
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0075]
图1是实施例一的一种含次级通道在线辨识的反馈型主动噪声控制系统的原理图;
[0076]
图2(a)是实施例三的残余噪声均方误差的变化曲线图;
[0077]
图2(b)是实施例三的次级通道估计均方误差的变化曲线图;
[0078]
图2(c)是实施例三的辅助噪声调整增益的变化曲线图;
[0079]
图3(a)是实施例四的目标噪声和残余噪声的变化曲线图;
[0080]
图3(b)是实施例四的辅助噪声调整增益的变化曲线图。
具体实施方式
[0081]
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
[0082]
实施例一:
[0083]
本实施例提供了一种含次级通道在线辨识的反馈型主动噪声控制系统,参见图1,所述主动噪声控制系统包括:参考信号合成子系统(1)、次级声源合成子系统(2)、线性预测子系统(3)和次级通道在线辨识子系统(4)。
[0084]
参考信号合成子系统(1)利用前一时刻的残余噪声和次级声源的叠加合成参考信号;次级声源合成子系统(2)采用线性滤波器作为控制器,控制器的输出和辅助噪声调整模块(42)的输出相加合成次级声源;线性预测子系统(3)由d阶延迟环节(31)和线性预测滤波器(32)按照串联方式组成,实现从残余噪声中分离出窄带分量和宽带分量;次级通道在线辨识子系统(4)随着反馈型主动噪声控制系统的运行,用于实时在线地估计时变的次级通道模型,提升系统的稳定性。
[0085]
目标噪声为:
[0086][0087]
其中,p0(n)为目标噪声中的窄带噪声分量;q为目标噪声中的窄带分量数目,为窄带分量的幅度;ω
p,i
为目标噪声中第i个窄带分量的频率;θ
i
为第i个窄带分量的初始相位;v
p
(n)为均值为零、方差为的加性高斯白噪声。
[0088]
实际次级通道s(z)表示从次级扬声器到误差传声器之间的声学空间模型,可采用有限冲激响应滤波器或无限冲激响应滤波器来表示。
[0089]
目标噪声p(n)与次级声源y(n)经过实际次级通道s(z)后信号y
p
(n)之差为残余噪声,即e(n)=p(n)
‑
y
p
(n)。
[0090]
参考信号合成子系统(1)包括次级通道估计模型和一阶延迟环节,利用误差传声器采集到的残余噪声e(n)和控制器输出y0(n)经次级通道估计模型(11)的输出进行相加,得到的信号经一阶延迟环节(12)后可合成参考信号,即:
[0091][0092]
其中,n为时刻,n≥0;次级通道估计模型(11)由次级通道在线辨识模块(41)提供。
[0093]
次级声源合成子系统(2)包括控制器(21)、滤波
‑
x最小均方算法模块(22)和带d阶延迟的线性预测补偿模型(23);控制器(21)采用线性滤波器,其系数和长度分别为和m
w
;滤波
‑
x最小均方算法模块(22)用于更新控制器(21)的系数,即:
[0094][0095]
其中,μ
w
为控制器更新步长,取值为正值;y
lp
(n)为线性预测子系统(3)分离出的窄带分量;参考信号x(n)经次级通道估计模型得到信号控制器(21)的输出和次级
通道在线辨识子系统(4)中辅助噪声调整模块(42)的输出进行相加,合成得到次级声源,即:y(n)=y0(n)
‑
v(n)。
[0096]
线性预测子系统(3)由d阶延迟环节(31)和线性预测滤波器(32)按照串联方式组成;线性预测滤波器(32)用h(z)表示,其系数和长度分别为和l,其系数利用最小均方算法进行更新,即
[0097]
h
j
(n+1)=h
j
(n)+μ
h
e
lp
(n)e(n
‑
d
‑
j)
[0098]
式中,μ
h
为线性预测滤波器更新步长,取值为正值;e
lp
(n)为线性预测子系统(3)分离出的宽带分量,即为残余噪声与线性预测滤波器(32)输出之差:e
lp
(n)=e(n)
‑
y
lp
(n),其中线性预测子系统(3)实现从残余噪声中分离出窄带分量y
lp
(n)和宽带分量e
lp
(n)。
[0099]
次级通道在线辨识子系统(4)包括次级通道在线辨识模块(41)和辅助噪声调整模块(42);次级通道在线辨识模块(41)以线性预测子系统(3)分离出的宽带分量为期望输入e
lp
(n)、以辅助高斯白噪声v0(n)经辅助噪声调整模块(42)后产生的有色噪声v(n)为参考输入,并利用最小均方算法实时在线地估计时变的次级通道模型,相应的次级通道估计模型的系数和长度分别为和其系数更新公式为:
[0100][0101]
e
s
(n)=e
lp
(n)
‑
y
s
(n)
[0102]
式中,μ
s
为次级通道估计模型更新步长,取值为正值;提升系统的稳定性;辅助噪声调整模块(42)以线性预测子系统(3)分离出的窄带分量y
lp
(n)为输入,调整增益表示为:
[0103][0104]
式中,辅助噪声调整模块遗忘因子λ∈(0,1),通常取值接近于1;那么辅助高斯白噪声v0(n)经辅助噪声调整模块(42)后产生的有色噪声为v(n)=v0(n)g
s
(n),其中,v0(n)为均值为零、方差为的加性高斯白噪声。
[0105]
系统通过实时计算残余噪声经平滑滤波后的能量变化,监测次级通道或目标噪声可能发生的突变,并对线性预测滤波器(32)的系数、次级通道估计模型的系数、控制器(21)的系数和辅助噪声调整模块(42)的调整增益进行重新初始化。
[0106]
残余噪声经平滑滤波后的能量为:
[0107]
p
e
(n)=λ
m
p
e
(n
‑
1)+(1
‑
λ
m
)e2(n)
[0108]
其中,λ
m
∈(0,1)为平滑滤波遗忘因子;
[0109]
在n
′
t
p
时刻,通过对残余噪声经平滑滤波后的能量p
e
(n),相继进行时间平均和平滑滤波后得到:
[0110][0111]
其中,n
′
为n整除t
p
时大于1的正整数,t
p
为时间平均窗的长度;
[0112]
当n时刻满足时,系统在n+1时刻进行重新初始化;其中,α∈(1,2)为阈值参数。
[0113]
实施例二
[0114]
本实施例提供一种含次级通道在线辨识的反馈型主动噪声控制方法,所述方法基于上述含次级通道在线辨识的反馈型主动噪声控制实现,包括:
[0115]
步骤一:设置系统参数:
[0116]
设置控制器(21)、线性预测滤波器(32)、次级通道估计模型的长度和更新步长;设置延迟环节的阶数d;设置辅助噪声调整模块(42)的遗忘因子;设置系统重新初始化所需的遗忘因子、阈值参数和时间平均窗的长度;设置控制器(21)、次级通道估计模型的系数、线性预测滤波器(32)的系数初始值均为零;
[0117]
步骤二:合成参考信号
[0118]
利用误差传声器获得的残余噪声e(n),与控制器(21)输出y0(n)经次级通道估计模型(11)的输出进行相加,得到的信号经一阶延迟环节(12)后获得参考信号x(n),即即利用n
‑
1时刻的残余噪声和次级通道估计模型(11)输出信号求和,合成得到n时刻的参考信号;
[0119]
步骤三:在n时刻,首先,参考信号x(n)经控制器(21)得到y0(n);然后,利用辅助噪声调整模块(42)获得辅助噪声v(n),进而合成得到次级声源y(n);最后,残余噪声e(n)经线性预测子系统(3)分离得到窄带分量y
lp
(n)和宽带分量e
lp
(n);
[0120]
步骤四:控制系统更新
[0121]
根据所述参考信号和所述窄带分量y
lp
(n)计算更新控制器(21)在n+1时刻的系数;
[0122]
根据残余噪声e(n)和窄带分量y
lp
(n)计算更新线性预测滤波器(32)在n+1时刻的系数;
[0123]
根据辅助噪声v(n)和宽带分量e
lp
(n)计算更新次级通道估计模型在n+1时刻的系数;
[0124]
根据窄带分量y
lp
(n)更新辅助噪声调整模块(42)在n+1时刻的调整增益。
[0125]
步骤五:实时计算残余噪声经平滑滤波后的能量变化,即:若满足步骤五:实时计算残余噪声经平滑滤波后的能量变化,即:若满足则在n+1时刻对线性预测滤波器(32)的系数、次级通道估计模型的系数、辅助噪声调整模块(42)的调整增益、控制器(21)的系数进行重新初始化,然后进入步骤六;若不满足则直接进入步骤六。
[0126]
步骤六:返回到步骤二,重复上述步骤二到步骤五,直至系统收敛并达到稳态,实现主动噪声控制。
[0127]
实施例三:仿真噪声与仿真次级通道情况下的验证
[0128]
目标噪声由五个频率分量和加性高斯白噪声组成,其五个频率分量的归一化角频率分别为0.10π、0.15π、0.20π、0.25π和0.30π,相应的频率分量幅度分别为1.41、1.00、0.50、0.25和0.10;加性高斯白噪声的均值为零、方差为0.10。
[0129]
为仿真次级通道的较大突变,实际次级通道s(z)采用线性fir模型,其截止频率为
0.5π,前半部分和后半部分的模型长度分别为51和31。次级通道估计模型长度为53,相应的系数更新步长为0.0005;辅助高斯白噪声v0(n)的均值为零、方差为0.25;辅助噪声调整模块(42)遗忘因子为0.9995。d阶延迟环节(31)的延迟长度为55;线性预测滤波器(32)的长度为128,其系数更新步长为0.001;控制器(21)采用线性滤波器,其长度为128,其系数的更新步长为0.000075;λ
m
、α、t
p
分别为0.98、1.1、20。独立运行次数为100次;仿真数据长度为60000。
[0130]
图2(a)为实施例三在仿真噪声与仿真次级通道情况下目标噪声和残余噪声的变化曲线;当系统达到稳态后,前半部分和后半部分的降噪量分别为10.84db和10.46db,相应的系统残余噪声能量分别约为0.15和0.16,其接近于目标噪声中加性高斯白噪声的方差,即趋于环境噪声水平,具有良好的目标噪声抑制性能。图2(b)为该情况下次级通道估计均方误差的变化曲线,图2(c)为该情况下辅助噪声调整增益的变化曲线,共同表明本发明系统不但能够有效跟踪次级通道的较大突变的情况,而且具有良好的次级通道在线辨识精度。
[0131]
实施例四:实际噪声与实际次级通道情形下的验证
[0132]
实际噪声源于工况下大型切割机械出料口的噪声,为仿真目标噪声的较大突变,目标噪声分为前后两半部分,前半部分对应转速为1400rpm、后半部分对应转速为1600rpm。实际次级通道为被同行广泛采用的iir模型(s.m.kuo and d.r.morgan,active noise control systems
‑
algorithms and dsp implementation,new york:wiley,1996.);次级通道估计模型长度为32,相应的系数更新步长为0.4;辅助高斯白噪声v0(n)的均值为零、方差为1.0;辅助噪声调整模块(42)遗忘因子为0.9995。d阶延迟环节(31)的延迟长度为61;线性预测滤波器(32)的长度为192,其系数更新步长为0.5;控制器(21)采用线性滤波器,其长度为192,其系数的更新步长为0.040;λ
m
、α、t
p
分别为0.98、1.8、20。独立运行次数为100次;实际数据长度为120000。
[0133]
图3(a)为实施例四在实际目标噪声与实际次级通道情况下目标噪声和残余噪声的变化曲线;图3(b)为该情况下辅助噪声调整增益的变化曲线;当系统达到稳态后,系统前半部分和后半部分的降噪量分别为10.55db和12.08db,表明本发明系统不仅能够有效估计iir类型的实际次级通道,还对产生较大突变的目标噪声具有良好的抑制性能。
[0134]
本发明实施例中的部分步骤,可以利用软件实现,相应的软件程序可以存储在可读取的存储介质中,如光盘或硬盘等。
[0135]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。