1.本发明属于语音识别技术领域,涉及语音识别阈值设置,具体涉及一种语音识别阈值设置方法。
背景技术:
2.随着技术迭代更新,语音识别技术日趋成熟,在实际产品如音响、玩具、家居中控等也得到广泛使用。目前主流的语音识别技术主要是通过深度神经网络学习的方式实现,深度神经网络学习包括训练和识别两个步骤,训练是通过语音到音节概率的计算得到声学模型,识别是根据声学模型和语言模型计算当前语音对应音节到文本的概率,实际应用中,对于语音识别本身而言,只有识别与未识别两种状态,故须将概率转变成二值量。通常的做法是设定一个概率(置信度)阈值,即,当获得的置信度值达到或超过阈值时,表明语音识别成功;反之为不成功。
3.阈值的确定通常是一个比较困难的问题,如果阈值设置过大,则会导致识别率下降,如果阈值设置过小,虽不影响识别率,但会增加集外误识别概率,降低识别体验。
技术实现要素:
4.为克服现有技术存在的技术缺陷,兼顾识别率和误识别,本发明提出了一种语音识别阈值设置方法。
5.本发明所述语音识别阈值设置方法,包括如下步骤:s1.确定识别函数和误识别函数;s2.对识别函数和误识别函数分别计算收益和损失,计算总收益gains,gains= gain
err
‑
loss
err
+gain
rec
‑
loss
rec
其中gain
rec
、loss
rec
、gain
err
、loss
err
分别为识别函数收益、识别函数损失、误识别函数收益、误识别函数损失;s3.对总收益gains,以置信度为变量进行求导,导数为零时的置信度值为置信度阈值。
6.优选的,识别函数和误识别函数分别为:rec(x)=
‑
ax2+bx+cerr(x)=
‑
ax2+mx+n其中, x为置信度,rec(x) 为识别次数、err(x) 为误识别次数;a,b,c,m,n为大于零的常数,且b≠m, c≠n;所述置信度阈值t = (n
‑
c)/(b
‑
m)。
7.本发明通过对识别和误识别的分析,通过最大收益的方法确定每个命令词的最佳置信度阈值,虽然略微降低新闻噪音下的识别率,但大幅降低了误识别率,提升了整体识别体验效果。
附图说明
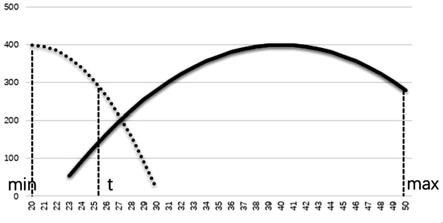
8.图1为本发明所述识别函数和误识别函数两条函数曲线的一个典型实例示意图;图1中实线曲线为识别函数,虚线曲线为误识别函数,横坐标为置信度阈值,单位为1%,纵坐标为次数,min,max分别为置信度阈值的区间左右端点。
具体实施方式
9.下面对本发明的具体实施方式作进一步的详细说明。
10.本发明所述语音识别阈值设置方法,包括如下步骤:s1.确定识别函数和误识别函数;s2.对识别函数和误识别函数分别计算收益和损失,计算总收益gains,gains= gain
err
‑
loss
err
+gain
rec
‑
loss
rec
其中gain
rec
、loss
rec
、gain
err
、loss
err
分别为识别函数收益、识别函数损失、误识别函数收益、误识别函数损失;s3.对总收益gains,以置信度为变量进行求导,导数为零时的置信度值为置信度阈值。
11.根据统计,识别时,纯净的目标词语音信号在送入神经网络得到的概率得分即置信度大部分分布在高分数段;而误识别时,因语音信号中包含与目标词中的一个或多个音节相近的音节,将整体置信度拉高导致误识发生,但误识别的置信度大部分分布在低分数段。
12.根据大量命令词的识别和误识别进行统计、拟合数据;一般的识别或误识别的置信度分布呈现如图1中err和rec两条函数曲线所示的规律。其中,实线为识别函数的置信度分布曲线rec,虚线为误识别函数的置信度曲线err。err和rec两函数可近似为如下形式:rec(x)=
‑
ax2+bx+c
ꢀꢀ
(1) err(x)=
‑
ax2+mx+n
ꢀꢀ
(2)其中, x为置信度,rec(x) 为识别次数、err(x) 为误识别次数;其中,a,b,c,m,n为大于零的常数,且b≠m, c≠n。x为置信度,;对于置信度区间内的所有置信度x,rec和err都是大于等于零的,实际中,根据命令词的组合方式不同,rec和err的开口大小和对称轴会不同,所以a,b,c,m,n的取值有所不同,但a,b,c,m,n的取值都是大于零的常数。
13.联合式(1)和式(2),即可求得两条曲线的交点x
o
为x
o =(n
‑
c)/(b
‑
m)
ꢀꢀꢀ
(3)为了兼顾识别和误识别,需要确定一个最佳的置信度阈值t,将问题进行简化,即求最大收益对应的置信度阈值t。
14.首先,在置信度区间[min,max]中计算识别函数收益gain
rec
和识别函数损失loss
rec
。
[0015]
收益指正确率,相应的损失是失误率。例如置信度阈值设置在0.25时,实测发现识别正确率97%,即收益为97%,损失为3%。
[0016]
置信度区间是置信度可能取值的范围,置信度阈值t位于置信度区间内;
(4)(5)其次,计算误识别函数收益gain
err
和误识别函数损失loss
err
(6)(7)最后,由式(1)
‑
(2)式及(4)
‑
(7)式可计算总收益gainsgains=
‑
(
‑
at3/3+bt2/2+ct)+(
‑
at3/3+mt2/2+nt)
‑
(
‑
at3/3+bt2/2+ct)
‑
(
‑
at3/3+mt2/2+nt)+const
ꢀꢀ‑‑‑
(8)其中,gain
rec
、loss
rec
、gain
err
、loss
err
分别为识别函数收益、识别函数损失、误识别函数收益、误识别函数损失;const为常数。
[0017]
整理(8)式并对t求导数得到gains’=
ꢀ‑
2(b
‑
m)t+2(n
‑
c)
ꢀꢀ
(9)当导数gains’为零时,总收益gains出现极大值,即总收益gains最大,此时的阈值为所求,由式(9)可得:t=(n
‑
c)/(b
‑
m)
ꢀꢀꢀ
(10)比较(3)式和(10)式,可以发现(10)式的物理意义为:置信度阈值的取值为识别和误识别分布曲线交点时,识别的收益最大,此时可得到最佳的识别体验效果。
[0018]
由上可知,总收益最大时的置信度阈值t与图1中识别与误识别分布曲线交点对应的置信度值一致。
[0019]
具体实施例:一般的,在声学模型训练出来时,通过大量测试集测试统计后确定一个初步的置信度阈值,如25。在此阈值下,识别效果能满足用户对语音识别的一般需求,但并不是最佳的体验效果。为了获取最佳的体验效果,考虑识别和误识别的平衡,需要单独对每个命令词的阈值进行确定。
[0020]
首先在初始设置置信度阈值25的条件下,选取10个不同声源如5男5女,分别在安静和新闻噪音下进行识别率测试,并根据测试结果统计识别打分分布;然后再选取12小时
综艺节目音频进行误识别测试,根据结果统计误识别打分分布。阈值为25时,部分命令词安静识别/误识别置信度分布如表1所示。
[0021]
表1的各个数字为置信度,表1中误识别测试时,使用12小时综艺节目音频,在这12个小时中,每个命令词误识的次数是不定的,误识测试时,每个命令词得到的打分个数不定。后续关注打分的分布,而不是打分个数多少。
[0022]
识别测试时,使用10人的声音,5男5女,每个命令词每人读一遍,故每个命令词测试结果对应10个打分,具体打分结果如表1所示。
[0023]
表1根据最大收益原则,结合识别和误识别的分布,单独对每个命令词的置信度阈值利用本发明所述方法进行调整,即根据(10)式得到置信度阈值。
[0024]
前后对比结果如表2所示。
[0025]
表2单独对每个命令词确认阈值后,再次对误识别和识别进行测试和确认,误识别数
据如表3所示;安静和噪音条件下的识别率如表4所示。
[0026]
表3是表1和表2置信度阈值调整前后的误识别次数对比测试结果,由表3可知,误识别次数相对于单独调整阈值前降低了51.05%,说明在对每个命令词调整置信度阈值后,整体的误识别次数大幅下降超过50%,提高了正确识别率。
[0027]
表4是表1和表2置信度阈值调整前后的识别次数对比测试结果,,说明在对每个命令词调整置信度阈值后,整体的识别率下降很少。
[0028]
综合表3和表4可以看出,调整置信度阈值后,误识别次数下降显著而识别次数基本维持,整体识别效果取得了提升。
[0029]
表3表4通过单独对每个命令词进行阈值调整后,略微降低新闻噪音下的识别率来大幅降低误识别,从而提高了用户的识别体验效果。
[0030]
前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。