1.本发明涉及声场景分类技术领域,具体为基于伽马通频谱分离的声场景分类方法。
背景技术:
2.声音是传递信息的重要媒介,也是人类听觉感知系统的重要组成部分。在对复杂环境中的声音事件进行感知方面,人类的固有能力使其不仅能同时捕捉多个声源的信息,如交谈声、敲门声和手机铃声等,且能有选择地屏蔽周围的背景噪音,如空调声、键盘敲击声等。当前,随着智能技术的快速发展,许多智能设备虽能高效地识别语音信息和声纹信息,但对复杂环境中的声音事件进行分类识别时,往往会因为背景噪音的影响,而导致分类识别的准确率不高。
技术实现要素:
3.为了解决因背景噪音导致生场景分类识别准确率低的问题,本发明提供基于伽马通频谱分离的声场景分类方法,其可以有效地减少背景噪音的影响,提高声音分类识别的准确率。
4.本发明的技术方案是这样的:基于伽马通频谱分离的声场景分类方法,其包括以下步骤:
5.s1:采集原始音频样本信息,对其进行预处理;
6.s2:将预处理后的所述原始音频样本信息经过傅里叶变换处理,经过用于提取声学特征的伽马通滤波器处理,得到所述原始音频样本信息对应的伽马通频谱图,记做伽马通频谱图;
7.其特征在于,其还包括以下步骤:
8.s3:将所述伽马通频谱图的时域分量和频域分量分别进行中值滤波计算,得到所述伽马通频谱图的谐波增强部分和打击源增强部分;
9.s4:定义所述所述伽马通频谱图的残差部分,并计算出所述伽马通频谱图的谐波增强部分、打击源增强部分和残差部分的相对分量;
10.s5:基于所述伽马通频谱图,结合所述谐波增强部分、所述打击源增强部分和所述残差部分的相对分量,计算得到所述伽马通频谱图的谐波分量、打击源分量以及残差分量;
11.s6:构建声场景分类模型;
12.s7:将所述伽马通频谱图的所述谐波分量、所述打击源分量、所述残差分量三种声学特征作为训练用数据,输入所述声场景分类模型进行训练,得到训练好的所述声场景分类模型;
13.s8:将待分类音频样本信息,进行特征分离处理,将得到对应的谐波分量、打击源分量以及残差分量,输入到所述训练好的所述声场景分类模型中,得到分类结果。
14.其进一步特征在于:
15.步骤s2中,所述伽马通滤波器组的脉冲响应的经典模型为:
[0016][0017]
f是是基于赫兹尺度的频率;
[0018]
步骤s3中,所述伽马通频谱图的谐波增强部分和打击源增强部分的计算方法如下:
[0019]
将所述伽马通频谱图sg的时域分量s
g
(t)和频域分量s
g
(f)的绝对值,作为输入信号输入中值滤波器:
[0020]
y(a)=m{x(a),l}=median{x(a
‑
j,a+j),j=(l
‑
1)/2}
[0021]
式中,median(.)为中值滤波器,a为信号值,l为滤波器总长度,j为滤波器左右方向的有效长度,x(.)为输入信号;
[0022]
输出信号为所述伽马通频谱图sg的谐波增强部分h
g
和打击源增强部分p
g
;
[0023][0024]
式中,l
p
为打击源增强部分的滤波器长度,l
h
为谐波增强部分的滤波器长度;
[0025]
步骤s4中,所述伽马通频谱图的残差部分r
g
定义为:
[0026]
r
g
=|s
g
|
‑
(p
g
+h
g
)
[0027]
步骤s4所述伽马通频谱图谐波增强部分、打击源增强部分和残差部分的相对分量m
hg
、m
pg
和m
rg
的计算公式为;
[0028][0029]
式中表示伽马通谐波增强部分的能量,表示伽马通打击源增强部分的能量,表示伽马通残差部分的能量,p为能量系数;
[0030]
步骤s5中,到所述伽马通频谱图的谐波分量gshc、打击源分量gspc以及残差分量gsrc的定义如下:
[0031][0032]
式中表示两矩阵对应位置元素相乘,结果为同型矩阵;
[0033]
步骤s6中,基于cnn构建所述声场景分类模型;
[0034]
所述声场景分类模型包括:通道数递增的连续的conv层,所述conve层的最后设置一个全连接层;
[0035]
每个所述conv层包括:两个连续的卷积层;每个所述卷积层后面分别依次跟着一
个br层、一个最大池化层;所述br层基于relu函数实现;
[0036]
基于所述声场景分类模型进行分类前,将所述谐波分量、所述打击源分量、所述残差分量三种声学特征输入所述声场景分类模型时,需在声学特征数据的维度的基础上增加一维表示通道数的向量;
[0037]
训练好的所述声场景分类模型通过softmax函数输出分类预测;
[0038]
步骤s1中,所述原始音频样本信息包括:音频时长和采样频率,所述预处理包括:预加重、分帧、加窗。
[0039]
本发明提供的基于伽马通频谱分离的声场景分类方法,其利用伽马通频谱图,并将音频样本信息分离出谐波分量、打击源分量以及残差分量三个部分,基于伽马通频谱图的残差分量,能够有效减少背景噪音中的谐波噪音和打击源噪音,以达到降低背景噪音的效果,进而提升了声场景分类模型的分类准确率,同时提高了声场景分类模型的泛化能力。
附图说明
[0040]
图1为本发明中伽马通频谱分离原理示意图;
[0041]
图2为本发明中声场景分类模型的网络结构示意图。
具体实施方式
[0042]
本发明基于伽马通频谱分离的声场景分类方法,首先对原始音频数据进行频谱分离操作,具体步骤如图1所示。
[0043]
s1:采集原始音频样本信息,对其进行预处理;
[0044]
本实施例中,原始音频样本信息包括:音频时长和采样频率,预处理包括:预加重、分帧、加窗。
[0045]
s2:将预处理后的原始音频样本信息经过傅里叶变换处理得到频谱图s;
[0046]
对于频谱图s经过用于提取声学特征的伽马通滤波器处理,得到原始音频样本信息对应的伽马通频谱图,记做伽马通频谱图sg。
[0047]
本专利中的声学特征提取方法是以频谱图的谐波打击源分离方法为基础,结合伽马通滤波器的特点提出的一种特征提取方法。伽马通语谱图(gamma
‑
tone spectrogram,gts)和伽马通频率倒谱系数(gamma
‑
tone frequency cepstral coefficients,gfcc)是基于等效矩形带宽频率尺度的伽马通滤波器组得到的声学特征。
[0048]
gamma
‑
tone滤波器组是耳蜗标准滤波器。它是模拟人耳听觉系统的滤波器组。gamma
‑
tone(伽马通语)滤波器组脉冲响应的经典模型为:
[0049][0050]
其中,f是基于赫兹尺度的频率;
[0051]
将频谱图s通过上述伽马通滤波器组得到伽马通频谱图s
g
。
[0052]
s3:将伽马通频谱图的时域分量和频域分量分别进行中值滤波计算,得到伽马通频谱图的谐波增强部分和打击源增强部分;
[0053]
伽马通频谱图的谐波增强部分和打击源增强部分的计算方法如下:
[0054]
将伽马通频谱图sg的时域分量s
g
(t)和频域分量s
g
(f)的绝对值,作为输入信号输
入中值滤波器:
[0055]
y(a)=m{x(a),l}=median{x(a
‑
j,a+j),j=(l
‑
1)/2}
[0056]
式中,median(.)为中值滤波器,a为信号值,l为滤波器总长度,j为滤波器左右方向的有效长度,x(.)为输入信号;
[0057]
输出信号为伽马通频谱图sg的谐波增强部分h
g
和打击源增强部分p
g
,具体如下所示:
[0058][0059]
式中,l
p
为打击源增强部分的滤波器长度,l
h
为谐波增强部分的滤波器长度。
[0060]
s4:定义伽马通频谱图的残差部分,并计算出伽马通频谱图的谐波增强部分、打击源增强部分和残差部分的相对分量;
[0061]
伽马通频谱图的残差部分r
g
定义为:
[0062]
r
g
=|s
g
|
‑
(p
g
+h
g
)
[0063]
其中,伽马通频谱图谐波增强部分、打击源增强部分和残差部分的相对分量m
hg
、m
pg
和m
rg
的计算公式为;
[0064][0065]
式中表示伽马通谐波增强部分的能量,表示伽马通打击源增强部分的能量,表示伽马通残差部分的能量,p为能量系数。
[0066]
s5:基于伽马通频谱图,结合谐波增强部分、打击源增强部分和残差部分的相对分量,计算得到伽马通频谱图的谐波分量、打击源分量以及残差分量;
[0067]
到伽马通频谱图的伽马通频谱图谐波分量(gamma
‑
tone spectrogram harmonic component,以下简称谐波分量gshc)、伽马通频谱图打击源分量(gamma
‑
tone spectrogram percussive
‑
source component,以下简称打击源分量gspc)以及伽马通频谱图谐波分量(gamma
‑
tone spectrogram residual component,以下谐波分量gsrc)的定义如下:
[0068][0069]
式中表示两矩阵对应位置元素相乘,结果为同型矩阵。
[0070]
s6:构建声场景分类模型;
[0071]
本发明技术方案中,基于cnn构建声场景分类模型;
[0072]
声场景分类模型包括:通道数递增的连续的conv层,conve层的最后设置一个全连接层;
[0073]
每个conv层包括:两个连续的卷积层;每个卷积层后面分别依次跟着一个br层、一个最大池化层;最后声场景分类模型通过softmax函数输出分类预测。
[0074]
即:conv层的结构为:
[0075]
卷积层+br层+最大池化层+卷积层+br层+最大池化层;
[0076]
本实施例中,cnn网络的主体结构是由三组通道数递增的conv层和一个全连接层组成,如图2所示,声场景分类模型的网络结构为:
[0077]
输入层(input)+conv层+conv层+conv层+全连接层+输出层(softmax)。
[0078]
设置conv层中的每一个卷积层中卷积核的尺寸为3
×
3,且卷积核在特征图上均匀扫过的步长设置为1,br层是由批归一化batch
‑
normalization和激活函数rectified linear unit(简称relu)组成,其计算公式为:
[0079][0080]
全连接层是利用全局平均池化处理,将卷积操作后的特征图层池化为一维数据,并在池化处理后使用dropout处理,舍弃部分网络节点来降低模型出现过拟合的风险。
[0081]
最后声场景分类模型通过softmax函数输出分类预测,softmax计算公式为
[0082][0083]
s
i
表示softmax函数,i为正整数,z
i
全连接层的输出值。
[0084]
s7:将伽马通频谱图的谐波分量、打击源分量、残差分量三种声学特征作为训练用数据,输入声场景分类模型进行训练,得到训练好的声场景分类模型;
[0085]
其中,基于声场景分类模型进行分类前,将谐波分量、打击源分量、残差分量三种声学特征输入声场景分类模型时,需在声学特征数据的维度的基础上增加一维表示通道数的向量。
[0086]
如图2所示,为本发明中主体网络的连接示意图,以gshc特征输入为例,声学特征的特征向量输入网络进行训练之前,需要在原有的2维向量的基础上,增加一维表示通道数的向量,来适应网络中的卷积操作,即,将三种声学特征的特征向量均扩展为分别表示(帧数、特征维数、通道数)的三维向量;如:gshc特征向量原始为2维向量:(174,128),扩展后为:(174,128,1)。
[0087]
特征向量输入图2所述的声场景分类模型后,首先经过三组通道数递增的conv层,其中,第一组conv层中包含两个通道数为32,卷积核尺寸为3,卷积核滑动步长为1的卷积层以及两组批标准化(batch
‑
normalization)处理和激活函数rectified linear unit(简称relu)处理,卷积核通过均匀扫过特征图来实现卷积操作,以一个卷积核的卷积操作为例,其计算公式为:
[0088][0089]
其中,求和∑表示卷积层前向传播的过程,i表示输入的特征图,s表示输出的特征图,k表示卷积核,
[0090]
*表示卷积运算,(i,j)表示特征图上的特征向量,(m,n)表示卷积核的尺寸。
[0091]
然后采用最大池化处理,并设置池化尺寸为3
×
3;第二组conv层的参数设置较第
一组conv层只改变了通道个数和池化尺寸,其两个通道数为64,池化尺寸为3
×
3;第三组conv层的参数设置较第二组conv层只改变了通道个数,其两个通道数为128。从conv层输出的特征图层进入全连接层,先通过全局平均池化处理将特征图层池化为一维数据,再经过全连接处理得到长度为256的一维特征数据,最后通过dropout处理来降低模型过拟合的概率。将输出后的特征数据再通过全连接处理得到长度为256的一维特征数据,以及dropout处理来降低模型过拟合的概率,最后通过归一化指数函数softmax处理后,输出最终分类预测结果。
[0092]
s8:使用训练好的声场景分类模型进行分类操作时,将待分类音频样本信息,进行特征分离处理,将得到对应的谐波分量、打击源分量以及残差分量,输入到训练好的声场景分类模型中,得到分类结果。
[0093]
为了确认本发明技术方案中的基于伽马通频谱分离的声场景分类方法的性能,在window10系统、显卡gtx1660ti、cpu为i7
‑
9750h、内存32g的实验环境下,使用keras+tensorflow作为深度学习框架,采用城市声音事件分类标准数据集urbansound8k,其中:fold1
‑
9作为训练集,训练集样本个数为7895;测试集为fold10中wav音频文件,样本个数为838;分别进行以下实验:
[0094]
(1)数据增强对模型影响的对比实验,
[0095]
(2)多声学特征和单一声学特征对模型影响的对比试验;
[0096]
(3)通过环境音频数据集esc50来检验伽马通频谱分离的声场景分类方法的泛化能力。
[0097]
利用本专利中的声场景分类模型(图中标记为cnn)和常用的resnet18模型作为分类模型,以伽马通频谱图(gamma
‑
tone spectrogram,以下简称gts)、gshc、gspc以及gsrc作为输入数据,在urbansound8k和esc
‑
50数据集上进行声场景分类实验,并对比分类准确率的变化情况,具体结果如表1所示:
[0098]
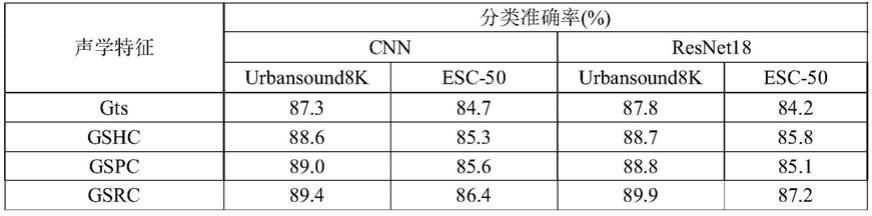
表1伽马通频谱图分离实验
[0099][0100]
传统的音频数据分类方法中,主要采用未经处理的频谱图特征作为输入数据,这会导致音频样本中的背景噪音对分类模型产生较大的影响。表1中给出不同声学特征输入的声场景分类准确率对比,可以从表1中的实验数据看出,相较于未经处理的伽马通频谱图特征(gts),将经过特征分离的gshc、gspc和gsrc输入cnn网络时,模型的分类准确率均有所提升,在两个数据集上平均提升了1.7%和1.1%,其中gsrc特征的准确率在两个数据集上均达到最高,分别为89.4%和86.4%。
[0101]
而在基于resnet18模型的分类结果数据中,相较于未经处理的伽马通频谱图特征(gts),将特征分离后的gshc、gspc和gsrc输入resnet18网络时,resnet18模型的分类准确率也是同样地均有所提升,在两个数据集上平均提升了1.3%和1.8%,其中gsrc特征的准
确率在两个数据集上均达到最高,分别为89.9%和87.2%。
[0102]
综上所述,基于表1的分类准确率数据可以得到,特征分离后得到的特征相比原始特征输入在分类准确率方面有一定的提升,且gsrc特征能有效减少背景噪音的影响从而提高模型的准确率。本发明提供的声场景分类方法,在处理音频数据时,引入了伽马通频谱图分离方式,将待分类音频数据尽心频谱分离,将其分离出:谐波分量、打击源分量以及残差分量,然后输入声场景分类模型中,使得声场景分类模型的准确率以及泛化能力都有一定的提升。