使用线索的聚类的语音增强
背景技术:
1.语音增强模块的性能取决于滤除所有干扰信号、仅留下期望的语音信号的能力。干扰信号可能是例如其他说话者、来自空调的噪声、音乐、马达噪声(例如在汽车或飞机中)和也称为“鸡尾酒派对噪声”的大的人群噪声。语音增强模块的性能通常通过其改进语音噪声比(snr)或语音干扰比(sir)的能力来衡量,语音噪声比和语音干扰比分别反映期望的语音信号的功率与噪声的总功率的比和期望的语音信号的功率与其他干扰信号的总功率的比(通常以db为单位)。
2.越来越需要在混响环境中执行语音增强。
技术实现要素:
3.可以提供用于语音增强的方法,所述方法可以包括:接收或生成声音样本,所述声音样本表示在给定的时间段期间由麦克风(microphone,传声器)阵列接收的声音信号;对所述声音样本进行频率变换,以提供经频率变换的样本;将所述经频率变换的样本根据说话者进行聚类,以提供说话者相关的聚类,其中所述聚类可以基于(i)与接收的声音信号相关的空间线索和(ii)与所述说话者相关的声学线索;为所述说话者中的每个说话者确定相对传递函数,以提供说话者相关的相对传递函数;在所述说话者相关的相对传递函数上应用多输入多输出(mimo)波束成形操作,以提供波束成形的信号;对所述波束成形的信号进行逆频率变换,以提供语音信号。
4.所述方法可以包括生成与所述说话者相关的声学线索。
5.所述声学线索的生成可以包括:在所述声音样本中搜索关键字;以及
6.从所述关键字提取所述声学线索。
7.所述方法可以包括提取与所述关键字相关的空间线索。
8.所述方法可以包括使用与所述关键字相关的空间线索作为聚类种子(seed)。
9.所述声学线索可以包括音高频率、音高强度、一个或多个音高频率谐波以及所述一个或多个音高频率谐波的强度。
10.所述方法可以包括将可靠性属性与每个音高相关联并且当所述音高的可靠性下降到预定义的阈值以下时确定可以与所述音高相关联的说话者可以是沉默的。
11.所述聚类可以包括处理所述经频率变换的样本,以提供所述声学线索和所述空间线索;使用所述声学线索追踪说话者的随时间变化的状态;将所述经频率变换的信号的每个频率分量的所述空间线索分割成组;并且将与当前活跃的(active)说话者相关的声学线索分配给每组经频率变换的信号。
12.所述分配可以包括对于每组经频率变换的信号计算时间频率图的等频率行(equal
‑
frequency lines)的元素与属于所述时间频率图的其他行并且可以与该组经频率变换的信号相关的元素之间的互相关。
13.所述追踪可以包括应用扩展卡尔曼滤波器。
14.所述追踪可以包括应用多假设追踪。
15.所述追踪可以包括应用粒子滤波器。
16.所述分割可以包括将与单个时间帧相关的单个频率分量分配给单个说话者。
17.所述方法可以包括监测语音速度、语音强度和情感表达(emotional utterance)中的至少一个监测的声学特征。
18.所述方法可以包括将所述至少一个监测的声学特征馈送到扩展卡尔曼滤波器。
19.所述经频率变换的样本可以被布置在多个向量中,所述麦克风阵列中的每个麦克风有一个向量;其中所述方法可以包括通过对所述多个向量进行加权平均来计算中间向量;以及通过忽略所述中间向量的具有可以低于预定义的阈值的值的元素来搜索声学线索候选。
20.所述方法可以包括将所述预定义的阈值确定为噪声的标准偏差的三倍。
21.可以提供一种非暂时性计算机可读介质,其存储指令,所述指令一旦被计算机化系统执行就导致所述计算机化系统:接收或生成声音样本,所述声音样本表示在给定的时间段期间由麦克风阵列接收的声音信号;对所述声音样本进行频率变换,以提供经频率变换的样本;将所述经频率变换的样本根据说话者进行聚类,以提供说话者相关的聚类,其中所述聚类可以基于(i)与接收的声音信号相关的空间线索和(ii)与所述说话者相关的声学线索;为所述说话者中的每个说话者确定相对传递函数,以提供说话者相关的相对传递函数;在所述说话者相关的相对传递函数上应用多输入多输出(mimo)波束成形操作,以提供波束成形的信号;对所述波束成形的信号进行逆频率变换,以提供语音信号。
22.所述非暂时性计算机可读介质可以存储用于生成与所述说话者相关的所述声学线索的指令。
23.所述声学线索的生成可以包括在所述声音样本中搜索关键字;以及
24.从所述关键字提取所述声学线索。
25.所述声学线索的生成可以包括在所述声音样本中搜索关键字;以及
26.从所述关键字提取所述声学线索。
27.所述非暂时性计算机可读介质可以存储用于提取与所述关键字相关的空间线索的指令。
28.所述非暂时性计算机可读介质可以存储用于使用与所述关键字相关的所述空间线索作为聚类种子的指令。
29.所述声学线索可以包括音高频率、音高强度、一个或多个音高频率谐波以及所述一个或多个音高频率谐波的强度。
30.所述非暂时性计算机可读介质可以存储用于将可靠性属性与每个音高相关联并且当所述音高的可靠性下降到预定义的阈值以下时确定可以与所述音高相关联的说话者可以是沉默的的指令。
31.所述聚类可以包括处理所述经频率变换的样本,以提供所述声学线索和所述空间线索;使用所述声学线索追踪说话者的随时间变化的状态;将所述经频率变换的信号的每个频率分量的所述空间线索分割成组;并且将与当前活跃的说话者相关的声学线索分配给每组经频率变换的信号。
32.所述分配可以包括对于每组经频率变换的信号计算时间频率图的等频率行的元素与属于所述时间频率图的其他行并且可以与该组经频率变换的信号相关的元素之间的
互相关。
33.所述追踪可以包括应用扩展卡尔曼滤波器。
34.所述追踪可以包括应用多假设追踪。
35.所述追踪可以包括应用粒子滤波器。
36.所述分割可以包括将与单个时间帧相关的单个频率分量分配给单个说话者。
37.所述非暂时性计算机可读介质可以存储用于监测语音速度、语音强度和情感表达中的至少一个监测的声学特征的指令。
38.所述非暂时性计算机可读介质可以存储用于将所述至少一个监测的声学特征馈送到扩展卡尔曼滤波器的指令。
39.所述经频率变换的样本可以被布置在多个向量中,所述麦克风阵列中的每个麦克风有一个向量;其中所述非暂时性计算机可读介质可以存储用于通过对所述多个向量进行加权平均来计算中间向量以及通过忽略所述中间向量的具有可以低于预定义的阈值的值的元素来搜索声学线索候选的指令。
40.所述非暂时性计算机可读介质可以存储用于将所述预定义的阈值确定为噪声的标准偏差的三倍的指令。
41.可以提供一种计算机化系统,其可以包括麦克风阵列、存储器单元和处理器。所述处理器可以被配置为接收或生成声音样本,所述声音样本表示在给定的时间段期间由麦克风阵列接收的声音信号;对所述声音样本进行频率变换,以提供经频率变换的样本;将所述经频率变换的样本根据说话者进行聚类,以提供说话者相关的聚类,其中所述聚类可以基于(i)与接收的声音信号相关的空间线索和(ii)与所述说话者相关的声学线索;为所述说话者中的每个说话者确定相对传递函数,以提供说话者相关的相对传递函数;在所述说话者相关的相对传递函数上应用多输入多输出(mimo)波束成形操作,以提供波束成形的信号;对所述波束成形的信号进行逆频率变换,以提供语音信号;并且其中所述存储器单元可以被配置为存储所述声音样本和所述语音信号中的至少一个。
42.所述计算机化系统可以不包括所述麦克风阵列,而是可以从所述麦克风阵列接收表示在给定的时间段期间由所述麦克风阵列接收的所述声音信号的信号。
43.所述处理器可以被配置为生成与所述说话者相关的所述声学线索。
44.所述声学线索的生成可以包括在所述声音样本中搜索关键字;以及
45.从所述关键字提取所述声学线索。
46.所述处理器可以被配置为提取与所述关键字相关的空间线索。
47.所述处理器可以被配置为使用与所述关键字相关的所述空间线索作为聚类种子。
48.所述声学线索可以包括音高频率、音高强度、一个或多个音高频率谐波以及所述一个或多个音高频率谐波的强度。
49.所述处理器可以被配置为将可靠性属性与每个音高相关联并且当所述音高的可靠性下降到预定义的阈值以下时确定可以与所述音高相关联的说话者可以是沉默的。
50.所述处理器可以被配置为通过处理所述经频率变换的样本进行聚类,以提供所述声学线索和所述空间线索;使用所述声学线索追踪说话者的随时间变化的状态;将所述经频率变换的信号中的每个频率分量的所述空间线索分割成组;并且将与当前活跃的说话者相关的声学线索分配给每组经频率变换的信号。
51.所述处理器可以被配置为通过对于每组经频率变换的信号计算时间频率图的等频率行的元素与属于所述时间频率图的其他行并且可以与该组经频率变换的信号相关的元素之间的互相关来分配。
52.所述处理器可以被配置为通过应用扩展卡尔曼滤波器来追踪。
53.所述处理器可以被配置为通过应用多假设追踪来追踪。
54.所述处理器可以被配置为通过应用粒子滤波器来追踪。
55.所述处理器可以被配置为通过将与单个时间帧相关的单个频率分量分配给单个说话者来分割。
56.所述处理器可以被配置为监测语音速度、语音强度和情感表达中的至少一个监测的声学特征。
57.所述处理器可以被配置为将所述至少一个监测的声学特征馈送到扩展卡尔曼滤波器。
58.所述经频率变换的样本可以被布置在多个向量中,所述麦克风阵列中的每个麦克风有一个向量;其中所述处理器可以被配置为通过对所述多个向量进行加权平均来计算中间向量;以及通过忽略所述中间向量的具有可以低于预定义的阈值的值的元素来搜索声学线索候选。
59.所述处理器可以被配置为将所述预定义的阈值确定为噪声的标准偏差的三倍。
附图说明
60.为了理解本发明并了解如何在实践中实施本发明,现在将参考附图仅通过非限制性示例的方式描述一个优选实施方案。
61.图1例示了多路径;
62.图2例示了一种方法的一个示例;
63.图3例示了图2的方法的聚类步骤的一个示例;
64.图4例示了时间
‑
频率图上的音高检测的一个示例;
65.图5例示了时间
‑
频率
‑
线索图(time
‑
frequency
‑
cue map)的一个示例;
66.图6例示了在离线训练中话音(voice)识别链的一个示例;
67.图7例示了在实时训练中话音识别链的一个示例;
68.图8例示了一种训练机制的一个示例;以及
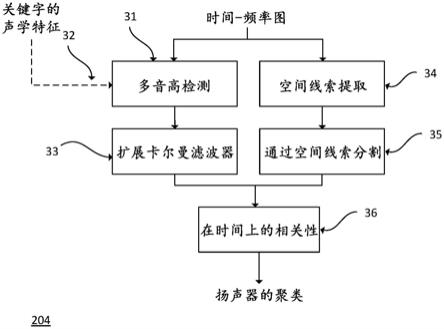
69.图9例示了一种方法的一个示例。
具体实施方式
70.对系统的任何引用经适当修改后应适用于由该系统执行的方法和/或存储指令的非暂时性计算机可读介质,所述指令一旦由该系统执行将导致该系统执行该方法。
71.对方法的任何引用经适当修改后应适用于被配置为执行该方法的系统和/或适用于存储指令的非暂时性计算机可读介质,所述指令一旦由该系统执行将导致该系统执行该方法。
72.对非暂时性计算机可读介质的任何引用经适当修改后应适用于由系统执行的方法和/或被配置为执行存储在该非暂时性计算机可读介质中的指令的系统。
73.术语“和/或”是附加地或替代地。
74.术语“系统”指计算机化系统。
75.语音增强方法专注于当信号受噪声和其他说话者干扰时从期望的源(说话者)提取语音信号。在自由场环境中,呈定向波束成形的形式的空间滤波是有效的。然而,在混响环境中,来自每个源的语音在数个方向上拖尾(模糊,smear),不一定是连续的,从而使普通波束成形器的优点减弱。使用基于传递函数(tf)的波束成形器来解决此问题,或使用相对传递函数(rtf)作为tf本身是有前途的方向。然而,在多说话者环境中,当语音信号被同时捕获时,估计用于每个说话者的rtf的能力仍然是一个挑战。提供了一种解决方案,该解决方案涉及追踪声学线索和空间线索以将同时进行的说话者聚类,从而便于在混响环境中估计说话者的rtf。
76.提供了一种说话者的聚类算法,该聚类算法将每个频率分量分配给其原始说话者,尤其是在多说话者混响环境中。这提供了rtf估计器在多说话者混响环境中正常工作的必要条件。对rtf矩阵的估计然后被用来计算基于传递函数的线性约束最小方差(tf
‑
lcmv)波束成形器的加权向量(参见后面的方程(10)),并且因此满足tf
‑
lcmv工作的必要条件。假设每个人类说话者被赋予不同的音高,使得音高对于说话者是双射指示符(bijective indicator)。已知多音高检测是一项具有挑战性的任务,尤其是在嘈杂、混响多说话者环境中。为了解决此挑战,采用w
‑
分离正交性(w
‑
disjoint orthogonality,w
‑
do)假设,并且使用空间线索的集合(例如信号强度、方位角和仰角)作为附加的特征。使用扩展卡尔曼滤波器(ekf)随时间追踪声学线索
‑
音高值,以克服暂时不活跃的(inactive)说话者和音高的变化,并且使用空间线索来分割最后的l频率分量并且将每个频率分量分配给不同的源。ekf和分割的结果通过互相关而组合,以便于将频率分量根据具有特定音高的特定说话者进行聚类。
77.图1描述了在混响环境中语音信号的频率分量从人类说话者11传播到麦克风阵列12所沿的路径。壁13和环境中的其他要素14以取决于壁的材料和纹理的衰减和反射角反射撞击的信号。人类语音的不同频率分量可能采取不同的路径。它们可能是位于人类说话者11和麦克风阵列12之间的最短路径上的直接路径15,或间接路径16、17。注意,频率分量可能沿一个或多个路径传播。
78.图2描述了算法。信号由麦克风阵列201获取,该麦克风阵列包含m≥2个麦克风,其中m=7个麦克风是一个示例。麦克风可以以一系列星座诸如等间距地部署在直线上、在圆形上或在球体上,或甚至非等间距地部署从而形成任意形状。来自每个麦克风的信号被采样、被数字化并且被存储在m个帧中,每个帧包含t个连续样本202。帧t的大小可以被选择为足够大使得短时傅里叶变换(stft)是准确的,但足够短使得信号沿等效持续时间是静止的(stationary)。对于16khz的采样率,t的典型值是4096个样本,换言之,该帧相当于1/4秒。通常,连续的帧彼此重叠,以在信号的特征随时间变化之后进行改进的追踪。典型的重叠是75%,换言之,每1024个样本启动一个新的帧。t的范围例如可以在0.1秒
‑
2秒之间——从而对于16khz的采样率采样1024
‑
32768个。所述样本也被称为表示在时间段t期间由麦克风阵列接收的声音信号的声音样本。
79.通过应用傅立叶变换或傅立叶变换的变体诸如短时傅立叶变换(stft)、常量q变换(cqt)、对数傅立叶变换(lft)、滤波器组等,在203中将每个帧变换到频域。可以应用多种
技术——诸如开窗(windowing)和补零(zero
‑
padding,零填充)——来控制成帧效果(framing effect)。203的结果是m个长度为k的复值向量。例如,如果阵列包括7个麦克风,准备7个向量,所述向量用帧时间索引登记。k是频率槽(frequency bin,频率窗口)的数目,并且由频率变换确定。例如,当使用普通stft时,k=t其是缓冲器的长度。步骤203的输出可以被称为经频率变换的信号。
80.在204中将语音信号根据不同的说话者进行聚类。聚类可以被称为说话者相关的聚类。与仅基于方向将说话者聚类的现有技术著作不同,204处理混响房间中的多个说话者,使得由于直接路径和间接路径,来自不同方向的信号可以被分配给同一个说话者。所提出的解决方案建议在空间线索的集合(例如在麦克风之一中的信号的方向(方位角和仰角)和强度)之上使用声学线索的集合(例如,音高频率和强度以及其谐波频率和强度)。音高和空间线索中的一个或多个被作为用于追踪算法(诸如卡尔曼滤波器以及其变体、多假设追踪(mht)或粒子滤波器)的状态向量,所述追踪算法被用来追踪此状态向量,并且将每个追踪分配给一个不同的说话者。
81.所有这些追踪算法都使用在时间上描述状态向量的动态的模型,使得当状态向量的测量结果丢失或被噪声破坏时,追踪算法使用该动态模型对此进行补偿,并且同时更新模型参数。此阶段的输出是一个向量,从而将给定的时间时的每个频率分量分配给每个说话者。204在图3中被进一步阐述。
82.在205中将rtf估计器应用于频域中的数据。此阶段的结果是rtf的集合,每个rtf被登记到一个相关联的说话者。使用来自将说话者聚类204的聚类阵列来完成登记过程。rtf的集合也被称为说话者相关的相对传递函数。
83.mimo波束成形器206通过空间滤波来使噪声的能量和干扰信号的能量相对于需要的语音信号的能量降低。步骤206的输出可以被称为波束成形的信号。然后波束成形的信号被转发到逆频率变换207,以创建呈样本流的形式的连续语音信号,该语音信号进而被传递到其他元件,诸如语音识别、通信系统和记录设备208。
84.在本发明的一个优选实施方案中,可以使用关键字识别(keyword spotting)209来改进聚类块204的性能。来自202的帧被搜索以寻找预定义的关键字(例如“hello alexa”或“ok google”)。一旦在帧的流中识别关键字,说话者的声学线索就被提取,诸如音高频率和强度以及其谐波频率和强度。此外,提取每个频率分量到达麦克风阵列201的路径的特征。这些特征由将说话者聚类204用作期望的说话者的聚类的种子。种子是关于聚类的初始参数的初始猜测。例如,对于基于形心的(centroid
‑
based)聚类算法的聚类的形心、半径和统计值,诸如k均值、pso和2kpm。另一个示例是用于基于子空间的聚类的子空间的基(base)。
85.图3描述了说话者的聚类算法。假设每个说话者被赋予不同的声学线索的集合,例如,音高频率和强度以及其谐波频率和强度,使得该声学线索的集合对于说话者是双射指示符。已知声学线索检测是一项具有挑战性的任务,尤其是在嘈杂、混响多说话者环境中。为了解决此挑战,使用例如信号强度、方位角和仰角的形式的空间线索。使用诸如粒子滤波器和扩展卡尔曼滤波器(ekf)的滤波器随时间追踪声学线索,以克服暂时不活跃的说话者和声学线索的变化,并且使用空间线索来在不同的源之间分割频率分量。ekf和分割的结果通过互相关而组合,以便于将频率分量根据具有特定音高的特定说话者进行聚类。
86.作为一个优选实施方案的一个示例,在31中,呈音高频率的形式的潜在声学线索被检测。首先,使用来自每个麦克风的缓冲器的频率变换来准备时间
‑
频率图,该频率变换在203中被计算。接下来,用一些加权因子对m个k长度的复值向量中的每个的绝对值进行加权平均,所述加权因子可以被确定,以减少一些麦克风中的伪影。结果是单个k长度的实向量。在此向量中,高于给定的阈值μ的值被提取,而其余元素被丢弃。阈值μ通常被适应性地选择为噪声的标准偏差的三倍,但不小于恒定值,该恒定值取决于系统的电气参数,并且尤其取决于采样信号的有效位的数目。具有在[k_min,k_max]的范围内的频率指数的值被定义为音高频率的候选。变量k_min和k_max通常分别为85hz和2550hz,因为典型的成年男性将具有从85hz至1800hz的基本频率,并且典型的成年女性具有从165hz至2550hz的基本频率。然后通过搜索其高次谐波(higher harmonics)来验证每个音高候选。2次谐波和3次谐波的存在可能是候选音高被检测为具有可靠性r(比如,r=10)的正当音高的先决条件。如果存在高次谐波(例如,4次和5次),音高的可靠性可以增加——例如,对于每个谐波该可靠性可以加倍。在图4中可以找到一个示例。在本发明的一个优选实施方案中,使用由期望的说话者发出的关键字通过210供应期望的说话者的音高32。将所供应的音高32以最大可能的可靠性(比如r=1000)添加到列表。
[0087]
在33中,扩展卡尔曼滤波器(ekf)被应用于来自31的音高。如关于扩展卡尔曼滤波器的维基百科条目(www.wikipedia.org/wiki/extended_kalman_filter)所指出的,卡尔曼滤波器具有状态转移方程(state transition equation)和观察模型(observation model)。对于离散计算,状态转移方程为:
[0088]
x
k
=f(x
k
‑1,u
k
)+w
k
ꢀꢀꢀ
(1)并且对于离散计算,观察模型为:
[0089]
z
k
=h(x
k
)+v
k
ꢀꢀꢀ
(2)
[0090]
其中x
k
是状态向量,其包含(部分地)描述系统的状态的参数,u
k
是提供关于系统的状态的信息的外部输入的向量,w
k
和v
k
是过程噪声和观察噪声。扩展卡尔曼滤波器的时间更新器可以使用预测方程来预测下一个状态,并且检测到的音高可以通过使用以下类型的方程将实际测量结果与预测测量结果进行比较来更新变量:
[0091]
y
k
=z
k
‑
h(x
k|k+1
)
ꢀꢀꢀ
(3)
[0092]
其中z
k
是检测到的音高,并且y
k
是测量结果和预测的音高之间的误差。
[0093]
在33中,每个轨迹可以从一个检测到的音高开始,随后是模型f(x
k
,u
k
),该模型反映音高的时间行为,该音高可能由于情绪而变得更高或更低。该模型的输入可以是过去的状态向量x
k
(一个状态向量或多个),以及影响音高的动态的任何外部输入u
k
,所述音高的动态诸如语音速度、语音强度和情感表达。状态向量x的元素可以定量地描述音高。例如,音高的状态向量尤其可能包括音高频率、1阶谐波的强度以及高次谐波的频率和强度。向量函数f(x
k
,u
k
)可以被用来预测在当前时间之前的某个给定的时间k+1时的状态向量x。ekf中的动态模型的示例性实现可以包括时间更新方程(也称为预测方程),如jerry m.mendel的书《lessons in digital estimation theory》中所描述的,该书通过引用并入本文。
[0094]
例如,考虑到3元组状态向量:
[0095][0096]
其中f
k
是在时间k时音高(1次谐波)的频率,a
k
是在时间k时音高(1次谐波)的强度,
并且b
k
是在时间k时2次谐波的强度。
[0097]
用于音高的示例性状态向量模型可以是:
[0098][0099]
其描述了一种假设总是恒定音高的模型。在本发明的一个优选实施方案中,使用本领域已知的语音识别算法的语音速度、语音强度和情感表达被连续地监测,从而提供改进ekf的时间更新阶段的外部输入u
k
。情感表达方法是本领域已知的。例如,参见palo等人的“new features for emotional speech recognition”。
[0100]
每个追踪被赋予可靠性场,该可靠性场与追踪仅使用时间更新来演变的时间成反比。当追踪的可靠性下降到比如表示10秒的未检测到的音高的某个可靠性阈值ρ以下时,该追踪被定义为死的(dead,不再有关的),这意味着相应的说话者不是活跃的。另一方面,当出现不能够被分配给任何现有追踪的新的测量结果(音高检测)时,启动新的追踪。
[0101]
在34中,从m个经频率变换的帧提取空间线索。如在31中,保存最近的l个向量,以使用在时间上的相关性进行分析。结果是时间
‑
频率
‑
线索(tfc)图,其对于m个麦克风中的每个是大小为lxkxp(其中p=m
‑
1)的3维阵列。图5描述了tfc。
[0102]
在35中,tfc中的每个频率分量的空间线索被分割。此想法是沿着l个帧,一个频率分量可能来源于不同的说话者,并且这可以通过比较空间线索观察到。然而,由于w
‑
do假设,假设在单个帧时间l时,频率分量来源于单个说话者。可以使用文献中的用于聚类的任何已知方法(诸如k最近邻(knn))来执行分割。聚类给a中的每个单元分配一个索引其指示单元(k,l)属于哪个聚类。
[0103]
在36中,信号的频率分量被分组,使得每个频率分量被分配给通过ekf追踪的音高的列表中的一个特定音高并且因其可靠性而是活跃的。这是通过计算分配给音高中的一个的时间
‑
频率图(参见图4)的第k行与该时间
‑
频率图中的其他行中的具有特定聚类索引c0(j,l)的所有值之间的样本互相关来完成的。这是对于每个聚类索引完成的。样本互相关由下式给出:
[0104][0105]
其中a是时间
‑
频率图,k是属于音高之一的行的索引,j是a的任何其他行,并且l是a的列的数目。在计算每个音高和其他行中的聚类中的每个之间的互相关之后,将行j1中具有最高互相关的聚类c1与相应的音高分组在一起,并且然后将行j2中具有第二最高互相关的聚类c2与相应的音高分组在一起,等等。重复此过程,直到样本互相关下降到某个阈值κ以下,该阈值可以被适应性地设置为比如0.5x(在单个频率,信号的平均能量)。35的结果是被赋予相应的音高频率的频率组的集合。
[0106]
图4描述了时间
‑
频率图上的音高检测的一个示例。41是时间轴,其由参数表示,并且42为频率轴,其由参数k描述。此二维阵列中的每个列是在时间时对m个经频率变换的缓冲器的绝对值进行平均之后在31中提取的k长度的实值向量。为了进行在时间上的相关性分析,将l个最近的向量保存在大小为kxl的二维阵列中。在43中,两个音高由不同方向的
对角线表示。由于存在4次谐波,音高k=2——其谐波在k=4,6,8处——具有可靠性r=20,并且在k=3处的音高——其谐波在k=6,9处——具有可靠性r=10。在44中,k=3的音高是不活跃的,并且只有k=2是活跃的。然而,由于未检测到4次谐波(在阈值μ以下),k=2的音高的可靠性降低到r=10。在45中,k=3的音高再次是活跃的,并且k=2是不活跃的。在46中,出现了k=4处的新音高候选,但是仅检测到它的2次谐波。因此,它未被检测为音高。在47中,k=3的音高是不活跃的,没有检测到音高。
[0107]
图5描述了tfc图,其轴是帧索引(时间)51、频率分量52和空间线索53,其可能是例如表达每个频率分量到达的方向(方位角和仰角)和分量强度的复值。当具有索引的帧被处理并且被传递到频域时,对于每个频率元素接收m个复数的向量。从每个向量提取多达m
‑
1个空间线索。在每个频率分量的方向和强度的示例中,这可能使用本领域已知的用于阵列处理的任何测向算法(诸如music或esprit)来完成。此算法的结果是在三维空间中多达m
‑
1个方向的集合,每个由两个角和到达信号的估计强度表达,强度线索被布置在tfc图中,使得在由k0,p0索引的单元处。
[0108]
附录
[0109]
语音增强模块的性能取决于滤除所有干扰信号、仅留下期望的语音信号的能力。干扰信号可能是例如其他说话者、来自空调的噪声、音乐、马达噪声(例如在汽车或飞机中)和也称为“鸡尾酒派对噪声”的大的人群噪声。语音增强模块的性能通常通过其改进语音噪声比(snr)或语音干扰比(sir)的能力来衡量,语音噪声比和语音干扰比分别反映期望的语音信号的功率与噪声的总功率的比和期望的语音信号的功率与其他干扰信号的总功率的比(通常以db为单位)。
[0110]
当采集模块包含单个麦克风时,方法被称为单麦克风语音增强并且通常基于信号本身在时间
‑
频率域中的统计特征,诸如单通道谱减法(single channel spectral subtraction)、使用最小方差无失真响应(mvdr)的谱估计和回声消除。当使用不止单个麦克风时,采集模块通常被称为麦克风阵列,并且方法被称为多麦克风语音增强。许多这些方法利用由麦克风同时捕获的信号之间的差异。一种得到确认的方法是波束成形,其在将每个信号乘以加权因子之后计算来自麦克风的信号的总数。加权因子的目标是均和(average out)干扰信号,以便调节感兴趣的信号。
[0111]
换句话说,波束成形是一种创建空间滤波器的方法,该空间滤波器在算法上增加从空间中的给定的位置发射的信号(来自期望的说话者的期望的信号)的功率,并且降低从空间中的其他位置发射的信号(来自其他源的干扰信号)的功率,从而增加波束成形器输出处的sir。
[0112]
延迟和求和波束成形器(delay
‑
and
‑
sum beamformer,dsb)涉及使用dsb的加权因子,所述加权因子由期望的信号从其源传播到阵列中的每个麦克风所沿的不同路线所隐含的计数器延迟组成。dsb被限制于各自来自单个方向的信号,诸如在自由场环境中。因此,在混响环境中,来自相同的源的信号沿着不同的路线传播到麦克风并且从多个方向到达麦克风,dsb性能通常是不足够的。
[0113]
为了减轻在混响环境中dsb的缺点,波束成形器可以使用更复杂的声学传递函数(atf),其表示每个频率分量从给定的源到达特定的麦克风的方向(方位角和仰角)。由dsb和其他基于doa的方法假设的单个到达方向(doa)在混响环境中通常不适用,其中同一语音信号的分量从不同方向到达。这是因为混响环境中的物理要素(诸如壁、家具和人)的不同频率响应。频域中的atf是给奈奎斯特(nyquist)带宽中的每个频率分配复数的向量。绝对值表示与此频率相关的路径增益,并且相位指示沿该路径添加到频率分量的相位。
[0114]
估计空间中的给定的点和给定的麦克风之间的atf可以通过使用定位在该给定的点处并且发射已知的信号的扬声器来完成。同时取得来自说话者的输入的信号和麦克风的输出的信号,人们可以很容易地估计atf。扬声器可以位于在系统运行期间人类说话者可能驻留的一个或多个位置处。此方法为空间中的每个点或更实际地为网格上的每个点创建atf的图。未包含在网格中的点的atf使用插值法进行近似。尽管如此——此方法存在严重缺点。首先,每次安装都需要校准系统,从而使此方法不切实际。其次,人类说话者和电子扬声器之间的声学差异,这使测量的atf偏离实际的atf。第三,测量大量的atf的复杂性,尤其是当还考虑说话者的方向时,以及第四,由于环境改变导致的可能误差。
[0115]
atf的一个更实用的替代方案是相对传递函数(rtf)作为对在实际应用中atf估计方法的缺点的补救。rtf是给定的源与阵列中的麦克风中的两个之间的atf之间的差异,在频域中,该差异采取两个atf的谱表示之间的比的形式。像atf一样,频域中的rtf给每个频率分配复数。绝对值是两个麦克风之间的增益差异,当麦克风彼此靠近时,该增益差异通常接近于1(unity),并且在一些条件下,相位反映源的入射角。
[0116]
基于传递函数的线性约束最小方差(tf
‑
lcmv)波束成形器可以减少噪声同时限制语音失真,在多麦克风应用中,通过在输出信号中的语音分量等于麦克风信号之一中的语音分量的约束下使输出能量最小化。如果n=n
d
+n
i
个源,考虑到提取受n
i
个干扰源和平稳噪声(stationary noise)污染的n
d
个期望的语音源的问题。所涉及的信号中的每个通过声学介质传播,之后由包括m个麦克风的任意阵列拾取。每个麦克风的信号被分割成长度为t的帧,并且fft被应用于每个帧。在频域中,让我们用和分别表示第m麦克风和第n源的第帧的第k频率分量。类似地,第n源和第m麦克风之间的atf为并且第m麦克风处的噪声为呈矩阵的形式的接收信号由下式给出:
[0117][0118]
其中是传感器矢量,是源矢量,是atf矩阵,使得并且是与任何源不相关的加性(additive)平稳噪声。等效地,(7)可以使用rtf公式化。在不丧失一般性的情况下,第n语音源的rtf可以被定义为第m麦克风处的第n语音分量与其在第一个麦克风处的相应的分量之间的比,即中的信号可以使用
detection),也称为话音活动检测(voice activity detection,vad),使得关于在特定时间活跃的源的信息被用来解决混合矩阵中的歧义。vad的缺点是不能够鲁棒地检测到话音暂停,尤其是在多说话者环境中。此外,此方法仅在每次不多于单个说话者加入对话时才有效,需要相对长的训练周期,并且在此周期期间对运动敏感。
[0132]
tf
‑
lcmv波束成形器以及其扩展形式可以连同双耳线索发生器用于双耳语音增强系统。声学线索被用来使语音分量与输入信号中的噪声分量分离。该技术基于听觉场景分析理论1,该理论建议使用独特的感知线索来在“鸡尾酒派对”环境中将来自不同语音源的信号聚类。可以被用于语音分离的原始分组线索的示例包括跨频带的常见起始/偏移、音高(基本频率)、空间中的同一位置、时间和谱调制、音高和能量连续性和平滑度。然而,此方法的隐含假设是期望的语音信号的所有分量几乎都具有相同的方向。换言之,几乎自由场条件,节省了头影效应(head
‑
shadow effect)的影响,该头影效应被建议通过使用头相关的(head related)传递函数进行补偿。这在混响环境中不太可能发生。
[0133]
需要注意的是,即使当多个说话者同时是活跃的时,说话者的谱内容在大多数时间
‑
频率点处不重叠。这被称为w
‑
分离正交性,或被简称w
‑
do。这可以通过时间
‑
频率域中语音信号的稀疏性来证明。根据此稀疏性,在一个特定的时间
‑
频率点中两个说话者的同时活动的概率非常低。换句话说,在多个同时进行的说话者的情况下,每个时间
‑
频率点最有可能对应于说话者中的一个的谱内容。
[0134]
w
‑
do可以被用来通过定义在某种程度上是w
‑
do的特定的一类信号来便于bss。这可以仅在需要一阶统计数据时使用,这是计算上经济的。此外,倘若源是w
‑
do并且不占据相同的空间位置,可以仅使用两个麦克风对任意数目的信号源进行解混(de
‑
mix)。然而,此方法假设跨所有频率底层混合矩阵相同。此假设对于使用跨不同频率的估计混合系数的直方图是必要的。然而,此假设在混响环境中通常不成立,而仅在自由场中成立。此方法到多路径情况的扩展被限制到来自多路径的可忽略的能量,或被限制到足够平滑的卷积混合滤波器,使得直方图被拖尾,但维持单个峰值。此假设在混响环境中也不成立,在混响环境中,不同路径之间的差异通常太大而无法创建平滑的直方图。
[0135]
已经发现,所建议的解决方案在混响环境中执行并且不必依赖于不必要的假设和约束。即使没有先验信息,即使没有大训练过程,即使没有将给定的源在每个频率的衰减和延迟的估计约束到衰减
‑
延迟空间中的单个点,即使没有约束单个源的衰减
‑
延迟值的估计值以创建单个聚类,以及即使没有将混合的声音的数目限制到两个,该解决方案也可以运行。
[0136]
源分离到语音识别引擎
[0137]
话音用户接口(vui)是人类说话者和机器之间的接口。vui使用一个或多个麦克风接收语音信号并且将语音信号转换成数字签名(signature),通常通过将语音信号转录为文本,该文本被用来推断说话者的意图。然后,机器可以基于机器被设计用于的应用来响应说话者的意图。
[0138]
vui的关键部件是自动语音识别引擎(asr),该自动语音识别引擎将数字化语音信号转换成文本。asr的性能,换言之,文本描述声学语音信号的准确程度,在很大程度上取决于输入信号与asr的要求的匹配。因此,vui的其他部件被设计以在将获取的语音信号馈送到asr之前对其进行增强。这样的部件可能是噪声抑制、回声消除和源分离,仅举几例。
[0139]
语音增强中的关键部件之一是源分离(ss),其意在用于分离来自数个源的语音信号。假设两个或更多个麦克风的阵列,麦克风中的每个所获取的信号是环境中的所有语音信号加上其他干扰(诸如噪声和音乐)的混合物。ss算法从所有麦克风取得混合信号并且将它们分解为它们的分量。换言之,源分离的输出是一组信号,每个代表一个特定的源的信号,无论是来自特定的说话者的语音信号还是音乐或甚至噪声。
[0140]
越来越需要改进源分离。
[0141]
图6例示了在离线训练中话音识别链的一个示例。该链通常包括麦克风阵列511,该麦克风阵列提供数字化声学信号的集合。数字化声学信号的数目等于组成阵列511的麦克风的数目。每个数字化声学信号包含麦克风阵列511附近的所有声学源的混合物,无论是人类说话者、合成说话者诸如tv、音乐和噪声。数字化声学信号被递送到预处理阶段512。预处理阶段512的目的是通过去除诸如回声、混响和噪声的干扰来改进数字化声学信号的质量。通常使用采用数字化声学信号之间的统计关联的多通道算法执行预处理阶段512。预处理阶段512的输出是经处理的信号的集合,通常具有与至该阶段的输入处的数字化声学信号的数目相同数目的信号。该经处理的信号的集合被转发到源分离(ss)阶段513,该源分离阶段旨在从麦克风阵列附近的每个源提取声学信号。换句话说,ss阶段513取得信号的集合,每个信号是从不同的源接收的声学信号的不同混合物,并且创建信号的集合,使得每个信号主要包含来自单个特定的源的单个声学信号。可以使用诸如波束成形的源的部署的几何考虑或通过考虑诸如独立分量分析的语音信号的特性来执行语音信号的源分离。分离的信号的数目通常等于麦克风阵列511附近的活跃的源的数目,但小于麦克风的数目。该分离的信号的集合被转发到源选择器514。源选择器的目的是选择其语音信号应被识别的相关的语音源。源选择器514可以使用触发字检测器,使得发出预定义的触发字音的源被选择。替代地,源选择器514可以考虑在麦克风阵列511附近的源的位置,诸如相对于麦克风阵列511的预定义的方向。此外,源选择器514可以使用语音信号的预定义的声学签名来选择与此签名匹配的源。源选择器514的输出单个语音信号,该单个语音信号被转发到语音识别引擎515。语音识别引擎515将数字化语音信号转换成文本。存在许多本领域已知的用于语音识别的方法,它们中的大多数基于从语音信号提取特征并且将这些特征与预定义的词汇进行比较。语音识别引擎515的主要输出是与输入语音信号相关联的文本串516。在离线训练中对麦克风发出预定义的文本518音。通过将asr 516的输出与此文本进行比较来计算误差519。可以使用简单的词计数或更复杂的比较方法来执行比较517,所述比较方法考虑词的含义并且对不同的词的误差检测进行适当地加权。然后ss513使用误差519来修改参数的集合,以查找使误差最小化的值。这可以通过任何受监督的估计或优化方法(诸如最小二乘法、随机梯度、神经网络(nn)以及其变体)来完成。
[0142]
图7例示了在实时训练中——换言之,在系统的正常运行期间——话音识别链的一个示例。在vui的操作期间,由人类说话者发音的真实文本是未知的,并且受监督的误差519是不可用的。一个替代方案是为实时应用开发的置信度分数521,当不存在对真实口语文本的引用时,并且应用可以从知道asr输出的可靠性级别受益。例如,当置信度分数为低时,系统可能进入适当的分支,在该分支中与用户进行更直接的对话。存在许多用于估计置信度分数的方法,它们中的大多数以与当知道口语文本时可以计算的误差的高相关性为目标。在实时训练中,由误差估计器522将置信度分数521转换成受监督的误差519。当置信度
分数与理论的受监督的误差高度相关时,误差估计器522可以是简单的轴转换(axis conversion)。当置信度分数521的范围是从0到100时,目标是使它更高,受监督的误差的范围是从0到100,并且目标是使它更低。估计的误差=100
‑
置信度分数的形式的简单的轴转换被用作误差估计器522。估计的误差519可以被用来训练ss的参数,离线训练也是如此。
[0143]
图3例示了典型的ss 513的训练机制。源分离器(ss)513从预处理阶段512接收混合信号的集合并且为源选择器514馈送分离的信号。通常,声学信号并且特别是语音信号的源分离是在频域中完成的。来自预处理阶段512的混合信号首先被变换到频域553。这是通过将混合信号划分成相同长度的段来完成的,在作为结果的段之间具有重叠时段。例如,当段的长度被确定为1024个样本,并且重叠时段为25%时,则混合信号中的每个被划分成每个有1024个样本的段。来自不同的混合信号的并发段的集合被称为批次。段的每个批次在前一批次之后768个样本开始。注意,跨混合信号的集合的段是同步的,换言之,属于同一批次的所有段的开始点是相同的。一个批次中的段的长度和重叠时段从模型参数552取得。
[0144]
解混算法554分离从频率变换553到达的一个批次的段。与许多其他算法一样,源分离(ss)算法包括数学模型的集合——伴有模型参数552的集合。数学模型建立操作方法,诸如ss应对物理现象(例如多路径)的方式。模型参数552的集合将ss的操作调整到源信号的特定特征、到接收这些信号的自动语音识别引擎(asr)的架构、到环境的几何形状、并且甚至到人类说话者。
[0145]
解混的批次的段被转发到逆频率变换555,在该逆频率变换中它被变换回到时域。在逆频率变换阶段555中使用在频率变换阶段553中所使用的相同的模型参数552的集合。例如,重叠时段被用来从作为结果的批次在时域中重建输出信号。这例如是使用重叠相加方法(overlap
‑
add method)完成的,在重叠相加方法中在逆频率变换之后,通过重叠和相加重叠的间隔来重建所得到的输出信号,可能跨重叠区域使用范围在0到1之间的适当的加权函数,使得总能量守恒。换句话说,来自前一批次的重叠段淡出而来自后一批次的重叠段淡入。逆频率变换块的输出被转发到源选择器514。
[0146]
模型参数552是由频率变换块553、解混块554和逆频率变换块555使用的参数的集合。将混合信号划分成相同长度的段——这由频率变换553完成——由诸如实时时钟的时钟机构(clocking mechanism)定步速(pace)。在每个步速下,频率变换块553、解混块554和逆频率变换块555中的每个从模型参数552提取参数。然后这些参数被代入在频率变换块553、解混块554和逆频率变换块555中执行的数学模型中。
[0147]
校正器551优化模型参数552的集合,目的在于减少来自误差估计器的误差519。校正器551接收误差519和当前的模型参数552的集合,并且输出经校正的模型参数552的集合。该参数的集合的校正可以先验地(离线)或在vui操作期间(实时)完成。在离线训练中,用来校正模型参数552的集合的误差519是使用对麦克风发音的预定义的文本并且将asr的输出与此文本进行比较提取的。在实时训练中,误差519是从asr的置信度分数提取的。
[0148]
然后该误差被用来修改该参数的集合,以查找使误差最小化的值。这可以通过任何受监督的估计或优化方法来完成,优选地是无导数方法,诸如黄金分割搜索、网格搜索和nelder
‑
mead。
[0149]
nelder
‑
mead方法(也是下坡单纯形(downhill simplex)方法、变形虫(amoeba)方法或多胞形(polytope)方法)是一种通常应用的、用来在多维空间中查找目标函数的最小
值或最大值数值方法。它是一种直接搜索方法(基于函数比较),并且通常适用于可能不知道导数的非线性优化问题。
[0150]
nelder
‑
mead迭代地查找作为数个参数的函数的误差519的局部最小值。该方法从确定单纯形(n维的广义三角形)的值的集合开始。存在局部最小值存在于单纯形内的假设。在每次迭代中,计算单纯形的顶点处的误差。将具有最大误差的顶点替换为新的顶点,使得单纯形的体积被减小。这重复进行,直到单纯形体积小于预定义的体积,并且最佳值是顶点之一。该过程由校正器551执行。
[0151]
黄金分割搜索通过连续地缩小已知其内存在最小值的值范围来查找误差519的最小值。黄金分割搜索需要作为参数的函数的严格单峰误差。缩小范围的操作由校正器551完成。
[0152]
黄金分割搜索是用于通过连续地缩小已知其内存在极值的值范围来寻找严格单峰函数的极值(最小值或最大值)的技术。。(www.wikipedia.org)。
[0153]
网格搜索遍历与待被优化的参数中的一个或多个相关联的值的集合进行迭代。当不止一个参数被优化时,集合中的每个值是长度等于参数的数目的向量。对于每个值,计算误差519,并且选择对应于最小误差的值。遍历值的集合的迭代由校正器551执行。
[0154]
网格搜索——执行超参数优化的传统方式是网格搜索或参数扫描,其只是遍历一种学习算法的超参数空间的手动指定的子集的穷举式搜索。网格搜索算法必须通过某个性能度量来指导,通常通过对训练集合的交叉验证或对保留验证集合的评估来衡量。由于机器学习器的参数空间可以包括用于某些参数的实值或无界值空间,因此在应用网格搜索之前手动设置边界和离散化可能是必要的。(www.wikipedia.org)。
[0155]
所有优化方法都需要用相同的分离的声学信号的集合连续计算误差519。这是耗时的过程,并且因此可能不被连续地执行,而是仅当误差519(其被连续地计算)超过某个预定义的阈值(例如10%的误差)时被执行。当这发生时,可以采用两种方法。
[0156]
一种方法是使用并行线程或多核与系统的正常操作并行地运行优化。换言之,存在与系统的正常操作的任务并行地执行块513、514、515、522的一个或多个并行任务。在并行任务中,从预处理512取得一批具有1
‑
2秒的长度的混合信号,并且用不同的模型参数552的集合对其进行重复地分离513和解译514、515。对于每个这样的循环都计算误差519。在每个循环中,校正器551根据优化方法选择模型参数的集合。
[0157]
第二种方法是当在房间内不存在语音时运行优化。可以使用话音活动检测(vad)算法来检测人类语音缺失的时段。这些时段被用来以与在第一种方法中相同的方式优化模型参数552,以节省对并行线程或多核的需要。
[0158]
应为552中的每个参数选择一种合适的优化方法。一些方法适用于单个参数,并且一些适用于一组参数。下文建议了数个影响语音识别的性能的参数。此外,基于参数的特性建议了优化方法。
[0159]
段长度参数。
[0160]
段长度参数与fft/ifft相关。通常,使用分离的音素的特征的asr需要大约20毫秒的短段,而使用一系列作为结果的音素的特征的asr使用大约100
‑
200毫秒的段。另一方面,段的长度受场景影响,该场景诸如房间的混响时间。段长度应大约是混响时间,该混响时间可以是多达200
‑
500毫秒。由于对于段的长度不存在甜蜜点(sweet point),应针对场景和
asr优化此值。就样本而言,典型的值是100
‑
500毫秒。例如,8khz的采样率意味着800
‑
4000个样本的段长度。这是连续参数。
[0161]
此参数的优化可以使用各种优化方法来完成,所述优化方法诸如黄金分割搜索或nelder
‑
mead连同重叠时段。当使用黄金分割搜索时,算法的输入是最小和最大可能长度,例如10毫秒到500毫秒,以及误差函数519。输出是使误差函数519最小化的段的长度。当使用nelder
‑
mead与重叠时段时,输入是重叠时段和段长度的三个二元组的集合,例如(10毫秒,0%),(500毫秒,10%)和(500毫秒,80%)以及误差函数519,并且输出是最佳段长度和最佳重叠时段。
[0162]
重叠时段
[0163]
重叠时段参数与fft/ifft相关。重叠时段被用来避免因为分割而忽略音素。换言之,音素被划分在作为结果的段之间。由于段的长度,重叠时段取决于asr采用的特征。典型的范围——段的长度的0
‑
90%。这是连续参数。
[0164]
对此参数的优化可以使用各种优化方法来完成,所述优化方法诸如黄金分割搜索或nelder
‑
mead与段长度。当使用黄金分割搜索时,算法的输入是最小和最大可能重叠时段,例如0%到90%,以及误差函数519。输出是使误差函数519最小化的重叠时段。
[0165]
窗口。窗口参数与fft/ifft相关。频率变换553通常使用开窗来减轻分割的影响。一些窗口诸如kaiser和chebyshev是参数化的。这意味着可以通过改变窗口的参数来控制窗口的作用。典型的范围取决于窗口的类型。这是连续参数。可以使用各种优化方法(诸如黄金分割搜索)来优化此参数。当使用黄金分割搜索时,算法的输入是窗口的参数的最小值和最大值——其取决于窗口类型,以及误差函数519。例如,对于kaiser窗口,最小值和最大值是(0,30)。输出是最佳窗口参数。
[0166]
采样率
[0167]
采样率参数与fft/ifft相关。采样率是影响语音识别的性能的关键参数之一。例如,存在对于低于16khz的采样率展现较差结果的asr。其他即使以4khz或8khz也可以很好地工作。通常,当asr被选择时,此参数被优化一次。典型的范围是4、8、16、44.1、48khz。此参数是离散参数。可以使用各种优化方法(诸如网格搜索)来优化此参数。算法的输入是执行网格搜索的值——例如(4,8,16,44.1,48)khz的采样率,以及误差函数519。输出是最佳采样率。
[0168]
滤波
[0169]
滤波参数与解混相关。一些asr使用表示有限的频率范围的特征。因此,在源分离513之后对分离的信号滤波可以强调由asr使用的特定特征,从而改进其性能。更多地,滤除asr未使用的谱分量可以改进分离的信号的信噪比(snr),这进而可以改进asr的性能。典型的范围是4khz
‑
8khz。可以使用各种优化方法(诸如黄金分割搜索)来完成对此参数的优化。此参数是连续的。当应用黄金分割搜索时,算法的输入是误差函数519和截止频率的部分的初始猜测,例如1000hz和0.5x采样率。输出是最佳滤波参数。
[0170]
用于每个麦克风的加权因子。用于每个麦克风的加权因子与解混相关。理论上,特定阵列上的不同的麦克风的灵敏度应是类似的、高达3db。然而,实际上,不同的麦克风的灵敏度的跨度可以是更大的。此外,麦克风的灵敏度可能由于灰尘和湿度随时间而变化。典型的范围是0
‑
10db。这是连续参数。无论是否有用于每个麦克风的加权因子,都可以使用各种
优化方法(诸如nelder
‑
mead)完成对此参数的优化。当应用nelder
‑
mead方法时,算法的输入是误差函数519和单纯形顶点的初始猜测。例如,每个n元组的大小是麦克风的数目——n:(1,0,
…
,0,0),(0,0,
…
,0,1)和(1/n,1/n,...,1/n)。输出是每个麦克风的最佳加权。
[0171]
麦克风的数目
[0172]
麦克风的数目与解混相关。麦克风的数目一方面影响可以被分离的源的数目,并且另一方面影响复杂性和数值精度。实际实验还表明,麦克风过多可能导致输出snr的降低。典型的范围是4
‑
8。这是离散参数。可以使用各种优化方法(诸如网格搜索或nelder
‑
mead)完成对此参数的优化。当应用网格搜索时,算法的输入是误差函数519和执行搜索的麦克风数目。例如,4、5、6、7、8个麦克风。输出是麦克风的最佳数目。
[0173]
图9例示了方法600。
[0174]
方法600可以从接收或计算与应用于源选择过程的先前输出上的语音识别过程相关的误差的步骤610开始。
[0175]
步骤610之后可以是基于所述误差的修改源分离过程的至少一个参数的步骤620。
[0176]
步骤620之后可以是接收表示来源于多个源并且被麦克风阵列检测到的音频信号信号的步骤630。
[0177]
步骤630之后可以是执行源分离过程以用于分离来源于所述多个源的不同的源的音频信号以提供源分离的信号并且将源分离的信号发送到所述源选择过程的步骤640。
[0178]
步骤640之后可以是步骤630。
[0179]
步骤630和步骤640的每一次或多次迭代之后可以是步骤610(未示出)——其中步骤640的输出可以被馈送到所述源选择过程和asr以提供所述asr的先前输出。
[0180]
应注意,可以在未接收到误差的情况下执行步骤630和步骤640的初始迭代。
[0181]
步骤640可以包括应用频率转换(诸如但不限于fft)、解混和应用逆频率转换(诸如但不限于ifft)。
[0182]
步骤620可以包括以下中的至少一个:
[0183]
a.修改频率转换的至少一个参数。
[0184]
b.修改逆频率转换的至少一个参数。
[0185]
c.修改解混的至少一个参数。
[0186]
d.修改表示对其应用频率转换的音频信号的信号的段的长度。
[0187]
e.修改表示音频信号的信号的连续段之间的重叠,其中在段到段的基础上应用频率转换。
[0188]
f.修改频率转换的采样率。
[0189]
g.修改由频率转换应用的窗口的开窗参数。
[0190]
h.修改在解混期间应用的滤波器的截止频率。
[0191]
i.修改在解混期间应用到麦克风阵列中的每个麦克风的加权。
[0192]
j.修改麦克风阵列中的麦克风的数目。
[0193]
k.使用黄金分割搜索确定至少一个参数的修改的值。
[0194]
l.使用nelder
‑
mead算法确定至少一个参数的修改的值。
[0195]
m.使用网格搜索确定至少一个参数的修改的值。
[0196]
n.基于误差和至少一个参数之间的预定义的映射确定至少一个参数的一个参数
的修改的值。
[0197]
o.实时确定误差和至少一个参数之间的映射。
[0198]
在前述说明书中,已经参考本发明的实施方案的具体示例描述了本发明。然而,明显的是,在不脱离如在所附权利要求中阐明的本发明的更广泛的精神和范围的情况下,可以在本文中进行各种修改和改变。
[0199]
此外,说明书和权利要求书中的术语“前”、“后”、“顶部”、“底部”、“在
……
上方”、“在
……
下方”等,若有的话,被用于描述目的,并且不一定用于描述永久的相对位置。应理解,如此使用的术语在适当的情况下是可互换的,使得本文所描述的本发明的实施方案例如能够在不同于本文所例示或以其他方式描述的定向的其他定向上操作。
[0200]
实现相同功能的任何部件布置被有效地“相关联”使得实现期望的功能。因此,在本文中被组合以实现特定功能的任何两个部件可以被看作彼此“相关联”使得实现期望的功能,而与架构或中间部件无关。同样地,任何两个如此相关联的部件也可以被视为彼此“可操作地连接”或“可操作地耦合”以实现期望的功能。
[0201]
此外,本领域技术人员将认识到,上文所描述的操作之间的界限仅是例示性的。多个操作可以被组合成单个操作,单个操作可以被分布在附加的操作中,并且操作可以在时间上至少部分地重叠地执行。此外,替代实施方案可以包括特定操作的多个实例,并且操作顺序可以在各其他实施方案中被更改。
[0202]
然而,其他修改、变化和替代方案也是可能的。因此,说明书和附图相应地被认为是例示性的而不是限制性的。
[0203]
短语“可以是x”指示可以满足条件x。这句话还表明可以不满足条件x。例如——任何对包括某个部件的系统的引用也应涵盖系统不包括该某个部件的场景。例如——任何对包括某个步骤的方法的引用也应涵盖该方法不包括该某个部件的场景。再例如——对被配置为执行某个操作的系统的任何引用也应涵盖系统未被配置为执行该某个操作的场景。
[0204]
术语“包括”、“包含”、“具有”、“由
……
组成”和“基本上由
……
组成”以可互换的方式使用。例如——任何方法可以至少包括附图和/或说明书中包括的步骤,仅包括附图和/或说明书中包括的步骤。这同样适用于系统。
[0205]
系统可以包括麦克风阵列、存储器单元和一个或多个硬件处理器,诸如被编程为执行任何上文所提到的方法的数字信号处理器、fpga、asic、通用处理器等。系统可以不包括麦克风阵列,而是可以从由麦克风阵列生成的声音信号馈送。
[0206]
应理解,为了例示的简单和清楚起见,附图中所示出的元件不一定按比例绘制。例如,为了清楚起见,一些元件的尺寸可能相对于其他元件被夸大。此外,在认为适当的情况下,参考数字可以在附图之中重复以指示对应或类似的元件。
[0207]
在前述说明书中,已经参考本发明的实施方案的具体示例描述了本发明。然而,明显的是,在不脱离所附权利要求中阐明的本发明的更广泛的精神和范围的情况下,可以在本文中进行各种修改和改变。
[0208]
此外,说明书和权利要求书中的术语“前”、“后”、“顶部”、“底部”、“在
……
上方”、“在
……
下方”等,若有的话,被用于描述目的,并且不一定用于描述永久的相对位置。应理解,如此使用的术语在适当的情况下是可互换的,使得本文所描述的本发明的实施方案例如能够在不同于本文所例示或以其他方式描述的定向的其他定向上操作。
[0209]
本领域技术人员将认识到,逻辑块之间的边界仅是例示性的,并且替代实施方案可以合并逻辑块或电路元件或对各种逻辑块或电路元件施加功能的替代分解。因此,应理解,本文所描述的架构仅是示例性的,并且实际上可以实施实现相同功能的许多其他架构。
[0210]
实现相同功能的任何部件布置被有效地“相关联”使得实现期望的功能。因此,在本文中被组合以实现特定功能的任何两个部件可以被看作彼此“相关联”使得实现期望的功能,而与架构或中间部件无关。同样地,任何两个如此相关联的部件也可以被视为彼此“可操作地连接”或“可操作地耦合”以实现期望的功能。
[0211]
此外,本领域技术人员将认识到,上文所描述的操作之间的界限仅是例示性的。多个操作可以被组合成单个操作,单个操作可以被分布在附加的操作中,并且操作可以在时间上至少部分地重叠地执行。此外,替代实施方案可以包括特定操作的多个实例,并且操作顺序可以在各其他实施方案中被更改。
[0212]
还例如,在一个实施方案中,所例示的示例可以被实施为位于单个集成电路上或同一器件内的电路系统。替代地,所述示例可以被实施为以合适的方式彼此互连的任何数目的单独的集成电路或单独的器件。
[0213]
还例如,示例或其部分可以被实施为物理电路系统或可转换成物理电路系统的逻辑表示的软或代码表示,诸如以任何适当的类型的硬件描述语言。
[0214]
此外,本发明不限于在非可编程硬件中实施的物理器件或单元,而是可以被应用于通过根据合适的程序代码操作来执行期望的器件功能的可编程器件或单元,诸如大型主机、小型计算机、服务器、工作站、个人计算机、笔记本计算机、个人数字助理、电子游戏机、汽车和其他嵌入式系统、蜂窝电话和各种其他无线设备,在本技术中通常被表示为“计算机系统”。
[0215]
然而,其他修改、变化和替代方案也是可能的。因此,说明书和附图被相应地认为是例示性的而不是限制性的。
[0216]
在权利要求中,置于括号之间的任何参考标记不应被解释为限制权利要求。词语“包括”不排除权利要求中列出的元件或步骤之外的其他元件或步骤的存在。此外,如本文所使用的术语“一个(a)”或“一个(an)”被定义为一个或不止一个。此外,在权利要求书中使用诸如“至少一个”和“一个或多个”的介绍性短语不应被解释为暗示通过不定冠词“一个(a)”或“一个(an)”对另一权利要求要素的介绍将包含这样的所介绍的权利要求要素的任何特定权利要求限制于仅包含一个这样的要素的发明,即使同一权利要求包括介绍性短语“一个或多个”或“至少一个”以及不定冠词诸如“一个(a)”或“一个(an)”。对于定冠词的使用也是如此。除非另有说明,诸如“第一”和“第二”的术语被用来任意区分这样的术语所描述的要素。因此,这些术语不一定意在指示这样的要素的时间或其他优先次序,在相互不同的权利要求中记载某些措施这一事实并不指示不能有利地使用这些措施的组合。
[0217]
本发明还可以在用于在计算机系统上运行的计算机程序中实施,该计算机程序至少包括用于当运行于诸如计算机系统的可编程设备上时执行根据本发明的方法的步骤或用于使得可编程设备能够执行根据本发明的设备或系统的功能的代码部分。计算机程序可以导致存储系统将磁盘驱动器分配给磁盘驱动器组。
[0218]
计算机程序是诸如特定应用程序和/或操作系统的指令列表。计算机程序例如可以包括以下中的一个或多个:子程序(subroutine)、函数、程序、对象方法、对象实现、可执
行的应用、小程序(applet)、小服务程序(servlet)、源代码、对象代码、共享库/动态加载库和/或其他被设计用于在计算机系统上执行的指令序列。
[0219]
计算机程序可以内部地存储在非暂时性计算机可读介质上。所有或一些计算机程序可以被设置在永久地、可移动地或远程地耦合到信息处理系统的计算机可读介质上。计算机可读介质可以例如包括,例如但不限于任何数目的以下项:磁存储介质,其包括磁盘和磁带存储介质;光存储介质,诸如光盘介质(例如,cd rom、cd
‑
r等)和数字视频磁盘存储介质;非易失性存储介质,包括基于半导体的存储器单元,诸如闪存、eeprom、eprom、rom;铁磁数字存储器;mram;易失性存储介质,包括寄存器、缓冲器或高速缓存、主存储器、ram等。计算机进程通常包括执行(运行)程序或程序的一部分、当前程序值和状态信息,以及操作系统以管理进程的执行所使用的资源。操作系统(os)是管理计算机的资源共享并且为程序员提供用来访问这些资源的接口的软件。操作系统处理系统数据和用户输入,并且通过分配和管理任务和内部系统资源作为对系统的用户和程序的服务来进行响应。计算机系统可以例如包括至少一个处理单元、相关联的存储器和多个输入/输出(i/o)设备。当执行计算机程序时,计算机系统根据计算机程序处理信息并且通过i/o设备产生由此导致的输出信息。
[0220]
本专利申请中提及的任何系统包括至少一个硬件部件。
[0221]
虽然本文已经例示和描述了本发明的某些特征,但是对于本领域普通技术人员而言,现在将出现许多修改、替换、变化和等同物。因此,应理解,所附权利要求意在涵盖落入本发明的真正精神内的所有这样的修改和变化。