1.本发明实施例涉及但不限于终端定位技术领域,具体而言,涉及但不限于一种定位方法、定位装置和计算机可读存储介质。
背景技术:
2.目前位置定位技术应用到各个方面,驾驶定位导航、汽车、轮船、物流、仓库物料定位,智能家居、智慧工厂、智慧城市,手机微信、美团等各种应用对位置服务均有需求;定位技术的市场应用正处于蓬勃发展期。而定位技术目前按照场景主要分两块:室外定位和室内定位。
3.但无论是室外定位还是室内定位,这些定位技术都需要预先架设无线信号源设备,建设维护成本较高,无线信号受环境干扰波动加大从而定位精度波动也大;且室内定位技术商用目前处于刚起步阶段,还没有某种定位技术像gps这种占据绝对室外定位市场。
4.上述的主流定位技术的方案均需要信号发生系统和信号接收系统完成定位,不能直接通过设备上的信号接收系统进行定位,需要周围配套的辅助定位设备才能实现定位,这导致无法连接辅助定位设备时设备的定位通常会失效。
技术实现要素:
5.本发明实施例提供的一种定位方法、定位装置和计算机可读存储介质,解决了在终端定位中,没有辅助定位设备,或者辅助设备失效时,无法进行定位的问题。
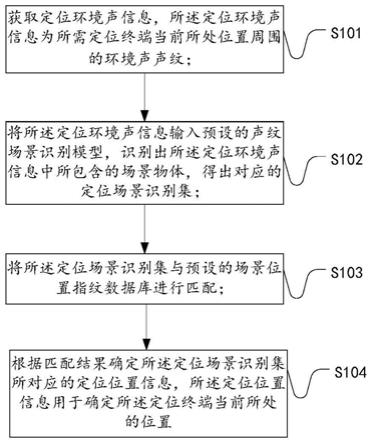
6.为解决上述技术问题,本发明实施例提供一种基于声纹场景指纹识别的定位方法,包括:获取定位环境声信息,所述定位环境声信息为所需定位终端当前所处位置周围的环境声声纹;将所述定位环境声信息输入预设的声纹场景识别模型,识别出所述定位环境声信息中所包含的场景物体,得出对应的定位场景识别集;将所述定位场景识别集与预设的场景位置指纹数据库进行匹配;根据匹配结果确定所述定位场景识别集所对应的定位位置信息,所述定位位置信息用于确定所述定位终端当前所处的位置。
7.本发明实施例还提供一种定位装置,包括:接收单元、处理单元、匹配单元和位置确定单元;所述接收单元,用于获取定位环境声信息,所述定位环境声信息为所需定位终端当前所处位置周围的环境声声纹;所述处理单元,将所述定位环境声信息输入预设的声纹场景识别模型,识别出所述定位环境声信息中所包含的场景物体,得出对应的定位场景识别集;所述匹配单元,用于将所述定位场景识别集与预设的场景位置指纹数据库进行匹配;所述位置确定单元,用于根据匹配结果确定所述定位场景识别集所对应的定位位置信息,所述定位位置信息用于确定所述定位终端当前所处的位置。
8.本发明实施例还提供一种计算机存储介质,所述计算机可读存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现如上所述的定位方法的步骤。
9.根据本发明实施例提供的一种定位方法、定位装置和计算机存储介质,其中定位
方法包括:获取定位环境声信息,定位环境声信息为所需定位终端当前所处位置周围的环境声声纹;将定位环境声信息输入预设的声纹场景识别模型,识别出定位环境声信息中所包含的场景物体,得出对应的定位场景识别集;将定位场景识别集与预设的场景位置指纹数据库进行匹配;根据匹配结果确定定位场景识别集所对应的定位位置信息,定位位置信息用于确定定位终端当前所处的位置。通过获取定位终端所处的环境声信息,并将环境声信息输入到声纹场景识别模型中,得出定位场景识别集,根据定位场景识别集从场景位置指纹数据库中匹配出对应的位置信息,即可确定终端当前所处位置。在某些实施过程中可实现包括但不限于,根据计算得出的定位场景识别集,确定终端当前所处的场景和场景物体,从而将终端所处位置的场景和场景物体在终端上进行显示的技术效果。
10.本发明其他特征和相应的有益效果在说明书的后面部分进行阐述说明,且应当理解,至少部分有益效果从本发明说明书中的记载变的显而易见。
附图说明
11.图1为本发明实施例一的一种定位方法的示意图;
12.图2为本发明实施例二的一种定位方法中应用的声纹场景识别模型训练方法的示意图;
13.图3为本发明实施例三的一种定位方法中应用的构建场景位置指纹数据库的示意图;
14.图4为本发明实施例五的一种定位方法的示意图;
15.图5为本发明实施例五的一种定位装置的示意图。
具体实施方式
16.为了使本发明的目的、技术方案及优点更加清楚明白,下面通过具体实施方式结合附图对本发明实施例作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
17.本发明实施例提供了一种基于声纹场景指纹识别的定位方法,该定位方法可以运行在定位终端上,也可以运行在定位服务器上,或者运行在定位服务器和定位终端所组成的系统上,例如,1、定位终端可以将预设的的声纹场景识别模型和预设的场景位置指纹数据库,存储到到定位终端上,定位终端即可通过自身采集周围的定位环境声信息实现定位;2、定位服务器通过接收定位终端的采集的定位环境声信息来对确定定位终端的定位位置信息,并将定位位置信息发送给定位终端实现定位;3、还可以在定位终端上存储预设的声纹场景识别模型,在定位服务器上存储预设的场景位置指纹数据库,定位终端将定位场景识别集发送给定位服务器,来实现定位终端的定位。
18.实施例一:
19.目前主流定位技术gps、wifi、蓝牙、超声波测距等方案均需要信号发生系统和信号接收系统完成定位,当系统中的辅助设备出现问题时定位就会出现故障,例如当gps受到隧道、建筑物遮挡信号等限制就会出现定位失效无法定位的情况。因此,提供一种不借助外部辅助定位设备即可进行定位的方法,对提高定位的准确性和可靠性十分重要。目前基于上述考虑,本发明提供了一种基于声纹场景指纹识别的定位方法,通过获取环境声信息来
实现终端的定位,不需要定位辅助设备,只需要采集周围的环境声即可进行定位,使得终端定位的可用场景变得更加的丰富,定位失败的概率大大降低。
20.请参见图1,为本实施例提供的一种定位方法的示意图,定位方法包括以下步骤:
21.步骤s101、获取定位环境声信息,所述定位环境声信息为所需定位终端当前所处位置周围的环境声声纹。
22.在本实施例中,定位终端可以是任何具备声音采集功能的设备、装置和功能模块,当需要定位时,定位终端采集当前所处位置周围的环境声的声纹,该环境声的声纹信息包括了周围环境中所有物体所产生的可闻声波,以及次声波、超声波等人类无法察觉感知的声波。
23.步骤s102、将所述定位环境声信息输入预设的声纹场景识别模型,识别出所述定位环境声信息中所包含的场景物体,得出对应的定位场景识别集。
24.在接收到定位环境声信息后,将其中的环境声信息提取出来,并将环境声信息输入到预设的声纹场景识别模型,预设的声纹场景识别模型会对环境声信息中的声纹进行识别,识别出环境声信息中所包含的所有的场景物体,将这些场景物体放在一起作为定位场景识别集;在另外一些实施例中,还可以根据物体发出声音信息的距离和方位确定出各个场景物体相对于定位终端所处的位置和距离;在另外一些实施例中,还可以根据识别出来的场景物体确定出当前所处的场景,例如厨房、客厅、路口和商场等。
25.步骤s103、将所述定位场景识别集与预设的场景位置指纹数据库进行匹配。
26.在识别出定位场景识别集后,将定位场景识别集与构建的预设的场景位置指纹数据库进行匹配,匹配出与识别的定位场景识别集最相似的场景识别集,并从该场景识别集获取到对应的定位位置信息,从而确定终端当前所处的位置,该定位位置信息包括但不限于地理坐标、所处位置的高度、所处位置的场景和所处位置的楼层等。
27.步骤s104、根据匹配结果确定所述定位场景识别集所对应的定位位置信息,所述定位位置信息用于确定在所述定位终端当前所处的位置。
28.在确定了定位位置信息后,定位终端通过该定位位置信息即可确定定位终端当前所处位置,从而可以在终端上将自身的位置显示出来,接收到定位场景识别集时,还可知道定位终端周围所处场景,以及场景中所包括的场景物体。
29.在一些实施例中,所述将将所述定位环境声信息输入预设的声纹场景识别模型之前还包括:处理所述定位环境声信息,将其中的随机噪声去除。对环境声信息进行处理,去除其中的随机噪声可以提高识别的准确性。
30.在一些实施例中,所述定位场景识别集中还包括:定位场景识别标签;所述定位场景识别标签是根据所述定位场景识别集得出的所述定位终端当前所处位置的场景;所述预设的场景位置指纹数据库存储的各个场景识别集中还包括对应的场景识别标签。定位场景识别集中包含了识别场景中所有的场景物体,定位场景识别标签即是根据识别出的场景物体判断出所处的场景的标签,例如场景中有燃气灶、锅、油烟机、冰箱和水龙头,该定位场景标签为厨房;当场景中有多个方向的汽车、红绿灯、行人和自行车,该定位场景标签为路口等。定位识别集中包括定位场景识别标签有利于在预设的场景位置指纹数据库进行匹配的过程中,更加快速和准确的匹配出对应的场景识别集。
31.在一些实施例中,所述根据匹配结果确定所述定位场景识别集所对应的定位位置
信息还包括:根据所述定位场景识别集和所述定位场景识别标签,确定所述定位终端当前所处位置的场景和场景物体,用于在所述定位终端上显示当前所处位置的场景和场景中所述包含的场景物体。在终端进行定位的过程中,由于已经识别出了定位场景识别集,即是识别出了终端当前位置上周围的场景物体,同时还能确定定位场景识别标签,因此,在显示定位终端位置的基础上,还可以继续显示终端当前位置周围的场景和场景中对应的物体,来提升用户体验。
32.本发明实施例提供的定位方法,包括:获取定位环境声信息,定位环境声信息为所需定位终端当前所处位置周围的环境声声纹;将定位环境声信息输入预设的声纹场景识别模型,识别出定位环境声信息中所包含的场景物体,得出对应的定位场景识别集;将定位场景识别集与预设的场景位置指纹数据库进行匹配;根据匹配结果确定定位场景识别集所对应的定位位置信息,定位位置信息用于在定位终端上显示当前的位置。通过获取终端当前位置周围的定位声音信息,并通过预设的声纹场景识别模型识别定位声音信息中的定位场景识别集,从而可以从预设的场景位置指纹数据库中匹配出定位终端所处的定位位置信息,实现了在不借助定位辅助设备的情况下对定位终端的定位,通过获取声音信息进行定位,丰富了定位的适用场景,降低了定位失败的概率。
33.实施例二:
34.本发明实施例是一种基于声纹场景指纹识别的定位方法,通过获取定位声音信息,并通过预设的声纹场景识别模型对定位声音信息进行识别,得到相应的定位场景识别集,根据定位场景识别集与预设的场景位置指纹数据库进行匹配,从而确定定位终端的位置信息,实现终端的定位。
35.因此,本发明实施例还提供了一种定位方法中应用的声纹场景识别模型的训练方法。
36.请参见图2,为本实施例提供的一种定位方法中应用的声纹场景识别模型训练的示意图。通过声纹场景识别模型训练得出的最佳声纹场景识别模型包括以下步骤:
37.步骤s201、获取同一种物体的声纹信息a次,并对该物体标记识别标签。
38.步骤s202、分别获取b种物体的声纹信息,得到b个识别标签。
39.这里的a和b在实际应用时可以根据实际需要灵活的设置,获取次数越多、种类越多、获取场景和获取品牌越丰富训练出来的声纹场景识别模型越准确,能够识别的物体越多。例如可以分别获取轿车的声纹信息500次,并将该声纹信息标记为轿车,获取的轿车声纹信息可以是不同的地点,不同时间、不同品牌和不同使用年限的轿车的声纹信息,同理还可以同时标记多种其他种类的物体的声纹信息,标记的声纹信息越多,能够识别的物体越多,识别的准确性越高。
40.步骤s203、分别将所述b种物体的声纹信息输入到声纹场景识别模型中进行a次识别训练,将每一次识别结果的识别标签与实际结果的识别标签进行比较,识别准确率达到预设值时的声纹场景识别模型为最佳的声纹场景识别模型。
41.获取到足够多的声纹信息后,将声纹信息输入到识别模型中,对识别模型进行训练,通过不断的训练使得模型的识别准确性和可识别种类不断的提高,直到识别准确度和可识别种类达到最佳的模型即为最佳声纹场景识别模型。需要说明的是,随着训练一直进行下去,识别准确性和可识别种类会不断的提高,但是从实际情况来看不可能无限的训练
下去,因此这里的最佳指的是能够达到预设阈值时的声纹场景识别模型为最佳的声纹场景识别模型,预设阈值设置越高需要训练的时间和次数越多,具体的数值可以根据实际情况设置。需要说明的是,模型的训练包括了训练和测试两个过程,因此在训练的过程中,获取的同一种物体的声纹信息a次,a次声纹信息中包括了训练所需的声纹信息和测试所需的声纹信息。
42.在一些实施例中,所述获取同一种物体的声纹信息a次,对每一次获取的物体声纹信息进行处理,将其中的随机噪声去除。
43.本实施例提供了一种定位方法中应用的声纹场景识别模型的训练方法,通过声纹场景识别模型训练方法,获取同一种物体的声纹信息a次,并对该物体标记识别标签;分别获取b种物体的声纹信息,得到b个识别标签;将b种物体的声纹信息输入到声纹场景识别模型中进行a次识别训练,将每一次识别结果的识别标签与实际结果的识别标签进行比较,识别准确率达到预设值时的声纹场景识别模型为最佳的声纹场景识别模型。获取多种物体的声纹信息对声纹信息标记识别标签,并将声纹信息输入到模型中进行训练,不断的提高模型的识别准确度可识别种类,从而得到最佳的声纹场景识别模型,在定位方法中使用该声纹场景识别模型作为预设的声纹场景识别模型,可以有效的提高识别得出场景识别集的准确度。
44.实施例三:
45.本发明实施例是一种基于声纹场景指纹识别的定位方法,通过获取定位声音信息,并通过预设的声纹场景识别模型对定位声音信息进行识别,得到相应的定位场景识别集,根据定位场景识别集与预设的场景位置指纹数据库进行匹配,从而确定定位终端的位置信息,实现终端的定位。
46.因此,本发明实施例还提供了一种定位方法中应用的构建场景位置指纹数据库的方法。
47.请参见图3,为本实施例提供的一种定位方法中应用的构建场景位置指纹数据库的示意图。通过构建场景位置指纹数据库的方法构建出场景位置指纹数据库包括以下步骤:
48.步骤s301、分别获取c个不同地点的场景识别集、每一个场景识别集所对应的场景识别标签和位置信息。
49.步骤s302、将每一个地点的场景识别集、对应的场景识别标签和位置信息进行存储构成数据库。
50.当得到最佳的声纹场景识别模型以后就可以进行数据收集构建数据库。分别在c个不同的地点采集周围的声音信息,并记录下每一个地点的位置信息和场景识别标签,采用最佳的声纹场景识别模型对声音信息进行识别得到场景识别集,每一个地点对应的场景识别集、位置信息和场景识别标签一并存储到数据库中得到场景位置指纹数据库。这里的c根据实际情况进行选择,例如在人流密集场景复杂的区域可以适当减小各个地点之间的距离,增加c的取值个数,在人员较少场地比较空旷的区域可以适当增加各个地点之间的距离,减少c的取值个数;在场景数据库的构建过程中,获取信息的地点越多,定位的准确性越高,可定位的范围和场景越广。
51.在一些实施例中,确定定位场景识别集所对应的定位位置信息之后还包括:将定
位场景识别集,更新到从预设的场景位置指纹数据库中匹配出的场景识别集中。根据常识可知,环境处在不断的变化中,相应的处于同一位置所采集到的声音信息也在不断的变化中,但是变化通常都是一个逐渐的过程不会在短时间内出现特别明显的变化,因此,每次在定位场景识别集与预设的场景位置指纹数据库进行匹配之后,需要根据匹配结果对预设的场景位置指纹数据库中对应的数据进行更新,及时对预设的场景位置指纹数据库中的数据进行更新,能有效的保证定位的准确性和实时性。
52.在一些实施例中,获取c个不同地点的场景识别集之前还包括:接收每一个地点上的环境声信息;将每一个地点上的环境声信息进行处理,去除随机噪声,并输入预设的声纹场景识别模型中,识别出环境声信息中所包含的场景物体,得出对应的场景识别集。对目标环境声信息去除随机噪声的目的是为了提高构建的场景位置指纹数据库中数据的准确性。
53.本实施例提供了一种定位方法中应用的构建场景位置指纹数据库的方法,分别获取c个不同地点的场景识别集、每一个场景识别集所对应的场景识别标签和位置信息,将每一个地点的场景识别集、对应的场景识别标签和位置信息进行存储构成的数据库。通过获取c个不同地点的场景识别集、场景识别标签和位置信息,并构成数据库,从而实现场景识别并进行定位的目的。
54.实施例四:
55.为了便于理解本发明实施例提供的一种定位方法完整的过程,本实施例提供了一种定位方法,参见图4,包括以下步骤:
56.步骤s1、训练声纹场景识别模型得到最佳的声纹场景识别模型:
57.[1]训练数据采集:采集场景a音频进行预处理,预处理后声纹作为训练样本,并对应场景为场景a标签。
[0058]
[2]模型训练:采集n个场景标签,每个场景采集m条声纹进行声纹场景识别模型训练。
[0059]
[3]得到最佳声纹场景识别模型ω。
[0060]
例如:
①
在马路边录制500段不同品牌轿车从马路开过的音频,标记为“轿车”;
[0061]
②
在不同地方不同品牌冰箱旁录制500段音频,标记为“冰箱”;
[0062]
③
在不同地点各家运营商基站机房旁录制500段音频,标记为“基站”;
[0063]
④
在地铁站附近录制500段地铁经过的音频,标记为“地铁”[0064]
⑤
在学校附近录制500段音频,标记为“学校”[0065]
⑥
在不同大桥旁录制500段音频,标记为“大桥”[0066]
⑦
在不同机场旁录制500段音频,标记为“机场”[0067]
⑧
在不同时间段不同地点的树里录制500段音频,标记为“树”[0068]
⑨
在不同位置不同时间海边沙滩上录制500段音频,标记“海边沙滩”[0069]
⑩
在不同高压线下录500段音频,标记“高压电线”[0070]
....
[0071]
将以上方式采集的数据与对应标记作为训练数据输入模型进行训练,完成声纹场景模型训练。
[0072]
步骤s2、对所需定位区域进行场景位置指纹数据库构建:
[0073]
[4]采集所需定位区域内确定位置点p处环境声纹;
[0074]
[5]预处理,去除随机噪声;
[0075]
[6]输入已训练好声纹场景识别模型ω;
[0076]
[7]得到位置p的识别场景集α,场景集α包括场景标签和位置信息;
[0077]
[8]将位置p及[7]得到场景集α作为一条指纹数据存入指纹数据库;
[0078]
[9]所需定位区域内划分q个确定位置点,每一个位置点的位置坐标和对应的场景集作为一条指纹数据,上述q个位置为待建库区域数据采集位置点,重复上述[4]-[8]步骤完成所需定位区域指纹数据库构建,相邻位置点之间间隔可调;
[0079]
[10]完成场景位置指纹数据库ν。
[0080]
例如:
①
在位置l1采集一段音频,输入步骤s1中得到训练模型,得到该位置的场景集:【轿车、地铁、基站、学校....】+【东经度45.56度,北纬30.06度】(经纬度可替换邮政地址)将【轿车、地铁、基站、学校....】与【东经度45.56度,北纬30.06度】映射作为一条指纹数据;
[0081]
②
在位置l2采集一段音频,输入步骤s1中得到训练模型,得到该位置的场景集:【大桥、火车、溪流....】+【东经度70.00度,北纬15.23度】将【沙滩、码头、发电厂....】与【东经度70.00度,北纬15.23度】映射作为第二条指纹数据;
[0082]
③
在位置l3采集一段音频,输入步骤s1中得到训练模型,得到该位置的场景集:【冰箱、微波炉、抽油烟机....】+【厨房】将【冰箱、微波炉、抽油烟机....】与【厨房】映射作为第二条指纹数据;
[0083]
④
在位置l4采集一段音频,输入步骤s1中得到训练模型,得到该位置的场景集:【风扇、电视、鱼缸、空调....】+【客厅】将【风扇、电视、鱼缸、空调....】与【客厅】映射作为第二条指纹数据;
[0084]
以上举例
①②
类为室外定位采集数据例子,
③④
为室内定位采集数据例子。每条指纹中场景越多,定位精度越高。
[0085]
步骤s3、终端定位:
[0086]
[11]采集待定位未知位置r的环境声音;
[0087]
[12]预处理,去除随机噪声;
[0088]
[13]输入已训练好声纹场景识别模型;
[0089]
[14]得到位置r识别结果场景集β,场景集β至少包含一个场景标签;
[0090]
[15]将[14]输出场景集β送入已建好场景位置指纹数据库ν进行匹配得到定位位置r;
[0091]
[16]系统输出定位结果位置r和场景集β;
[0092]
[17]将[16]位置r和场景集β作为更新数据用于位置指纹数据库ν迭代更新为位置指纹数据库ν’。
[0093]
实施例五:
[0094]
本实施例还提供了一种定位装置,参见图5所示,其包括:接收单元501、处理单元502、匹配单元503和位置确定单元504;
[0095]
所述接收单元501,用于获取定位环境声信息,所述定位环境声信息为所需定位终端当前所处位置周围的环境声声纹;
[0096]
所述处理单元502,用于将所述定位环境声信息输入预设的声纹场景识别模型,识
别出所述定位环境声信息中所包含的场景物体,得出对应的定位场景识别集;
[0097]
所述匹配单元503,用于将所述定位场景识别集与预设的场景位置指纹数据库进行匹配;
[0098]
所述位置确定单元504,用于存储所述预设的声纹场景识别模型和所述预设的场景位置指纹数据库。
[0099]
在一些实施例中,所述处理单元502,用于根据匹配结果确定所述定位场景识别集所对应的定位位置信息,所述定位位置信息用于在所述定位终端上显示当前的位置。
[0100]
本实施例还提供了一种计算机可读存储介质,该计算机可读存储介质包括在用于存储信息(诸如计算机可读指令、数据结构、计算机程序模块或其他数据)的任何方法或技术中实施的易失性或非易失性、可移除或不可移除的介质。计算机可读存储介质包括但不限于ram(random access memory,随机存取存储器),rom(read-only memory,只读存储器),eeprom(electrically erasable programmable read only memory,带电可擦可编程只读存储器)、闪存或其他存储器技术、cd-rom(compact disc read-only memory,光盘只读存储器),数字多功能盘(dvd)或其他光盘存储、磁盒、磁带、磁盘存储或其他磁存储装置、或者可以用于存储期望的信息并且可以被计算机访问的任何其他的介质,以实现上述的定位方法。
[0101]
可见,本领域的技术人员应该明白,上文中所公开方法中的全部或某些步骤、系统、装置中的功能模块/单元可以被实施为软件(可以用计算装置可执行的计算机程序代码来实现)、固件、硬件及其适当的组合。在硬件实施方式中,在以上描述中提及的功能模块/单元之间的划分不一定对应于物理组件的划分;例如,一个物理组件可以具有多个功能,或者一个功能或步骤可以由若干物理组件合作执行。某些物理组件或所有物理组件可以被实施为由处理器,如中央处理器、数字信号处理器或微处理器执行的软件,或者被实施为硬件,或者被实施为集成电路,如专用集成电路。
[0102]
此外,本领域普通技术人员公知的是,通信介质通常包含计算机可读指令、数据结构、计算机程序模块或者诸如载波或其他传输机制之类的调制数据信号中的其他数据,并且可包括任何信息递送介质。所以,本发明不限制于任何特定的硬件和软件结合。
[0103]
以上内容是结合具体的实施方式对本发明实施例所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。