1.本发明属于语音识别技术领域,具体涉及一种基于端到端模型的混合语音识别系统及方法。
背景技术:
2.近年来,随着ai技术和计算机硬件的不断发展,语音识别领域取得了飞速发展。语音识别系统框架先后经历了三个阶段。第一个阶段为模版匹配系统,这个阶段最具代表性的算法为动态弯曲算法(dynamic time warping),通过计算两个模版的相似性,并且在时间上进行弯曲,从而实现简单的孤立词识别系统;第二个阶段为混合语音识别系统,是基于隐马尔可夫(hmm)框架,根据贝叶斯公式,将语音识别系统模块化,混合语音识别系统框架分为五个模块:特征提取、解码器、语言模型、声学模型、后处理;特征提取是将语音信号从时域信号转为频域特征,一般采用mfcc或者fbank;解码器一般采用基于加权有限状态机(weighted finite state transducer,wfst)的静态解码器,利用viterbi算法,搜索解码网络中最优的路径作为识别结果;静态解码器将语音识别系统中的语言模型、发音字典、音素建模,统一表示成wfst的形式,然后利用有限状态机中的复合操作、确定化操作、最小化操作等算法,可以充分地优化解码网络,从而提高解码效率,另外,基于wfst的解码器,可以采用基于类的语言模型、热词增强、优化发音字典等技术,实现项目的可定制化,进一步提高识别率;声学模型先后经历了传统混合高斯(gmm)和深度神经网络(dnn、rnn、lstm、cnn等神经网络结构),训练时的损失函数从交叉熵(ce)到连接时域分类(ctc),其中,鉴别性训练(smbr、mpe等),对提升识别率是有帮助的。第三个阶段为纯端到端的语音识别系统,是将声学模型和语言模型联合优化,彻底抛弃了hmm的框架,包含编码器(encoder)和解码器(decoder),其中,编码器负责学习语音信号的高级特征,解码器负责学习语义上的特征,并给出解码结果;
3.相关技术中,纯端到端语音识别系统发展迅速,先后提出了las、rnn
‑
t、ct(conformer
‑
transformer),其中,ct结构同时考虑语音信号的全局特征和局部特征,并且在训练中采用ctc/attention联合优化的机制,训练稳定,取得了不错的结果。但是,在具体实施项目优化中,纯端到端语音识别系统,面临两个瓶颈:一是如果训练集和项目领域不匹配,识别效果较差;另一个是无法快速优化项目中某些关键词的识别率。
技术实现要素:
4.有鉴于此,本发明的目的在于克服现有技术的不足,提供一种基于端到端模型的混合语音识别系统及方法,以解决现有技术中训练集和项目领域不匹配时识别效果较差,以及实现项目中快速优化关键词识别率的问题。
5.为实现以上目的,本发明采用如下技术方案:一种基于端到端模型的混合语音识别系统,包括:特征提取模块、语言模型、基于端到端模型的声学模型、解码器、词图重估模块以及输出模块;
6.所述特征提取模块用于提取音频数据中的声学特征;
7.所述语言模型用于获取所述声学特征中对应的候选文本的语言模型分数;
8.所述基于端到端模型的声学模型用于获取所述声学特征的每个建模单元的后验概率;其中,所述建模单元包括词、单字、带调或无调拼音、和音素;
9.所述解码器用于对所述语言模型分数及对应建模单元的后验概率进行加权处理,然后根据加权处理后的得分进行搜索排序;
10.所述词图重估模块用于对排序后的识别结果进行重估并重新排序;
11.所述输出模块用于输出重新排序后的识别结果。
12.进一步的,构建基于端到端模型的声学模型的方法,包括:
13.在预先标注的音频数据中提取声学特征,将所述声学特征和对应的建模单元作为输入,采用连接时域分类和注意力结构的优化机制,对预构建的纯端到端模型进行训练,得到纯端到端模型的编码器;
14.将训练集输入到所述编码器中,解码得到所述训练集对应的词图文件和强制对齐文件,通过所述词图文件和强制对齐文件对所述编码器进行鉴别性训练,得到最终的基于端到端模型的声学模型。
15.进一步的,所述解码器采用viterbi算法。
16.进一步的,
17.预先对所述语音数据对应的建模单元进行建模,生成多个建模单元;其中,所述建模单元包括词、单字、带调或无调拼音、和音素。
18.进一步的,对预先标注的音频数据进行预处理、加窗、fft变换、梅尔滤波器处理,得到声学特征,或者直接将音频数据作为声学特征。
19.进一步的,对预先标注的音频数据进行预处理,包括:
20.对预先标注的音频数据进行降噪处理,或者幅值调整。
21.本技术实施例提供一种基于端到端模型的混合语音识别方法,包括:
22.提取音频数据中的声学特征;
23.获取所述声学特征对应的候选文本的语言模型分数;
24.获取所述声学特征的每个建模单元的后验概率;其中,所述建模单元包括单字或带调拼音;
25.对所述语言模型分数及对应建模单元的后验概率进行加权处理,然后根据加权处理后的得分进行搜索排序;
26.对排序后的识别结果进行重估并重新排序;
27.输出重新排序后的识别结果。
28.进一步的,构建基于端到端模型的声学模型的方法,包括:
29.在预先标注的音频数据中提取声学特征,将所述声学特征和对应的建模单元作为输入,采用连接时域分类和注意力结构的优化机制,对预构建的纯端到端模型进行训练,得到纯端到端模型的编码器;
30.将训练集输入到所述编码器中,解码得到所述训练集对应的词图文件和强制对齐文件,通过所述词图文件和强制对齐文件对所述编码器进行鉴别性训练,得到最终的基于端到端模型的声学模型。
31.本发明采用以上技术方案,能够达到的有益效果包括:
32.本发明提供一种基于端到端模型的混合语音识别系统及方法,采用声学语言端到端建模技术,对海量语音数据进行建模,并将端到端模型的编码网络作为声学模型,嵌入到混合语音识别系统中,不仅进一步提高了语音识别准确率,而且解决了纯端到端语音识别系统在项目中难以做定制化的问题。另外,本发明在端到端模型的编码网络的基础上,继续做鉴别性声学模型训练(smbr、mpe等),可以进一步提高识别准确率。
附图说明
33.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
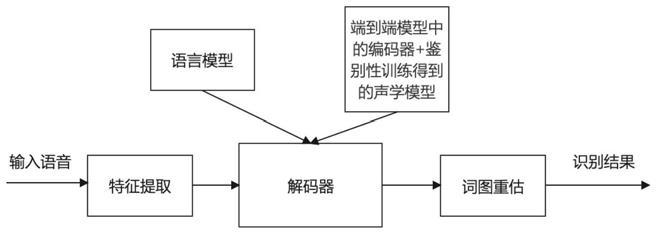
34.图1为本发明基于端到端模型的混合语音识别系统的结构步骤示意图;
35.图2为本发明构建基于端到端模型的声学模型的方法的步骤程示意图;
36.图3为本发明基于端到端模型的混合语音识别方法的步骤示意图。
具体实施方式
37.为使本发明的目的、技术方案和优点更加清楚,下面将对本发明的技术方案进行详细的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施方式,都属于本发明所保护的范围。
38.下面结合附图介绍本技术实施例中提供的一个具体的基于端到端模型的混合语音识别系统及方法。
39.如图1所示,本技术实施例中提供的基于端到端模型的混合语音识别系统,包括:特征提取模块、语言模型、基于端到端模型的声学模型、解码器、词图重估模块以及输出模块;
40.所述特征提取模块用于提取音频数据中的声学特征;
41.所述语言模型用于获取所述声学特征中对应的候选文本的语言模型分数;
42.所述基于端到端模型的声学模型用于获取所述声学特征的每个建模单元的后验概率;其中,所述建模单元包括词、单字、带调或无调拼音、和音素;
43.所述解码器用于对所述语言模型分数及对应建模单元的后验概率进行加权处理,然后根据加权处理后的得分进行搜索排序;
44.所述词图重估模块为可选模块,用于对排序后的识别结果进行重估并重新排序;
45.所述输出模块用于输出重新排序后的识别结果。
46.优选的,预先对所述语音数据对应的单字或者带调拼音进行建模,生成多个建模单元;其中,所述建模单元包括词、单字、带调或无调拼音、和音素。
47.本技术提供的基于端到端模型的混合语音识别系统的工作原理为,特征提取模块提取音频数据中的声学特征;语言模型获取声学特征中对应的候选文本的语言模型分数;基于端到端模型的声学模型获取声学特征的每个建模单元的后验概率;其中,建模单元包
括但不限于单字或带调拼音,带调拼音包括声母、韵母和声调;解码器用于对所述语言模型分数及对应建模单元的后验概率进行加权处理,然后根据加权处理后的得分进行搜索排序;词图重估模块对排序后的识别结果进行重估并重新排序;输出模块输出重新排序后的识别结果,如果搜索排序准确也可以直接输出搜索排序的识别结果。可以理解的是,带调拼音包括声母、韵母及声调。还可以包括其他建模单元,本技术在此不做限定。
48.优选的,对预先标注的音频数据可以进行预处理、加窗、fft变换、梅尔滤波器处理,得到声学特征,或者直接将音频数据作为声学特征。
49.优选的,对预先标注的音频数据进行预处理,包括:
50.对预先标注的音频数据进行降噪处理,或者幅值调整。
51.具体的,本技术中需要对音频数据进行处理得到音频数据的声学特征,其中处理方式可采用现有技术实现,例如对音频数据进行预处理、加窗、fft变换、梅尔滤波器等步骤提取到待识别语音声学特征。其中预处理可以为声音去噪处理,或者幅值调整。
52.其中,语言模型分数和声学模型的后验概率均可以用分数表示,后验概率是信息理论的基本概念之一。在一个通信系统中,在收到某个消息之后,接收端所了解到的该消息发送的概率称为后验概率。解码器在对两个分数进行加权处理后,可以得到多个候选文本的分数,分数按照从高到低进行排序,然后词图重估模块可以对加权处理后的结果进行重新评估,如果排序不对可以进行重新排序,其中,词图重估模块可采用现有技术中的模型,可采用现有技术实现,本技术在此不再赘述。
53.本发明采用声学语言端到端建模技术,对海量语音数据进行建模,并将端到端模型的编码网络作为声学模型,嵌入到混合语音识别系统中,不仅进一步提高了语音识别准确率,而且解决了纯端到端语音识别系统在项目中难以做定制化的问题。另外,本发明在端到端模型训练的基础上,进一步做鉴别性声学模型训练(smbr、mpe等),进一步提高识别准确率。
54.优选的,如图2所示,构建基于端到端模型的声学模型的方法,包括:
55.s101,在预先标注的音频数据中提取声学特征,将所述声学特征和对应的建模单元作为输入,采用连接时域分类(ctc,connectionist temporal classification)和注意力结构(attention)的优化机制,对预构建的纯端到端模型进行训练,得到纯端到端模型的编码器;
56.s102,将训练集输入到所述编码器中,解码得到所述训练集对应的词图文件和强制对齐文件,通过所述词图文件和强制对齐文件对所述编码器进行鉴别性训练,得到最终的基于端到端模型的声学模型。
57.优选的,所述解码器采用viterbi算法。
58.具体的,基于端到端模型的混合语音识别系统的具体实施步骤为:
59.1,采用端到端模型和相关目标函数,对语音信号进行建模,将事先收集并标注好的音频数据提取可供模型训练的声学特征(例如,可以经过传统的信号处理方法做预处理、加窗、fft变换、梅尔滤波器等步骤),将声学特征作为模型训练的输入,将标注好的文本作为训练目标,在海量数据下通过深度学习的方法完成模型参数的训练,得到可使用的声学语言端到端模型;
60.2,提取步骤1)训练好的声学语言端到端模型中的编码器,作为混合语音识别系统
的声学模型,利用该声学模型,解码得到训练集对应的词图文件和强制对齐文件,在此基础上,进行鉴别行训练(例如smbr,mpe等);
61.3,提取,步骤2)中训练好的基于端到端模型的声学模型,作为最终基于端到端模型的混合语音识别系统的声学模型,计算后验概率。对输入的语音信号仿照步骤1)做同样的声学特征提取,输入给语言模型和基于端到端模型的声学模型,基于端到端模型的声学模型将输出每一帧对应的所有建模单元对应的后验概率;语言模型输出文本的语言模型分数。
62.步骤4)结合建模单元的后验概率和语言模型分数,采用基于viterbi算法的解码器,搜索出解码网络中得分最高的路径,作为识别结果。
63.如图3所示,本技术实施例提供一种基于端到端模型的混合语音识别方法,包括:
64.s201,提取音频数据中的声学特征;
65.s202,获取所述声学特征对应的候选文本的语言模型分数;
66.s203,获取所述声学特征的每个建模单元的后验概率;其中,所述建模单元包括但不限于词、单字、带调或无调拼音、和音素;
67.s204,对所述语言模型分数及对应建模单元的后验概率进行加权处理,然后根据加权处理后的得分进行搜索排序;
68.s205,对排序后的识别结果进行重估并重新排序;
69.s206,输出重新排序后的识别结果。
70.本技术实施例提供的基于端到端模型的混合语音识别方法的工作原理为,提取音频数据中的声学特征;获取所述声学特征中文本的语言模型分数;获取所述声学特征的每个建模单元的后验概率;其中,所述建模单元包括词、单字、带调或无调拼音、和音素;对所述语言模型分数及每个建模单元的后验概率进行加权处理进行排序;对排序后的识别结果进行重估并重新排序;输出重新排序后的识别结果。
71.优选的,构建基于端到端模型的声学模型的方法,包括:
72.在预先标注的音频数据中提取声学特征,将所述声学特征和对应的建模单元作为输入,采用连接时域分类(ctc,connectionist temporal classification)和注意力结构(attention)的优化机制,对预构建的纯端到端模型进行训练,得到纯端到端模型的编码器;
73.将训练集输入到所述编码器中,解码得到所述训练集对应的词图文件和强制对齐文件,通过所述词图文件和强制对齐文件对所述声学语言端到端模型进行鉴别性训练,得到基于端到端模型的声学模型。
74.本技术实施例提供一种计算机设备,包括处理器,以及与处理器连接的存储器;
75.存储器用于存储计算机程序,计算机程序用于执行上述任一实施例提供的基于端到端模型的混合语音识别系统;
76.处理器用于调用并执行存储器中的计算机程序。
77.综上所述,本发明提供一种基于端到端模型的混合语音识别系统及方法,包括特征提取模块、语言模型、基于端到端模型的声学模型、解码器、词图重估模块以及输出模块。本发明采用声学语言端到端建模技术,对海量语音数据进行建模,并将端到端模型的编码网络作为声学模型,嵌入到混合语音识别系统中,不仅进一步提高了语音识别准确率,而且
解决了纯端到端语音识别系统在项目中难以做定制化的问题。另外,本发明在端到端模型训练的基础上,进一步做鉴别性声学模型训练(smbr、mpe等),进一步提高识别准确率。
78.可以理解的是,上述提供的系统实施例与上述的方法实施例对应,相应的具体内容可以相互参考,在此不再赘述。
79.本领域内的技术人员应明白,本技术的实施例可提供为系统、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
80.本技术是参照根据本技术实施例的系统、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
81.这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令系统的制造品,该指令系统实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
82.这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
83.以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。