1.本发明涉及动画生成领域,尤其涉及一种生成语音动画的装置和方法。
背景技术:
2.如今,在流媒体视频、游戏和与虚拟现实相关的应用中,虚拟角色非常流行。这些角色在虚拟世界中相互交流,且有时他们会与现实世界中的观众或玩家互动。人类对虚拟角色的任何面部不自然造物,以及不协调或不同步的表现都非常敏感,这使得制作面部动画,尤其是制作语音动画非常具有挑战性,因为动画同时涉及声音和嘴部动作。
3.在现实的语音动画中,艺术家寻求与高度拟人的虚拟人物之间最沉浸式的体验。但是,制作过程中的高成本以及对包括音频,视频和可能的3d模型在内的数据的巨大要求极大地破坏了其扩展潜力。以使用头像的线上会议为例,这种对真实效果要求较低但对于缩放可能性有要求的应用,音频数据可能是所述过程中唯一可用的媒介。这种情况要求虚拟角色通过与语音输入无缝匹配的嘴部运动来正确运行,这就是我们所说的可信语音动画。“可信”语音动画要求算法在实际资源限制下,为具有各种3d模型的所有可能的虚拟面容服务,并生成具有足够真实感的合成视频以使遥控端的用户感到舒适。
4.实时语音动画是一个引人注目但具有挑战性的主题,其中多模态输入(例如音频,视频或深度信息)可以用于最大化性能。但是,在音频是唯一可用输入的情况下,由于资源限制或隐私问题,结果的质量很大程度上取决于实时音素识别,例如识别的准确度和延迟。对于实时应用来说,平衡延迟和准确度非常关键。当前的问题是找到一种音素识别解决方案,所述解决方案使实时动画在较低延迟下实现最高准确度。
技术实现要素:
5.鉴于上述现有技术的不足之处,本发明的目的在于提供一种音素识别解决方案,以使实时动画在较低延迟下实现最高准确度。
6.本发明一方面公开了一种从音频信号生成语音动画的方法。所述方法包括:接收音频信号;将接收到的所述音频信号转换为频域音频特征;将所述频域音频特征输入神经网络执行神经网络处理过程以识别音素,其中使用以音素数据集训练的所述神经网络来执行所述神经网络处理过程,所述音素数据集包括具有相应的准确音素标注的音频信号;并根据识别的所述音素中生成语音动画。
7.在本实施例的一种实现方式中,所述将所述音频信号转换为频域音频特征包括:计算所述音频信号的梅尔频率倒谱系数(mfccs);计算mfccs的一阶导数分量和二阶导数分量,并将所述一阶导数分量和所述二阶导数分量集合为单一音频特征帧;根据所述单一音频特征帧,所述单一音频特征帧的前向语境向量和所述单一音频特征帧的后向语境向量生成所述频域音频特征。
8.在本实施例的一种实现方式中,所述将所述频域音频特征输入神经网络执行神经网络处理过程以识别音素包括:将所述频域音频特征输入卷积神经网络(cnn)过滤器以生
成多组中间特征,每组所述中间特征与一条cnn输出通道相对应;将所述中间特征输入多个长短期记忆(lstm)网络进行并行的时序建模,以生成lstm堆栈块(lsb)输出特征,其中,每个lstm网络输入一组中间特征以生成一组lsb输出特征;将所述lsb输出特征输入统一的lstm网络进行统一的时序建模,以生成统一的lstm输出特征;在所述统一的lstm输出特征输入全连接层(fcl),以生成隐马尔可夫模型(hmm)共享状态;将所述hmm共享状态输入hmm三音素解码器以生成已识别的音素标注。
9.在本实施例的一种实现方式中,所述方法还包括:将所述音频特征存储在第一存储缓冲器中;将所述hmm共享状态存储在第二存储缓冲器中;将识别的所述音素存储在第三存储缓冲器中;其中,所述第一存储缓冲器,所述第二存储缓冲器和所述第三存储缓冲器是固定大小的先进先出(fifo)缓冲器。
10.在本实施例的一种实现方式中,所述方法还包括:根据所述单一音频特征帧与所述lsb输出特征来生成第一组合特征;并将所述第一组合特征输入所述统一的lstm网络以生成所述统一的lstm输出特征。
11.在本实施例的一种实现方式中,所述方法还包括:将所述lsb输出特征与所述统一的lstm输出特征进行组合来生成第二组合特征;并将所述第二组合特征输入所述fcl以生成所述hmm共享状态。
12.在本实施例的一种实现方式中,所述根据识别的所述音素生成语音动画包括:生成二维(2d)视素域,将所述2d视素域划分为多个块,其中每个识别的所述音素对应于所述2d视素域的区块。
13.本发明另一方面公开一种从音频信号生成语音动画的装置。所述装置包括存储器,其存储有计算机可执行指令;处理器,与所述存储器耦合,并且在执行所述计算机可执行指令时,用于:接收所述音频信号;以及将接收到的所述音频信号转换为频域音频特征;将所述频域音频特征输入神经网络执行神经网络处理过程以识别音素,其中使用以音素数据集训练的所述神经网络来执行所述神经网络处理过程,所述音素数据集包括具有相应的准确音素标注的音频信号;并根据识别的所述音素中生成语音动画。
14.在本实施例的一种实现方式中,所述处理器还用于:计算所述音频信号的梅尔频率倒谱系数(mfccs);计算mfccs的一阶导数分量和二阶导数分量,并将所述一阶导数分量和所述二阶导数分量集合为单一音频特征帧;根据所述单一音频特征帧,所述单一音频特征帧的前向语境向量和所述单一音频特征帧的后向语境向量来生成所述频域音频特征。
15.在本实施例的一种实现方式中,所述处理器还用于:将所述频域音频特征输入卷积神经网络(cnn)过滤器以生成多组中间特征,每组所述中间特征与一条cnn输出通道相对应;将所述中间特征输入多个长短期记忆(lstm)网络进行并行的时序建模,以生成lstm堆栈块(lsb)输出特征,其中,每个lstm网络输入一组中间特征以生成一组lsb输出特征;将所述lsb输出特征输入统一的lstm网络进行统一的时序建模,以生成统一的lstm输出特征;将所述统一的lstm输出特征输入全连接层(fcl),以生成隐马尔可夫模型(hmm)共享状态;将所述hmm共享状态输入hmm三音素解码器以生成已识别的音素标注。
16.在本实施例的一种实现方式中,所述处理器还用于:将所述音频特征存储在第一存储缓冲器中;将所述hmm共享状态存储在第二存储缓冲器中;将识别的所述音素存储在第三存储缓冲器中;其中,所述第一存储缓冲器,所述第二存储缓冲器和所述第三存储缓冲器
是固定大小的先进先出(fifo)缓冲器。
17.在本实施例的一种实现方式中,所述处理器还用于:组合所述单一音频特征帧与所述lsb输出特征来生成第一组合特征;并将所述第一组合特征输入所述统一的lstm网络以生成所述统一的lstm输出特征。
18.在本实施例的一种实现方式中,所述处理器还用于:将所述lsb输出特征与所述统一的lstm输出特征进行组合来生成第二组合特征;并将所述第二组合特征输入所述fcl以生成所述hmm共享状态。
19.在本实施例的一种实现方式中,所述处理器还用于:生成二维(2d)视素域,将所述2d视素域划分为多个块,其中每个识别的所述音素对应于所述2d视素域的区块。
20.本发明另一方面公开了一种非暂时性计算机可读存储介质。所述存储介质存储多个指令,其中,当处理器执行所述指令时,所述指令使所述处理器:接收所述音频信号;以及将接收到的所述音频信号转换为频域音频特征;将所述频域音频特征输入神经网络执行神经网络处理过程以识别音素,其中使用以音素数据集训练的所述神经网络来执行所述神经网络处理过程,所述音素数据集包括具有相应的准确音素标注的音频信号;并根据识别的所述音素中生成语音动画。
21.在本实施例的一种实现方式中,所述指令还使所述处理器:计算所述音频信号的梅尔频率倒谱系数(mfccs);计算mfccs的一阶导数分量和二阶导数分量,并将所述一阶导数分量和所述二阶导数分量集合为单一音频特征帧;根据所述单一音频特征帧,所述单一音频特征帧的前向语境向量和所述单一音频特征帧的后向语境向量来生成所述频域音频特征。
22.在本实施例的一种实现方式中,其中,所述指令还使所述处理器:将所述频域音频特征输入卷积神经网络(cnn)过滤器以生成多组中间特征,每组所述中间特征与一条cnn输出通道相对应;将输入多个长短期记忆(lstm)网络进行并行的时序建模,以生成lstm堆栈块(lsb)输出特征,其中,每个lstm网络输入一组中间特征以生成一组lsb输出特征;将所述lsb输出特征输入统一的lstm网络进行统一的时序建模,以生成统一的lstm输出特征;将所述统一的lstm输出特征输入全连接层(fcl),以生成隐马尔可夫模型(hmm)共享状态;将所述hmm共享状态输入hmm三音素解码器以生成已识别的音素标注。
23.在本实施例的一种实现方式中,所述指令还使所述处理器:将所述音频特征存储在第一存储缓冲器中;将所述hmm共享状态存储在第二存储缓冲器中;将识别的所述音素存储在第三存储缓冲器中;其中,所述第一存储缓冲器,所述第二存储缓冲器和所述第三存储缓冲器是固定大小的先进先出(fifo)缓冲器。
24.在本实施例的一种实现方式中,所述指令还使所述处理器:组合所述单一音频特征帧与所述lsb输出特征来生成第一组合特征;并将所述第一组合特征输入所述统一的lstm网络以生成所述统一的lstm输出特征。
25.在本实施例的一种实现方式中,所述指令还使所述处理器:将所述lsb输出特征与所述统一的lstm输出特征进行组合来生成第二组合特征;并将所述第二组合特征输入所述fcl以生成所述hmm共享状态。
26.相较于现有技术,本发明提供了一种从音频信号生成语音动画的装置及方法和非暂时性计算机可读存储介质,所述的装置和方法可以生成实时的可信语音动画且执行方式
简单,从而使实时动画在较低延迟下实现最高准确度。
附图说明
27.为了更清楚地说明本发明实施例中的技术方案,下面对在实施例的描述中使用的附图进行简要说明。显而易见的是,以下描述中的附图仅是本发明的部分实施例。基于这些附图,本领域普通技术人员可以得到其他附图。
28.图1为本发明实施例中语音动画生成装置的示意图;
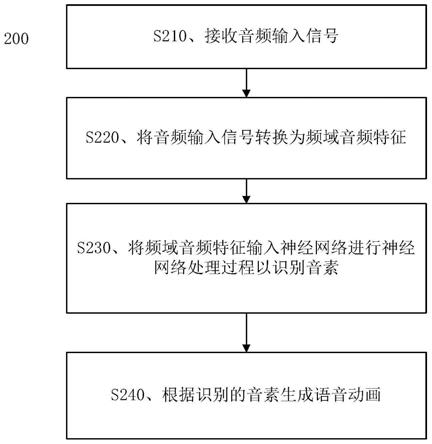
29.图2为实施例中从输入音频信号生成语音动画的语音动画生成方法示意图;
30.图3为从输入音频信号生成语音动画的语音动画生成方法的综述示意图,所述输入音频信号与词汇/slowly/的音素流{s,ow,iy}相对应;
31.图4为本发明实施例中具有缓冲器的音素识别过程的示意图;
32.图5为本发明实施例中音频特征变换时间消耗分布示意图;
33.图6为在音素/o/的发音期间不同帧处的音素对应视素的示例图;
34.图7为本发明实施例中生成2d视素域动画曲线的音素选择示例图;
35.图8为通过区块索引将2d视素域划分为20个区块的示意图;
36.图9为实施例中realprnet的整体网络架构示意图;
37.图10为实施例中从cnn输出通道输出的音频特征示意图;
38.图11a为实施例中lsb中的过程示意图;
39.图11b为另一实施例中lsb中的过程示意图;
40.图12为实施例中根据音频特征预测音素的神经网络处理过程的步骤示意图;
41.图13为lstm,cldnn和realprnet的实时性能比较示意图;
42.图14音素预测方法根据音素错误率的性能比较示意图;
43.图15为音素预测方法根据区块距离误差的性能比较示意图;
44.图16为语音动画生成方法的视觉比较示意图;以及
45.图17为本发明实施例中输出音素缓冲器占用率示意图。
具体实施方式
46.下面参考附图描述本发明实施例的技术方案。所描述的实施例仅是本发明的实施例的一部分,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
47.一些近期的作品证明了可信语音动画是可以实现的。在一些作品中,将音频输入分成称为帧的小片段,并且从每一帧中提取基本频率特征。音素是特定语言发声中在感知上的不同单元,将字与字区分开来。通过从所述特征中识别元音和基本摩擦辅音来预测音素,然后将所述音素与对应的静态动画(称为视素,即视觉领域的音素副本)进行映射。在这种基于帧的处理机制中,延迟可以忽略不计,因为它几乎等于单一帧的处理时间。但是,在此过程中缺乏对邻域语境信息的考虑,系统只能识别基本音素,极大地限制了识别音素的准确度,这直接导致了生成的动画质量低。在其他作品中,采用了基于单词的处理机制来实现更高质量的动画。使用强制对齐方法,对应于音频块提取音素转录,并且准确度很高,所述音频块包含多个单词。考虑到相邻音素的自然过渡,解决了所谓的视素共同发音的问题。
此外,这种方法考虑了一组较丰富的音素(大约39种不同音素),并将其与某些作品中的基本音素(低于10种不同音素)进行了比较,这将直接提高生成动画的质量。但是,不利之处在于单词级持续时间的延迟对于实时应用来说不可接受。因此,如果可以找到基于帧的方法与基于单词的方法之间的中间点,则可能可以解决实时的可信语音动画这一问题,例如利用处理过程中帧的滑动窗口和针对更丰富音素集且具有可接受的准确度的音素识别算法。
48.在深度学习的最新进展中,已使用全新方法重新审视音素识别主题。与传统模型相比,隐马尔可夫模型(hmm)(有工作表明错误率26.61%)和hmm/条件随机域(crfs)(有工作表明错误率25.24%)这些基于深度学习神经网络(dnn)的方法可使预测音素的错误率降低10%。在某些工作中,提出了一种前馈深度神经网络模型,并达到了23.71%的错误率。系统使用11个连续帧(每个标准音频帧为25ms,其中重叠15ms)的39个梅尔频率倒谱系数(mfcc)作为输入来预测每个音素标注。在另一项工作中,据报道,前馈深度神经网络架构达到了16.49%的更低错误率,而四层标准的长短期记忆(lstm)网络达到了15.02%的更低错误率。在某些工作中,提出了一种称为cldnn的网络体系结构,所述cldnn网络结构体系将卷积神经网络(cnn),lstm和完全连接的dnn相结合。与lstm相比,它可以进一步提高4
‑
6%的性能。
49.对于实时应用,递归神经网络(rnn)和lstm的设计理念显示找出延迟和准确度之间的平衡是非常关键的。相邻音频帧之间的时间相关性对于提高识别的准确度能发挥非常重要的作用。然而,通过在滑动窗口中添加更多的相邻帧来提高音素识别的准确度是以延迟为代价的。因此,当前的问题是找到一种音素识别解决方案,从而在实时动画的较低延迟下实现最佳准确度。
50.本发明公开了一种从包含语音信号的音频输入中生成语音动画的方法及装置。在实施例中,由本发明公开的装置和方法采用新颖的深度网络架构,称为实时音素识别网络(realprnet),以解决基于音频信号生成语音动画中的现有问题。具有考虑时间相关性和空间相关性的网络结构设计,realprnet可以为音频帧输入的滑动窗口预测音素流。在实施例中,可以采用lstm堆栈块(lsb)来最大化时间
‑
空间模式的学习效率。所述lsb包括多并联lstm层。在cnn过滤器学习输入信号中频率特征之间的空间相关性之后,可以通过两个模块执行时序建模,包括通过lsb进行分离的时序建模和通过统一的lstm层进行统一的时序建模。在运用realprnet的实施例中,所述cnn不直接与lstms相连。在训练过程中,不同的cnn过滤器可以学习加强输入特征中不同的频率
‑
时间模式。所述lsb可以进一步利用时间相关性,并分别处理来自不同cnn过滤器的中间输出特征,所述时间相关性具有不同的加强后的频率
‑
时间模式。每个输出特征都将传递到所述lsb中单独的lstm网络。将来自lsb的输出内容汇总并传递到后续的统一的lstm网络和输出dnn层。这些策略可以提高语音动画生成方法的性能。
51.图1示出了本发明实施例的语音动画生成装置100。如图1所示,所述语音动画生成装置100可以用于接收音频信号。在实施例中,接收到的所述音频信号可以是数字化语音信号。语音音频信号可以从记录装置获得,从存储模块加载或以其他方式提供给所述语音动画生成装置100。所述语音动画生成装置100可以用于执行神经网络处理过程,以将所述音频输入转换为识别的音素序列并根据识别的音素生成面部动画。在实施例中,可以通过训练过程来生成神经网络的参数,所述训练过程用于接收包含多个音频信号和准确音素标注
的训练数据。
52.在实施例中,所述语音动画生成装置100可以是包括处理器102和存储介质104的计算装置。所述语音动画生成装置100还可以包括显示器106,通信模块108和附加的外围装置112。部分装置可以省略,而其他装置也可以包括在内。处理器102可以包括任何适当的处理器。在实施例中,处理器102包括用于多线程或并行处理的多个核心。处理器102可以执行计算机程序指令序列以实现各种处理过程,例如神经网络处理过程程序。存储介质104可以是非暂时性计算机可读存储介质,并且可以包括诸如rom(只读存储器)、ram(随机存取存储器)、闪存模块以及可擦除和可重写的存储器,以及诸如cd
‑
rom(压缩式光盘只读存储器)、u盘和硬盘之类的大容量存储器。存储介质104可以存储计算机程序和用于实现各种处理过程的指令,当由处理器102执行所述指令时,使处理器执行语音动画生成方法的神经网络处理过程程序的各个步骤,所述语音动画生成方法用于从输入音频信号生成语音动画的。所述通信模块108可以包括通过网络建立连接的网络装置。显示器106可以包括任何适当类型的计算机显示装置或电子装置显示器(例如,基于crt(阴极射线管)或lcd(液晶显示器)的装置,触摸屏)。在实施例中,外围装置112可以包括音频接收和记录装置,例如麦克风。外围装置112可以进一步包括附加的输入/输出装置,例如键盘、鼠标等。处理器102可以用于执行存储在所述存储介质104上的指令,并执行如以下描述中详述的语音动画生成方法的各种操作。
53.图2示出了实施例中从输入音频信号生成语音动画的语音动画生成方法200。如图3和图4所示为实施例中所述语音动画生成方法200的部分内容。在实施例中,所述语音动画生成方法200可以公开实时过程,所述实时过程从音频输入中识别音素流,并将所述音素流与对应的参数流进行映射并驱动3d面部模型。
54.视素是已在语音识别和动画中广泛使用的可视嘴形表示,因为它可以直接从音素映射(但反之则不然,因为如果多个音素在发音期间具有相似的嘴形,则它们可以映射到同一个视素,例如/b/和/p/)。重要的是要意识到,到目前为止,尚无统一标准来规范视素,例如,有的系统使用了20个不同的视素,而其他系统使用了26个不同的视素,甚至还有系统使用了16个视素,等等。
55.如图2所示,所述语音动画生成方法200可以包括以下步骤以作示例。步骤s210是接收音频输入信号。在实施例中,所述音频输入信号可以是数字化语音信号。音频输入信号可以从记录装置获得,从存储模块加载或以其他方式提供。在实施例中,所述语音动画生成方法200可以实时处理所述音频输入信号以生成与语音信号同步的实时语音动画。
56.步骤s220是将所述音频输入信号转换为频域音频特征。当接收到原始音频输入信号时,将其转换成频域信号。在实施例中,根据所述音频输入信号来计算梅尔频率倒谱系数(mfccs)。所述mfccs广泛用于音频处理。它们共同构成了一个梅尔倒谱(mfc),代表音频信号的短期功率谱。可以看到,人的声音是不同频率的声波的组合。mfccs可以平衡不同频率下声音变化的差异。
57.所述音频输入信号包括多个帧。例如在实施例中所述音频输入信号每秒有100帧,并且每个音频帧的长度为25ms,其中有15ms重叠。在其他实施例中,所述音频帧的数量,长度和重叠持续时间可以改变,并且在本发明中不受限制。
58.对于每个音频帧,可以将mfccs的一阶导数分量和二阶导数分量集合为代表单一
音频特征帧f的向量。时刻t的音频特征x
t
符合时刻t的音频特征f
t
以及f
t
前向和后向语境向量,记为[f
t
‑
n
,
…
,f
t
,
…
,f
t+m
]。数值n表示在时刻t之前音频帧的数量,数值m表示在将来的音频帧的数量。集成的音频特征xt用于在时刻t预测音素标注。因此,对数值m的选择直接造成每秒100帧的帧率下10m ms的延迟。m的值越大,识别准确度越高,但延迟越长。当m=0时,不会缓冲未来帧以避免引入额外的延迟。无论如何,已经利用语境信息的潜在优势来提高音素识别性能。
[0059]
步骤s230是将所述频域音频特征输入神经网络进行神经网络处理过程以识别音素。在实施例中,可以通过训练过程来生成神经网络的参数,所述训练过程用于接收包含多个音频信号和准确音素标注的训练数据。在实施例中,可以使用实时音素识别网络(realprnet)和隐马尔可夫模型(hmm)的三音素解码器来进行音素识别。所述realprnet可以利用不同的神经网络,如cnn和lstm。所述realprnet的输出可以是hmm共享状态h,将其用作解码器的输入以计算识别的音素p。
[0060]
为了生成流畅的动画,可能需要音素识别过程以a ms的恒定时间间隔输出预测的音素。因此,在实施例中,可以采用缓冲器机制。如图4所示为实施例中具有缓冲器的音素识别过程。在所述过程中使用并且在图4中示出的所述缓冲器是固定大小的先进先出(fifo)缓冲器。
[0061]
如图4所示,将所述音频输入信号以每a ms的时间间隔(等于采样间隔)转换为频域音频特征f
t
之后,将f
t
存储在输入特征缓冲器(第一存储缓冲器)b1中。原始音频信号到音频特征的转换过程的计算可能导致第一延迟d1+e1,其中d1是中位计算时间,e1是波动时间。根据实验,频域音频特征变换过程的时间消耗通常是稳定的,并且100%比a ms少。图5示出了音频特征变换的时间消耗分布。如图5所示,频域音频特征变换过程的时间消耗100%比a ms(在图5所示的实验中为10ms)少。
[0062]
b1中的所述音频特征可以用于构建音频特征向量x
t
,其包括时刻t的音频特征f
t
以及f
t
前向和后向语境向量,记为[f
t
‑
n
,
…
,f
t
,
…
,f
t+m
]。b1的大小取决于两个因素:(1)选择数值m和n的大小,以及(2)每次预测realprnet的时间消耗d2+e2,其中d2是中位预测时间,e2是预测的波动时间。为了保证平稳输出,需要满足以下不等式(公式1):d2+e2≤br
·
a,br=1,2,3,
…ꢀꢀꢀ
公式1其中br是预测进度中使用的批大小,a是时间间隔常数。如果br为小值(即br=10),则通过运行一次所述神经网络可以以最小的计算量增加来一次运行神经网络来并行预测br输出。这是因为当br小时,与模型参数相比,输入特征的数据大小相对较小。在实施例中,主要的时间消耗是在数据解析和传输中。所述realprnet每br
·
a ms从b1中获取音频特征,并预测br输出[h
t
,h
t
‑1,
…
]。这些预测的输出可以存储在hmm共享状态缓冲器(第二存储缓冲器)b2中。根据实验,可以将br的值配置为4,这样可以确保在99%的情况下都满足公式(1)。图5进一步示出了根据实验得到的网络预测时间消耗分布(深灰色)。在部分实施方案中,当b1中存在br子缓冲器,且各子缓冲器的大小为m+n+1且包含音频帧特征f
t
‑
n
‑
i
,
…
,f
t
‑
i
,
…
,f
t+m
‑
i
,由于使用了m个前向音频帧构造x,所以处理过程的延迟可能会增加到m
·
a+br
·
a ms。
[0063]
在实施例中,由于神经网络和hmm解码器的组合可以进一步提高系统性能,因此所述音素识别过程不会直接预测音素标注,而是会预测hmm共享状态。b2中预测的hmm共享状
态可用作hmm三音素解码器的输入内容。对于每个时间间隔br
·
a,所述解码器可以获取b2中的所有预测数据,计算相应的音素[p
t
,
…
,p
t
‑
br+1
],并将所述音素存储在缓冲器(第三存储缓冲器)b3中。计算过程的时间为d3+e3(d3是中位计算时间,e3是计算的波动时间),且b3可取决于用于计算[p
t
,
…
,p
t
‑
br+1
]前一状态的数量。hmm解码器可以通过一起使用之前预测的共享状态以及当前状态h
t
来计算对应的音素p
t
从而改善预测结果。在实施例中,解码器可以仅将所述共享状态作为参考,而不是像语音识别系统中那样依赖于所述共享状态。这是因为音素对音素可能没有像单词对单词那样强大的内部逻辑关系。因此,解码器可以用二元音素模型来构造,所述二元音素模型关注处理过程的声学部分(信号到音素)而不是语言部分(音素到音素)。根据实验结果,用于解码的计算时间通常是稳定的,并且始终小于br
·
a。如果在上述讨论中考虑延迟的话,从原始音频输入信号到相应输出音素的总延迟是(m+br)
·
a+d+e
t
,其中d=d1+d2+d3且e
t
=e1+e2+e3。
[0064]
作为附加缓冲器,第三存储缓冲器b3可以用于控制音素识别系统的最终输出p。将具有时间戳的输出预测音素存储到b3中。所述方法可以连续地从b3获取第一音素,并将所述第一音素每隔a ms输入动画步骤。如果带有时间戳的预测音素具有负e
t
,即d+e
t
<d,则所述方法可能要等待a ms才能从b3输出。如果带有时间戳的预测音素p
et
具有正e
t
,即d+e
t
>d并且所述缓冲器中不包含更多音素,则所述方法可以输出最后一个音素并将p
et
作为最后一个音素存储在所述缓冲器中。如果下一个预测的音素也具有正e
t
,则可以将p
et
输出。如果下一个预测音素不具有正e
t
,所述方法可以丢弃p
et
并在a ms时间间隔后输出下一个预测音素。通过这种方法,所述音素识别过程能够具有时间间隔为a ms的稳定输出流,并且从原始音频输入信号到相应输出音素流的总延迟为(m+br)
·
a+d,其中d=d1+d2+d3。稳定的音素输出流可以存储在数据缓冲器b4中。以下伪代码表示在实施例中的处理过程。缓冲器是b3,输出d_p是将要存储在b4中的输出音素。
[0065]
参照图2,所述语音动画生成方法的步骤s240是根据识别的所述音素生成语音动画。在实施例中,所述方法可以从数据缓冲器b4获取数据并且使用所述数据来生成相应的语音动画。
[0066]
对于实时语音动画,实施例中公开的方法可能不直接使用来自所述音素识别过程的输出音素序列,因为所述输出音素序列是针对具有时间间隔为a的音频帧预测了音素。因此b4用于为动画曲线生成过程选择适当的下一个音素帧。图6示出了在音素/o/发音时,不同帧中与音素对应视素的示例。图7示出了实施例中用于生成2d视素域动画曲线的音素选择的示例。如图7所示,相同的音素可以出现在不同的帧中。b4的大小可以对应于音频帧中单一音素的平均发音时间。由所述音素识别处理过程输出的预测音素可以首先存储在数据缓冲器b4中。音素发音可以是动态的,这意味着在发音开始时的视素音素可能与图6所示的音素对应的唇形不完全相同。因此应该从部分音素发音帧中选择适当的音素帧,以计算用于动画曲线生成过程的视素转换的完整时间。例如,代表图6中最右边视素帧的音素帧在/o/音素帧序列中。如果数据集中的最小可识别音素发音时间为pr
min
音频帧,并且缓冲器中连续预测的音素的长度小于pr
min
,则可以用之前的音素替换相应的音素。因此,可以根据以下规则选择即将来临的音素:
[0067]
(a)连续将至少pr
min
单位的相同音素追加到缓冲器中。
[0068]
(b)如果连续音素的数量大于pr
min
单位并且小于数据缓冲器b4的大小。从缓冲器的此部分中选择代表音素的合适帧。
[0069]
(c)如果连续音素的数目大于b4的大小,则从缓冲器中的所有音素中选择合适的
帧,并且直到将下一个不同的音素附加到缓冲器之后,才选择新帧。
[0070]
在使用关键帧视素以生成最终动画的大多数程序方法中,包括jali(颌与唇)视素域和程序性嘴唇同步方法,在没有任何变化的情况下将音素映射到一个固定的静态视素。但是,基于对人类语音行为的观察,与音素相对应的视素在不同情况下可能会略有不同。即使当前的音素具有足够长的发音时间,从而消除了之前的音素发音引起的声音的共发音,这种观察也是正确的。例如,在相同的说话风格下,代表音素/s/的视素在“things”和“false”中的表现不同。因此,在本发明的实施例中,动画制作过程可以使用颌和嘴唇(jali)视素域的修饰形式和程序性嘴唇同步方法来实现。
[0071]
本发明的实施例中,将二维(2d)视素域划分为不同的区块。如图8所示为将2d视素域划分为具有块索引的20个区块。参照图8,每个音素可以对应于区块的范围而不是2d域中的静态点。
[0072]
在实施例中,步骤s230中使用的神经网络可以包括几个组件。图9示出了在实施例中的整体网络架构。如图9所示,用于音素识别的网络可以包括一个或多个卷积神经网络(cnn)层,长短期记忆(lstm)堆栈块,一个或多个统一的lstm层以及全连接层(fcl)。所述cnn层将音频特征向量x
t
作为输入内容,并对音频特征应用频率建模。所述cnn层的n维矢量输出可以传递到所述lstm的n层堆栈中,以进行并行和分离的处理过程以及时序建模。输出内容可以与f
t
组合,以输入附加lstm层用于时序建模,然后穿过全连接层。可以采用hmm三音素解码器来预测音素标注。
[0073]
所述cnn层可以用于频率建模以减少频率变化。对于不同的人,即使他们说同样的话,他们的语音中也包含不同的频率范围,基于这种观察结果,可以使用cnn层来改善音频特征中的频率变化。
[0074]
cnn层也可以在时间
‑
空间域中起作用。这里,空间是指频域音频特征模式的检测和学习。输入特征包含频率信息,因为梅尔频率倒谱中的每个系数都是通过不同的频率过滤器组生成的。所述cnn层可以包括cnn过滤器。每个cnn过滤器可以在训练过程中从所述输入特征中学习不同的频率模式。在本发明的实施例中,通过将不同cnn过滤器的cnn输出特征(cnn
fout
)分别连接到lstm堆栈中的不同lstm,为所述cnn层选择一种网络结构,以加强所述输入特征中学习到的频率模式。例如,在实施例中,第一cnn层包括9
×
9频率(空间)
‑
时间过滤器,而第二cnn层包括3
×
3过滤器。所述第一cnn层可以具有256个输出通道,并且所述第二cnn层可以具有16个输出通道。在所述cnn层中最大池化层或平均池化层都不能帮助改善神经网络处理过程的性能,基于这一观察结果,在实施例中所述cnn层中未配置池化层。
[0075]
在所述cnn层应用频率建模并且所述cnn过滤器从所述输入特征获知声学特征之后,每个cnn输出通道可生成中间特征。图10示出了来自cnn输出通道的输出内容。随后,所述lsb可以通过并行处理过程对所述cnn输出通道输出的所述中间特征执行时序建模。
[0076]
所述cnn通道的输出内容cnn
fout
可以用公式2表示,其中c
fout,i
代表来自第i个通道的输出内容。cnn
fout
可以传递到所述lsb中的多个lstm模块。所述lstm模块可以称为lstm管(lts),并且在如图9所示的lsb中示出。lsb内部lts的数量取决于最后一个cnn层输出通道的数量,其中一个lt对应于一个cnn输出通道。lt可以是相对较小且独立的lstm网络。lstm网络具有存储单元以记住有关之前特征的信息,因此在时序建模中非常有利。在实施例中,将来自特定cnn通道的每个输出c
fout,i
视为原始音频特征的派生特征,并且具有滑动窗口内
的语境。因此,可以将分离的时序建模应用于每个不同的c
fout,i
。图11a和图11b示出了在实施例中lsb的处理过程。例如图11a示例性地展示了将c
fout,i
中间特征传递到lsb内部的lts,而所述lts生成相应的lt输出内容lt
n
。例如,将c
fout,0
传递给位于lsb内的lt0用于独立时序建模(如公式3所示,其中fcl(lstm(
…
))代表lstm模块的全连接层处理过程),其中“0”代表索引为0的cnn过滤器,输出特征为lt0。图11b示出了集合的lsb输出特征。如图11b所示,可以将来自lts的分离的输出特征汇总在一起,作为下一个lstm层的输入特征(如公式4所示)。cnn
fout
={c
fout,1
,c
fout,2
,
…
,c
fout,n
}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式2lt
n
=fcl(lstm(c
fout,i
))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式3lsb(cnn
fout
)={lt1,lt2,
…
,lt
n
}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式4
[0077]
在本发明的实施例中,lsb可以包含16个lts,并且每个lt包括两个lstm层和一个全连接层(fcl)。每个lstm层可以配置为具有512个隐藏单元和0.3的丢弃率,而fcl可以具有128个输出单元。
[0078]
已经证明,lstm层在输入特征空间中提取时间模式方面是有利的。lstm中的门单元可用于控制lstm内部的信息流。例如,输入门可以决定将什么信息添加到单元状态。忘记门可以决定需要从所述单元状态中删除哪些信息,而输出门可以决定可以在输出中使用哪些信息。因此,lstm网络可以选择性地“记住”时间特征。
[0079]
在本发明的实施例中,在lsb执行并行和分离的时序建模之后,可以将输出内容传递到附加的统一的lstm层,所述统一的lstm层用于统一的时序建模。在实施例中,可以配置4个附加lstm层。每个附加lstm层可能具有1024个隐藏单元,512个输出单元和0.2的丢弃率。
[0080]
将来自所述附加lstm层的输出内容传递到全连接层(fcl),所述全连接层具有混合来自之前层中所有神经元的输出信号的能力,并使每个类别的输出概率成形,以便目标类别具有更高的可能性。在实施例中,可以使用softmax函数激活来实现fcl。在实施例中,flc可以具有1024个隐藏单元,并且输出1896维向量,所述1896维向量表示1896个hmm
‑
gmm(隐马尔科夫模型
‑
高斯混合模型)共享状态的可能性。hmm三音素解码器将来自flc的向量作为输入内容,以预测最终的音素标注。
[0081]
在实施例中,为了总结在神经网络处理过程中用于预测音素的网络组件,所述语音动画生成方法的步骤s230可以包括几个步骤。图12示出了在实施例中的步骤。参照图12,步骤s232是将音频特征输入cnn过滤器,以生成多组中间特征,每组中间特征对应一条cnn输出通道;步骤s234将中间特征输入多个lstm网络进行并行时序建模,以生成lsb输出特征,其中,每个lstm网络中输入一组中间特征,以生成一组lsb输出特征;步骤s236是将所述lsb输出特征输入统一的lstm网络进行统一的时序建模,生成统一的lstm输出特征;步骤s238是将所述统一的lstm输出特征输入fcl,以生成hmm共享状态;步骤s239是将所述hmm共享状态输入hmm三音素解码器,以生成识别的音素标注。
[0082]
在神经网络中,每一层可以专注于不同的输入内容。在自动语音识别(asr)任务中,较低的层(例如realprnet中的cnn层)可能更多地关注说话者的适应性,而较高的层(例如realprnet中的附加lstm层)可能更多地关注辨别力。因此不同层的输入特征可以互补以提高所述神经网络的性能。在本发明的实例中,采用了两种特征附加策略。图9中通过线(1)
fcl01024 1896
ꢀꢀ
[0088]
标准的timit音素识别评估中错误度量标准用于评估realprnet的音素错误率(per)。原始timit数据集使用60个音素来创建字典。在评估过程中,所述过程首先将60个音素映射到39个音素,然后计算识别的音素序列与准确音素序列之间的“编辑距离(levenshtein distance)”。编辑距离是一种测量两个序列之间差异的方法。它计算将一个序列转换为另一个序列所需的最小单字符编辑次数(包括插入,删除和替换)。首先计算将识别的音素序列更改为准确音素序列所需的编辑次数,然后计算最小编辑次数与整个音素序列长度之间的比值。所述比值是per。在实时情况下,将针对每个音频帧预测音素。因此,在我们的评估过程中基于音频帧级别的音素序列来计算per。
[0089]
区块距离误差测量视素域中识别的音素序列产生的的轨迹曲线与准确音素序列产生的曲线之间的平均距离。此处使用的基本单位是2d视素域区块的短边。对于各音频帧,计算两条曲线上的对应点以及这两点之间的绝对距离,也称为欧几里得距离。然后计算每个时刻t上这两条曲线之间的平均距离。
[0090]
在实验中,将realprnet与其他两个音素识别系统进行了比较:(1)具有前馈深度神经网络结构的4层lstm;以及(2)结合了cnn、lstm以及完全连接的深度学习神经网络(dnn)的cldnn。表2显示了利用timit数据集进行离线音素识别评估的性能。所述realprnet在per方面优于其他方法,最多降低了7.7%。
[0091]
参照图13,比较了lstm,cldnn和realprnet的实时性能。图中的x轴表示单一x
t
中使用的帧数,y轴表示音素错误率。如图13所示,当时间语境信息不足时(即使用少于10个f
s
来集合x
t
时),lstm的性能很差,但是lstm的性能随着x
t
值的增加直到x
t
中有20个音频帧特征的这一点,在持续提高。如图13所示,realprnet优于lstm最多达到20%,优于cldnn最多达到10%。频率建模和时序建模的结合使realprnet在x
t
帧数的不同选择中具有平滑的表现。表2离线音素识别错误率神经网络离线perlstm18.63cldnn18.30realprnet17.20
[0092]
为了进一步理解realprnet的优势,我们考虑了以下两个其他变体:(1)没有lstm层的realprnet,(2)不添加长短期特征的cldnn和realprnet。
[0093]
所述realprnet将两种不同类型的时序建模应用于x
t
,包括由lsb执行的分离的时序建模和由统一的lstm层执行的统一的时序建模。可以比较这两个影响神经网络性能的时序建模之间的差异。在一实验中,从所述realprnet中删除了统一的lstm层,并将得到的神经网络称为“realprnet
‑
分离”。通过分别比较realprnet
‑
分离和cldnn,得到图14中的结果。图14示出了单独一个分离的时序建模无法超过统一的时序建模。因此,realprnet的性能在两种时序建模一起使用时会受益。图14示出了在不同延迟场景(不同数值的m和n)下realprnet的per,可见realprnet要优于单独使用任意一种时序建模的网络结构。
[0094]
如上所述,可以通过多尺度特征添加技术来进一步改善神经网络的性能。可以使用realprnet演示所述技术,并将其性能与具有特征添加结构的最强基线模型cldnn和没有
添加特征的之前网络进行比较。如图14所示,多尺度特征添加的realprnet(realprnet
‑
附加)和多尺度特征添加的cldnn(cldnn
‑
附加)的性能都得到了改善。附加的短期特征为中间输入特征提供了补充信息,所述中间输入特征迫使神经网络将注意力集中在当前帧f
t
上。因此,在大多数延迟场景下,realprnet都优于其他神经网络。特别是它可以在实时per评估中实现额外4%的相对提升。
[0095]
还评估了由本发明所述方法生成的输出语音动画的质量。将视素域中由各种参考神经网络和realprnet预测的已识别音素流生成的轨迹曲线与由准确模型生成的轨迹曲线进行比较。将区块的短边长度用作距离单位,以计算每个时间点由识别的音素生成的曲线和准确曲线之间的差值
[0096]
比较结果在图15中示出。图15中的x轴表示输入特征中使用的帧数,y轴表示基本单位中的区块距离误差。如图15所示,在不同的延迟场景下,realprnet还可以实现错误最少,比其他网络最多减少27%。
[0097]
为了进行主观评估,比较了由本发明与其他现有技术的现实语音动画方法之间的视素差异。利用相同的音频产生可信语音动画,并记录视频。来自不同方法的视频将与相同的音频信号对齐。然后,同时获取视素的屏幕截图,以在视觉上比较视素的相似性。如图16所示,所有结果相似。主观测试是邀请受试者并排观看输出的动画视频并获得相同的反馈。
[0098]
缓冲器机制用于稳定系统输出并确保输出延迟在公差范围内。实验中b3在运行时间中的占用状态在图17示出。在理想情况下,每隔br
·
a ms,[p
t
,
…
,p
t
‑
br+1
]排队输入b3,并且b3每隔a ms将队中的第一值输出。每次输出之后记录所述b3的占用率状态,在实验中br的值是4,因此b3占用率大小应均匀分布在[0,1,2,3]。实际上,90%的测试用例在此范围内,这表明本发明公开的方法可以在实时情况下工作。b3中的大多数错误都发生在0和4上,因为计算机程序无法在运行期间的每个步骤中使用精确的a(例如,a的波动范围为10.3ms至11ms)。其他情况是由音素识别子系统其他部分的计算波动引起的
[0099]
本发明公开了一种音频驱动的可信语音动画生成框架的装置和方法,所述框架具有称为realprnet的新音素识别神经网络。所述realprnet展示了在音素识别方面针对强基准模型的改进性能。所述框架可以轻易地在大多数现有虚拟形象中实现,而无需创建新的形象。像真实人类一样的语音动画需要利用视频和音频数据在预训练上付出巨大的努力,甚至需要艺术家进行后期编辑。本发明所述的装置和方法着重于生成实时的可信语音动画且执行方式简单。这些公开的特征还可以允许用户使用在线后期效果编辑。
[0100]
上面详细描述了本发明实施例中的方法和装置。在此通过具体示例对本发明的原理和实施方式进行了描述。以上实施例的描述仅用于帮助理解本发明。同时,本领域技术人员可以根据本发明的思想,对具体实施例和应用范围进行改进。总之,本说明书的内容不应解释为对本发明的限制。
[0101]
本发明包含受版权保护的材料。版权是版权所有者的财产。版权持有人不反对在国家知识产权局的正式记录和文件中复制专利文件或公开专利。