1.本说明书涉及语音处理技术领域,尤其涉及一种语音转换模型的训练方法及装置。
背景技术:
2.语音转换(voice conversion,vc)是近些年来研究比较热门的课题,其为一种将一个人的语音在保留完整内容信息的基础下,转换为另外一个人的音色的过程。语音转换属于语音合成的一个技术领域,由于语音转换侧重于语音中身份信息的转换,因此它是语音信号处理中具有挑战性的研究问题之一。
3.目前的语音转换技术依赖于平行语料,即通过不同人录制的相同内容信息的语音,但是在实际的应用场景中,用户很难去录制特定内容的语音,因而平行语料在现实环境中的获取的难度较大,进而影响后续的语音转换效果。
4.那么,如何提供一种可以得到不依赖平行语料且转换效果较好的语音转换方法成为亟待解决的问题。
技术实现要素:
5.本说明书一个或多个实施例提供了一种语音转换模型的训练方法及装置,以实现不依赖平行语料训练得到语音转换模型,且通过该多任务训练所得的语音转换模型,得到转换效果较好的音频。
6.根据第一方面,提供一种语音转换模型的训练方法,所述语音转换模型包括编码器、瓶颈层以及解码器,所述方法包括:
7.对样本音频进行特征提取,得到梅尔谱特征标签以及基频序列;
8.将所述梅尔谱特征标签输入所述编码器,得到第一内容向量;
9.将所述第一内容向量输入所述瓶颈层,得到当前码本向量以及第二内容向量,其中,所述瓶颈层用于去除输入向量中的说话人信息,所述当前码本向量为与所述第一内容向量距离最近的向量;
10.基于所述第一内容向量和所述当前码本向量,确定第一损失值;
11.将所述第一内容向量输入感知机层,得到所述第一内容向量对应的各字符或空白符的发射概率;
12.基于所述样本音频对应的转录文本标签以及所述发射概率,确定第二损失值;
13.将归一化后的所述基频序列、所述第二内容向量以及所述样本音频对应的说话人标签,输入所述解码器,得到预测梅尔谱特征;
14.基于所述梅尔谱特征标签以及所述预测梅尔谱特征,确定第三损失值;
15.以最小化所述第一损失值、所述第二损失值以及所述第三损失值为目标,训练所述编码器、瓶颈层以及解码器。
16.在一种可实施方式中,所述对所获得的样本音频进行特征提取,得到梅尔谱特征
标签以及基频序列,包括:
17.对所述样本音频进行预加重,得到对应的加重样本音频;
18.对所述加重样本音频进行分帧,得到对应的子音频;
19.针对每一子音频进行加窗;
20.对每一加窗后的子音频进行快速傅里叶变换,得到每一加窗后的子音频的频谱,并基于每一加窗后的子音频的频谱,确定每一加窗后的子音频的能量谱;
21.利用梅尔滤波器以及每一加窗后的子音频的能量谱,得到每一加窗后的子音频对应的梅尔谱特征,以得到所述样本音频对应的梅尔谱特征;
22.基于每一加窗后的子音频,确定所述样本音频对应的基频序列。
23.在一种可实施方式中,所述编码器包括卷积神经网络层以及全局自注意力神经网络层;
24.所述将所述梅尔谱特征标签输入所述编码器,得到第一内容向量,包括:
25.将所述梅尔谱特征标签输入所述卷积神经网络层,得到中间特征序列;
26.将所述中间特征序列输入所述全局自注意力神经网络层,得到所述第一内容向量。
27.在一种可实施方式中,所述全局自注意力神经网络层包括采用多头自注意力的自注意力子层以及前馈神经网络子层;
28.所述将所述中间特征序列输入所述全局自注意力神经网络层,得到所述第一内容向量,包括:
29.将所述中间特征序列输入所述自注意力子层,以使所述自注意力子层,针对其每头自注意力,对所述中间特征序列进行第一线性映射,得到每头自注意力对应的问询矩阵、键值矩阵以及值矩阵;对每头自注意力对应的问询矩阵、键值矩阵以及值矩阵进行缩放点积注意力操作,得到每头自注意力对应的中间向量;对所有头自注意力对应的中间向量的第一拼接向量进行第二线性映射操作,得到对应的输出结果;
30.将所述输出结果输入所述前馈神经网络子层,以使所述前馈神经网络子层,对所述输出结果进行第三线性映射操作,得到第一线性映射结果;将所述第一线性映射结果输入修正线性单元,得到中间修正结果;对所述中间修正结果进行第四线性映射操作,得到所述第一内容向量。
31.在一种可实施方式中,所述瓶颈层包括:包含第一数量个待训练的多维码本向量的码本向量层,以及时间抖动模块;
32.所述将所述第一内容向量输入所述瓶颈层,得到当前码本向量以及第二内容向量,包括:
33.将所述第一内容向量输入所述码本向量层,计算所述第一内容向量与每一码本向量之间的距离;基于计算所得的距离,确定出与所述第一内容向量距离最近的码本向量,作为所述当前码本向量;
34.将所述当前码本向量输入所述时间抖动模块,得到所述第二内容向量。
35.在一种可实施方式中,所述解码器包括第一线性映射层、全局自注意力机制模块、前向计算模块以及第二线性映射层;
36.所述将归一化后的所述基频序列、所述第二内容向量以及所述样本音频对应的说
话人标签,输入所述解码器,得到预测梅尔谱特征,包括:
37.将归一化后的所述基频序列、所述第二内容向量以及所述样本音频对应的说话人标签进行拼接,得到第二拼接向量;
38.将所述第二拼接向量输入所述解码器,以使所述解码器依次基于第一线性映射层、全局自注意力机制模块、前向计算模块以及第二线性映射层,对所输入的拼接向量进行处理,得到所述预测梅尔谱特征。
39.在一种可实施方式中,还包括:
40.对待转换音频进行特征提取,得到所述待转换音频对应的待转换梅尔谱特征以及待转换基频序列;
41.将所述待转换梅尔谱特征输入已训练的所述编码器,得到第三内容向量;
42.将所述第三内容向量输入已训练的所述瓶颈层,得到第四内容向量;
43.将归一化后的所述待转换基频序列、所述第四内容向量以及所选择的目标说话人标签,输入已训练的所述解码器,得到转换后的梅尔谱特征;
44.将所述转换后的梅尔谱特征输入已训练的声码器,得到所述待转换音频对应的转换后的目标音频。
45.根据第二方面,提供一种语音转换模型的训练装置,所述语音转换模型包括编码器、瓶颈层以及解码器,所述装置包括:
46.特征提取模块,配置为对样本音频进行特征提取,得到梅尔谱特征标签以及基频序列;
47.第一输入模块,配置为将所述梅尔谱特征标签输入所述编码器,得到第一内容向量;
48.第二输入模块,配置为将所述第一内容向量输入所述瓶颈层,得到当前码本向量以及第二内容向量,其中,所述瓶颈层用于去除输入向量中的说话人信息,所述当前码本向量为与所述第一内容向量距离最近的向量;
49.第一确定模块,配置为基于所述第一内容向量和所述当前码本向量,确定第一损失值;
50.第三输入模块,配置为将所述第一内容向量输入感知机层,得到所述第一内容向量对应的各字符或空白符的发射概率;
51.第二确定模块,配置为基于所述样本音频对应的转录文本标签以及所述发射概率,确定第二损失值;
52.第四输入模块,配置为将归一化后的所述基频序列、所述第二内容向量以及所述样本音频对应的说话人标签,输入所述解码器,得到预测梅尔谱特征;
53.第三确定模块,配置为基于所述梅尔谱特征标签以及所述预测梅尔谱特征,确定第三损失值;
54.训练模块,配置为以最小化所述第一损失值、所述第二损失值以及所述第三损失值为目标,训练所述编码器、瓶颈层以及解码器。
55.根据第三方面,提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行第一方面所述的方法。
56.根据第四方面,提供一种计算设备,包括存储器和处理器,其中,所述存储器中存
储有可执行代码,所述处理器执行所述可执行代码时,实现第一方面所述的方法。
57.根据本说明书实施例提供的方法及装置,训练所得的语音转换模型可以通过瓶颈层得到去除说话人信息(包括音色)的内容向量,实现对音频中说话人信息、内容信息的解耦,通过第一损失值、第二损失值和第三损失值监督语音转换模型的语音转换结果,保证语音转换模型的语音转换结果的准确性。进而,利用训练所得的语音转换模型解耦得到待转换音频所表现的与说话人无关的内容信息,进而结合所选择的说话人标签(可以表征说话人信息)以及可以表征语调平均性的归一化后的基频序列,实现对音频的转换,将音频从一个说话人的音色转换为另一个说话人的音色,该模型训练过程不需要平行语料,且语音(音频)转换效果好。
附图说明
58.为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单的介绍。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
59.图1为本说明书披露的一个实施例的实施框架示意图;
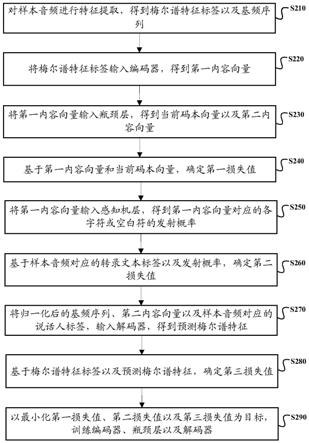
60.图2为实施例提供的语音转换模型的训练方法的一种流程示意图;
61.图3为实施例提供的语音转换模型的训练装置的一种示意性框图。
具体实施方式
62.下面将结合附图,详细描述本说明书实施例的技术方案。
63.本说明书实施例披露一种语音转换模型的训练方法及装置,下面首先对语音转换模型的训练方法的应用场景和发明构思进行介绍,具体如下:
64.目前的语音转换技术依赖于平行语料,即通过不同人录制的相同内容信息的语音,但是在实际的应用场景中,用户很难去录制特定内容的语音,因而平行语料在现实环境中的获取的难度较大,利用较少的平行语料训练语音转换模型,其语音转换效果不够好。
65.鉴于此,本说明书实施例提供了一种语音转换模型的训练方法,如图1所示,为本说明书披露的一个实施例的实施框架示意图。其中,语音转换模型包括编码器、瓶颈层以及解码器,方法包括:利用特征提取模块,对样本音频进行特征提取,得到梅尔谱特征标签以及基频序列;将梅尔谱特征标签输入编码器,得到第一内容向量;将第一内容向量输入瓶颈层,得到当前码本向量以及第二内容向量,其中,瓶颈层用于去除输入向量中的说话人信息,当前码本向量为与第一内容向量距离最近的向量;基于第一内容向量和当前码本向量,确定第一损失值;将第一内容向量输入感知机层,得到第一内容向量对应的各字符或空白符的发射概率;基于样本音频对应的转录文本标签以及发射概率,确定第二损失值;对基频序列进行归一化处理,得到归一化后的基频序列;将归一化后的基频序列、第二内容向量以及样本音频对应的说话人标签,输入解码器,得到预测梅尔谱特征;基于梅尔谱特征标签以及预测梅尔谱特征,确定第三损失值;以最小化第一损失值、第二损失值以及第三损失值为目标,训练编码器、瓶颈层以及解码器。
66.在训练语音转换模型的过程中,通过第一损失值可以使得瓶颈层学到去除第一内
容向量中的说话人信息的内容,通过第二损失值可以使得编码器和瓶颈层学习得到提取音频中准确的内容信息的能力,通过第三损失值可以使得解码器学习得到融合归一化后的基频序列、与说话人信息无关的第二内容向量以及说话人标签,得到贴合说话人标签表征的说话人信息的梅尔谱特征的能力,以保证通过解码器输出的梅尔谱特征得到更贴合输入解码器的说话人标签表征的说话人信息,实现在不使用平行语料的情况下,实现对语音转换模型的有监督的学习,保证语音转换模型的音频转换的效果。
67.下面结合具体实施例,对本说明书提供的语音转换模型的训练方法进行阐述。
68.图2示出了本说明书一个实施例中语音转换模型的训练方法的流程图。该方法可以通过任何具有计算、处理能力的装置、设备、平台、设备集群等来实现。所述方法包括如下步骤s210
‑
s290:
69.s210:对样本音频进行特征提取,得到梅尔谱特征标签以及基频序列;
70.在一种实现方式中,在训练语音转换模型之前,可以首先构建用于训练该语音转换模型的训练集,其中,该训练集可以包括多个样本音频以及样本音频对应标注信息。其中,不同样本音频所表征的内容信息可以不同,录制不同样本音频的说话人可以是不同的说话人,也可以是同一说话人录制多个样本音频。样本音频对应的标注信息可以包括样本音频对应的说话人标签以及转录文本标签,该说话人标签可以表征录制该样本音频的说话人的说话人信息,其中,说话人信息至少包括说话人的音色。说话人标签可以唯一表征说话人,可以为说话人id。该转录文本标签可以表征样本音频所录制的内容信息。
71.可以理解的,本说明书实施例中,以其中一个样本音频为例来说明训练集每个样本音频的处理过程,也就是说,针对训练集中的每一样本音频,可以进行类似处理。
72.获得样本音频之后,利用特征提取模块,对样本音频进行特征提取,得到该样本音频对应的梅尔谱特征标签以及基频序列。在一种实现方式中,所述s210,可以包括如下步骤11
‑
16:
73.步骤11:对样本音频进行预加重,得到对应的加重样本音频。通过预加重可以对样本音频中的高频分量进行补偿,得到样本音频对应的加重样本音频。
74.步骤12:对加重样本音频进行分帧,得到对应的子音频。其中,为了保证分帧后的子音频的连续性,分帧之后的相邻的预设长度的子音频帧之间存在重合。该预设长度可以根据需求以及经验进行设置,相应的,相邻子音频帧之间重合的长度也可以根据需求以及经验进行设置。一种情况中,该预设长度可以为25毫秒,重合的长度为10毫秒。
75.步骤13:针对每一子音频进行加窗。其中,该窗可以为汉明窗。
76.步骤14:对每一加窗后的子音频进行快速傅里叶变换,得到每一加窗后的子音频的频谱,并基于每一加窗后的子音频的频谱,确定每一加窗后的子音频的能量谱。其中,可以对每一加窗后的子音频的频谱对应的值进行平方,得到每一加窗后的子音频的能量谱。
77.步骤15:利用梅尔滤波器以及每一加窗后的子音频的能量谱,得到每一加窗后的子音频对应的梅尔谱特征,以得到样本音频对应的梅尔谱特征。将每一加窗后的子音频的能量谱输入梅尔滤波器,得到输出结果,对输出结果取对数,以得到每一加窗后的子音频对应的梅尔谱特征。基于所有加窗后的子音频对应的梅尔谱特征,确定得到样本音频对应的梅尔谱特征。该所提取的样本音频对应的梅尔谱特征,为样本音频的原始的梅尔谱特征,作为后续训练语音转换模块的梅尔谱特征标签。其中,梅尔滤波器的可以为多个。一种情况
中,梅尔滤波器的个数可以设置为80个,相应的,每一加窗后的子音频对应的梅尔谱特征为80维的梅尔谱特征。举例而言,若样本音频对应的加窗后的子音频个数为100,则样本音频对应的梅尔谱特征标签为100*80维的梅尔谱特征。
78.步骤16:基于每一加窗后的子音频,确定样本音频对应的基频序列。本步骤中,可以利用预设基频提取算法,基于每一加窗后的子音频,确定样本音频对应的基频序列,其中,该预设基频提取算法可以是基于时域的基频提取算法、基于频域的基频提取算法以及基于机器学习算法的基频提取算法。本说明书实施例并不对基频序列的提取算法进行限定,任一可以提取音频中的基频的算法都可以应用于本说明书实施例中。
79.s220:将梅尔谱特征标签输入编码器,得到第一内容向量。提取得到样本音频对应的梅尔谱特征标签以及基频序列之后,将梅尔谱特征标签输入编码器,编码器对梅尔谱特征标签进行处理,得到梅尔谱特征标签对应的第一内容向量,该第一内容向量包含样本音频对应的说话人信息以及样本音频对应的文本内容信息。
80.s230:将第一内容向量输入瓶颈层,得到当前码本向量以及第二内容向量。其中,瓶颈层用于去除输入向量中的说话人信息,当前码本向量为与第一内容向量距离最近的向量。为了保证后续的语音转换的效果,即在保证音频对应的文本内容信息不变的情况,将音频从一个说话人的音色转换成另一个说话人的音色,需要去除第一内容向量中掺杂的说话人信息,得到仅与音频的文本内容信息相关的内容向量,进而实现在不改变音频的文本内容信息的情况下,转换音频对应的说话人信息,实现对语音(音频)的转换。相应的,将第一内容向量输入瓶颈层,得到当前码本向量以及与说话人信息无关的第二内容向量。其中,说话人信息包括但不限于说话人的音色。
81.s240:基于第一内容向量和当前码本向量,确定第一损失值。当前码本向量为瓶颈层中与第一内容向量距离最近的码本向量,第一损失值可以表征出第一内容向量与当前码本向量之间的差异,通过第一损失值可以使得瓶颈层学习得到去除第一内容向量中说话人信息,使得编码器和瓶颈层学习到可以共同从音频中提取出仅与音频的文本内容信息相关的内容向量的能力。其中,第一损失值越小,瓶颈层的去除第一内容向量中说话人信息,提取出第一内容向量中相应的文本内容信息的能力越好,进而,所得到的第二内容向量中的说话人信息越少,可以仅包含文本内容信息。其中,可以通过第一损失函数,基于第一内容向量和当前码本向量,确定第一损失值,该第一损失函数可以为但不限于交叉熵损失函数或者均方误差损失函数或者绝对值损失函数等。在一种情况中,该第一损失值对应的计算公式可以通过如下公式(1)表示:
82.其中,z
e
表示编码器,y表示梅尔谱特征标签(输入编码器的特征),z
e
(y)表示第一内容向量,e表示当前码本向量,为待训练的参数,sg表示停止梯度传播,l
vq
表示第一损失值。
83.s250:将第一内容向量输入感知机层,得到第一内容向量对应的各字符或空白符的发射概率。将第一内容向量输入感知机层,感知机层对第一内容向量中各元素进行分类,确定各元素对应的各字符或空白符的发射概率。其中,该发射概率可以表征感知机层所感知的所对应元素为某一字符或为空白符的概率。通过该发射概率可以确定出第一内容向量各元素对应的目标对象,从而可以确定出第一内容向量对应的字符序列,其中,元素对应的目标对象可以为某一字符或空白符。其中,各元素对应的目标对象为:该元素所对应发射概
率中概率值最高的字符或空白符。举例而言,第一内容向量的第三个元素对应的各字符或空白符对应的发射概率分别为:字符1对应的发射概率为0.01,字符2对应的发射概率为0.01,字符3对应的发射概率为0.10,字符4对应的发射概率为0.80,空白符对应的发射概率为0.08,相应的,可以确定出第一内容向量的第三个元素对应的目标对象为字符4。
84.s260:基于样本音频对应的转录文本标签以及发射概率,确定第二损失值。通过第一内容向量各元素对应的各字符或空白符的发射概率,可以确定出第一内容向量对应的字符序列,样本音频对应的转录文本标签包含样本音频对应的真实的字符序列。相应的,通过连接时序主义规则,确定相应的损失值,进而利用该损失值训练语音转换模型,即基于样本音频对应的转录文本标签以及发射概率,确定第二损失值。其中,该第二损失值,可以表征出编码器所编码出的第一内容向量对应的字符序列与样本音频对应的转录文本标签之间的差异。其中,第二损失值越小,表征编码器所编码出的第一内容向量对应的字符序列,越接近样本音频对应的转录文本标签,相应的,编码器编码所得的第一内容向量越准确。其中,可以通过第二损失函数,基于样本音频对应的转录文本标签以及发射概率,确定第二损失值,该第二损失函数可以为但不限于交叉熵损失函数或者均方误差损失函数或者绝对值损失函数等。
85.在一种情况中,转录文本标签的长度比第一内容向量对应的字符序列的长度稍短,在计算第二损失值之前,需要对转录文本进行填充,例如使用空白符对转录文本标签进行填充,以使得填充后的转录文本标签的长度与第一内容向量对应的字符序列的长度相同,继而基于样本音频对应的填充后的转录文本标签以及发射概率,确定第二损失值。
86.一种实现中,对于内容向量对应的字符序列来说,在样本音频为利用中文录制的音频的情况下,该字符序列中的字符可以为汉字,在样本音频为利用英文录制的音频的情况下,该字符序列中的字符可以为字母。
87.s270:将归一化后的基频序列、第二内容向量以及样本音频对应的说话人标签,输入解码器,得到预测梅尔谱特征。归一化后的基频序列可以将语调平均化,将归一化后的基频序列、与说话人信息无关的第二内容向量以及样本音频对应的说话人标签(可以表征说话人信息),输入解码器,可以得到符合说话人标签的说话人信息的梅尔谱特征,即为通过语音转换模型所转换得到的预测梅尔谱特征。
88.其中,对基频序列进行归一化处理可以得到该归一化后的基频序列,该归一化处理可以通过如下公式(2)表示:
89.p
norm
=(p
src
‑
μ)/(4*σ);(2)其中,p
norm
表示归一化后的基频序列,p
src
表示基频序列,μ表示基频序列对应的均值,σ表示基频序列对应的方差。
90.s280:基于梅尔谱特征标签以及预测梅尔谱特征,确定第三损失值。第三损失值可以表征样本音频的真实的梅尔谱特征标签(包含说话人标签的说话人信息),与样本音频对应的通过语音转换模型所转换的预测梅尔谱特征(包含说话人标签的说话人信息)之间的差异。其中,第三损失值越小,可以表征语音转换模型对样本音频的转换效果越好,且解码器的融合能力也越好。其中,可以通过第三损失函数,基于梅尔谱特征标签以及预测梅尔谱特征,确定第三损失值,该第三损失函数可以为但不限于交叉熵损失函数或者均方误差损失函数或者绝对值损失函数等。在一种情况中,第三损失值可以通过如下计算公式(3)表示:
91.(3)其中,loss表示第三损失值,y
i
表示预测梅尔谱特征中的第i帧(子音频)梅尔谱特征,表示梅尔谱特征标签中的第i帧(子音频)梅尔谱特征,m表示梅尔谱特征标签或预测梅尔谱特征的帧数(子音频数量)。
92.s290:以最小化第一损失值、第二损失值以及第三损失值为目标,训练编码器、瓶颈层以及解码器。本步骤中,以最小化第一损失值、第二损失值以及第三损失值为目标,训练语音转换模型,即调整编码器、瓶颈层以及解码器的参数,以使得语音转换模型对语音转换能力越高,其语音转换效果越好。
93.在一种实现中,可以是:基于第一损失值、第二损失值以及第三损失值确定总预测损失,例如将第一损失值、第二损失值以及第三损失值的和或者均值,作为总预测损失。基于总预测损失,利用反向传播算法,确定语音转换模型的模型参数梯度。利用所确定的模型参数梯度以及语音转换模型的模型参数,确定语音转换模型更新后的模型参数。进而基于更新后的模型参数,调整语音转换模型的模型参数。其中,确定语音转换模型的模型参数梯度是以最小化总预测损失为目标得到。最小化总预测损失,可以实现对语音转换模型的语音转换结果的监督,保持其准确性。
94.上述步骤s210~s290为一次模型迭代训练过程。为了训练得到更好的语音转换模型,可以多次迭代执行上述过程。也就是在步骤s270之后基于语音转换模型更新后的模型参数,返回执行步骤s210。
95.上述模型迭代训练过程的停止条件可以包括:迭代训练次数达到预设次数阈值,或者迭代训练时长达到预设时长,或者总预测损失小于设定的损失阈值等等。
96.本实施例中,训练所得的语音转换模型可以通过瓶颈层得到去除说话人信息(包括音色)的内容向量,实现对音频中说话人信息、内容信息的解耦,通过第一损失值、第二损失值和第三损失值监督语音转换模型的语音转换结果,保证语音转换模型的语音转换结果的准确性。进而,利用训练所得的语音转换模型解耦得到待转换音频所表现的与说话人无关的内容信息,进而结合所选择的说话人标签(可以表征说话人信息)以及可以表征语调平均性的归一化后的基频序列,实现对音频的转换,将音频从一个说话人的音色转换为另一个说话人的音色,该模型训练过程不需要平行语料,且语音转换效果好。
97.回顾一下步骤s210~s290的执行过程,上述实施例是以一个样本音频为一个样本为例进行说明的。在另一实施例中,也可以针对一批样本即多个样本音频执行上述步骤s210~步骤s280,分别得到每个样本音频的第一损失值、第二损失值以及第三损失值。基于与多个样本音频的第一损失值、第二损失值以及第三损失值正相关,确定总预测损失,以最小化总预测损失为目标,训练语音转换模型。本实施例中,对一批样本确定总预测损失,然后再调整语音转换模型的模型参数,这样能够减少对语音转换模型的参数调整次数,更易于训练过程的实施。
98.在本说明书的一种可实施方式中,该编码器可以包括卷积神经网络层以及全局自注意力神经网络层;
99.所述s220,可以包括如下步骤11
‑
12:
100.步骤11:将梅尔谱特征标签输入卷积神经网络层,得到中间特征序列。
101.步骤12:将中间特征序列输入全局自注意力神经网络层,得到第一内容向量。
102.本实施方式中,卷积神经网络层可以为两层步长为2的卷积神经网络组成。将梅尔谱特征标签即样本音频对应的80维的梅尔谱特征标签输入卷积神经网络层,通过两层卷积神经网络,得到梅尔谱特征标签对应的中间特征序列,其中,中间特征序列为256维度的特征序列,该中间特征序列的长度为梅尔谱特征标签的长度的1/4。将中间特征序列输入全局自注意力神经网络层,得到第一内容向量。一种情况中,该两层卷积神经网络可以对为梅尔谱特征标签进行深度可分离卷积网络和位置可分离卷积,以得到中间特征序列,该第一内容向量为256维度的特征向量,与中间特征序列的长度相同。
103.在本说明书的一种可实施方式中,该全局自注意力神经网络层包括采用多头自注意力的自注意力子层以及前馈神经网络子层;
104.所述步骤12可以包括如下子步骤121
‑
122:
105.子步骤121:将中间特征序列输入自注意力子层,以使自注意力子层,针对其每头自注意力,对中间特征序列进行第一线性映射,得到每头自注意力对应的问询矩阵、键值矩阵以及值矩阵;对每头自注意力对应的问询矩阵、键值矩阵以及值矩阵进行缩放点积注意力操作,得到每头自注意力对应的中间向量;对所有头自注意力对应的中间向量的第一拼接向量进行第二线性映射操作,得到对应的输出结果。
106.子步骤122:将输出结果输入前馈神经网络子层,以使前馈神经网络子层,对输出结果进行第三线性映射操作,得到第一线性映射结果;将第一线性映射结果输入修正线性单元,得到中间修正结果;对中间修正结果进行第四线性映射操作,得到第一内容向量。
107.本实现方式中,该全局自注意力神经网络层包括采用多头自注意力的自注意力子层以及前馈神经网络子层。将中间特征序列输入自注意力子层,自注意力子层,针对其每头自注意力,对中间特征序列进行第一线性映射,得到每头自注意力对应的问询矩阵q、键值矩阵k以及值矩阵v;对每头自注意力对应的问询矩阵q、键值矩阵k以及值矩阵v进行缩放点积注意力(scaled dot
‑
product attention)操作,得到每头自注意力对应的中间向量m;对所有头自注意力对应的中间向量m进行拼接,得到相应的第一拼接向量,对第一拼接向量进行第二线性映射操作,得到对应的输出结果。其中,得到每头自注意力对应的中间向量m的过程,可以通过如下公式(4)表示:
108.(4)q表示问询矩阵,k表示键值矩阵,v表示值矩阵,d表示值矩阵的长度,softmax()为归一化指数函数。
109.将自注意力子层的输出结果,输入前馈神经网络子层,前馈神经网络子层对输出结果进行第三线性映射操作,得到第一线性映射结果;将第一线性映射结果输入修正线性单元,,其中,该修正线性单元作为激活函数,通过修正线性单元得到中间修正结果;对中间修正结果进行第四线性映射操作,得到第一内容向量。其中,前馈神经网络子层对自注意力子层的输出结果进行处理的过程,可以通过如下公式(5)表示:
110.ffn(x)=max(xw1+b1,0)w2+b2;(5)其中,w1、w2分别为第三线性映射操作和第四线性映射操作对应的线性映射的权重矩阵,为待训练的参数,维度分别为d
×
d
f
和d
f
×
d,为待训练的参数,d为自注意力子层的输出结果的维度;b1、b2为偏置向量,为待训练的参数,x表示自注意力子层的输出结果,ffn(x)表示第一内容向量。
111.在一种情况中,该全局自注意力神经网络层通过6层全局注意力神经网络构成。
112.在本说明书的一种可实施方式中,该瓶颈层可以包括:包含第一数量个待训练的多维码本向量的码本向量层,以及时间抖动模块;
113.所述s230,可以包括如下步骤21
‑
22:
114.步骤21:将第一内容向量输入码本向量层,计算第一内容向量与每一码本向量之间的距离;基于计算所得的距离,确定出与第一内容向量距离最近的码本向量,作为当前码本向量。
115.步骤22:将当前码本向量输入时间抖动模块,得到第二内容向量。
116.本实现方式中,将第一内容向量输入码本向量层,该码本向量层包含第一数量个待训练的多维码本向量,针对每一码本向量,计算第一内容向量与该码本向量之间的距离,基于第一内容向量与每一码本向量之间的距离,从第一数量个码本向量中,确定出与第一内容向量距离最近的码本向量,作为当前码本向量。一种情况中,该第一数量可以根据实际情况进行设置,例如可以为512。码本向量的维度为256。
117.将当前码本向量输入时间抖动模块,时间抖动模块对当前码本向量进行相应的时间抖动操作,得到第二内容向量。其中,该时间抖动模块可以破坏当前码本向量中元素之间的相互关联系,实现阻止向量量化学习到特征的相互关联性的作用。该时间抖动操作对应的表达式可以通过如下公式(7)表示:
118.j
t
~categorical(p,1
‑
2*p,p)j
t
∈{
‑
1,0,1};(7),其中,p表示替换概率,j
t
表示位置,其中,0表示当前码本向量中的某一元素的位置,
‑
1表示该元素所在位置的前一位置,1表示该元素的所在位置的后一位置,该表达式可以表征当前码本向量中的某一元素,被其前一位置的元素替换的概率为p,该元素不被替换的概率为1
‑
2*p,该元素被其后一位置的元素替换的概率为p。该替换概率p的数值可以根据实际需求进行设定,一种情况中,该替换概率p的数值可以设置为0.5。
119.在本说明书的一种可实施方式中,该解码器可以包括第一线性映射层、全局自注意力机制模块、前向计算模块以及第二线性映射层;
120.所述s270,可以包括如下步骤31
‑
32:
121.步骤31:将归一化后的基频序列、第二内容向量以及样本音频对应的说话人标签进行拼接,得到第二拼接向量。
122.步骤32:将第二拼接向量输入解码器,以使解码器依次基于第一线性映射层、全局自注意力机制模块、前向计算模块以及第二线性映射层,对所输入的拼接向量进行处理,得到预测梅尔谱特征。
123.本实现方式中,得到第二内容向量以及归一化后的基频序列之后,将归一化后的基频序列、第二内容向量以及样本音频对应的说话人标签进行拼接,例如可以将归一化后的基频序列、第二内容向量以及说话人标签依次从上到下进行拼接,得到第二拼接向量。将第二拼接向量输入解码器。解码器通过第一线性映射层对第二拼接向量进行线性映射,得到第二拼接向量对应的中间线性映射向量。一种情况,该中间线性映射向量为256维度的向量。在该中间线性映射向量上加上位置编码,将加上预设的位置编码的中间线性映射向量输入全局自注意力机制模块,得到相应的编码向量,将该编码向量输入前向计算模块,得到相应的输出结果,将前向计算模块的输出结果输入第二线性映射层,进行线性映射,得到预测梅尔谱特征,其中,该预测梅尔谱特征为80维度的预测梅尔谱特征。其中,前向计算模块
可以通过两个线性层构成。
124.其中,该全局自注意力机制模块可以通过4层全局自注意力神经网络构成。
125.一种情况中,预设的位置编码可以通过如下公式(8)表示:
[0126][0127]
其中,pe表示位置编码,pos代表当前位置(中间线性映射向量中的加上位置编码的元素所在位置)的下标,n代表当前维度(中间线性映射向量中的加上位置编码的元素对应的维度)的下标,d
model
代表维度的大小。
[0128]
在本说明书的一种可实施方式中,所述方法还可以包括如下步骤41
‑
:
[0129]
步骤41:对待转换音频进行特征提取,得到待转换音频对应的待转换梅尔谱特征以及待转换基频序列。
[0130]
步骤42:将待转换梅尔谱特征输入已训练的编码器,得到第三内容向量。
[0131]
步骤43:将第三内容向量输入已训练的瓶颈层,得到第四内容向量。
[0132]
步骤44:将归一化后的待转换基频序列、第四内容向量以及所选择的目标说话人标签,输入已训练的解码器,得到转换后的梅尔谱特征。
[0133]
步骤45:将转换后的梅尔谱特征输入已训练的声码器,得到待转换音频对应的转换后的目标音频。
[0134]
本实现方式中,在训练完成语音转换模型之后,可以利用该语音转换模型对语音(音频)进行转换。相应的,获得待转换音频,该录制该待转换音频所使用的语言与录制样本音频所使用的语言可以相同。该待转换音频可以是说话人1录制的音频。
[0135]
利用上述的特征提取模块,对待转换音频进行特征提取,得到待转换音频对应的待转换梅尔谱特征以及待转换基频序列;将待转换梅尔谱特征输入已训练的编码器,得到第三内容向量。将第三内容向量输入已训练的瓶颈层,得到与说话人信息无关的第四内容向量,该第四内容向量可以表征待转换音频的文本内容信息。对待转换基频序列进行归一化操作,得到归一化后的待转换基频序列。获得用户选择的目标说话人标签,该目标说话人标签可以表征用户所希望转换的说话人音色。将归一化后的待转换基频序列、第四内容向量以及目标说话人标签进行拼接,得到待转换拼接向量,将待转换拼接向量输入已训练的解码器,得到转换后的梅尔谱特征,将转换后的梅尔谱特征输入已训练的声码器,得到待转换音频对应的转换后的目标音频,实现语音转换。该目标音频对应的说话人的音色即为目标说话人标签所表征的说话人的音色。
[0136]
该声码器为预先已训练的声码器,其可以包括卷积层、转置卷积和残差连接层神经网络。
[0137]
上述内容对本说明书的特定实施例进行了描述,其他实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行,并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要按照示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的,或者可能是有利的。
[0138]
相应于上述方法实施例,本说明书实施例,提供了一种语音转换模型的训练装置
300,其示意性框图如图3所示,语音转换模型包括编码器、瓶颈层以及解码器,所述装置包括:
[0139]
特征提取模块310,配置为对样本音频进行特征提取,得到梅尔谱特征标签以及基频序列;
[0140]
第一输入模块320,配置为将所述梅尔谱特征标签输入所述编码器,得到第一内容向量;
[0141]
第二输入模块330,配置为将所述第一内容向量输入所述瓶颈层,得到当前码本向量以及第二内容向量,其中,所述瓶颈层用于去除输入向量中的说话人信息,所述当前码本向量为与所述第一内容向量距离最近的向量;
[0142]
第一确定模块340,配置为基于所述第一内容向量和所述当前码本向量,确定第一损失值;
[0143]
第三输入模块350,配置为将所述第一内容向量输入感知机层,得到所述第一内容向量对应的各字符或空白符的发射概率;
[0144]
第二确定模块360,配置为基于所述样本音频对应的转录文本标签以及所述发射概率,确定第二损失值;
[0145]
第四输入模块370,配置为将归一化后的所述基频序列、所述第二内容向量以及所述样本音频对应的说话人标签,输入所述解码器,得到预测梅尔谱特征;
[0146]
第三确定模块380,配置为基于所述梅尔谱特征标签以及所述预测梅尔谱特征,确定第三损失值;
[0147]
训练模块390,配置为以最小化所述第一损失值、所述第二损失值以及所述第三损失值为目标,训练所述编码器、瓶颈层以及解码器。
[0148]
在一种可实施方式中,所述特征提取模块310,具体配置为对所述样本音频进行预加重,得到对应的加重样本音频;
[0149]
对所述加重样本音频进行分帧,得到对应的子音频;
[0150]
针对每一子音频进行加窗;
[0151]
对每一加窗后的子音频进行快速傅里叶变换,得到每一加窗后的子音频的频谱,并基于每一加窗后的子音频的频谱,确定每一加窗后的子音频的能量谱;
[0152]
利用梅尔滤波器以及每一加窗后的子音频的能量谱,得到每一加窗后的子音频对应的梅尔谱特征,以得到所述样本音频对应的梅尔谱特征;
[0153]
基于每一加窗后的子音频,确定所述样本音频对应的基频序列。
[0154]
在一种可实施方式中,所述编码器包括卷积神经网络层以及全局自注意力神经网络层;
[0155]
所述第一输入模块320,包括:
[0156]
第一输入单元(图中未示出),配置为将所述梅尔谱特征标签输入所述卷积神经网络层,得到中间特征序列;
[0157]
第二输入单元(图中未示出),配置为将所述中间特征序列输入所述全局自注意力神经网络层,得到所述第一内容向量。
[0158]
在一种可实施方式中,所述全局自注意力神经网络层包括采用多头自注意力的自注意力子层以及前馈神经网络子层;
[0159]
所述第二输入单元,具体配置为将所述中间特征序列输入所述自注意力子层,以使所述自注意力子层,针对其每头自注意力,对所述中间特征序列进行第一线性映射,得到每头自注意力对应的问询矩阵、键值矩阵以及值矩阵;对每头自注意力对应的问询矩阵、键值矩阵以及值矩阵进行缩放点积注意力操作,得到每头自注意力对应的中间向量;对所有头自注意力对应的中间向量的第一拼接向量进行第二线性映射操作,得到对应的输出结果;
[0160]
将所述输出结果输入所述前馈神经网络子层,以使所述前馈神经网络子层,对所述输出结果进行第三线性映射操作,得到第一线性映射结果;将所述第一线性映射结果输入修正线性单元,得到中间修正结果;对所述中间修正结果进行第四线性映射操作,得到所述第一内容向量。
[0161]
在一种可实施方式中,所述瓶颈层包括:包含第一数量个待训练的多维码本向量的码本向量层,以及时间抖动模块;
[0162]
所述第二输入模块330,配置为将所述第一内容向量输入所述码本向量层,计算所述第一内容向量与每一码本向量之间的距离;基于计算所得的距离,确定出与所述第一内容向量距离最近的码本向量,作为所述当前码本向量;
[0163]
将所述当前码本向量输入所述时间抖动模块,得到所述第二内容向量。
[0164]
在一种可实施方式中,所述解码器包括第一线性映射层、全局自注意力机制模块、前向计算模块以及第二线性映射层;
[0165]
所述第四输入模块370,具体配置为将归一化后的所述基频序列、所述第二内容向量以及所述样本音频对应的说话人标签进行拼接,得到第二拼接向量;
[0166]
将所述第二拼接向量输入所述解码器,以使所述解码器依次基于第一线性映射层、全局自注意力机制模块、前向计算模块以及第二线性映射层,对所输入的拼接向量进行处理,得到所述预测梅尔谱特征。
[0167]
在一种可实施方式中,所述装置还包括:
[0168]
所述特征提取模块310,还配置为对待转换音频进行特征提取,得到所述待转换音频对应的待转换梅尔谱特征以及待转换基频序列;
[0169]
所述第一输入模块320,还配置为将所述待转换梅尔谱特征输入已训练的所述编码器,得到第三内容向量;
[0170]
所述第二输入模块330,还配置为将所述第三内容向量输入已训练的所述瓶颈层,得到第四内容向量;
[0171]
所述第四输入模块370,还配置为将归一化后的所述待转换基频序列、所述第四内容向量以及所选择的目标说话人标签,输入已训练的所述解码器,得到转换后的梅尔谱特征;
[0172]
第五输入模块(图中未示出),配置为将所述转换后的梅尔谱特征输入已训练的声码器,得到所述待转换音频对应的转换后的目标音频。
[0173]
上述装置实施例与方法实施例相对应,具体说明可以参见方法实施例部分的描述,此处不再赘述。装置实施例是基于对应的方法实施例得到,与对应的方法实施例具有同样的技术效果,具体说明可参见对应的方法实施例。
[0174]
本说明书实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,当
所述计算机程序在计算机中执行时,令计算机执行本说明书所提供的所述语音转换模型的训练方法。
[0175]
本说明书实施例还提供了一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现本说明书所提供的所述语音转换模型的训练方法。
[0176]
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于存储介质和计算设备实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。
[0177]
本领域技术人员应该可以意识到,在上述一个或多个示例中,本发明实施例所描述的功能可以用硬件、软件、固件或它们的任意组合来实现。当使用软件实现时,可以将这些功能存储在计算机可读介质中或者作为计算机可读介质上的一个或多个指令或代码进行传输。
[0178]
以上所述的具体实施方式,对本发明实施例的目的、技术方案和有益效果进行了进一步的详细说明。所应理解的是,以上所述仅为本发明实施例的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的技术方案的基础之上所做的任何修改、等同替换、改进等,均应包括在本发明的保护范围之内。