用于文本到语音转换分析的持续时间知悉网络
1.相关申请的交叉引用
2.本技术要求于2019年4月29日提交的第16/397,349号美国申请的优先权,该美国申请的公开内容通过引用整体并入本文。
背景技术:
3.近来,基于tacotron的端到端语音合成系统显示了从合成语音的韵律以及自然度的角度得到的令人印象深刻的文本到语音转换(tts)结果。然而,在合成语音时跳过或重复输入文本中的某些单词方面,此类系统具有显著缺点。这个问题由此类系统的端到端性质引起,其中不可控的注意机制用于语音生成。本公开通过将tacotron系统内部的端到端注意机制替代成会通知持续期的注意网络来解决这些问题。本公开所提出的网络实现了相当的或提高的合成性能,并解决了tacotron系统内的问题。
技术实现要素:
4.根据一些可能的实现方式,一种方法包括:通过设备接收包括文本分量的序列的文本输入;通过设备并使用持续时间模型来确定文本分量的相应持续时间;通过设备基于文本分量的序列来生成第一语谱集;通过设备基于第一语谱集和文本分量的序列的相应持续时间来生成第二语谱集;通过设备基于第二语谱集来生成语谱图帧;通过设备基于语谱图帧来生成音频波形;以及通过设备提供音频波形作为输出。
5.根据一些可能的实现方式,一种设备包括:至少一个存储器,配置成存储程序代码;至少一个处理器,配置成读取程序代码并按照程序代码的指令进行操作,程序代码包括:接收代码,配置成使得至少一个处理器接收包括文本分量的序列的文本输入;确定代码,配置成使得至少一个处理器使用持续时间模型来确定文本分量的相应持续时间;生成代码,配置成使得至少一个处理器:基于文本分量的序列来生成第一语谱集;基于第一语谱集和文本分量的序列的相应持续时间来生成第二语谱集;基于第二语谱集来生成语谱图帧;基于语谱图帧来生成音频波形;以及提供代码,配置成使得至少一个处理器提供音频波形作为输出。
6.根据一些可能的实现方式,一种非暂时性计算机可读介质存储指令,指令包括一个或多个指令,一个或多个指令在由设备的一个或多个处理器运行时,使得一个或多个处理器:接收包括文本分量的序列的文本输入;使用持续时间模型来确定文本分量的相应持续时间;基于文本分量的序列来生成第一语谱集;基于第一语谱集和文本分量的序列的相应持续时间来生成第二语谱集;基于第二语谱集来生成语谱图帧;基于语谱图帧来生成音频波形;以及提供音频波形作为输出。
附图说明
7.图1是本文描述的示例实现方式的概略图;
8.图2是可实现本文描述的系统和/或方法的示例环境的图;
9.图3是图2的一个或多个设备的示例组件的图;以及
10.图4是使用用于文本到语音合成的、会通知持续期的注意网络来生成音频波形的示例过程的流程图。
具体实施方式
11.tts系统具有各种各样的应用。然而,大部分采用的商业系统主要基于参数系统,该参数系统与人类的自然语音相比存在很大的差距。tacotron是与基于参数的传统tts系统明显不同的tts合成系统,且能够产生高度自然的语音句子。整个系统可以以端到端的方式训练,且用编码器
‑
卷积
‑
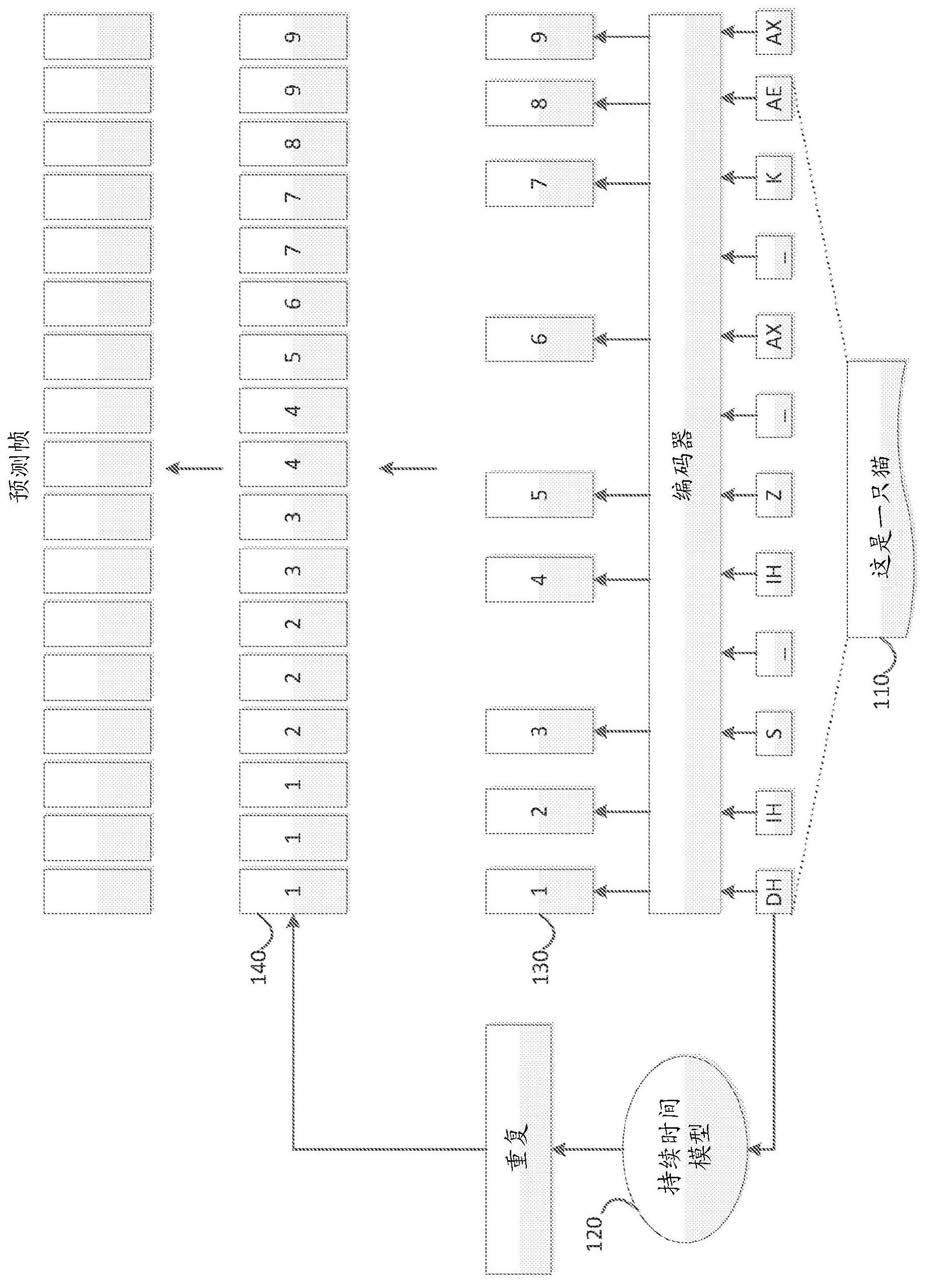
堆
‑
公路网
‑
双向选通
‑
循环单元(cbhg)模块代替传统的复杂语言特征提取部分。
12.用端到端的注意机制来代替在传统参数系统中使用的持续时间模型,其中在端到端的注意机制中,从注意模型学习输入文本(或音素序列)和语音信号之间的对齐,而不是基于隐马尔可夫模型(hmm)的对齐。与tacotron系统相关联的另一个主要区别在于它直接预测梅尔/线性语谱,该梅尔/线性语谱可直接由高级声码器(例如wavenet和wavernn)使用来合成高质量语音。
13.基于tacotron的系统能够生成更精确和自然的发声语音。然而,tacotron系统包括不稳定性,例如跳过和/或重复输入文本,这是在合成语音波形时所固有的缺点。
14.本文的一些实现方式解决基于tacotron的系统的前述输入文本跳过和重复问题,同时保持其优异的合成质量。此外,本文的一些实现方式解决这些不稳定的问题,并在合成的语音中实现显著提高的自然度。
15.tacotron的不稳定性主要由其不可控的注意机制引起,不能保证每个输入文本可被顺序地合成而不会跳过或重复。
16.本文的一些实现方式用基于持续期的注意机制来代替这种不稳定和不可控的注意机制,其中在基于持续期的注意机制中,保证输入文本被顺序地合成而不会跳过或重复。在基于tacotron的系统中需要注意的主要原因是在源文本和目标语谱图之间缺少对齐信息。
17.通常,输入文本的长度比生成的语谱图的长度短得多。来自输入文本的单个字符/音素可生成语谱图的多个帧,同时需要该信息来通过任何神经网络架构对输入/输出关系进行建模。
18.基于tacotron的系统主要利用端到端机制来解决这个问题,其中在端到端机制中,语谱图的生成依赖于对源输入文本的已知注意。然而,这种注意机制基本上不稳定,原因是这种注意机制的注意高度不可控。本文的一些实现方式用持续时间模型来代替tacotron系统内的端到端注意机制,持续时间模型预测单个输入字符和/或音素持续多长时间。换句话说,通过在预定持续期内复制每个输入字符和/或音素来实现输出语谱图和输入文本之间的对齐。通过基于hmm的强制对齐来实现从我们的系统学习的输入文本的地面真值持续期。利用预测的持续期,语谱图中的每个目标帧可与输入文本中的一个字符/音素匹配。整个模型架构在下面的图中绘制。
19.图1是本文描述的实施例的概略图。如图1所示,参考附图标记110,平台(例如,服务器)可接收包括文本分量的序列的文本输入。如图所示,文本输入可包括短语,例如“这是
一只猫”。文本输入可包括示出为字符“dh”、“ih”、“s”、“ih”、“z”、“ax”、“k”、“ae”和“ax”的文本分量的序列。
20.进一步如图1所示,参考附图标记120,平台可使用持续时间模型来确定文本分量的相应持续时间。持续时间模型可包括接收输入文本分量并确定文本分量的持续时间的模型。作为一个例子,短语“这是一只猫”在可听输出时可包括一秒的总持续时间。短语的相应文本分量可包括不同的持续时间,这些不同的持续时间共同构成总持续时间。
21.作为示例,单词“这”可包括400毫秒的持续时间,单词“是”可包括200毫秒的持续时间,单词“一只”可包括100毫秒的持续时间,以及单词“猫”可包括300毫秒的持续时间。持续时间模型可确定文本分量的相应组成持续时间。
22.进一步如图1所示,参考附图标记130,平台可基于文本分量的序列来生成第一语谱集。例如,平台可将文本分量输入到基于所输入的文本分量来生成输出语谱的模型中。如图所示,第一语谱集可包括每个文本分量的相应语谱(例如,示出为“1”、“2”、“3”、“4”、“5”、“6”、“7”、“8”和“9”)。
23.进一步如图1所示,参考附图标记140,平台可基于第一语谱集和文本分量的序列的相应持续时间来生成第二语谱集。平台可通过基于语谱的相应持续时间复制语谱来生成第二语谱集。作为示例,可复制语谱“1”,使得第二语谱集包括对应于语谱“1”的三个语谱分量等。平台可使用持续时间模型的输出来确定生成第二语谱集的方式。
24.进一步如图1所示,参考附图标记140,平台可基于第二语谱集来生成语谱图帧。语谱图帧可由第二语谱集的相应组成语谱分量形成。如图1所示,语谱图帧可与预测帧对齐。换句话说,由平台生成的语谱图帧可精确地与文本输入的预期音频输出对齐。
25.平台可使用各种技术,基于语谱图帧来生成音频波形,并提供音频波形作为输出。
26.以这种方式,本文的一些实现方式通过利用确定所输入的文本分量的相应持续时间的持续时间模型来允许与语音到文本合成相关联的更精确的音频输出生成。
27.图2是可实现本文描述的系统和/或方法的示例环境200的图。如图2所示,环境200可包括用户设备210、平台220和网络230。环境200的设备可通过有线连接、无线连接或者有线连接和无线连接的组合来互连。
28.用户设备210包括能够接收、生成、存储、处理和/或提供与平台220相关联的信息的一个或多个设备。例如,用户设备210可包括计算设备(例如,台式计算机、膝上型计算机、平板计算机、手持式计算机、智能扬声器、服务器等)、移动电话(例如,智能电话、无线电话等)、可穿戴设备(例如,一对智能眼镜或智能手表)或类似设备。在一些实现方式中,用户设备210可从平台220接收信息和/或向平台220发送信息。
29.平台220包括能够使用用于文本到语音合成的、会通知持续期的注意网络来生成音频波形,如在本文的其他地方所描述的。在一些实现方式中,平台220可包括云服务器或一组云服务器。在一些实现方式中,平台220可设计成模块化平台,使得某些软件组件可根据特定需要而换入或换出。因此,平台220可容易地和/或快速地针对不同用途来重新配置。
30.在一些实现方式中,如图所示,平台220可托管在云计算环境222中。应注意,虽然本文描述的实现方式将平台220描述成托管在云计算环境222中,但是在一些实现方式中,平台220不基于云(即,可以在云计算环境之外实现)或者可部分地基于云。
31.云计算环境222包括托管平台220的环境。云计算环境222可提供不需要终端用户
(例如,用户设备210)知道托管平台220的系统和/或设备的物理位置和配置的计算、软件、数据访问、存储等服务。如图所示,云计算环境222可包括一组计算资源224(这一组计算资源统称为“计算资源224”,单独一个计算资源称为“计算资源224”)。
32.计算资源224包括一个或多个个人计算机、工作站计算机、服务器设备或其他类型的计算和/或通信设备。在一些实现方式中,计算资源224可控制平台220。云资源可包括在计算资源224中运行的计算实例、在计算资源224中提供的存储设备、由计算资源224提供的数据传输设备等。在一些实现方式中,计算资源224可通过有线连接、无线连接或者有线连接和无线连接的组合与其他计算资源224通信。
33.进一步如图2所示,计算资源224包括一组云资源,例如一个或多个应用(“app”)224
‑
1、一个或多个虚拟机(“vm”)224
‑
2、虚拟化存储器(“vs”)224
‑
3、一个或多个管理程序(“hyp”)224
‑
4等。
34.应用224
‑
1包括可提供给用户设备210和/或传感器设备220或者由用户设备210和/或传感器设备220访问的一个或多个软件应用。应用224
‑
1可消除在用户设备210上安装和运行软件应用的需要。例如,应用224
‑
1可包括与平台220相关联的软件和/或能够通过云计算环境222提供的任何其他软件。在一些实现方式中,一个应用224
‑
1可通过虚拟机224
‑
2向一个或多个其他应用224
‑
1发送信息/从一个或多个其他应用224
‑
1接收信息。
35.虚拟机224
‑
2包括运行程序的机器(例如,计算机)的软件实现,类似于物理机。根据虚拟机224
‑
2对任何实际机器的对应程度和用途,虚拟机224
‑
2可以是系统虚拟机或过程虚拟机。系统虚拟机可提供支持完整操作系统(“os”)的运行的完整系统平台。过程虚拟机可运行单个程序,且可支持单个过程。在一些实现方式中,虚拟机224
‑
2可代表用户(例如,用户设备210)运行,且可管理云计算环境222的基础设施,例如数据管理、同步或长时间数据传输。
36.虚拟化存储器224
‑
3包括在计算资源224的存储系统或设备内使用虚拟化技术的一个或多个存储系统和/或一个或多个设备。在一些实现方式中,在存储系统的环境中,虚拟化的类型可包括块虚拟化和文件虚拟化。块虚拟化可指的是逻辑存储与物理存储的抽象化(或分离),使得可以在不考虑物理存储或异构结构的情况下访问存储系统。分离可允许存储系统的管理员在管理员如何管理终端用户的存储方面具有灵活性。文件虚拟化可消除以文件级别访问的数据与物理地存储文件的位置之间的依赖性。这可使得存储器使用、服务器整合和/或无干扰文件迁移性能得到优化。
37.管理程序224
‑
4可提供硬件虚拟化技术,硬件虚拟化技术允许多个操作系统(例如,“客户操作系统”)在主控计算机例如计算资源224上同时运行。管理程序224
‑
4可给客户操作系统呈现虚拟操作平台,且可管理客户操作系统的运行。各操作系统的多个实例可共享虚拟化硬件资源。
38.网络230包括一个或多个有线网络和/或无线网络。例如,网络230可包括蜂窝网络(例如,第五代(5g)网络、长期演进(lte)网络、第三代(3g)网络、码分多址(cdma)网络等)、公共陆地移动网络(plmn)、局域网(lan)、广域网(wan)、城域网(man)、电话网(例如,公共交换电话网(pstn))、专用网络、自组织网络、内部网、因特网、基于光纤的网络等,和/或这些或其他类型网络的组合。
39.图2所示的设备和网络的数量和布置作为示例来提供。在实践中,可存在额外的设
备和/或网络、更少的设备和/或网络、不同的设备和/或网络、或与图2所示的设备和/或网络不同地布置的设备和/或网络。此外,图2所示的两个或更多个设备可以在单个设备内实现,或者图2所示的单个设备可实现为多个分布式设备。另外或者替代地,环境200的一组设备(例如,一个或多个设备)可执行被描述成由环境200的另一组设备执行的一个或多个功能。
40.图3是设备300的示例组件的图。设备300可对应于用户设备210和/或平台220。如图3所示,设备300可包括总线310、处理器320、存储器330、存储组件340、输入组件350、输出组件360和通信接口370。
41.总线310包括允许设备300的组件之间进行通信的组件。处理器320以硬件、固件或者硬件和软件的组合来实现。处理器320是中央处理单元(cpu)、图形处理单元(gpu)、加速处理单元(apu)、微处理器、微控制器、数字信号处理器(dsp)、现场可编程门阵列(fpga)、专用集成电路(asic)或另一类型的处理组件。在一些实现方式中,处理器320包括能够被编程以执行功能的一个或多个处理器。存储器330包括随机存取存储器(ram)、只读存储器(rom)和/或另一类型的动态或静态存储设备(例如,闪存、磁性存储器和/或光学存储器),其存储供处理器320使用的信息和/或指令。
42.存储组件340存储与设备300的操作和使用相关的信息和/或软件。例如,存储组件340可包括硬盘(例如,磁盘、光盘、磁光盘和/或固态盘)、光碟(cd)、数字通用盘(dvd)、软盘、盒式磁带、磁带和/或另一类型的非暂时性计算机可读介质、以及相应的驱动器。
43.输入组件350包括允许设备300接收信息的组件,该信息例如通过用户输入(例如,触摸屏显示器、键盘、小键盘、鼠标、按钮、开关和/或麦克风)输入。另外或者替代地,输入组件350可包括用于感测信息的传感器(例如,全球定位系统(gps)组件、加速计、陀螺仪和/或致动器)。输出组件360包括提供来自设备300的输出信息的组件(例如,显示器、扬声器和/或一个或多个发光二极管(led))。
44.通信接口370包括类似收发器的组件(例如,收发机和/或单独的接收机和发射机),其使得设备300能够与其他设备通信,例如通过有线连接、无线连接或者有线连接和无线连接的组合与其他设备通信。通信接口370可允许设备300从另一设备接收信息和/或向另一设备提供信息。例如,通信接口370可包括以太网接口、光学接口、同轴接口、红外接口、射频(rf)接口、通用串行总线(usb)接口、wi
‑
fi接口、蜂窝网络接口等。
45.设备300可执行本文描述的一个或多个过程。设备300可响应于处理器320运行由诸如存储器330和/或存储组件340的非暂时性计算机可读介质存储的软件指令,来执行这些过程。在本文中,计算机可读介质定义为非暂时性存储器设备。存储器设备包括单个物理存储设备内的存储器空间或者分布在多个物理存储设备上的存储器空间。
46.软件指令可通过通信接口370从另一计算机可读介质读入存储器330和/或存储组件340中,或者从另一设备读入存储器330和/或存储组件340中。当运行时,存储在存储器330和/或存储组件340中的软件指令可使得处理器320执行本文描述的一个或多个过程。另外或者替代地,可使用硬连线电路来代替软件指令或者与软件指令组合,来执行本文描述的一个或多个过程。因此,本文描述的实现方式不限于硬件电路和软件的任何特定组合。
47.图3所示的组件的数量和布置作为示例来提供。在实践中,设备300可包括额外的组件、更少的组件、不同的组件、或与图3所示的组件不同地布置的组件。另外或者替代地,
设备300的一组组件(例如,一个或多个组件)可执行被描述成由设备300的另一组组件执行的一个或多个功能。
48.图4是使用用于文本到语音合成的、会通知持续期的注意网络来生成音频波形的示例过程400的流程图。在一些实现方式中,可由平台220执行图4的一个或多个过程块。在一些实现方式中,可由与平台220分离或包括平台220的另一设备或一组设备(例如,用户设备210)执行图4的一个或多个过程块。
49.如图4所示,过程400可包括通过设备接收包括文本分量的序列的文本输入(框410)。
50.例如,平台220可接收将要转换成音频输出的文本输入。文本分量可包括字符、音素、n元(n
‑
gram)、单词、字母等。文本分量的序列可形成句子、短语等。
51.进一步如图4所示,过程400可包括通过设备并使用持续时间模型来确定文本分量的相应持续时间(框420)。
52.持续时间模型可包括接收所输入的文本分量并确定所输入的文本分量的持续时间的模型。平台220可训练持续时间模型。例如,平台220可使用机器学习技术来分析数据(例如,训练数据,例如历史数据等)并创建持续时间模型。机器学习技术可包括例如监督技术和/或无监督技术,例如人工网络、贝叶斯统计、学习自动机、隐马尔可夫建模、线性分类器、二次分类器、决策树、关联规则学习等。
53.平台220可通过使已知持续期的语谱图帧和文本分量的序列对齐来训练持续时间模型。例如,平台220可使用基于hmm的强制对齐来确定文本分量的输入文本序列的地面真值持续期。平台220可通过使用已知持续期的预测或目标语谱图帧和包括文本分量的已知输入文本序列来训练持续时间模型。
54.平台220可将文本分量输入到持续时间模型中,并基于模型的输出来确定标识文本分量的相应持续时间或与文本分量的相应持续时间相关联的信息。标识相应持续时间或与相应持续时间相关的信息可用于生成第二语谱集,如下所述。
55.进一步如图4所示,过程400可包括确定是否已使用持续时间模型来确定每个文本分量的相应持续时间(框430)。
56.例如,平台220可迭代地或同时确定文本分量的相应持续时间。平台220可确定是否已针对输入文本序列的每个文本分量确定持续时间。
57.进一步如图4所示,如果没有使用持续时间模型来确定每个文本分量的相应持续时间(框430
‑
否),则过程400可包括返回到框420。
58.例如,平台220可将尚未确定持续时间的文本分量输入到持续时间模型中,直到给每个文本分量确定持续时间为止。
59.进一步如图4所示,如果已使用持续时间模型来确定每个文本分量的相应持续时间(框430
‑
是),则过程400可包括通过设备基于文本分量的序列来生成第一语谱集(框440)。
60.例如,平台220可生成对应于所输入的文本分量的序列的文本分量的输出语谱。平台220可利用cbhg模块来生成输出语谱。cbhg模块可包括一堆一维(1
‑
d)卷积滤波器、一组公路网、双向选通循环单元(gru)、循环神经网络(rnn)和/或其他组件。
61.在一些实现方式中,输出语谱可以是梅尔频率倒谱(mfc)语谱。输出语谱可包括用
于生成语谱图帧的任何类型的语谱。
62.进一步如图4所示,过程400可包括通过设备基于第一语谱集和文本分量的序列的相应持续时间来生成第二语谱集(框450)。
63.例如,平台220可使用第一语谱集和标识文本分量的相应持续时间或与文本分量的相应持续时间相关联的信息来生成第二语谱集。
64.作为示例,平台220可基于对应于语谱的基础文本分量的相应持续时间来复制第一语谱集的各个语谱。在一些情况下,平台220可基于复制因子、时间因子等,来复制语谱。换句话说,持续时间模型的输出可用于确定复制特定语谱、生成附加语谱等的因子。
65.进一步如图4所示,过程400可包括通过设备基于第二语谱集来生成语谱图帧(框460)。
66.例如,平台220可基于第二语谱集来生成语谱图帧。第二语谱集共同形成语谱图帧。如在本文的其他地方所描述的,使用持续时间模型生成的语谱图帧可更精确地类似于目标帧或预测帧。以这种方式,本文的一些实现方式提高了tts合成的精确度,提高了所生成的语音的自然度,提高了所生成的语音的韵律等。
67.进一步如图4所示,过程400可包括通过设备基于语谱图帧来生成音频波形(框470),以及通过设备提供音频波形作为输出(框480)。
68.例如,平台220可基于语谱图帧来生成音频波形,并提供音频波形来输出。作为示例,平台220可给输出组件(例如,扬声器等)提供音频波形,可给另一设备(例如,用户设备210)提供音频波形,可将音频波形传输给服务器或另一终端等。
69.虽然图4示出了过程400的示例块,但是在一些实现方式中,过程400可包括额外的块、更少的块、不同的块、或与图4所描绘的块不同地布置的块。另外或者替代地,可并行地执行过程400的两个或更多个块。
70.前述公开内容提供了说明和描述,但是不旨在穷举或将实现方式限制为所公开的精确形式。可根据上述公开内容进行修改和变化,或者可从实现方式的实践中获得修改和变化。
71.如本文所使用的,术语“组件”旨在广义地解释为硬件、固件或者硬件和软件的组合。
72.显然,本文描述的系统和/或方法可以以不同形式的硬件、固件或者硬件和软件的组合来实现。用于实现这些系统和/或方法的实际专用控制硬件或软件代码不限制实现方式。因此,在本文中未参考特定的软件代码来描述系统和/或方法的操作和行为
‑
应理解,软件和硬件可设计成实现基于本文的描述的系统和/或方法。
73.即使在权利要求中记载和/或在说明书中公开特征的特定组合,这些组合并不旨在限制可能的实现方式的公开。实际上,这些特征中的许多特征可以以未在权利要求中具体记载和/或在说明书中公开的方式组合。虽然下面列出的每个从属权利要求可仅直接从属于一个权利要求,但是可能的实现方式的公开包括每个从属权利要求与权利要求集中的每一个其他权利要求的组合。
74.除非本身明确地描述,否则本文使用的元素、动作或指令不应理解为至关重要或必要的。此外,如本文所使用的,冠词“一”和“一个”旨在包括一个或多个项目,且可与“一个或多个”互换地使用。此外,如本文所使用的,术语“集”旨在包括一个或多个项目(例如,相
关项目、不相关项目、相关项目和不相关项目的组合等),且可与“一个或多个”互换地使用。在意图仅是一个项目的情况下,使用术语“一”或类似的语言。此外,如本文所使用的,术语“具有”、“有”、“含有”或类似术语旨在是开放式术语。此外,短语“基于”的意思旨在是“至少部分地基于”,除非另有明确说明。