1.本发明属于嵌入式计算机技术领域,涉及一种基于嵌入式系统的端到端模型语音合成声码器。
背景技术:
2.随着与机器的语音交互越来越多,语音合成技术在现实中的应用越来越多,像ai合成主播,以及地铁广播等。但是,语音的合成质量或微小的变化都会对客户体验和客户的喜好产生很大的影响。因此,高质量的实时语音合成仍然是一个具有挑战性的任务。
3.目前,先进的语音合成模型有统计参数神经网络语音合成模型与端到端语音合成模型。文本到语音的合成通常分为两个部分。第一步是将文本转换为时间对齐的特征,比如mel
‑
光谱图。第二个模型是将这些时间对齐的特征转换为音频样本。第二种模型,有时称为声码器,主要影响质量,并决定速度。现在的语音合成多是在云端实现,但是,语音合成也迫切需要在离线端实现。
4.语音合成技术主要由编解码和声码器部分组成,编解码有fastspeech,tacotron等模型,声码器主要有wavernn,wavenet,waveglow模型。编解码的韵律调节方法有vae,gst等方法。提高声码器的推理速度,主要有稀疏化等方法。
5.本专利所述端到端语音合成网络能够将文本信息通过编解码结构后,再通过声码器实时地合成音频,从而易于布置在地铁嵌入式平台上,使地铁紧急广播成为可能。
6.中国发明专利申请,公开号cn1924994a,公开了一种嵌入式语音合成方法及系统,将系统接收到的或输入的文字转换成语音输出。首先创建基于声韵母的语音库,然后基于声韵母样本的上下文属性以及声学特征,对语音库进行压缩,得到最终语音库。但是该发明需要建立声韵母的语音库,比较繁琐。
7.中国发明专利申请,公开号ncmmsc2007,公开了一种实用的嵌入式语音合成方法,在该方法中,将tts系统的后端处理分为两个阶段:参数拼接和波形合成,并分别由mcu和dsp来承担。在此基础上,提出了一种新的拼接方法。但是,该发明所采用的拼接法很难获得较高的质量,相比目前广泛应用的神经网络方法,而且在推理的速度方面也没有做到实时。
技术实现要素:
8.本发明的主要目的是提供一种并行的语音合成网络。文字通过编解码,生成梅尔谱图,然后将图片通过声码器转换成语音文件。同时,在保证语音质量没有显著衰减的情况下,提高推理速度,做到实时,最后部署在嵌入式平台上面。
9.本发明的技术方案:
10.一种基于嵌入式系统的端到端语音合成网络,该端到端语音合成网络将文字文件转换到语音文件,步骤如下:
11.首先,对端到端语音合成网络的编码端fastspeech模型前馈一个韵律编码器,得到新的rhythm fastspeech网络;其中,韵律编码器由prenet模块和cbhg模块组成;prenet
模块由两层全连接层组成,cbhg模块输出一个隐藏状态序列;将输入频谱图中每个音素和韵律符合转为连续向量,通过prenet模块传递。通过两个独立的全连接层和relu激活函数来生成潜在变量。然后通过cbhg模块,输出一段隐藏状态序列,将序列转换为固定长度的上下文向量,提取更高级别特征,最后通过线性层输出。基于该编码端fastspeech模型构建编解码前端网络,以文字作为输入,输出梅尔谱图;
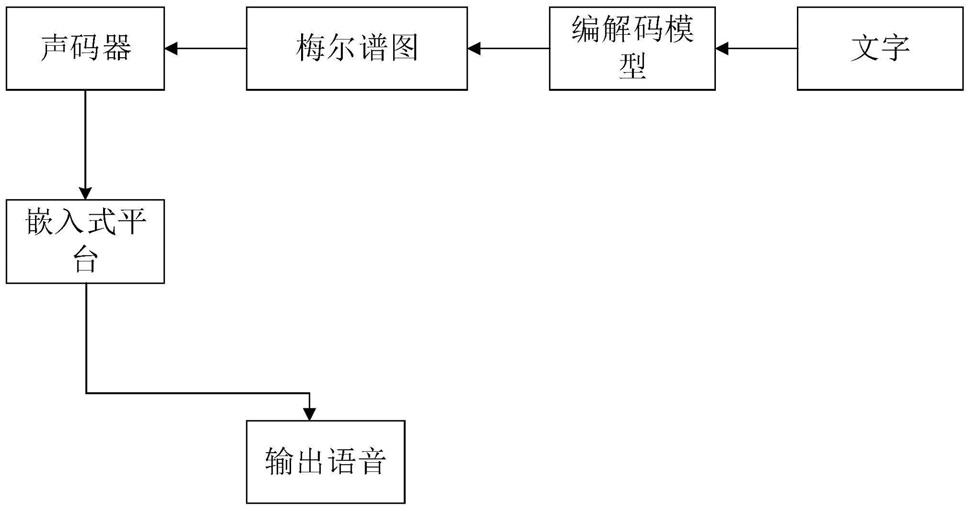
12.然后,对现有的waveglow声码器模型进行结构化稀疏化处理,在waveglow声码器模型中,将wn模型的扩展卷积部分和膨胀卷积部分用cnn进行替换;其次,去掉wn模型中多余的残差连接和跳跃连接,结构化稀疏化处理后的模型称为fast waveglow模型;因为膨胀卷积和扩展卷积是因果卷积,它是串行的,运算时间比较慢,所以用cnn来替换。之后,去掉wn部分多余的残差连接和跳跃连接。因为模型需要重复计算12次,每次间隔几个卷积层,都要进行一次求和运算,再作为输入,进行下次的卷积运算,去掉残差连接和跳跃连接可以减少运算次数。fast waveglow模型在保证网络预测性能不衰减的前提下,具有更少模型参数和更快在线预测速度。
13.最后,将新的rhythm fastspeech网络和经过稀疏化处理后的fast waveg
‑
low模型合并为一个单一的网络,同时进行训练,即end
‑
to
‑
end方法;同时具有模型小,预测准确率高,预测速度快的优点。首先,先将训练好的权重模型提取出来,将该权重模型转换成onnx模型,然后再将onnx模型转成rknn形式;在模型推理的过程中,对于不支持的算子用softmax函数进行替换;其次,将模型封装到推理函数中,最后在嵌入式平台上移植推理函数,运行推理函数,得到最终的输出结果。在保证质量没有明显衰减的情况下,可以将语音做到实时输出。
14.本发明的有益效果:采用该端到端网络,使用最新神经网络的方法,在减少参数和模型计算量的情况下,能够将推理速度大幅提高,并且通过前馈一个韵律编码器,达到韵律可调的作用。将文字通过前端编解码部分,生成梅尔谱图,之后通过声码器转为语音文件。即端到端的方法。该方法能够高效实时的合成音频,从而部署在地铁嵌入式平台上面。
附图说明
15.图1为现有技术中的语音合成系统的结构图;
16.图2为本发明中的嵌入式平台语音合成系统的结构图;
具体实施方式
17.以下结合附图和技术方案,进一步说明本发明的具体实施方式。
18.结合图1,合成语音,主要包括以下几个步骤:
19.步骤1:将文字通过编解码结构,转换成梅尔谱图。
20.步骤2:输入连续序列,先经过fastspeech中的k个1
‑
d卷积,这些卷积核可以对当前以及上下文信息有效建模。卷积输入堆叠一起,沿着时间轴最大池化以增加当前信息不变性,然后输入到几个固定宽带的1
‑
d卷积,将输出增加到起始的输入序列。所有卷积都采用batch normalization。输入多层的highway网络,用以提取更高级别的特征。最后在顶部加入双向gru,用于提取序列的上下文特征。频谱图通过韵律编码器的2层全连接和线性激活函数,生成潜在变量的均值。然后,通过16个不同宽度的1d卷积组成的卷积层,提取序列
上下文信息。之后通过池化层,保留特征不变,通过线性层输出。经由highway网络,提取更高级别特征。最后,通过双向rnn提取序列上下文信息。在预测时,特征频谱图与文字通过编码端和解码端的输出目标帧进行叠加。
21.步骤3:梅尔谱图通过声码器,合成出语音文件。我们取8组音频样本作为向量,称为“挤压”操作,将其作为输入向量,输入到声码器模型中。然后,我们通过几个“流程步骤”处理这些向量。这里的每个流动步骤由一个可逆的1
×
1卷积和一个仿射耦合层组成。可逆神经网络通常使用耦合层构建。在本专利中,使用了一个仿射耦合层。一半的通道作为输入,然后产生乘法和加法项,x
a
被不加更改地传递到层的输出。因此,当对网络求逆时,我们可以从输出x
a
中计算s和t,然后将x
b
求逆得到x
′
b
,最后将x
a
与x
′
b
进行拼接,得到最后的输出,公式如下所示:
22.x
a
,x
b
=split(x)
ꢀꢀ
(1)
23.(logs,t)=wn(x
a
,mel
‑
spectrogram)
ꢀꢀ
(2)
24.x
′
b
=s
⊙
x
b
+t
ꢀꢀ
(3)
[0025][0026]
输入x分为x
a
与x
b
。x
a
与梅尔谱图作为输入,通过wn进行运算,得到s和t。将s和x
b
进行卷积运算,再与t进行求和运算,得到x
′
b
。将x
a
与x
′
b
进行拼接,得到最终输出。
[0027]
步骤4:结构稀疏化
[0028]
在waveglow声码器模型中,将wn模型(wavenet)结构用cnn(convolutional neural networks)模型实现,wn模型的扩展卷积部分和膨胀卷积部分用cnn模型进行替换,因为膨胀卷积和扩展卷积是因果卷积,串行运算时间比较慢。之后,去掉多余的残差连接和跳跃连接,因为每次间隔几个卷积层,都要进行一次求和运算,再作为输入,进行下次的卷积运算。去掉多余的连接,可以减少运算次数。
[0029]
wn使用带gatedtanh非线性的膨胀卷积层,以及剩余连接和跳过连接,这种架构类似于wavenet和parallel wavenet。但是,卷积不是因果卷积,因为因果卷积需要许多层,或大型过滤器来增加感受野,所以wn框架部分采用膨胀卷积,使得网络在只有几层的情况下,可以拥有非常大的感受野。并且根据公式(logs,t)=wn(x
a
,mel
‑
spectrogram),输出完全由wn与(x
a
,mel
‑
spectrogram)的卷积运算所决定,而且wn模型部分有跳跃连接与残差连接,每次间隔几个卷积层,都要进行一次求和运算,再作为输入,进行下次的卷积运算。waveglow模型一共需要进行12次仿射耦合运算,计算量比较大,导致运行时间比较长,所以使得模型难于布置在cpu或嵌入式等平台上,并且很难有较好的实时性。而且wn部分的卷积并不是因果关系,所以本文这里采用普通cnn来实现wn,从而减少计算量,进而提高模型的训练速度和计算速度。通过如上的公式可以得出结论,将wn进行结构稀疏化处理,可以有效的加快运算速度,从而提高推理速度。
[0030]
步骤5:控制装置
‑
嵌入式平台运行
[0031]
结合图2,完成图1的操作后,将整个端到端语音合成网络训练好的权重转换成rknn模型,最后将rknn模型运行在嵌入式平台上面。最后通过测试,可以得出模型可以在嵌入式平台高速的合成语音文件。