融合dsnet与edsr网络的非平行多对多语音转换方法
技术领域
1.本发明涉及语音转换技术领域,具体涉及到一种融合dsnet与edsr网络的非平行多对多语音转换方法。
背景技术:
2.语音转换是语音信号处理领域中重要的研究分支,研究该技术有着重要的理论价值和应用前景。语音转换是一种将语音中源说话人的身份特征转换为目标说话人的身份特征,同时保证语音中的语义特征不变的技术。简言之,将一个人的一段语音转换成听起来像是由另一个指定说话人所发出的同一段语音。一个典型的语音转换系统可以分为两个阶段:训练阶段、转换阶段。在训练阶段,需要先进行语音分析和特征计算从而将语音波形信号编码成可以进行处理的语音特征。在传统的语音转换方法中还需要对源和目标说话人的语音进行时间对齐,从而使得具有相同音素内容的语音之间产生关联性,并且用这些对齐后的语音特征来训练转换模型,而在非平行语音转换方法中不需要执行时间对齐操作。在转换阶段,先计算出待转换语音的特征,用训练阶段训练好的转换模型进行特征转换,然后用语音合成器将转换后的特征合成为语音信号。
3.语音转换技术经过多年的研究,已经涌现了很多经典的转换方法。其中,基于高斯混合模型(gmm)的方法得到了广泛的研究,该方法利用统计参数模型来变换频谱特征;此外,神经网络也因其优异的性能而被应用于语音转换中,如递归神经网络(rnn)和深度神经网络(dnn)。包括上述提到的许多语音转换方法被归类为平行文本条件下的转换方法,这需要精确对齐的源语音和目标语音的并行数据。在一般情况下,收集平行文本语料可能是一个昂贵和耗时的过程,即使能够收集平行文本语料,我们通常需要执行自动时间对齐程序,当源语音和目标语音之间相差很大时,可能会导致无法对齐。因此,无论从语音转换系统的通用性还是实用性来考虑,研究非平行文本条件下的语音转换技术具有更大的应用价值和现实意义。
4.在语音转换领域的研究中,现有的非平行文本条件下的语音转换方法取得了很大进展,主要包括c
‑
vae(conditional variational auto
‑
encoder,基于条件变分自编码器)的方法、cycle
‑
gan(cycle
‑
consistent adversarial networks,基于循环一致对抗网络)的方法和stargan(star generative adversarial networks,基于星型生成对抗网络)的方法等,这些转换方法能够规避对平行文本的依赖,实现非平行文本条件下的转换。基于c
‑
vae模型的语音转换方法,直接利用说话人的身份标签建立语音转换系统,其中编码器实现语音的语义信息和说话人个性信息的分离,解码器通过语义和说话人身份标签来实现语音的重构,从而可以解除对平行文本的依赖。但是c
‑
vae模型改进的理想假设认为观察到的数据通常是服从高斯分布的,从而使解码器的输出语音过度平滑,导致转换语音的质量不好。以往的研究已经证明,基于cycle
‑
gan模型的语音转换方法能够产生更真实的语音。该模型可以同时学习声学特征的正映射和逆映射,主要是通过利用对抗损失和循环一致性损失来实现,可以有效地缓解过平滑问题,改善转换语音质量,虽然cycle
‑
gan模型被证明效果相
当好,但是该模型的局限性是它被设计为学习两个域之间的映射,只能实现一对一转换。
5.stargan(star generative adversarial networks,基于星型生成对抗网络)模型的语音转换方法同时具有c
‑
vae和cycle
‑
gan的优点,该方法的生成器结构由编码网络和解码网络组成,可以同时学习多对多映射,说话人身份标签控制着生成器的输出属性,因此可以实现非平行文本条件下的多对多语音转换。但是由于此方法中生成器的编码网络和解码网络之间相互独立,且编码网络和解码网络层次较低,整个生成器缺乏对深层特征的提取能力,直接通过编码网络无法生成较好的语义特征,同时生成器的解码网络也无法较好地实现语义特征和说话人个性特征的合成,因此在网络传输中容易丢失频谱深层的语义特征与说话人个性特征,造成转换语音的部分信息丢失和噪声的生成。针对这种情况,需要一种能够解决在训练过程中网络退化问题的方法,来提高生成器的编码网络对语义的学习能力,并且实现模型对频谱深层的语义特征与个性特征的学习能力,从而提高解码网络的频谱生成能力,使得转换后的语音在音质和个性相似度上有所提升。
6.目前,大多数基于深度学习的方法都是通过backbone网络实现的,其中两个最有名的方法就是resnet和densenet。resnet与densenet的不同之处在于,resnet采用求和的方法将之前所有的特征图连接起来,而densenet将所有的特征图使用级联的方式连接起来。尽管它们具有相近的性能,但它们两个都存在缺点。对于resnet,稳定训练的“短路连接”方式也限制了其表示能力,而densenet具有更高的特征,可以进行多层特征级联,但是,densenet中采用的密集级联产生了一些新的问题,即需要较高的gpu内存和更多的训练时间。dsnet结构的核心是dense weighted normalized shortcuts,吸取了上述两种方法的优点,采用加权归一化的“短路连接”和多层特征相加,实验结果也表明,dsnet比resnet取得了更好的结果,并且具有与densenet相当的性能,但需要的计算资源更少。dsnet在“短路连接”中加入了归一化和特征加权的操作,其中使用归一化的动机是为了将前面的所有特征归一化到一个相似的尺度,避免任何前一个特征支配整个求和,方便训练;同时,特征加权是为了让网络根据特征图的显著性来给每个归一化特征图分配适当的权值。
7.在图像领域中,resnet取得了显著的效果,它解决了深层卷积网络由于网络层次加深而引起的性能退化问题。resnet结构的核心是通过建立输入和输出之间的“短路连接”,有助于提升训练过程中梯度的反向传播,解决梯度消失问题,提高模型的训练效率。在图像sr(super
‑
resolution,超分辨率)领域,也使用resnet这种结构来搭建深度卷积网络,为sr问题中的峰值信噪比提供了显著的性能改进。但是,这样的网络在架构最优性方面有所限制:神经网络模型的重建性能对架构的微小变化很敏感,同样的模型在不同的初始化和训练技术之下实现的性能水平不同;srresnet虽然成功地解决了模型训练难的问题,并且有很好的性能,但它只是采用了原始的resnet架构,并不适用于超分辨率问题。edsr(enhanced deep super
‑
resolution network,增强型超分辨率网络)基于srresnet架构来构建,通过删除不必要的模块进行优化,把batch norm层去掉(bn层的计算量和一个卷积层几乎持平,移除bn层后训练时可以节省内存空间)以及相加后不经过relu层,同时为了保证训练更加稳定,在残差块相加前,经过卷积处理的输出乘以一个小数,这些改变构建出更简单的结构,并且在计算效率上优于原始网络。
技术实现要素:
8.本发明所要解决的技术问题:为了克服现有技术的不足,本发明提供一种融合dsnet与edsr网络的非平行多对多语音转换方法,该方法可以增强网络的表征能力,解决现有的语音转换技术中生成语音噪声过大的问题,降低编码网络对语义特征的学习难度,提高模型对频谱深层特征的学习能力,从而提高解码网络对语音频谱的生成质量,改善转换语音的音质和个性相似度。
9.本发明为解决以上技术问题而采用以下技术方案:本发明所述的融合dsnet与edsr网络的非平行多对多语音转换方法,包括训练阶段和转换阶段,所述训练阶段包括以下步骤:
10.(1.1)获取训练语料,训练语料由多名说话人的语料组成,所述说话人包含源说话人和目标说话人;
11.(1.2)使用world语音分析/合成模型提取出所述训练语料中各说话人语料的频谱包络特征x、非周期性特征以及基频特征;
12.(1.3)将源说话人的频谱包络特征x
s
、目标说话人的频谱包络特征x
y
、源说话人标签c
s
以及目标说话人标签c
t
,输入到转换网络进行训练,所述的转换网络由生成器g、鉴别器d、分类器c组成,所述的生成器g由编码网络、edsr网络、dsnet网络以及解码网络构成,dsnet网络构建在编码网络与解码网络之间。所述的edsr网络能够提升生成器对语音频谱信息提取能力,说话人频谱特征一同输入到edsr网络和编码网络中,再通过dsnet网络将编码网络的输出与edsr网络的输出进行特征融合;
13.(1.4)对所述转换网络训练过程中,使所述转换网络的生成器的损失函数、鉴别器的损失函数、分类器的损失函数尽量小,设置所述转换网络的超参数,使得目标函数最小化,直至设置的迭代次数,从而得到训练好的转换网络,称之为dsnet
‑
edsr stargan网络;
14.(1.5)构建从源说话人的语音基频到目标说话人的语音基频的基频转换函数;
15.所述转换阶段包括以下步骤:
16.(2.1)通过world语音分析/合成模型将待转换语料中源说话人的频谱包络特征x
s
'、非周期性特征和基频特征提取出来;
17.(2.2)将上述源说话人的频谱包络特征x
s
'和目标说话人的标签特征c
t
'输入到(1.4)中训练好的转换网络中,重构出目标说话人的频谱特征x
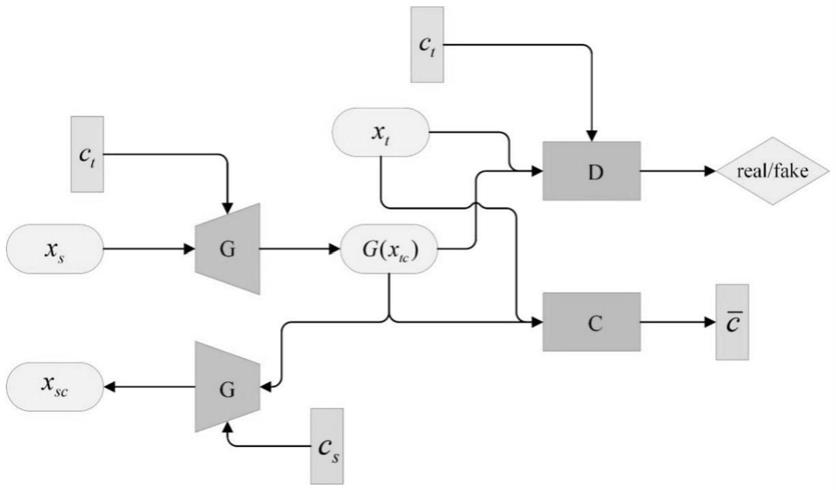
tc
';
18.(2.3)将步骤(2.1)中提取出的源说话人的基频,使用步骤(1.5)中的基频转换函数,转换为目标说话人的基频;
19.(2.4)使用world语音分析/合成模型将步骤(2.1)中提出的非周期性特征、步骤(2.2)中得到的重构目标说话人频谱特征x
tc
'和步骤(2.3)中得到的目标说话人的基频进行合成,得到转换后的说话人语音。
20.进一步说明,生成器g的编码网络与edsr网络和解码网络之间构建了dsnet网络。
21.进一步说明,步骤(1.3)和(1.4)中的训练过程包括以下步骤:
22.(1)将源说话人的频谱包络特征x
s
输入到生成器g的编码网络与edsr网络,得到说话人无关的语义特征g'(x
s
)和e'(x
s
);
23.(2)将上述得到的语义特征g'(x
s
)和e'(x
s
)输入到dsnet网络中进行特征融合,得到g(x
s
),再与目标说话人的标签特征c
t
一同输入到生成器g的解码网络进行训练,在训练过
程中最小化生成器g的损失函数,从而得到重构的目标说话人的频谱包络特征x
tc
;
24.(3)将上述得到的重构目标说话人的频谱包络特征x
yc
,再次输入到生成器g的编码网络与edsr网络,得到说话人无关的语义特征g'(x
tc
)和e'(x
tc
);
25.(4)将上述得到的语义特征g'(x
tc
)和e'(x
tc
)输入到dsnet网络进行特征融合,得到g(x
tc
),再与源说话人标签特征c
s
一同输入到生成器g的解码网络进行训练,在训练过程中最小化生成器g的损失函数,得到重构的源说话人的频谱包络特征x
sc
;
26.(5)将重构目标说话人的频谱包络特征x
tc
、目标说话人频谱包络特征x
t
以及目标说话人的标签特征c
t
,一同输入到鉴别器d中进行训练,最小化鉴别器d的损失函数;
27.(6)将重构目标说话人的频谱包络特征x
tc
、目标说话人的频谱包络特征x
t
输入到分类器c进行训练,最小化分类器c的损失函数;
28.(7)回到步骤(1)重复上述步骤,直至达到设置的迭代次数,从而得到训练好的dsnet
‑
edsr stargan网络。
29.进一步说明,步骤(2.2)中的输入过程包括以下步骤:
30.(1)将源说话人的频谱包络特征x
s
'输入到生成器g的编码网络和edsr网络,得到说话人无关的语义特征g'(x
s
')和e'(x
s
');
31.(2)将上述得到的语义特征g'(x
s
')和e'(x
s
')输入到dsnet网络中进行特征融合得到g'(x
s
'),再与目标说话人的标签特征c
t
'一同输入到生成器g的解码网络,得到目标说话人的频谱包络特征x
tc
'。
32.进一步说明,所述的生成器g的损失函数为:
[0033][0034]
其中,λ
cls
>=0、λ
cyc
>=0和λ
id
>=0分别表示分类损失、循环一致性损失和身份映射损失的正则化参数,l
cyc
(g)和l
id
(g)分别表示生成器的对抗损失、分类器优化生成器的分类损失、循环一致性损失和身份映射损失;
[0035]
所述的鉴别器d的损失函数为:
[0036][0037]
其中,d(x
t
,c
t
)表示鉴别器d判别真实频谱特征,g(x
s
,c
t
)表示生成器g生成的目标说话人频谱特征,d(g(x
s
,c
t
),c
t
)表示鉴别器判别生成的频谱特征,表示生成器g生成的概率分布的期望,表示真实概率分布的期望;
[0038]
所述的分类器c的损失函数为:
[0039][0040]
其中,p
c
(c
t
|x
t
)表示分类器判别目标说话人频谱特征为标签c
t
的真实频谱的概率。
[0041]
进一步说明,所述的生成器g的对抗损失函数为:
[0042][0043]
其中,表示生成器生成的概率分布的期望,g(x
s
,c
t
)表示生成器生成频谱特征;
[0044]
所述的生成器g的分类损失函数为:
[0045][0046]
其中,p
c
(c
t
|g(x
s
,c
t
))表示分类器判别生成目标说话人频谱特征标签属于c
t
的概率,g(x
s
,c
t
)表示生成器生成的目标说话人频谱特征;
[0047]
所述的生成器g的循环一致性损失函数为:
[0048][0049]
其中,g(g(x
s
,c
t
),c
s
)为重构的源说话人频谱特征,为重构的源说话人频谱和真实源说话人频谱的损失期望;
[0050]
所述的生成器g的身份映射损失函数为:
[0051][0052]
其中,g(x
s
,c
s
)为源说话人频谱和源说话人标签输入到生成器后,得到的重构源说话人频谱特征,为x
s
和g(x
s
,c
s
)的损失期望。
[0053]
进一步说明,所述的生成器g的编码网络包括5个卷积层,5个卷积层的过滤器大小分别为3*3、5*5、3*3、5*5、3*3,步长分别为1*1、2*2、1*1、2*2、9*1,过滤器深度分别为32、64、128、64、12;所述的edsr网络包括1个head卷积模块、1个body卷积模块和1个tail卷积模块,其中head包括1个卷积层,该卷积层的过滤器大小为5*5,步长为2*2,过滤器深度为64;body包括16个残差模块,每个残差模块包括2个卷积层,2个卷积层的过滤器大小分别为3*3、3*3,步长分别为1*1、1*1,过滤器深度分别为64、64;tail包括一个1个上采样层和2个卷积层,其中上采样层包括1个卷积层和1个pixelshuffle层,该卷积层的过滤器大小为3*3,步长为1*1,过滤器深度为256,该pixelshuffle层的尺度因子为2;2个卷积层的过滤器大小分别为3*3、3*3,步长分别为2*2、2*2,过滤器的深度分别为64、12;所述的生成器g的解码网络包括5个反卷积层,5个反卷积层的过滤器大小分别为3*3、5*5、3*3、5*5、3*3,步长分别为1*1、2*2、1*1、2*2、1*1,过滤器深度分别为64、128、64、32、1;在生成器编码网络与edsr网络以及解码网络之间,融合了dsnet网络。该网络由6层卷积块构成,每层卷积块都包括2个相同的卷积层,2个卷积层的过滤器大小分别为3*3、3*3,步长分别为1*1、1*1,过滤器深度分别为24、24。
[0054]
进一步说明,所述的鉴别器d包括5个卷积层,5个卷积层的过滤器大小分别为3*9、3*8、3*8、3*6、36*5,步长分别为1*1、1*2、1*2、1*2、36*1,过滤器深度分别为32、32、32、32、1。
[0055]
进一步说明,所述的分类器c包括5个卷积层,5个卷积层的过滤器大小分别为4*4、4*4、4*4、3*4、1*4,步长分别为2*2、2*2、2*2、1*2、1*2,过滤器深度分别为8、16、32、16、8。
[0056]
进一步说明,所述的基频转换函数为:
[0057][0058]
其中,μ
s
和σ
s
分别为源说话人的基频在对数域的均值和均方差,μ
t
和σ
t
分别为目标说话人的基频在对数域的均值和均方差,log f
0s
为源说话人的对数基频,log f
0t
'为转换后的目标说话人的对数基频。
[0059]
本发明采用以上技术方案,与现有技术相比具有有益效果为:
[0060]
本方法能够基于stargan基准模型以融合dsnet与edsr网络的方式来实现非平行文本条件下的多对多语音转换,主要通过编码网络结合edsr网络的方式来进一步提升模型对语音频谱特征信息的提取能力,再将编码网络和edsr网络中提取的特征频谱输入到dsnet网络中进行特征融合,从而较好地提升转换语音的音质和个性相似度,实现高质量的多对多语音转换。dsnet在“短路连接”中加入了归一化和特征加权的操作,可以将前面的所有特征频谱归一化到一个相似的尺度,方便训练;同时,dsnet能够使网络根据特征频谱的显著性来给每个归一化特征频谱分配适当的权值,避免任何前一个特征支配整个求和,通过强调有用信息,抑制无用信息,进一步增强模型的表征能力。通过将dsnet与edsr网络融合到stargan模型中,使得模型能够充分学习源说话人和目标说话人的语音特征和个性化特征,并且提升了生成器对语音语义特征的提取能力,克服了传统stargan模型中造成的语音特征丢失问题,改善了转换后的语音质量。本方法是基于stargan模型在语音转换领域中的进一步改进应用。
[0061]
本方法能够实现非平行文本条件下的多对多语音转换,并且训练过程中不需要任何对齐过程,提高了语音转换系统的通用性和实用性,本方法还可以将多个源
‑
目标说话人对的转换系统整合在一个转换模型中,即实现多说话人转换,在跨语种语音转换、电影配音、语言翻译及医疗辅助系统等丰富人机交互方面有广阔的市场应用前景。
附图说明
[0062]
图1是本发明实施例所述的模型的原理示意图;
[0063]
图2是本发明实施例所述的模型中生成器的网络结构图;
[0064]
图3是本发明实施例所述的模型中edsr的网络结构图;
[0065]
图4是本发明实施例所述的模型中dsnet的网络结构图;
具体实施方式
[0066]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅是本发明一部分实施例,并不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0067]
如图1所示,本发明提出的融合dsnet与edsr网络的非平行多对多语音转换方法,包括训练阶段和转换阶段,训练阶段用于得到语音转换所需的参数和转换函数,而转换阶段用于实现源说话人语音转换为目标说话人语音。
[0068]
进一步说明,训练阶段包括以下步骤:
[0069]
步骤1、获取非平行文本的训练语料,训练语料由多名源说话人和目标说话人的语料组成。训练所需要的语音语料库取自vcc2018,该语料库的训练集中包括6名男性说话人和6名女性说话人,其中vcc2sf3、vcc2sf4、vcc2sm3、vcc2sm4与vcc2tf1、vcc2tf2、vcc2tm1、vcc2tm2的语音内容是不相同的,本发明是使用非平行文本的训练语料进行训练,因此从语料库的训练集中选取以上八位说话人的语料作为训练语料,每位说话人有81句语料,语音总时长约5分钟。
[0070]
步骤2、使用world语音分析/合成模型从训练语料中提取出每个说话人的频谱特
征x、非周期性特征、对数基频log f0。其中将快速傅氏变换(fast fourier transformation,fft)的长度设置为1024,可以得到频谱特征x和非周期性特征均为1024/2+1=513维。每一个语音数据有512帧,从频谱包络特征中提取36维的梅尔倒谱系数(mcc)特征,一次训练时的批次设置为8。因此,训练语料的维度为8*36*512。
[0071]
步骤3、本实施例中的融合dsnet和edsr网络的非平行多对多语音转换方法以stargan模型为基准,通过改善stargan模型结构,来提升转换网络的效果。stargan基准模型由三部分组成:一个产生真实频谱的生成器g,一个判断输入频谱是真实频谱特征还是生成频谱特征的鉴别器d,以及一个判别生成器频谱特征的标签是否属于标签c
t
的分类器c。
[0072]
dsnet
‑
edsr stargan网络的目标函数为:
[0073][0074]
其中,l
g
(g)为生成器的损失函数:
[0075][0076]
其中,λ
cls
>=0、λ
cyc
>=0和λ
id
>=0分别表示分类损失、循环一致性损失和身份映射损失的正则化参数,l
cyc
(g)和l
id
(g)分别表示生成器的对抗损失、分类器优化生成器的分类损失、循环一致性损失和身份映射损失;
[0077]
为鉴别器d的损失函数:
[0078][0079]
其中,d(x
t
,c
t
)表示鉴别器d判别真实频谱特征,g(x
s
,c
t
)表示生成器g生成的目标说话人频谱特征,d(g(x
s
,c
t
),c
t
)表示鉴别器判别生成的频谱特征,表示生成器g生成的概率分布的期望,表示真实概率分布的期望;
[0080]
为分类器c的损失函数:
[0081][0082]
其中,p
c
(c
t
|x
t
)表示分类器判别目标说话人频谱特征为标签c
t
的真实频谱的概率。
[0083]
步骤4、将步骤2中提取的源说话人频谱特征x
s
与目标说话人标签特征c
t
作为联合特征(x
s
,c
t
)输入到生成器中进行训练。训练生成器,直至达到设置的迭代次数,使得生成器的损失函数l
g
尽可能小,得到生成目标说话人频谱特征x
tc
。
[0084]
生成器由编码网络、edsr网络、dsnet网络和解码网络组成,编码网络由5个卷积层组成,5个卷积层的过滤器大小分别为3*3、5*5、3*3、5*5、3*3,步长分别为1*1、2*2、1*1、2*2、9*1,过滤器深度分别为32、64、128、64、12。edsr网络由1个head卷积模块、1个body卷积模块和1个tail卷积模块组成,其中head包括1个卷积层,该卷积层的过滤器大小为5*5,步长为2*2,过滤器深度为64;body包括16个残差模块,每个残差模块包括2个卷积层,2个卷积层的过滤器大小分别为3*3、3*3,步长分别为1*1、1*1,过滤器深度分别为64、64;tail包括一个1个上采样层和2个卷积层,其中上采样层包括1个卷积层和1个pixelshuffle层,该卷积层的过滤器大小为3*3,步长为1*1,过滤器深度为256,该pixelshuffle层的尺度因子为2;2个卷积层的过滤器大小分别为3*3、3*3,步长分别为2*2、2*2,过滤器的深度分别为64、12。
其中,dsnet网络融合在生成器编码网络与edsr网络以及解码网络之间,由6层卷积块构成,每层卷积块都包括2个相同的卷积层,2个卷积层的过滤器大小分别为3*3、3*3,步长分别为1*1、1*1,过滤器深度分别为24、24。解码网络由5个反卷积层组成,5个反卷积层的过滤器大小分别为3*3、5*5、3*3、5*5、3*3,步长分别为1*1、2*2、1*1、2*2、1*1,过滤器深度分别为64、128、64、32、1。
[0085]
步骤5、将步骤4得到的生成目标说话人频谱特征x
tc
和步骤2得到的训练语料的目标说话人频谱特征x
c
以及目标说话人标签c
t
,一同输入到鉴别器中来训练鉴别器,使鉴别器的损失函数尽可能小。
[0086]
鉴别器是由二维卷积神经网络搭建而成,包括5个卷积层,5个卷积层的过滤器大小分别为3*9、3*8、3*8、3*6、36*5,步长分别为1*1、1*2、1*2、1*2、36*1,过滤器深度分别为32、32、32、32、1。
[0087]
鉴别器的损失函数为:
[0088][0089]
优化目标为:
[0090][0091]
步骤6、将步骤4得到的生成目标说话人频谱特征x
tc
再次输入到生成器g的编码网络和edsr网络,通过dsnet网络进行特征融合之后得到说话人无关的语义特征g(x
tc
),将g(x
tc
)与源说话人标签特征c
s
一同输入到生成器g的解码网络进行训练,得到重构的源说话人频谱特征x
sc
。在整个训练过程中最小化生成器的损失函数,包括生成器的对抗损失、循环一致性损失、身份映射损失以及生成器的分类损失。其中,循环一致性损失使得转换后的语音特征可以保留更多的语义特征。身份映射损失来确保当输入的真实语音特征已经属于标签为c'的说话人时,其频谱特征保持不变。生成器的分类损失指分类器判别生成器所生成的目标说话人频谱特征x
tc
属于标签c
t
的概率损失。
[0092]
生成器的损失函数为:
[0093][0094]
优化目标为:
[0095][0096]
其中,λ
cls
>=0、λ
cyc
>=0和λ
id
>=0分别表示分类损失、循环一致性损失和身份映射损失的正则化参数。
[0097]
dsnet
‑
edsr stargan网络中生成器的对抗损失表示为:
[0098][0099]
其中,x
s
~p(x
s
)表示任意说话人的一段语音的声学特征,表示生成器生成的概率分布的期望,g(x
s
,c
t
)表示生成器生成的频谱特征。在训练过程中使的值逐渐变小,不断优化生成器,使得生成器g能够成功欺骗鉴别器d,即鉴别器将生成器生成的语音特征g(x
s
,c
t
)错误地分类为真实语音特征。
[0100]
分类器c用来优化生成器的分类损失表示为:
[0101][0102]
其中,p
c
(c
t
|g(x
s
,c
t
))是生成的频谱特征g(x
s
,c
t
)被分类器分类的概率分布,g(x
s
,c
t
)表示生成器生成的目标说话人频谱特征。当分类器能够将g(x
s
,c
t
)正确地分类为说话人类别c
t
时,的值应该是尽可能小的。因此,在训练过程中,通过最小化来优化生成器g,使得生成器g生成的频谱特征g(x
s
,c
t
)能够被分类器正确分类为类别c
t
。
[0103]
进一步说明,l
cyc
(g)为生成器g的循环一致性损失:
[0104][0105]
其中,g(g(x
s
,c
t
),c
s
)为重构的源说话人频谱特征,为重构源说话人频谱特征和真实源说话人频谱特征的损失期望。在训练过程中,使l
cyc
(g)损失尽可能小,来保证生成器g可以保留更多语音特征中的语义信息,使说话人语音的语义特征在经过生成器的编码之后不被损失。
[0106]
l
id
(g)为生成器g的身份映射损失:
[0107][0108]
其中,g(x
s
,c
s
)为生成器生成的源说话人频谱特征,为x
s
和g(x
s
,c
s
)的损失期望。使l
id
(g)尽可能小,来确保当输入的源说话人频谱特征已经属于标签c
s
的说话人时,其频谱特征保持不变。
[0109]
步骤7、将上述生成的目标说话人频谱特征x
tc
和真实目标说话人的频谱特征x
t
输入到分类器中进行训练,最小化分类器的损失函数。
[0110]
分类器c是由二维卷积神经网络搭建而成,包括5个卷积层,5个卷积层的过滤器大小分别为4*4、4*4、4*4、3*4、1*4,步长分别为2*2、2*2、2*2、1*2、1*2,过滤器深度分别为8、16、32、16、8。
[0111]
分类器的损失函数为:
[0112][0113]
优化目标为:
[0114][0115]
步骤8、重复步骤4/5/6/7,使得目标函数最小化,直至达到迭代次数。在训练过程中,使所述转换网络的对抗损失、分类损失、循环一致性损失和身份映射损失尽可能小,直至设置的迭代次数,从而得到训练好的所述转换网络。本实验中设置的迭代次数为200000次。
[0116]
步骤9、使用对数基频log f0的均值和均方差建立基音频率转换关系,统计出每个说话人的对数基频的均值和均方差,利用对数域线性变换将源说话人对数基频log f
0s
转换为目标说话人对数基频log f
0t
'。
[0117]
进一步说明,基频转换函数为:
[0118]
[0119]
其中,μ
s
和σ
s
分别为源说话人的基频在对数域的均值和均方差,μ
t
和σ
t
分别为目标说话人的基频在对数域的均值和均方差,log f
0s
为源说话人的对数基频,log f
0t
'为转换的目标说话人对数基频。
[0120]
进一步说明,转换阶段包括以下步骤:
[0121]
步骤1、通过world语音分析/合成模型将待转换语料中源说话人的频谱包络特征x
s
'、非周期性特征和基频特征提取出来;
[0122]
步骤2、将上述源说话人的频谱包络特征x
s
'和目标说话人的标签特征c
t
'输入到训练阶段步骤8中训练好的转换网络中,重构出目标说话人的频谱特征x
tc
';
[0123]
步骤3、将步骤1中提取的源说话人基频特征,使用训练阶段步骤9中的基频转换函数,转换为目标说话人的基频;
[0124]
步骤4、使用world语音分析/合成模型,将步骤1中提取的非周期性特征、步骤2中得到的重构目标说话人频谱特征x
tc
'和步骤3中得到的目标说话人的基频等进行合成,得到转换后的说话人语音。
[0125]
以上所述为本发明的示例性实施例,并非因此限制本发明专利保护范围,凡是利用本发明内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。