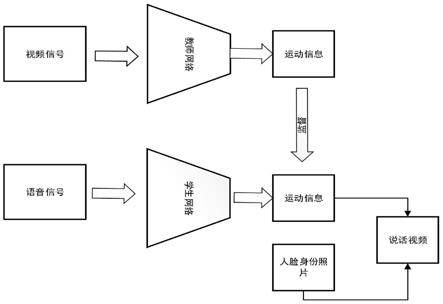
1.本发明涉及多媒体领域和人工智能领域,特别是涉及一种基于教师学生网络的语音驱动说话人脸视频生成方法。
背景技术:
2.任意说话人脸视频生成技术是指输入任意一个人的一张正脸照片和其一段说话语音,然后生成该人正脸说话的视频,且生成的视频有准确的唇动和表情变化。由单张人脸图片和说话语音生成自然流畅的说话人脸视频十分具有挑战性,其需要生成保留身份特征的多帧人脸,而且要求人脸变化尤其是唇形变化在时域上要与输入的语音一致。说话人脸视频生成技术在虚拟主播、智能家居、游戏电影人物制作等领域具有十分广阔的应用前景和潜力。
3.说话人脸生成任务最早可以追溯到上个世纪九十年代,当时是使用稀疏网格建模人脸,然后使用语音信号驱动人脸网格运动。20世纪初,麻省理工的ezzat提出“make it talk”的方案,通过收集单人一定数量的说话人脸视频形成单人视频库,然后将文本信号转换成音素信号,再将音素信号在单人视频库中搜索最合适的视素,最后使用光流计算这些视素的中间帧来生成视频。近年来,随着计算机计算能力的增长、大规模数据集的构建以及深度学习的兴起,2016年vgg组的joon son chung在其论文《you said that?》中首次实现了使用编解码学习结构在大规模数据集lrw上训练,只使用单张人脸照片和说话音频就可以生成单张人脸说话视频。随后的技术都是使用视频帧作为真值来对网络进行自监督学习,但是这些方法都没有充分挖掘视频信息的动态信息。
技术实现要素:
4.本发明针对现有技术的不足,在深度学习自编码器生成模型的基础上,融入生成对抗网络和知识蒸馏在图像生成方面的优良特性,提出了一种基于教师学生网络的语音驱动说话人脸视频生成方法。首先利用教师网络压缩出视频数据中的动态信息,接着利用学生网络学习语音到动态信息的预测,然后使用预训练好的教师网络提取的人脸动态信息作为监督,结合人脸身份信息实现语音驱动人脸的说话任务。
5.为了达到上述目的,本发明提供的技术方案是一种基于教师学生网络的语音驱动说话人脸视频生成方法,包括以下步骤:
6.步骤1,获取大量的说话人脸视频数据集;
7.步骤2,使用ffmpeg工具从步骤1获取的数据集中提取视频帧和语音数据;
8.步骤3,使用dlib库提供的人脸检测工具提取步骤2视频帧中的人脸照片,并将其转换成正脸照片,然后剪裁成n
×
n尺寸的正脸照片i1,使用语音处理工具库python_speech_features提取步骤2语音信号的mfcc特征;
9.步骤4,使用face_alignment提供的人脸对齐工具,检测步骤3剪裁好的正脸照片i1中的人脸特征点;
10.步骤5,构建并训练教师网络;
11.步骤6,构建并训练学生网络;
12.步骤7,级联学生网络训练;
13.步骤8,将步骤3提取的mfcc特征序列和任意人脸照片i输入到步骤7训练好的级联学生网络中,即可得到对应的图片序列,然后使用ffmpeg将图片序列合成视频。
14.而且,所述步骤5中构建并训练教师网络包括以下几个步骤:
15.步骤5.1,整个网络采取自监督学习的方式,分别对步骤4检测出的人脸特征点l1、l2和剪裁好的正脸照片i1使用三个编码器f1、f2、f3进行编码,生成隐变量z1、z2、z3;
16.步骤5.2,令z4=concat((z2‑
z1),z3),用解码器f
d
对z4进行解码,得到表现剪裁好的正脸照片i1变化的区域范围m和变化区域内像素值的变化信息c,动态特征m和c的计算方式如下:
17.(m,c)=f
d
(z4)
ꢀꢀ
(1)
18.步骤5.3,利用步骤5.2计算得到的参数m和c,结合剪裁好的正脸照片i1,得到合成照片i1′
:
19.i1′
=m
×
c+(1
‑
m)
×
i1ꢀꢀ
(2)
20.步骤5.4,使用w
‑
gan
‑
gp算法的网络架构对教师网络进行训练。
21.而且,所述步骤5.4中使用w
‑
gan
‑
gp算法的网络架构对教师网络进行训练包括生成器训练阶段和判别器训练阶段:
22.步骤5.4.1,生成器训练阶段,给定预处理好的人脸特征点l1、l2和剪裁好的正脸照片i1,使用步骤5.1
‑
5.3的计算流程,网络通过预测的运动信息m和c生成图片i1′
,并计算生成器的损失函数l
loss
:
23.l
loss
=l
rec
+l
reg
+l
gen
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
24.l
rec
=||i1‑
i1′
||1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
25.l
reg
=||m||1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
26.l
gen
=
‑
d
i
([i1′
,m])
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0027]
式中,l
rec
为重建损失,l
reg
为稀疏正则化损失,l
gen
为对抗损失,d
i
(
·
)表示判别器,||||1表示l1范数。
[0028]
步骤5.4.2,判别器训练阶段,使用w
‑
gan
‑
gp的判别器部分,判别器损失函数计算方式为:
[0029][0030][0031]
式中,表示求导,d
i
(
·
)表示判别器,||||表示l2范数,λ=10,l
gp
表示lipschitz惩罚系数,为了解决梯度爆炸。
[0032]
生成阶段和判别阶段交替训练直到算法收敛,教师网络训练结束。
[0033]
而且,所述步骤6中构建并训练学生网络包括以下几个步骤:
[0034]
步骤6.1,使用步骤3提取到的语音信号的mfcc特征,以视频帧的时间点为中心,加上一个10ms的时间窗提取mfcc信号;
[0035]
步骤6.2,使用步骤5训练好的教师网络,输入人脸特征点l1、l2和剪裁好的正脸照片i1,得到变化区域m和变化区域内像素值的变化信息c;
[0036]
步骤6.3,输入步骤6.1切割好的语音信号10ms的mfcc特征a
mfcc
和一张剪裁好的正脸照片i1,分别使用语音编码器f4和身份信息编码器f5进行编码,生成隐变量z5和z6,然后令z7=concat(z5,z6);
[0037]
步骤6.4,使用解码器预测运动信息(m
s
,c
s
),
[0038]
步骤6.5,利用步骤6.4计算得到的参数m
s
和c
s
,结合剪裁好的正脸照片i1,得到合成照片i
′
1s
:
[0039]
i
1s
′
=m
s
×
c
s
+(1
‑
m
s
)
×
i1ꢀꢀ
(9)
[0040]
步骤6.6,使用w
‑
gan
‑
gp算法的网络架构对学生网络进行训练。
[0041]
而且,所述步骤6.6中使用w
‑
gan
‑
gp算法的网络架构对学生网络进行训练包括生成器训练阶段和判别器训练阶段:
[0042]
步骤6.6.1,生成器训练阶段,给定mfcc特征a
mfcc
和剪裁好的正脸照片i1,使用步骤6.2
‑
6.5的计算流程,学生网络通过预测的运动信息m
s
和c
s
生成图片i
′
1s
,并计算生成器的损失函数l
′
loss
:
[0043]
l
′
loss
=l
′
rec
+l
′
reg
+l
′
gen
+l
mot
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0044]
l
′
rec
=||i1‑
i1′
s
||1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0045]
l
′
reg
=||m||1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0046]
l
′
gen
=
‑
d
i
([i
1s
′
,m])
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0047]
l
mot
=||m
s
‑
m||1+||c
s
‑
c||1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)
[0048]
式中,l
′
rec
为重建损失,l
′
reg
为稀疏正则化损失,l
′
gen
为对抗损失,l
mot
为监督运动信息损失,d
i
(
·
)表示判别器,||||1表示l1范数。
[0049]
步骤6.6.2,判别器训练阶段,使用w
‑
gan
‑
gp的判别器部分,判别器损失函数为:
[0050][0051][0052]
式中,表示求导,d
i
(
·
)表示判别器,||||表示l2范数,λ=10,l
′
gp
表示lipschitz惩罚系数,为了解决梯度爆炸。
[0053]
生成阶段和判别阶段交替训练直到算法收敛,学生网络训练结束。
[0054]
而且,所述步骤7中级联学生网络训练包括以下几个步骤:
[0055]
步骤7.1,将步骤3提取的mfcc特征序列{a1,a2,...a
n
}依次通过步骤6.3中的语音编码器f4得到语音隐变量序列{a
′1,a
′2,...a
′
n
};
[0056]
步骤7.2,输入人脸身份照片i1,通过步骤6.3中的身份编码器f5得到身份隐变量z,通过广播机制将隐变量z与语音隐变量序列{a
′1,a
′2,...a
′
n
}拼接得到隐变量序列{b1,b2,...b
n
};
[0057]
步骤7.3,为了建模时序序列的时序性,将隐变量序列{b1,b2,...b
n
}输入lstm网络得到包含时序信息的隐变量序列{b
′1,b
′2,...b
′
n
},然后再将隐变量序列{b
′1,b
′2,...b
′
n
}中的每一个隐变量分别按照步骤6.4
‑
6.6进行训练,生成图片序列{i
1a
,i
2a
,...i
na
}。
[0058]
与现有技术相比,本发明具有如下优点:相比于传统的任意说话人脸视频生成技术,本发明首次挖掘视频信号中的动态信息,在人脸生成、图片清晰度和生成说话人脸的视频唇形的准确度上有较大的提升。
附图说明
[0059]
图1为本发明实施例的网络结构图。
[0060]
图2为本实施例基于对抗网络的教师网络模型框图。
[0061]
图3为本实施例基于对抗网络的学生网络模型框图。
[0062]
图4为本实施例基于对抗网络的级联学生网络模型框图。
具体实施方式
[0063]
本发明提供一种基于教师学生网络的语音驱动说话人脸视频生成方法,首先利用教师网络压缩出视频数据中的动态信息,接着利用学生网络学习语音到动态信息的预测,然后使用预训练好的教师网络提取的人脸动态信息作为监督,结合人脸身份信息实现语音驱动人脸的说话任务。
[0064]
下面结合附图和实施例对本发明的技术方案作进一步说明。
[0065]
如图1所示,本发明实施例的流程包括以下步骤:
[0066]
步骤1,获取大量的说话人脸视频数据集。
[0067]
步骤2,使用ffmpeg工具从步骤1获取的数据集中提取视频帧和语音数据。
[0068]
步骤3,使用dlib库提供的人脸检测工具提取步骤2视频帧中的人脸照片,并将其转换成正脸照片,然后剪裁成n
×
n尺寸(n可以取64、128、256等值)的正脸照片i1,使用语音处理工具库python_speech_features提取步骤2语音信号的mfcc特征。
[0069]
步骤4,使用face_alignment提供的人脸对齐工具,检测步骤3剪裁好的正脸照片i1中的人脸特征点。
[0070]
步骤5,构建并训练教师网络。
[0071]
步骤5.1,整个网络采取自监督学习的方式,首先分别对步骤4检测出的人脸特征点l1、l2和剪裁好的正脸照片i1使用三个编码器f1、f2、f3进行编码,生成隐变量z1、z2、z3。
[0072]
步骤5.2,令z4=concat((z2‑
z1),z3),用解码器f
d
对z4进行解码,得到表现剪裁好的正脸照片i1变化区域m和变化区域内像素值的变化信息c。
[0073]
动态特征m和c的计算方式如下:
[0074]
(m,c)=f
d
(z4)
ꢀꢀ
(1)
[0075]
步骤5.3,利用步骤5.2计算得到的参数m和c,结合剪裁好的正脸照片i1,得到合成照片i1′
。
[0076]
合成照片i1′
的计算方式如下:
[0077]
i1′
=m
×
c+(1
‑
m)
×
i1ꢀꢀ
(2)
[0078]
步骤5.4,使用w
‑
gan
‑
gp算法的网络架构对教师网络进行训练。
[0079]
步骤5.4.1,生成器训练阶段,给定预处理好的人脸特征点l1、l2和剪裁好的正脸照片i1,使用步骤5.1
‑
5.3的计算流程,网络通过预测的运动信息m和c生成图片i1′
,生成器的损失函数l
loss
包含重建损失l
rec
、稀疏正则化损失l
reg
和对抗损失l
gen
三个损失函数,计算方
式如下:
[0080]
l
loss
=l
rec
+l
reg
+l
gen
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0081]
l
rec
=||i1‑
i1′
||1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0082]
l
reg
=||m||1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0083]
l
gen
=
‑
d
i
([i1′
,m])
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0084]
式中,d
i
(
·
)表示判别器,||||1表示l1范数。
[0085]
步骤5.4.2,判别器训练阶段,使用w
‑
gan
‑
gp的判别器部分,判别器损失函数计算方式为:
[0086][0087][0088]
式中,表示求导,d
i
(
·
)表示判别器,||||表示l2范数,λ=10,l
gp
表示lipschitz惩罚系数,为了解决梯度爆炸。
[0089]
生成阶段和判别阶段交替训练直到算法收敛,教师网络训练结束。
[0090]
步骤6,构建并训练学生网络。
[0091]
步骤6.1,使用步骤3提取到的语音信号的mfcc特征,以视频帧的时间点为中心,加上一个10ms的时间窗提取mfcc信号。
[0092]
步骤6.2,使用步骤5预训练好的教师网络,输入人脸特征点l1、l2和剪裁好的正脸照片i1,得到变化区域m和变化区域内像素值的变化信息c。
[0093]
步骤6.3,输入步骤6.1切割好的语音信号10ms的mfcc特征a
mfcc
和一张剪裁好的正脸照片i1,分别使用语音编码器f4和身份信息编码器f5进行编码,生成隐变量z5和z6,然后令z7=concat(z5,z6)。
[0094]
步骤6.4,使用解码器预测运动信息(m
s
,c
s
),
[0095]
步骤6.5,利用步骤6.4计算得到的参数m
s
和c
s
,结合剪裁好的正脸照片i1,得到合成照片i
′
1s
。
[0096]
合成照片i
′
1s
的计算方式如下:
[0097]
i
1s
′
=m
s
×
c
s
+(1
‑
m
s
)
×
i1ꢀꢀ
(9)
[0098]
步骤6.6,使用w
‑
gan
‑
gp算法的网络架构对学生网络进行训练。
[0099]
步骤6.6.1,生成器训练阶段,给定mfcc特征a
mfcc
和剪裁好的正脸照片i1,使用步骤6.2
‑
6.5的计算流程,学生网络通过预测的运动信息m
s
和c
s
生成图片i
′
1s
,生成器的损失函数l
′
loss
包含重建损失l
rec
、稀疏正则化损失l
reg
、对抗损失l
gen
和监督运动信息损失l
mot
四个损失函数,计算方式如下:
[0100]
l
′
loss
=l
′
rec
+l
′
reg
+l
′
gen
+l
mot
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0101]
l
′
rec
=||i1‑
i
1s
′
||1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0102]
l
′
reg
=||m||1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0103]
l
′
gen
=
‑
d
i
([i
1s
′
,m])
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0104]
l
mot
=||m
s
‑
m||1+||c
s
‑
c||1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)
[0105]
式中,d
i
(
·
)表示判别器,||||1表示l1范数。
[0106]
步骤6.6.2,判别器训练阶段,使用w
‑
gan
‑
gp的判别器部分,判别器损失函数为:
[0107][0108][0109]
式中,表示求导,d
i
(
·
)表示判别器,||||表示l2范数,λ=10,l
′
gp
表示lipschitz惩罚系数,为了解决梯度爆炸。
[0110]
生成阶段和判别阶段交替训练直到算法收敛,学生网络训练结束。
[0111]
步骤7,级联学生网络训练。
[0112]
步骤7.1,将步骤3提取的mfcc特征序列{a1,a2,...a
n
}依次通过步骤6.3中的语音编码器f4得到语音隐变量序列{a
′1,a
′2,...a
′
n
};
[0113]
步骤7.2,输入人脸身份照片i1,通过步骤6.3中的身份编码器f5得到身份隐变量z,通过广播机制将其与语音隐变量序列{a
′1,a
′2,...a
′
n
}拼接得到隐变量序列{b1,b2,...b
n
};
[0114]
步骤7.3,为了建模时序序列的时序性,将隐变量序列{b1,b2,...b
n
}输入lstm网络得到包含时序信息的隐变量序列{b
′1,b
′2,...b
′
n
},将隐变量序列{b
′1,b
′2,...b
′
n
}中的每一个隐变量分别按照步骤6.4
‑
6.6进行训练,生成图片序列{i
1a
,i
2a
,...i
na
}。
[0115]
步骤8,将步骤3提取的mfcc特征序列{a1,a2......a
n
}和任意人脸照片i输入到步骤7训练好的级联学生网络中,即可得到对应的图片序列{i
1a
,i
2a
,...i
na
},然后使用ffmpeg将图片序列合成视频。
[0116]
具体实施时,以上流程可采用计算机软件技术实现自动运行流程。
[0117]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。