一种基于时
‑
频双分支特征的猕猴情绪识别方法及系统
技术领域
1.本发明涉及计算机技术领域,特别涉及一种基于时
‑
频双分支特征的猕猴情绪识别方法及系统。
背景技术:
2.灵长类动物正面临着严重的生存危机,了解灵长类动物的生活习性,对有效开展灵长类动物保护具有重要研究价值。近年来,人工智能(artificial intelligence,ai),尤其是深度学习(deep learning,dl)在多个领域的应用中取得了超过经典算法的成果,例如语音信号处理领域(语音识别、语音合成、声纹识别等),图像处理领域(图像识别、图像分类、图像生成、实例分割等)以及文本处理领域(文本分类、文本相似度检测等)。由于灵长类动物多生活在密林等环境中,使得图像采集设备难以部署,且监控设备易受密林遮挡,难以捕捉有效的影像信息。因而,从场景适用性及成本控制的角度考虑,将动物的叫声作为目标信号进行研究有很大优势。
3.目前国内外尚未有学者提出通过猕猴叫声对猕猴进行语音情绪识别的方案,现有的研究多集中在人类语音识别领域。而人类语音中包含的信息更加丰富,情绪种类多,如一段语音中包含的情绪可能有多种,有情绪的变化,因此在根据人类语音进行情绪识别时,通常需要设计复杂的预处理策略,以及更丰富的特征提取方法来从更多的维度提取人类语音中的情绪特征,才能设计出更有效人类语音情绪识别算法。而猕猴的叫声时长较短,并且一段猕猴叫声内的情绪较为一致(无情绪转折),因此现有人类语音识别的复杂特征提取方法在猕猴语音情绪识别过程通常发挥不出作用,无法进行有效的特征提取。
技术实现要素:
4.本发明的目的在于克服现有技术缺陷,提供了一种基于时
‑
频双分支特征的猕猴情绪识别方法及系统,能够实现基于猕猴叫声对猕猴的情绪进行识别。
5.为了实现上述目的,本发明提出了一种基于时
‑
频双分支特征的猕猴情绪识别方法,所述方法包括:
6.将采集的猕猴叫声输入预先建立和训练好的猕猴情绪识别模型,得到对应的精确情绪类别;所述精确情绪类别包括“友好”情绪、“进攻或威胁”情绪、“失落或顺从”情绪和无情绪;
7.所述猕猴情绪识别模型,用于提取猕猴叫声的中间特征,基于时
‑
频双分支对时域特征和频域特征进行分离提取,经融合分类确定对应的精确情绪类别。
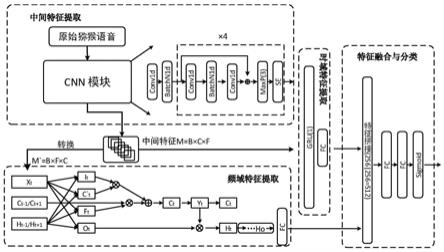
8.作为上述方法的一种改进,所述猕猴情绪识别模型包括中间特征提取模块、频域特征提取模块、时域特征提取模块和特征融合与分类模块;其中,
9.所述中间特征提取模块,用于对输入的猕猴叫声数据进行多层次递进的特征提取和压缩,得到猕猴叫声的中间层二维特征表示f
m
;
10.所述频域特征提取模块,用于将中间层二维特征表示f
m
变换为频域特征表示f
m
′
,
然后进行频域特征捕获处理,得到f
m
的低维频域压缩特征表示e
ff
;
11.所述时域特征提取模块,用于对中间层二维特征表示f
m
进行时域特征捕获处理,得到f
m
的低维时域压缩特征表示e
ft
;
12.所述特征融合与分类模块,用于根据低维频域压缩特征表示e
ff
与低维时域压缩特征表示e
ft
,获取融合特征的分类编码输出,得到猕猴叫声数据对应的预测情绪类别。
13.作为上述方法的一种改进,所述中间特征提取模块包括一个头层和4个堆叠的结构相同的加权残差卷积块;其中,
14.所述头层包括一个卷积核大小为1*255,步长为1,通道数为128的一维卷积层;
15.所述加权残差卷积块包括两个结构相同的一维卷积层、一个一维批归一化层、一个最大值池化层和一个通道注意力机制层,并且每个加权残差卷积块的输入跳跃连接至加权残差卷积块第二个卷积层的输出;其中,每个一维卷积层卷积核大小为1*3,步长为1,通道数为128;通道注意力机制层包括一个自适应池化层、一个全连接层和权重计算函数。
16.作为上述方法的一种改进,所述中间特征提取模块的具体处理过程包括:
17.头层的一维卷积层对输入叫声数据i进行维度转换,得到输入特征o1,满足下式:
18.o1=i
·
w1+b119.其中,w1为一维卷积层的权重参数,b1为一维卷积层的偏置;
20.将输入特征o1分别输入4个堆叠的加权残差卷积块,通过自适应池化将二维特征映射至通道维度的一维向量表示,然后通过一层全连接及sigmoid函数σ得到每个通道的权重表示,将通道的权重表示与输入通道注意力计算函数的二维特征x相乘,得到各残差卷积块通道加权后的特征表示,作为下一个残差卷积块的输入;经过4层加权残差卷积块后得到猕猴叫声的中间层二维特征表示f
m
;
21.其中,第i个加权残差块输出为o
ri
,i≤4,满足下式:
22.o
ri
=se(maxp(o1+(bn(o1·
w
ri0
+b
ri0
)
·
w
ri1
+b
ri1
))
23.其中,w
ri0
,b
ri0
分别表示第i个残差块中第一个卷积的卷积核及偏置参数,w
ri1
,b
ri1
分别表示第i个残差块中第二个卷积的卷积核及偏置参数,maxp(
·
)表示最大池化,bn(
·
)表示批归一化处理,se(x)为通道注意力计算函数,满足下式:
24.se(x)=σ(adap(o
r1
)
·
w
s1
+b
s1
)
·
x
25.其中,σ(
·
)表示激活函数,adap(
·
)表示自适应池化,w
s1
表示通道注意力的权重参数,b
s1
表示通道注意力的偏置,x表示中间变量。
26.作为上述方法的一种改进,所述频域特征提取模块包括依次连接的三层双向lstm和一个全连接层;具体处理过程为:
27.将中间层二维特征表示f
m
变换为频域特征表示f
m
′
,将f
m
′
中每一时刻的频域表示特征依次输入三层双向lstm;经lstm进行特征提取后得到隐藏特征表示h
t
,将所有时刻得到的隐藏特征进行融合,得到猕猴叫声的通道关联特征h
o
;
28.通过全连接层对h
o
进行映射,得到低维压缩频域特征表示e
ff
为:
29.e
ff
=w
fd
*h
o
+b
fd
30.式中,w
fd
和b
fd
分别表示全连接层的权重参数及偏置。
31.作为上述方法的一种改进,所述时域特征提取模块包括依次连接的一个单层的gru和一个全连接层;具体处理过程包括:
32.将f
m
转换为时域表示特征,并将每一通道的时域表示特征输入gru;对gru所有通道对应的输出进行特征融合,得到猕猴叫声的时间关联特征g
o
,并由全连接层进行特征降维,得到猕猴叫声的低维频域压缩特征表示e
ft
为:
33.e
ft
=w
ft
*g
o
+b
ft
34.式中,w
ft
和b
ft
分别表示全连接层权重参数及偏置。
35.作为上述方法的一种改进,所述特征融合与分类模块包括依次连接的一个融合层、第一全连接层、第二全连接层和一个分类函数;其中第二全连接层的维度为1;所述特征融合与分类模块具体处理过程包括:
36.对低维压缩频域特征表示e
ff
和低维时域压缩特征表示e
ft
进行特征融合,得到时
‑
频融合特征e
fc
=concat(e
ff
,e
ft
);
37.将时
‑
频融合特征e
fc
依次输入第一全连接层和第二全连接层,并对第二全连接层的输出经分类函数进行特征映射,根据映射结果预测出猕猴叫声对应的情绪类别。
38.作为上述方法的一种改进,所述方法还包括猕猴情绪识别模型的训练步骤,具体包括:
39.由原始猕猴叫声的声音数据集分别建立训练集和验证集;
40.将猕猴声音数据集与影像数据进行对应,分析猕猴的面部表情,对应每个声音数据确定情绪分类;
41.将训练集的数据依次输入猕猴情绪识别模型,利用二值交叉熵损失函数计算输出的预测标签与真实标签间的损失,并进行反向传播,采用梯度下降法对模型中的参数进行更新;反复迭代,直至训练出的模型在验证集上得到的准确率最高,得到最优参数组合,从而完成猕猴情绪识别模型的训练。
42.一种基于时
‑
频双分支特征的猕猴情绪识别系统,所述系统包括:猕猴情绪识别模型和猕猴情绪输出模块;其中,
43.所述猕猴情绪输出模块,用于将采集的猕猴声音输入预先建立和训练好的猕猴情绪识别模型,得到对应的精确情绪类别;所述精确情绪类别包括“友好”情绪、“进攻或威胁”情绪、“失落或顺从”情绪和无情绪;
44.所述猕猴情绪识别模型,用于提取猕猴声音的中间特征,基于时
‑
频双分支对时域特征和频域特征进行分离提取,经融合分类确定对应的精确情绪类别。
45.与现有技术相比,本发明的优势在于:
46.本发明通过使用原始叫声数据作为网络输入,能够从叫声中提取丰富的情绪相关中间特征,无需语音预处理,简化了算法流程,之后通过时域与频域两个分支,对时域和频域特征进行分离提取,从不同角度获取叫声的压缩特征,通过特征融合分类模块对时域和频域特征进行融合,增强了特征的表达力,有效地提升了识别准确率。
附图说明
47.图1为本发明实施例1的基于时
‑
频双分支特征的猕猴情绪识别网络整体结构示意图;
48.图2为本发明实施例1的中间特征提取模块结构示意图;
49.图3为本发明实施例1的频域特征提取模块结构示意图;
50.图4为本发明实施例1的时域特征提取模块结构示意图;
51.图5为本发明实施例1的特征融合与分类模块结构示意图。
具体实施方式
52.本发明的方法包括:
53.步骤1)数据预处理,将原始猕猴叫声的训练语料库按每组a段叫声分为m组;
54.步骤2)随机读取一组叫声,由具有n层结构的中间特征提取模块对输入猕猴叫声数据进行多层次递进的特征提取和压缩,得到猕猴叫声的中间层二维特征表示f
m
=a
×
c
×
d=[f1,f2,..,f
c
],f
i
∈r
d
,其中m表示时
‑
频特征时域通道数,d表示通道特征维度,c表示通道数量,fi表示第i个通道的特征,其维度为d;
[0055]
中间特征提取模块包括一个头层和4个堆叠的加权残差卷积块;
[0056]
头层包括一个一维卷积层,所述一维卷积核大小为1*255,步长为1,通道数为128;
[0057]
加权残差卷积块包括两个一维卷积层,一个一维批归一化层,一个最大值池化层及一个通道注意力机制层,并且每个所述加权残差卷积块的输入跳跃连接至所述加权残差卷积块第二个卷积层的输出;所述通道注意力机制层包括一个自适应池化层,一个全连接层及权重计算函数;其中,所述加权残差卷积块中每个一维卷积层卷积核大小为1*3,步长为1,通道数为128。
[0058]
步骤2)具体包括:
[0059]
步骤2
‑
1)利用一维卷积对输入叫声数据i进行维度转换,得到输入特征o1,计算公式如下:
[0060]
o1=i
·
w1+b1[0061]
步骤2
‑
2)将输入特征o1作为所述4个堆叠的加权残差卷积块的输入,依次经过各加权残差卷积块进行通道加权特征提取,经过4层加权残差卷积块后得到所述猕猴叫声的中间层二维特征表示f
m
;
[0062]
其中,每一层加权残差块输出为o
ri
,其计算过程如下:
[0063]
o
r1
=se(maxp(o1+(bn(o1·
w
r10
+b
r10
)
·
w
r11
+b
r11
))
[0064]
通道注意力机制层的计算公式如下:
[0065]
se(x)=σ(adap(o
r1
)
·
w
s1
+b
s1
)
·
x
[0066]
其中,o1表示头层输出,o
ri
表示第i层残差块输出。w
ri0
,b
ri0
分别表示第i个残差块中第一个卷积的卷积核及偏置参数,w
ri1
,b
ri1
分别表示第i个残差块中第二个卷积的卷积核及偏置参数,se(x)为通道注意力计算函数,se(x)通过自适应池化将二维特征映射至通道维度的一维向量表示,然后通过一层全连接及sigmoid函数σ得到每个通道的权重表示,将通道的权重表示与输入se的原二维特征相乘即得到各残差卷积块通道加权后的特征表示,作为下一残差卷积块的输入。
[0067]
步骤3)将步骤2)的输出f
m
变换为频域特征表示f
m
′
=a
×
d
×
c,将f
m
′
输入频域特征提取模块进行频域特征捕获处理,得到fm的低维频域压缩特征表示e
ff
;频域特征提取模块包括三层双向lstm和一个全连接层。
[0068]
具体包括:
[0069]
步骤3
‑
1)将f
m
变换为频域特征表示f
m
′
,将f
m
′
中每一时刻的频域表示特征f
i
依次
输入三层双向lstm;
[0070]
步骤3
‑
2)将步骤3
‑
1)中最后一层双向lstm所有时刻的输出进行特征融合,并由全连接层进行特征降维,得到所述猕猴叫声的低维频域压缩特征表示e
ff
;
[0071]
其中,频域表示特征每一时刻的输入特征x
t
经lstm进行特征提取后得到隐藏特征表示为h
t
,将所有时刻得到的隐藏特征进行融合,得到所述猕猴叫声的通道关联特征h
o
;h
t
的计算过程如下:
[0072]
c
t
=f
t
·
c
t
‑1+i
t
·
tanh(w
xc
*x
t
+w
hc
*h
t
‑1+b
c
)
[0073]
f
t
=σ(wx
f
*x
t
+w
hf
*ω
t
‑1+w
xf
·
c
t
‑1+b
f
)
[0074]
o
t
=σ(w
xo
*x
t
+w
ho
*ω
t
‑1+w
co
·
c
t
‑1+b
o
)
[0075]
i
t
=σ(w
xi
*x
t
+w
hi
*ω
t
‑1+w
ci
·
c
t
‑1+b
i
)
[0076]
h
t
=o
t
·
tanh(c
t
)
[0077]
其中,f
t
,o
t
,i
t
分别表示lstm中遗忘门、输出门和输入门的输出;c
t
及h
t
分别表示t时刻的细胞状态及隐藏特征,w
x*
,w
h*
表示对应门的卷积核参数,b
*
表示对应门的偏置参数,σ表示对应的激活函数,双向lstm的隐藏状态输出可表示为:
[0078]
h
ot
=g(vh
t
+v
′
h
t
′
)
[0079]
其中,h
ot
表示t时刻的隐藏特征,h
t
和h
t
′
分别表示正向和反向的输出特征;
[0080]
通过全连接层对进行h
o
进行映射,得到低维压缩频域特征表示e
ff
,即:
[0081]
e
ff
=w
fd
*h
o
+b
fd
[0082]
上式中,w
f
d和b
fd
分别表示全连接层的权重参数及偏置。
[0083]
步骤4)将步骤2)的输出f
m
输入时域特征提取模块进行时域特征捕获处理,得到f
m
的低维时域压缩特征表示e
ft
。时域特征提取模块包括一个单层的gru和一个全连接层。
[0084]
具体包括:
[0085]
步骤4
‑
1)将f
m
转换为时域表示特征,并将每一通道的时域表示特征输入gru;
[0086]
步骤4
‑
2)将gru所有通道对应的输出进行特征融合,得到猕猴叫声的时间关联特征g
o
,并由全连接层进行特征降维,得到所述猕猴叫声的低维频域压缩特征表示e
ft
;
[0087]
其中,gru进行隐状态g
t
的计算过程如下:
[0088]
z
t
=σ(w
z
·
[h
t
‑1,x
t
])
[0089]
r
t
=σ(w
r
·
[h
t
‑1,x
t
])
[0090]
h
t
=tanh(w
·
[r
t
*h
t
‑1,x
t
])
[0091]
g
t
=(1
‑
z
t
)*h
t
‑1+z
t
*h
t
[0092]
通过全连接层对g
o
进行映射得到低维时域压缩特征表示e
ft
,即:
[0093]
e
ft
=w
ft
*g
o
+b
ft
[0094]
上式中z
t
和r
t
分别表示更新门和重置门的输出特征;w
ft
和b
ft
分别表示全连接层权重参数及偏置。
[0095]
步骤5)将所述低维频域压缩特征表示e
ff
与低维时域压缩特征表示e
ft
通过特征融合与分类模块处理,获取融合特征的分类编码输出,得到所述猕猴叫声对应的预测情绪类别;特征融合与分类模块包括一个融合层、两个全连接层和一个分类函数;
[0096]
具体包括:
[0097]
步骤5
‑
1)将所述低维频域压缩特征表示e
ff
与所述低维时域压缩特征表示e
ft
输入
所述融合层进行特征融合,得到时
‑
频融合特征e
fc
=concat(e
ff
,e
ft
);
[0098]
步骤5
‑
2)将时
‑
频融合特征e
fc
特征依次输入两个全连接层,其中,第二个全连接层的输出维度为1;
[0099]
步骤5
‑
3)将第二个全连接层的输出输入分类函数进行特征映射,根据映射结果预测出所述猕猴叫声对应的情绪类别。
[0100]
步骤6)根据预测情绪类别与真实的情绪类别进行损失计算,并采用梯度下降法对模型中的参数进行更新;反复迭代,直至训练出最优参数组合;
[0101]
步骤7)基于最优参数模型,对待被测试的猕猴叫声进行情绪识别,其中,所述待被测试的猕猴不属于训练集所包含的猕猴。
[0102]
下面结合附图和实施例对本发明的技术方案进行详细的说明。
[0103]
实施例1
[0104]
本发明的实施例1提出了基于时
‑
频双分支特征的猕猴情绪识别方法。
[0105]
需要说明的是,为了便于描述,附图中仅示出了与本发明实施例相关的部分而非全部内容。一些示例性实施例被描述成作为流程示意图描绘的处理或方法,虽然流程示意图将各项操作(或步骤)描述成顺序的处理,但是其中的许多操作可以被并行地、并发地或者同时实施,各项操作的顺序可以被重新安排。当其操作完成时所述处理可以被终止,但是还可以具有未包括在附图中的附加步骤。
[0106]
本发明技术方案设计的难点如下:
[0107]
现有的研究多集中在人类语音识别领域,尚未有学者提出通过猕猴叫声对猕猴进行情绪识别的方案。而人类语音中包含的信息更加丰富,情绪种类多,如一段语音中包含的情绪可能有多种,有情绪的变化,因此在根据人类语音进行情绪识别时,通常需要设计复杂的预处理策略,以及更丰富的特征提取方法来从更多的维度提取人类语音中的情绪特征,才能设计出更有效人类语音情绪识别算法。而在本发明方案的设计过程中发现,猕猴的叫声时长较短,经统计,猕猴的一段叫声平均约为0.5秒,并且一段猕猴叫声内的情绪较为一致(无情绪转折),因此现有人类语音识别的复杂特征提取方法在猕猴语音情绪识别过程通常发挥不出作用,无法进行有效的特征提取,因此本发明设计了一种简单而有效的特征提取与训练策略,来学习猕猴叫声中含有的情绪特征,具有较高的猕猴情绪识别准确率,经实际实验获得的情绪识别准确率可达96.67%。
[0108]
图1为本发明实施例提供的基于时
‑
频双分支特征的猕猴情绪识别网络整体结构示意图,“cnn模块”表示中间特征提取模块。图1所示网络的数据处理过程包括如下步骤:
[0109]
步骤110,数据预处理,将原始猕猴叫声的训练语料库按每组a段叫声分为m组。
[0110]
步骤120,将待被检测的原始猕猴叫声输入中间特征提取模块,得到猕猴叫声的中间特征;其中,待被检测的猕猴不属于训练集所包含的猕猴随机读取一组叫声,由具有n层结构的中间特征提取模块对输入猕猴叫声数据进行多层次递进的特征提取和压缩,得到猕猴叫声的中间层二维特征表示f
m
=a
×
c
×
d=[f1,f2,..,f
c
],f
i
∈r
d
,其中m表示特征时域通道数,d表示通道特征维度,c表示通道数量,fi表示第i个通道的特征,其维度为d。
[0111]
步骤130,将f
m
变换为频域特征表示f
m
′
=a
×
d
×
c,将f
m
′
输入频域特征提取模块进行频域特征捕获处理,得到f
m
的低维频域压缩特征表示e
ff
。
[0112]
步骤140,将f
m
输入时域特征提取模块进行时域特征捕获处理,得到f
m
的低维时域
压缩特征表示e
ft
。
[0113]
步骤150,将所述低维频域压缩特征表示e
ff
与低维时域压缩特征表示e
ft
通过特征融合与分类模块处理,获取融合特征的分类编码输出,得到所述猕猴叫声对应的预测情绪类别。
[0114]
步骤160,根据预测情绪类别与真实的情绪类别进行损失计算,并采用梯度下降法对模型中的参数进行更新;反复迭代,直至训练出最优参数组合。
[0115]
步骤170,基于最优参数模型,对待被测试的猕猴叫声进行情绪识别,其中,所述待被测试的猕猴不属于训练集所包含的猕猴。
[0116]
现有的神经网络在进行训练和测试时,多采用封闭数据集的形式,即训练集和测试集是对相同来源的数据进行比例划分,这样训练出来的模型泛化能力较差,而本发明采用开放数据集的形式,测试集和训练集数据分别来自不同的猕猴,即待被检测的猕猴不属于训练集所包含的猕猴。假设一共有m只猕猴的叫声,则本发明选择m1只猕猴的声音数据作为训练集,剩余的m
‑
m1只猕猴的声音数据作为待被测试的猕猴叫声,使得训练和测试所采用的猕猴叫声来自于不同的猕猴,这样训练出的网络,对任意的猕猴声音都能进行较好的情绪识别,泛化能力更好,实用性更强。
[0117]
本发明实施例提供的端到端时
‑
频特征融合的猕猴叫声情绪识别方法,通过使用原始叫声数据作为网络输入,能够从叫声中提取丰富的情绪相关中间特征,无需语音预处理,简化了算法流程,之后通过时域与频域两个分支,对时域特征和频域特征进行分离提取,从不同角度获取叫声的压缩特征,通过特征融合分类模块对时域和频域特征进行融合,增强了特征的表达力,有效提升了情绪识别的准确率。
[0118]
另外,在步骤150得到预测标签之后还包括:利用二值交叉熵损失函数计算网络输出的预测标签与真实标签间的损失,并进行反向传播,采用梯度下降法对模型中的参数进行更新;反复迭代,直至训练出的网络在验证集上得到的准确率最高,得到网络的最优参数组合;之后采用具有最优网络参数组合的猕猴情绪识别网络对待被检测的猕猴原始叫声进行情绪识别。
[0119]
可选的,根据猕猴表情与情绪的对应关系,确定出猕猴叫声中含有的至少2种情绪类别,包括:将猕猴声音数据集与影像数据进行对应,分析猕猴的面部表情;将嘴半张,嘴唇微微突出的猕猴表情所对应的声音确定为“友好”情绪;将眉毛扬起,聚精会神地盯着,嘴巴张开,露出牙齿,或者,眉毛扬起,聚精会神地注视,嘴唇突出,形成一个圆形这两种猕猴表情对应的声音确定为“进攻或威胁”情绪。
[0120]
猕猴的情绪并没有人类情绪的明确定义,而实现猕猴叫声情绪识别,首先需要对猕猴叫声中的情绪进行分类,因此本发明结合猕猴的影像与声音信息,对猕猴的情绪进行了分析统计,将猕猴典型的6种表情对应的情绪分为4类,分别为:友好情绪,进攻或威胁情绪,失落或顺从情绪,面部特征为:动物的嘴张得很大,正在打呵欠。在灵长类动物中,打哈欠可能与痛苦和焦虑有关;无情绪,面部特征为:嘴巴紧闭,整个面部放松。其中,“友好”和“进攻或威胁”情绪的面部特征已在上文描述,此处未再赘述。
[0121]
图2为本发明实施例提供的中间特征提取模块结构示意图,如图2所示,中间特征提取模块包括一个头层和4个堆叠的加权残差卷积块;
[0122]
其中,头层包括一个一维卷积层(conv1d)和一个一维批归一化层(batchn1d);本
实施例中设定头层的输入通道数为1,输出通道数为128,卷积核大小为1*255,步长为1,即每一个1*255大小的卷积核通过与原始叫声数据进行卷积生成该层输出的一个通道。
[0123]
加权残差卷积块包括两个一维卷积层,一个一维批归一化层,一个最大值池化层(maxp)及一个通道注意力机制层(se),并且将每个加权残差卷积块的输入跳跃连接至加权残差卷积块第二个卷积层的输出;通道注意力机制层包括一个自适应池化层,一个全连接层(fc)及权重计算函数。需要说明的是,加权残差卷积块的数量并不限于4个,可以通过增加加权残差卷积块的数量来增加网络深度。
[0124]
具体的,所述步骤120具体包括:
[0125]
步骤121,利用一维卷积对输入叫声数据i进行维度转换,得到输入特征o1,计算公式如下:
[0126]
o1=i
·
w1+b1[0127]
步骤122,将输入特征o1作为所述4个堆叠的加权残差卷积块的输入,依次经过各加权残差卷积块进行通道加权特征提取,经过4层加权残差卷积块后得到猕猴叫声的中间层二维特征表示f
m
;
[0128]
其中,每一层加权残差块输出为o
ri
,其计算过程如下:
[0129]
o
r1
=se(maxp(o1+(bn(o1·
w
r10
+b
r10
)
·
w
r11
+b
r11
))
[0130]
通道注意力机制层的计算公式如下:
[0131]
se(x)=σ(adap(o
r1
)
·
w
s1
+b
s1
)
·
x
[0132]
其中,o1表示头层输出,o
ri
表示第i层残差块输出。w
ri0
,b
ri0
分别表示第i个残差块中第一个卷积的卷积核及偏置参数,w
ri1
,b
ri1
分别表示第i个残差块中第二个卷积的卷积核及偏置参数,se(x)为通道注意力计算函数,se(x)通过自适应池化将二维特征映射至通道维度的一维向量表示,然后通过一层全连接及sigmoid函数σ得到每个通道的权重表示,将通道的权重表示与输入se的原二维特征相乘即得到各残差卷积块通道加权后的特征表示,作为下一残差卷积块的输入。
[0133]
其中,通道注意力机制层的权重计算函数可以是sigmoid函数。通过通道注意力机制中的自适应池化层可将二维特征映射至通道维度的一维向量表示,然后通过一层全连接及sigmoid函数得到每个通道的权重表示,对更能够表达猕猴情绪的特征通道赋予更大的权重,将通道的权重与原二维特征相乘,得到通道加权后的特征表示。通过中间特征提取模块对原始猕猴叫声进行特征提取,能够得到更加丰富的特征信息,对猕猴情绪的表示能力也更强。
[0134]
最终得到的中间特征可以表示为f
m
=a
×
c
×
d,经过残差卷积提取的丰富特征图可理解为每段叫声的时频二维特征表示,每段叫声的二维特征大小为c
×
d。例如,本发明实施例可设置c=256,当输入的叫声数据长度为5120时,中间特征的d=19。为从不同的角度得到猕猴叫声的压缩特征,本发明实施例提出了时域和频域特征分离提取的形式。
[0135]
图3为本发明实施例提供的频域特征提取模块结构示意图,如图3所示,频域特征提取模块包括三层双向lstm(bilstm)和一个全连接层;将中间特征转换为频域表示特征,并将每一时刻的频域表示特征依次输入三层双向lstm中;将最后一层双向lstm所有时刻的输出进行特征融合,并由全连接层进行特征降维,得到猕猴叫声的频域特征。本发明实施例中可设置压缩后的频域特征为1*256维的特征向量。需要说明的是,本发明实施例中的三层
双向lstm为示例性的技术方案,并不对双向lstm的层数进行限制。
[0136]
所述步骤130具体包括:
[0137]
步骤131,将f
m
变换为频域特征表示f
m
′
,将f
m
′
中每一时刻的频域表示特征f
i
依次输入三层双向lstm。
[0138]
步骤132,将步骤131中最后一层双向lstm所有时刻的输出进行特征融合,并由全连接层进行特征降维,得到所述猕猴叫声的低维频域压缩特征表示e
ff
;
[0139]
其中,频域表示特征每一时刻的输入特征x
t
经lstm进行特征提取后得到隐藏特征表示为h
t
,将所有时刻得到的隐藏特征进行融合,得到所述猕猴叫声的通道关联特征h
o
;h
t
的计算过程如下:
[0140]
c
t
=f
t
·
c
t
‑1+i
t
·
tanh(w
xc
*x
t
+w
hc
*h
t
‑1+b
c
)
[0141]
f
t
=σ(w
xf
*x
t
+w
hf
*ω
t
‑1+w
xf
·
c
t
‑1+b
f
)
[0142]
o
t
=σ(w
xo
*x
t
+w
ho
*ω
t
‑1+w
co
·
c
t
‑1+b
o
)
[0143]
i
t
=σ(w
xi
*x
t
+w
hi
*ω
t
‑1+w
ci
·
c
t
‑1+b
i
)
[0144]
h
t
=o
t
·
tanh(c
t
)
[0145]
其中,f
t
,o
t
,i
t
分别表示lstm中遗忘门、输出门和输入门的输出;c
t
及h
t
分别表示t时刻的细胞状态及隐藏特征,w
x*
,w
h*
表示对应门的卷积核参数,b
*
表示对应门的偏置参数,双向lstm的隐藏状态输出可表示为:
[0146]
h
ot
=g(vh
t
+v
′
h
t
′
)
[0147]
其中,h
ot
表示t时刻的隐藏特征,h
t
和h
t
′
分别表示正向和反向的输出特征;
[0148]
通过全连接层对进行h
o
进行映射,得到低维压缩频域特征表示e
ff
,即:
[0149]
e
ff
=w
fd
*h
o
+b
fd
[0150]
上式中,w
fd
和b
fd
分别表示全连接层的权重参数及偏置
[0151]
具体的,将中间特征f
m
进行转置,得到频域表示特征为f
m
′
=b*f*c,将频域表示特征依次输入至三层双向的lstm中,通过lstm对频域维度建立通道关联,将lstm计算出的所有时刻的隐藏特征融合为h
o
作为该段叫声的lstm输出特征,并经过一层全连接对h
o
的特征维度进行降维,将中间特征映射为频域的压缩特征。
[0152]
图4为本发明实施例提供的时域特征提取模块结构示意图,如图4所示,时域特征提取模块包括一个单层的gru和一个全连接层;
[0153]
所述步骤140具体包括:
[0154]
步骤141,将f
m
转换为时域表示特征,并将每一通道的时域表示特征输入gru;
[0155]
步骤142,将gru所有通道对应的输出进行特征融合,得到猕猴叫声的时间关联特征g
o
,并由全连接层进行特征降维,得到所述猕猴叫声的低维频域压缩特征表示e
ft
。
[0156]
其中,若中间特征的表示不满足f
m
=b*c*d,则对中间特征进行转换。使用单层gru结合全连接层,将中间特征映射并压缩为时域关联特征。本发明实施例中可设置压缩后的时域特征为1*256维的特征向量。
[0157]
其中,gru进行隐状态g
t
的计算过程如下:
[0158]
z
t
=σ(w
z
·
[h
t
‑1,x
t
])
[0159]
r
t
=σ(w
r
·
[h
t
‑1,x
t
])
[0160]
h
t
`=tanh(w
·
[r
t
*h
t
‑1,x
t
])
[0161]
g
t
=(1
‑
z
t
)*h
t
‑1+z
t
*h
t
[0162]
通过全连接层对g
o
进行映射得到低维时域压缩特征表示e
ft
,即:
[0163]
e
ft
=w
ft
*h
o
+b
ft
[0164]
上式中z
t
和r
t
分别表示更新门和重置门的输出特征;w
ft
和b
td
分别表示全连接层权重参数及偏置。
[0165]
图5为本发明实施例提供的特征融合与分类模块结构示意图。如图5所示,特征融合与分类模块包括一个融合层、两个全连接层和一个分类函数;
[0166]
所述步骤150具体包括:
[0167]
步骤151,将所述低维频域压缩特征表示e
ff
与所述低维时域压缩特征表示e
ft
输入所述融合层进行特征融合,得到时
‑
频融合特征e
fc
=concat(e
ff
,e
ft
)。
[0168]
步骤152,将时
‑
频融合特征e
fc
特征依次输入两个全连接层,其中,第二个全连接层的输出维度为1。
[0169]
步骤153,将第二个全连接层的输出输入分类函数进行特征映射,根据映射结果预测出所述猕猴叫声对应的情绪类别。
[0170]
其中,特征融合与分类模块中所采用的分类函数为sigmoid函数。将频域特征与时域特征分别得到大小为1*256维的特征向量(分别表示为e
ft
和e
ff
)进行特征融合(如拼接),得到一个1*512维的特征向量。第一个全连接层的输入和输出的特征维度分别为512和256,第二个全连接层输入和输出维度分别为256和1,将第二个全连接层输出的1维特征进一步由分类函数进行计算,得到预测的概率输出。根据预测概率与预设阈值的比较结果,即可识别出输入的原始猕猴叫声所表达的情绪。
[0171]
该方法基于猕猴叫声实现猕猴情绪识别,主要处理流程包括:首先对输入的原始猕猴声音进行多层次递进的特征提取和压缩,得到与情绪相关的中间层二维特征;之后将中间层二维特征转换为时域特征表示,进行时间关联特征提取,捕获猕猴叫声采样数据的时域压缩特征表示;同时将中间层二维特征转换为频域特征表示,进行通道关联特征提取,捕获猕猴叫声采样数据的频域压缩特征表示;最后,将频域压缩特征与时域压缩特征通过特征融合策略聚合为双分支语义信息,并通过多层全连接映射得到输入猕猴声音对应的精确情绪类别,有效提升了基于猕猴叫声的情绪识别准确率。
[0172]
为比较发明所提算法有效性,将其与近年来的两种效果较为优秀的人类语音情绪识别算法进行比较,其分别为基于双分支cnn结构的capr和基于cnn结构的rsse。实验所采用数据集均为猕猴叫声情绪数据集。最终实验结果如表所示,可见,本发明所提供的猕猴情绪识别算法显著提高了情绪识别的准确率。
[0173][0174]
实施例2
[0175]
本发明的实施例2提供了一种基于时
‑
频双分支特征的猕猴情绪识别系统,根据上
述实施例所提供的任一方法所构建的情绪识别网络模型实现,该系统包括:系统包括:猕猴情绪识别模型和猕猴情绪输出模块;其中,
[0176]
猕猴情绪输出模块,用于将采集的猕猴声音输入预先建立和训练好的猕猴情绪识别模型,得到对应的精确情绪类别;所述精确情绪类别包括“友好”情绪、“进攻或威胁”情绪、“失落或顺从”情绪和无情绪;
[0177]
猕猴情绪识别模型,用于提取猕猴声音的中间特征,基于时
‑
频双分支对时域特征和频域特征进行分离提取,经融合分类确定对应的精确情绪类别。
[0178]
其中,猕猴情绪识别模型包括中间特征提取模块、频域特征提取模块、时域特征提取模块和特征融合与分类模块;其中,
[0179]
中间特征提取模块,用于对输入猕猴叫声数据进行多层次递进的特征提取和压缩,得到猕猴叫声的中间层二维特征表示f
m
=a
×
c
×
d=[f1,f2,..,f
c
],f
i
∈r
d
,中m表示时
‑
频特征时域通道数,d表示通道特征维度,c表示通道数量,fi表示第i个通道的特征,其维度为d;
[0180]
频域特征提取模块,用于f
m
输入频域特征提取模块进行频域特征捕获处理,得到f
m
的低维频域压缩特征表示e
ff
;
[0181]
时域特征提取模块,用于将f
m
变换为时域特征表示f
m
′
=a
×
d
×
c,对f
m
′
进行时域特征捕获处理,得到低维时域压缩特征表示e
ft
;
[0182]
特征融合与分类模块,用于对低维频域压缩特征表示e
ff
与低维时域压缩特征表示e
ft
进行特征融合,并计算出融合特征的分类编码输出,得到所述猕猴叫声对应的情绪类别。
[0183]
在对猕猴情绪识别模型进行训练时包括数据预处理模块,用于猕猴叫声数据的预处理,并将猕猴叫声的训练语料库按每组a段叫声分为m组。
[0184]
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。