1.本发明属于语音信号处理技术领域,具体涉及到一种基于动态卷积网络及脉冲神经网络的语音情感识别模型。
背景技术:
2.语言是人类最基本、最常见、最有效的交际方式之一,人们可以从语言中感知情感的微妙变化。语音情感识别是指通过计算机对输入语音的情感状态进行自动识别,作为智能人机语音交互的关键技术,语音情感识别技术受到了众多研究者的关注。在过去几十年中,语音情感识别的相关研究取得了巨大的进展,并在许多不同的领域都有着广阔的前景。语音情感识别开始更多地应用到教育、娱乐、通讯等行业当中。加强对语音情感、情绪的识别成为了下一代人机交互、人工智能发展的重点。因此,开展针对语音情感识别的研究具有重要的理论价值和现实意义。
3.情感特征提取是语音情感识别的关键步骤。特征表征能力好坏直接决定了情感识别的有效性,如何从原始语音信号中提取出有判别力的情感特征是语音情感识别的热门研究课题之一。传统的语音情感特征包括韵律特征、谱图特征和语音质量特征。随着研究者的不断研究,越来越多的相关特征被提出。虽然这些人工设计的特征促进了语音情感识别的发展,但由于内容和不同说话人的变化等复杂因素,如何提高识别效果仍然是一个挑战。
4.近年来深度学习的兴起,神经网络在特征提取方面展现出了卓越的性能。与手工设计的特征相比,神经网络通过多轮迭代、自动提炼的方式所提取的深层特征具有更多的内在信息于更强的表征能力。相关研究人员已经开始使用神经网络和深度学习方法来解决语音情感识别问题,通过设计和开发特定的神经网络模型,提高了语音情感识别的研究水平,并且一些网络模型已经成功地应用于语音情感识别中。相关神经网络的成功应用,促使研究人员利用相关网络对语音信号进行深层研究,但仍存在一些重要的问题有待解决。
5.首先,因语言的固有特性,每条语音的持续时间不同,但现有大多数深度学习模型需要固定尺寸的输入,故需要在不损失情感信息的前提下设计一种满足模型要求的固定尺寸的输入特征。其次,用于语音情感识别的相关模型大多是采用串联式的方式来连接不同的神经网络模型,模型间的单线呈递关系可能会造成情感信息的丢失。
6.针对这些问题,本文提出了一种用于语音情感识别的dy
‑
cnn+snn模型。使用谱图特征和统计特征两种不同功能的特征作为模型的输入,不同于传统模型之间的呈递关系,dy
‑
cnn+snn模型采用并行的连接方式,以获得更好更丰富的情感细节。dy
‑
cnn模块可以捕获谱特征中的时频相关特性。同时,作为第三代人工神经网络,snn所展现出来前所未有的能源效率而受到广泛关注,本发明采用统计特征作为snn输入可以更好的弥补因压缩谱图大小而在dy
‑
cnn模块中丢失的情感细节。使用加权融合的方式分别对两个模块的输出连接一个可训练的权重层后融合,最后,使用softmax分类器对不同情感进行分类。
技术实现要素:
7.在语音情感识别中,特征提取是及其重要和关键的一步,提取特征的有效性直接关系到了后端识别的效果。本发明公布了一种基于动态卷积神经网络及脉冲神经网络的语音情感识别模型,其特征在于,包括以下步骤:
8.(1)语音信号预处理:将情感语料库中的语音数据按对应的情感类别标记标签,之后对每条语音进行分帧及加窗操作;
9.(2)语音特征提取:对步骤(1)预处理后的语音数据,提取出梅尔倒谱系数(mfcc)、过零率、基频等统计特征和log
‑
mel谱图特征;
10.(3)网络模型建构:该网络由一个动态卷积网络、一个脉冲神经网络以及融合层和分类层组成,该过程的具体实现步骤如下:
11.a.首先,将(2)中提取的mel谱图特征作为动态卷积神经网络的输入;同时,将(2)提取的统计特征作为脉冲神经网络的输入;
12.b.将步骤(3)a中并行网络输出的两类高级特征进行拼接,并使用了加权的融合方式对两模块的输出进行融合;最后将融合后的特征送入softmax分类器中进行分类;
13.设每条语音的语谱图为n
i
,动态卷积网络中融入了基于区间动态卷积的混合注意力机制,cat表示水平拼接操作,mixed
‑
atten(k,q,k
s
,v;n
f
)表示动态卷积网的输出;n
i
在动态卷积网络中特征提取的过程可以用如下公式表示:
14.n∈r
d
×
k
ꢀꢀꢀ
(1)
[0015][0016]
sdconv(q,k
s
,v;n
f
,i)=lconv(v,softmax(n
f
(q
⊙
k
s
)),i)
ꢀꢀꢀ
(3)
[0017]
mixed
‑
atten(k,q,k
s
,v;n
f
)=cat(self
‑
attn(q,k,v),sdconv(q,k
s
,v;n
f
))
ꢀꢀꢀ
(4)
[0018]
设每条语音提取的384维统计特征为x
i
,snn通过脉冲序列传递信息,此机制将连续值特征向量编码成脉冲序列,并对输出神经元的输出结果进行解码;本编码方案首先将输入特征通过一层加权的线性校正单元神经元如公式(6)所示,其中是输入与神经元j之间突触连接的强度,是神经元j的相应偏置项,ρ()便是激活函数;本方案还定义了自由聚集膜电位等于relu神经元的激活值并将这个量分布在编码时间窗ns上,并按照公式(7)和(8)用脉冲列表示;神经编码层输出的脉冲序列s0和脉冲计数c0可以表示为公式(9)和(10);
[0019]
脉冲神经元输入输出原理如下公式表示:
[0020][0021][0022][0023][0024]
s0={θ0(1),
…
,θ0(n
s
)}
ꢀꢀꢀ
(9)
[0025][0026]
snn层的非线性变换可以表示为公式(11):
[0027][0028]
其中f(
·
)表示由脉冲神经元执行的转换,在给定单一放电阈值β的情况下,本发明提出简化版的脉冲计数公式(13)来近似由于脉冲的不可微分性,故采用结构完全相同的ann与snn的一个并行结构,将ann的参数与snn共享,测试阶段则有snn独立完成;
[0029][0030][0031]
(4)特征融合:将两个自并行网络的输出特征进行拼接并加权融合;
[0032]
(5)分类识别输出:将融合后的特征输入到全连接层,经非线性变换输入分类器,然后分类器进行分类识别,计算该有监督过程的损失计算选择交叉熵损失函数;实现过程如下:
[0033][0034]
附图说明
[0035]
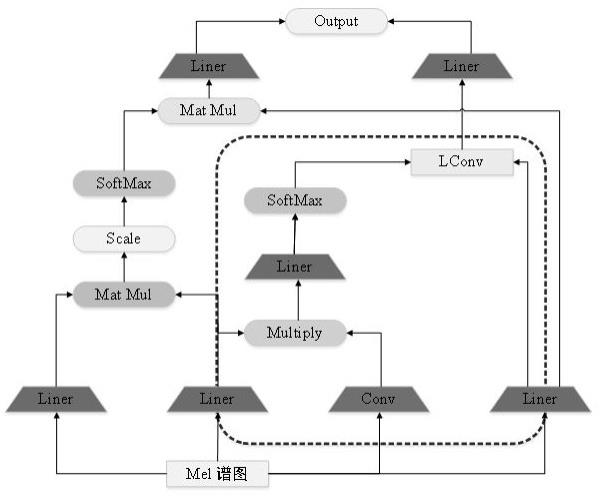
如附图所示,图1为基于区间动态卷积的混合注意力网络,方框部分为动态卷积模块。
[0036]
图2为脉冲神经网络模块。
[0037]
图3为混合神经网络整体框架。
具体实施方式
[0038]
下面结合具体实施方式对本发明做更进一步的说明。
[0039]
本发明提出的是一种基于动态卷积网络及脉冲神经网络的语音情感识别模型,为实现兼具较高识别准确率与较低能源消耗的语音情感识别提出了可行性的解决方法,为在能源有限的移动端部署提供了可能,具体实现步骤如下:
[0040]
(1)语音信号预处理与低级特征提取:提取语音中384维的情感统计特征,它们包括均方根信号能量、梅尔倒谱系数等共16个低级描述子,利用12个统计函数和回归系数函数提取16低级描述子及其一阶倒数的统计特性共384项指标作为脉冲神经网络模块输入。同时获取语音谱图特征,并求其一阶导于二阶导组成三维谱图特征作为动态卷积模块的输入。
[0041]
(2)将步骤(1)得到的谱图特征与统计特征同时输入到动态卷积神经网络与脉冲神经网络中提取更高级的特征f1与f2,其中
[0042]
f1=mixed
‑
atten(k,q,k
s
,v;n
f
)
ꢀꢀꢀ
(1)
[0043]
mixed
‑
atten(k,q,k
s
,v;n
f
)=cat(self
‑
attn(q,k,v),sdconv(q,k
s
,v;n
f
))
ꢀꢀꢀ
(2)
[0044][0045][0046]
公式(1)和(2)为基于区间动态卷积的混合注意力算子公式,能有效提取语谱图中的动态情感特征。公式(3)和(4)为脉冲神经网络特征提取算法,可相较于传统网络更低的能源功耗前提下有效提取语音中的全局特征。由于语音数据库大多数据量较少,不适宜过深的网络模型,在动态卷积模块中,本发明将图1的结构串行堆叠4层。
[0047]
(3)将步骤(2)得到的特征f1与f2通过concat操作将两种高级特征拼接,得到更具表征能力的深层特征,并通过全连接线性层将两类特征进行融合。接着批处理归一化处理后进行传递,然后使用softmax分类器对情绪进行分类,计算交叉熵损失函数,求出分类loss,实现过程如下:
[0048][0049][0050]
本发明网络模型是基于有监督学习的语音情感识别,网络训练过程中,训练集使用真实的标签,并将其类别标签为独热编码向量形式,与最后经softmax输出的概率计算做交叉熵损失。为避免梯度消失,加速梯度下降算法速度,模型中隐层神经网络中均采用rule激活函数。