1.本发明涉及一种对话分析系统(conversation analysis system)。
背景技术:
2.在日本发明专利公开公报特开2017-167368号中记载了一种语音识别错误修正装置。该装置为了修正第1文本(text 1)中包含的修改目标字符串(change object string)而识别所述第2讲话语音并根据第1文本和第2文本(text 2)的文本匹配(text matching)来推定修改目标字符串。现有技术中的修正装置使用一般的修正引擎来修正语音识别的错误,无论对话的领域和概要如何。因此,现有技术中的修正装置的修正精度不高。[现有技术文献][专利文献]
[0003]
专利文献1:日本发明专利公开公报特开2017-167368号
技术实现要素:
[发明所要解决的技术问题]
[0004]
本说明书中记载的一发明的目的在于,提供一种能够通过比现有技术更简单的作业来修正语音识别的错误的系统。[用于解决技术问题的技术方案]
[0005]
本说明书中记载的一发明基于如下见解:如果把握对话的领域和概要,则能够把握语音中容易错误识别的用语,因此能够更准确且迅速地对语音识别的错误进行修正。
[0006]
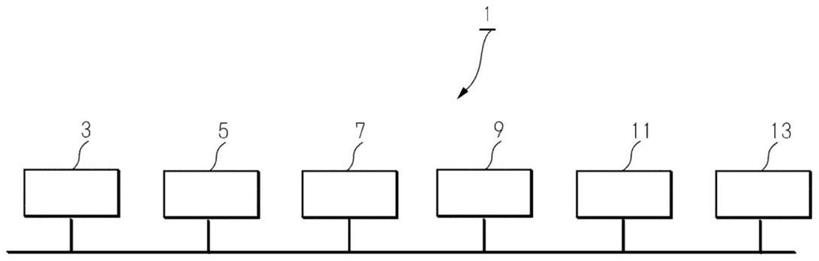
本说明书中记载的一发明涉及一种对话分析系统1。该对话分析系统1包含语音分析部3、话题(topics)相关修正用语存储部7、话题把握部(topics grasping unit)5和对话修正部9。语音分析部3是用于分析对话中所包含的内容的结构要素。话题把握部5是用于把握对话的话题的结构要素。话题相关修正用语存储部7是用于按照每个话题来存储待进行语音识别的发音或语音识别出的用语、以及与待进行语音识别的发音或语音识别出的用语相关的候选修正用语的结构要素。对话修正部9是用于对语音分析部3分析过的对话进行修正的结构要素。并且,对话修正部9使用话题把握部5把握到的对话的话题,从话题相关修正用语存储部7读取候选修正用语,来对语音分析部3分析过的对话进行修正。
[0007]
对话分析系统的优选例还具有话题相关用语更新部13,该话题相关用语更新部13用于更新话题相关修正用语存储部7。并且,话题相关用语更新部13使用输入到系统的与各话题有关的信息来更新候选修正用语。
[0008]
对话分析系统的优选例还具有用于提取与话题有关的信息的话题信息提取部11。并且,话题信息提取部11通过使用由语音分析部3对输入到系统1的演示(presentation)进
行分析而得到的语音信息以及被输入到系统的演示资料,来提取输入到系统的与各话题有关的信息。
[0009]
本说明书中所记载的一发明涉及一种对话分析系统用程序。该程序是使计算机作为语音分析机构、话题相关用语存储机构、话题把握机构和对话修正机构发挥作用的程序。并且,各种机构与上述各部对应。[发明效果]
[0010]
根据本说明书中记载的一发明,能够提供一种系统,该系统能够通过比现有技术更简单的作业来修正语音识别的错误。
附图说明
[0011]
图1是概略表示对话分析系统的框图。图2是表示计算机的基本结构的框图。图3是表示本发明的系统一例的概念图。图4是表示本发明的处理一例的流程图。
具体实施方式
[0012]
下面,参照附图对用于实施本发明的方式进行说明。本发明并不限于以下说明的方式,还包括本领域技术人员在显而易见的范围内对下述方式进行的适当变更。
[0013]
图1是关于对话分析系统的框图。如图1所示,对话分析系统1包括语音分析部3、话题把握部5、话题相关修正用语存储部7和对话修正部9。如图1所示,该系统1还可以具有话题信息提取部11和话题相关用语更新部13中的任一方或双方。该系统1也可以适当包含上述以外的结构要素。
[0014]
图2是表示计算机的基本结构的框图。如该图所示,计算机具有输入部31、输出部33、控制部35、运算部37以及存储部39,各结构要素通过总线41等连接,从而能够进行信息的收发。例如,在存储部中可以存储控制程序,也可以存储各种信息。在从输入部输入了规定的信息的情况下,控制部读取被存储于存储部中的控制程序。并且,控制部适当地读取被存储于存储部中的信息并将其传送给运算部。另外,控制部将输入的信息适当地传送给运算部。运算部使用接收到的各种信息进行运算处理,并将运算结果存储于存储部。控制部读取被存储于存储部中的运算结果并将该运算结果从输出部输出。这样,执行各种处理。以下说明的各结构要素也可以对应于计算机中的任一结构要素。
[0015]
图3是表示本发明的系统一例的概念图。如图3所示,本发明的系统(包含本发明的装置的系统)可以包含:移动终端45,其与互联网或内部网43连接;和服务器47,其与互联网或内部网43连接。当然,单个计算机或移动终端可以作为本发明的装置发挥功能,也可以存在多个服务器。
[0016]
语音分析部3是用于分析对话中所包含的内容的结构要素。语音分析部3是用于分析对话内容的结构要素。
[0017]
图4是表示本发明的处理一例的流程图。当进行对话时,由系统的语音识别部进行语音识别(语音识别工序:s101)。对话从系统1的麦克风等输入部31输入到系统1内。所输入的对话被适当地存储于
系统1的存储部39中。也可以将对话转换成数字信息而存储于存储部39中。语音分析部3是用于读取被存储于存储部39中的对话并分析对话中所包含的单词和对话语句的结构要素。这样的语音分析部(语音分析系统)是公知的。
[0018]
例如,在医生和患者之间进行某段对话,将该段对话转换成数字信息并存储于存储部中,语音分析部3从存储部读取对话信息,并进行如下分析。首先,从系统的输入部31即麦克风输入基于以下对话的语音信息,并通过语音识别而如下这样存储于存储部39中。
[0019]“gen ju jian cha jie guo ke yi shuo nin de bing ming shi xian wei ji tong zong he zheng de ke neng xing jiao gao xian wei ji tong zong he zheng shi yi zhong ban you quan shen duo ge bu wei ya tong huo teng tong de ji bing gei nin kai le yong yu huan jie xian wei ji tong zong he zheng yin qi de ya tong de nei fu yao lilika qing yi tian liang ci zai zao can hou he wan can hou fu yong”[0020]
接着,对语音识别出的对话进行语音分析(语音分析工序:s102)。例如,由语音分析部3如下这样对基于上述对话的语音信息进行分析,并将其作为语音分析后的对话存储于存储部39中。
[0021]
医生:“根据检查结果,可以说您的病名是纤维机通钲的可能性较高。纤维机通钲是一种伴有全身多个部位压痛或滕通的疾病。给您开了用于缓解纤维机通钲引起的压痛的内服药李理科,请1天2次在早餐后和晚餐后浮用。”[0022]
接着,把握与对话有关的话题(话题把握工序:s103).在该工序中,话题把握部5把握对话的话题。此时,可以预先在医生具有的系统1中输入对话内容为医疗用途的话题,例如,如果医生是精神科医生则预先输入与精神科有关的话题。在该情况下,可以为,与所输入的话题有关的信息被预先存储于系统1的存储部39中,当医生与患者的对话开始时,从存储部读取与话题有关的信息。另外,也可以由例如接待员、护士或医生根据患者的诊断文件等,将压痛、纤维肌痛症等与患者有关的话题输入到该系统1中。另外,系统1也可以具有后述的话题信息提取部11,能够自动地从对话内容中提取对话的话题。另外,也可以为,能够使用存储于话题相关修正用语存储部7中的候选修正用语或与候选修正用语对应的用语,自动地从对话内容中提取对话的话题。在该情况下,即使在仅通过语音分析不能分析出表示正确的话题的用语时,也能够通过使用候选修正用语的修正之前的用语来推测话题,从而提取(或确定)正确的话题。即,在待进行语音识别的发音或语音识别出的用语是修正用语的修正之前的用语的情况下,能够通过推测候选修正用语来正确地提取话题。
[0023]
另外,也可以为,系统1在存储部具有话题辞典,话题把握部5读取被存储于话题辞典中的话题词,并进行话题词与通过麦克风等输入的对话或由语音分析部3分析过的对话中所包含的用语是否一致的匹配,从而根据对话来把握话题。
[0024]
接着,从存储部中读取与话题相关的候选修正用语(修正用语读取工序:s104).例如,医疗机构的接待员向医疗机构内的系统1输入纤维肌痛症。于是,位于医生附近的终端1从存储部读取纤维肌痛症作为话题。话题相关修正用语存储部7按照每个话题存储有待进行语音识别的发音或语音识别出的用语、和与待进行语音识别的发音或语音识别出的用语相关的候选修正用语。
在该例子中,针对“xian wei ji tong zong he zheng”或“纤维机通钲”,存储有“纤维肌痛症”作为候选修正用语。针对“teng tong”或“滕通”,存储有“疼痛”作为候选修正用语。针对“lilika”或“李理科”,存储有“lyrica”(一种药物,日语名为
リリカ
:注册商标)作为候选修正用语。这样,按照每个话题,从存储部读取待进行语音识别的发音或语音识别出的用语、和与待进行语音识别的发音或语音识别出的用语相关的候选修正用语。
[0025]
接着,对话修正部9使用话题把握部5把握到的对话的话题来从话题相关修正用语存储部7中读取候选修正用语,并且对话修正部9对语音分析部3分析过的对话进行修正(对话修正工序:s105)。
[0026]
在上述例子中,例如将对话修正如下。“根据检查结果,可以说您的病名是纤维肌痛症的可能性较高。纤维肌痛症是伴有全身多个部位压痛或疼痛的疾病。给您开了用于缓解纤维肌痛症引起的压痛的内服药lyrica(
リリカ
:注册商标),请1天2次在早餐后和晚餐后服用。”例如,“理科”是正确的用语,因此一般的修正引擎无法对其进行修正。由于像这样把握了纤维肌痛症这一话题,因此该系统1能够进行恰当的修正。
[0027]
对话分析系统的优选例还具有话题信息提取部11,所述话题信息提取部11用于提取与话题有关的信息。话题信息提取部11的一例是从对话中提取与话题相关的用语。另外,话题信息提取部11的另一例是从各种信息站点读取包含话题词的各种数据,并从读取出的数据中所包含的用语中提取与话题有关的信息(用语),其中,所述各种信息站点经由互联网等与系统1连接。与话题有关的信息的一例是在与话题相关的资料或演示中使用的频率较高的用语。例如,样本中的用语为正确的用语的可能性高。因此,读取存储部中存储的用语即话题,并读取包含与该话题有关的用语的资料中所包含的用语,将其作为与该话题相关的信息(用语)存储即可。该用语可以作为候选修正用语被存储于话题相关修正用语存储部7中,或者也可以更新已存储的用语。
[0028]
对话分析系统的优选例还具有用于更新话题相关修正用语存储部7的话题相关用语更新部13。并且,话题相关用语更新部13使用输入到系统的与各话题有关的信息来更新候选修正用语。
[0029]
例如,系统1具有机器学习程序。并且,机器学习程序根据被输入到系统中的与话题有关的各种信息或数据来存储与话题有关的经常使用的用语,并将存储的用语作为候选修正用语存储于存储部即可。这样一来,对于用语的变化也能够自动地应对,能够自动更新恰当的修正用语。
[0030]
本说明书中记载的一发明涉及一种对话分析系统用程序。该程序是使计算机作为语音分析机构、话题相关用语存储机构、话题把握机构和对话修正机构发挥作用的程序。并且各种机构与上述各部对应。
[0031]
本说明书中记载的一发明涉及一种储存有上述程序的计算机可读取的信息记录介质。信息记录介质的例子有cd-rom、dvd、软盘(floppy disk)、存储卡(memory card)和记忆棒(memory stick)。
[产业上的可利用性]
[0032]
本发明涉及一种对话分析系统,因此可以用于信息相关产业。[附图标记说明]1:对话分析系统;3:语音分析部;5:话题把握部;7:话题相关修正用语存储部;9:对话修正部;11:话题信息提取部;13话题相关用语更新部。