1.本发明涉及语音降噪技术领域,尤其涉及一种利用数理统计和深度网络结合的语音降噪通用方法。
背景技术:
2.基于传统的语音降噪算法有很多(可参考图1),大类归为噪声抑制和语音增强。
3.对于单支麦克风的单通道情况,噪声抑制常见的有维纳滤波、卡尔曼滤波、自适应滤波器等基于数理统计原理的减谱法,此类方法听感还不错,但是在强噪声下或者全频污染,要保留较好的降噪效果,会引起很大的语音畸变,保真度无法得到保证。另一个最大的缺陷是无法很好的处理非稳态突发噪声,如狗叫、键盘敲击等突发噪声。由于短时傅立叶变换无法同时兼顾时域和频域的分辨率,选择较大的收敛因子会导致降噪完不平稳;选择较小的收敛因子则收敛时间长,无法及时处理突发噪声。
4.因此也有基于小波包变换,此方法计算复杂度高,而且目前针对语音的小波基还在研究中,还没有较通用的小波基可用于语音降噪的工程产品,目前大部分小波基算法用于机械故障检测和图像边缘检测等领域。
5.对于多支麦克风的多通道语音降噪算法,如信号子空间方法、听觉掩蔽效应方法、独立分量分析、波束形成等,为了语音保真度,保留了大部分噪声,从听感的舒适度来讲,不适用于通话降噪、对讲机或视频会议等使用场景,且多麦克风成本高,对麦克风一致性要求较为严苛,算法落地和故障排查多有不便。此外对于混响较大的场景,此类算法的性能大打折扣。
6.随着数据获取的便捷性的提高和芯片运算性能的快速发展,深度学习降噪(可参考图2)成为一种主流趋势,有用端到端的深度神经网络结构,编解码一体;也有运用卷积和递归估计噪声谱,然后用减谱法降噪等。此类方法有四个明显的缺陷:
7.第一:延时高,因为拼帧做卷积计算;
8.第二:运算复杂度高,含有多层级的卷积和逆卷积过程;
9.第三:内存开销大,由于要还原语音需要大量的权重参数;
10.第四:存在较为严重的语音失真,尤其在没有训练模型见过的样本中,语音还原度差,降噪引入的声音畸变较大。简而言之,此类算法由于运算量大、泛化能力差、延时高等问题,导致其无法快速工业化落地应用。也有一些低延时单纯的网络降噪算法,在非语音段噪声压制得很干净,但在语音段,为了防止语音失真,帧间音乐噪声伪影残留大,伴有哧啦呼啦的声音,在低性能噪比和全频污染(如白噪声)等情况下,尤为明显。
11.综上所述,语音识别前处理要求降噪处理后的语音有较高保真度,通话降噪或视频会议等场景要求降噪处理后的语音有较好的自然度和可懂度并且能能处理各类噪声,目前没有可以很好兼顾二者,同时又有实用价值的通用降噪算法。
12.因此,提出一种利用数理统计和深度网络结合的语音降噪通用方法。
技术实现要素:
13.本发明的目的在于:为了解决上述的问题,而提出的一种利用数理统计和深度网络结合的语音降噪通用方法。
14.为了实现上述目的,本发明采用了如下技术方案:
15.一种利用数理统计和深度网络结合的语音降噪通用方法,包括以下步骤:
16.a.带噪语音输入,用短时傅立叶变换,得到带噪频谱的64个子带;
17.b.计算64个子带的三角滤波对数能量;
18.c.计算子带能量的倒谱系数作为特征,输入lstm神经网络模型;
19.d.用lstm神经网络模型计算语音权重;
20.e.通过语音权重系数作用于带噪频谱,得到初级干净频谱;
21.f.通过拉式滤波和小波作用于初级干净频谱,得到干净频谱;
22.g.输入干净频谱,用短时傅立叶逆变换回干净语音。
23.作为上述技术方案的进一步描述:
24.所述d步骤中的lstm神经网络模型构建步骤为:
25.s1.带噪语音输入,用短时傅立叶变换,把频域均匀的分成64个子带,每个子带4个频点;
26.s2.设计64个子带的三角滤波,取对数能量,让特征值更加平稳;
27.s3.用离散余弦傅立叶变换计算子带能量的倒谱系数,同时计算一阶二阶差分;
28.s4.由此得到每帧64维矩阵作为特征输入,用单向lstm神经网络学习它的语音权重;
29.s5.通过损失函数计算和迭代,得到最终的lstm神经网络模型。
30.作为上述技术方案的进一步描述:
31.所述f步骤的具体步骤为:
32.输入相对干净的频谱,利用拉式滤波估计残留稳态噪声;
33.输入相对干净的频谱,利用小波瞬时特性估计音乐噪声伪影。
34.综上所述,由于采用了上述技术方案,本发明的有益效果是:
35.1.通用性:该方法可同时用于通话、对讲机或视频会议等降噪场景和语音识别前处理,通过调整权重,做语音识别保真度高,做通话降噪自然度和可懂度高。
36.2.低成本:针对单通道设计,只需要一支麦克风,节约成本。
37.3.低内存:用了量化机制,节省内存开销,神经元权重仅有30k左右就可以达到很好的效果,实际运行时候开辟内存空间仅需要55k。
38.4.低功耗:用ln2优化自然对数指数函数【1】,而不用泰勒展开的查表方式,更简洁,运行速度也更快;用简化的球面高斯算法优化非自然对数指数函数【2】。
39.5.低延时:帧间依赖仅有32ms(小于41ms),可以音视频同步。
40.6.用均匀的子带,具有较强的泛化能力,而不像mel域仅考虑音高感知的非线性映射或bark域仅考虑心理声学的非线性映射。
附图说明
41.图1示出了根据本发明实施例提供的传统语音降噪流程示意图;
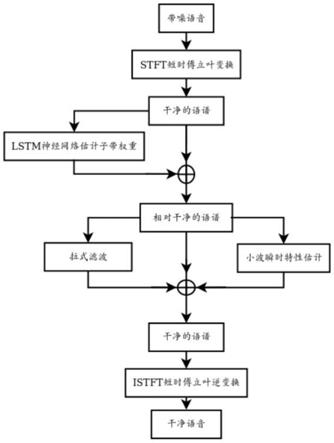
42.图2示出了根据本发明实施例提供的常见神经网络语音降噪流程结构示意图;
43.图3示出了根据本发明实施例提供的lstm神经网络训练流程示意图;
44.图4示出了根据本发明实施例提供的通用语音降噪解码流程示意图;
45.其中:
46.图3中的lstm是长短期记忆递归神经元的缩写;
47.图3中的dct是离散余弦傅立叶变换的缩写;
48.图4中的stft是短时傅立叶变换的缩写,istft是短时傅立叶逆变换的缩写。
具体实施方式
49.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
50.请参阅图3
‑
4,本发明提供一种技术方案:一种利用数理统计和深度网络结合的语音降噪通用方法,包括以下步骤:
51.a.单通道带噪语音输入,用短时傅立叶变换,得到带噪频谱的64个子带;
52.b.计算64个子带的三角滤波对数能量;
53.c.用离散余弦傅立叶变换计算子带能量的倒谱系数作为特征,输入lstm神经网络模型;
54.d.用lstm神经网络模型计算语音权重;
55.e.通过语音权重系数作用于带噪频谱,得到初级干净频谱;
56.f.通过拉式滤波和小波作用于初级干净频谱,得到干净频谱,具体步骤为,
57.输入相对干净的频谱,利用拉式滤波估计残留稳态噪声,拉氏滤波是优化拉普拉斯算子后,用于稳态噪声的概率密度模型统计的滤波器;
58.输入相对干净的频谱,利用小波瞬时特性估计音乐噪声伪影,小波瞬时特性估计,是受到小波时域和频域兼顾的启发,设计出一种估计音乐噪声伪影的滤波器。
59.g.输入干净频谱,用短时傅立叶逆变换回干净语音。
60.其中,初级干净频谱是指相对干净的频谱。
61.具体的,如图3和图4所示,lstm神经网络模型构建主要分为三个关键点,第一:根据干净语音和带噪语音,设计模型标签,即理想权重参数,可以根据使用需求进行设计;第二:特征提取模块;第三:神经网络训练模块。d步骤中的lstm神经网络模型构建步骤为:
62.s1.带噪语音输入,用短时傅立叶变换,把频域均匀的分成64个子带,每个子带4个频点;
63.s2.设计64个子带的三角滤波,取对数能量,让特征值更加平稳;
64.s3.用离散余弦傅立叶变换计算子带能量的倒谱系数,同时计算一阶二阶差分;
65.s4.由此得到每帧64维矩阵作为特征输入,用单向lstm神经网络学习它的语音权重;
66.s5.通过损失函数计算和迭代,得到最终的lstm神经网络模型。
67.以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,
任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。