1.本发明属于声音信号识别领域,涉及一种基于多层矩阵随机神经网络的城市噪声识别方法。
背景技术:
2.伴随着城市化建设进程的日益推进,城市噪声问题愈发严重,给人类的日常生活和身体健康都带来了不可忽视的影响,因此,采用机器学习的方法,建立实时全天候的城市噪声监测系统进行管控是至关重要的。
3.目前采用声信号特征提取方法,并结合传统的分类器搭建的实时监控系统,其问题在于,传统的声特征提取方法往往是针对语音信号而设计的,并不完全适用于城市噪声信号;针对城市噪声的特征提取方法无法覆盖到各种声源的特性;此外,由于声信号的非平稳性,这些特征提取方法均是基于一段短时范围内的声信号,其包含的信息有限。
4.相比较于在一维短时声信号上进行特征提取,采用以时间为横轴,频域特征为纵轴构成的二维时频图,是现在主流的声信号识别所采取的方法,其所包含的信息量是远大于一维短时声信号的。在此基础上,采用卷积神经网络进行学习,或者采用深度迁移特征进行特征提取,结合传统分类器进行识别,是目前流行的两种方式。然而卷积神经网络训练时间长,而深度迁移特征对时频图的表示能力弱,因此目前缺乏有效快速的基于时频图的城市噪声识别方法。
技术实现要素:
5.为了克服上述城市噪声识别中存在的问题,本发明提出了一种基于多层矩阵随机神经网络的城市噪声识别方法。
6.本发明的技术方案主要包括如下步骤:
7.步骤1、对采集到的城市噪声进行预处理,包括去噪、预加重、分帧、加窗等,其中帧长为l,帧移为
8.步骤2、将经过预处理的噪声信号转换成时频图。
[0009]2‑
1.对经过预处理后的每一帧噪声信号,进行离散傅里叶变换(dft),将时域信号转换为频域信号。
[0010]2‑
2.对经过dft后的各帧信号,对各频率点的幅值进行平方,获得该频率点下的能量;
[0011]2‑
3.组合连续的l
n
帧信号,以频率为纵坐标,横坐标为连续的l
n
帧信号,构成二维时频图,其中像素点(m,n)的大小表示第m帧,第n个频率点的能量。
[0012]
步骤3、构建矩阵随机自编码器,以城市噪声二维时频图作为矩阵随机自编码器的输入,通过输出重建输入的方式进行训练,获得最优的输出权重作为编码器。同时将上一个相邻矩阵随机自编码器的编码输出作为下一个矩阵随机自编码器的输入,堆叠k个矩阵随
机自编码器。
[0013]3‑
1.通过步骤2处理之后,得到具有n个样本的训练数据集x=[x1,x2,
…
,x
i
,
…
,x
n
],其中表示由第i张尺寸为d1×
d2的时频图,i=1,2,
…
,n。并记y
(0)
=x,即
[0014]3‑
2.将作为输入,随机生成输入权重矩阵以及隐藏层偏置矩计算隐藏层输出为:
[0015][0016]
其中g(
·
)激活函数。
[0017]3‑
3.构建矩阵随机自编码器的损失函数为:
[0018][0019]
其中表示第k次进行训练获得的输出权重,c为正则项参数,采用随机梯度下降法求解上述损失函数。
[0020]3‑
4.基于训练好的第k个矩阵随机自编码器的输出权重,获得第k个矩阵随机自编码器的编码输出为:
[0021][0022]3‑
5.重复步骤3
‑
2、3
‑
3、3
‑
4,训练k个矩阵随机自编码器,并得到最终的编码输出
[0023]
步骤4、构建矩阵均方误差损失函数,进行城市噪声分类识别。
[0024]4‑
1.基于步骤3中获得的k个矩阵随机自编码器的编码输出构造如下的损失函数:
[0025][0026]
其中c为权重衰减参数,t=[t1,t2,
…
,t
n
]
t
表示训练样本的期望输出,为需要进行训练的输出权重。此处的权重β
u
和β
v
与前述自编码器的权重有所区别,此处的权重是为了进行分类而训练的,为了与自编码器的权重进行区分,此处不带上标。
[0027]4‑
2.利用随机梯度下降法进行训练,获得训练好的β
u
和β
v
。
[0028]
步骤5、对新的声音信号进行分类预测。
[0029]
对于未知信号,通过预处理之后转换为时频图x
p
,并输入到多层矩阵随机神经网络中,获得编码输出为:
[0030][0031]
将所得的输出传输给decision layer进行决策分类:
[0032][0033]
最终所得的y
p
是一个向量,其元素中数值最大的元素所对应的位置即为该样本所属的类别。
[0034]
本发明有益效果如下:
[0035]
本发明针对城市噪声监控问题,提出了多层矩阵随机神经网络方法进行实时高效全天候监控,该方法的效益在于:
[0036]
1)采用矩阵随机自编码器对城市噪声时频图进行自动快速的特征表示。相比较于传统的一维声音信号特征,采用二维时频图包含有更多的信息;相比较于传统的自编码器,提出的矩阵自编码器能够直接以二维矩阵作为输入,在二维图上直接进行特征提取,充分保留了时频图的结构信息,同时采用矩阵的方式可以大大减少待训练参数数量;采用隐藏层参数随机生成的方式,可以大大加快矩阵随机自编码器的训练速度。
[0037]
2)采用堆叠矩阵随机自编码器,利用逐层贪婪训练搭建起来的多层矩阵随机神经网络,可以学习到更加有效的关于城市噪声有效的特征表示;同时结合构建的矩阵均方误差损失函数,可以免去全连接层中的矢量化步骤,在充分保留时频图结构信息的基础上,实现有效的城市噪声识别。
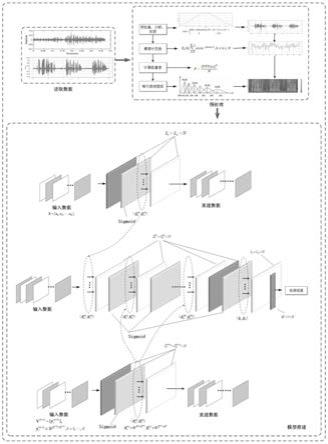
附图说明
[0038]
图1是ae模型结构图;
[0039]
图2是本发明总体模型结构图。
具体实施方式
[0040]
下面结合附图和具体实施方式对本发明作详细说明,以下描述仅作为示范和解释,并不对本发明作任何形式上的限制。本发明分别采用以下方式进行改进,包括1)构建矩阵随机自编码器,以二维时频图直接作为随机自编码器的输入,通过在重建输入的时频图过程中,学习到有效的针对于城市噪声的特征表示,既充分保留了图像内部的结构信息,同时又免去了繁琐的矢量化步骤,实现更好的利用音频特征,使得能够有效的处理多种高维复杂特征;2)以训练好的矩阵随机自编码器的输出权重作为多层矩阵随机神经网络的连接权重,采用贪婪式方法进行矩阵随机自编码器的堆叠,构建多层矩阵神经网络结构,采用隐藏层参数随机生成的方式可以有效提高训练速度,减少训练时间,此外,采用矩阵的形式大大减少了待训练参数的数量;3)构建矩阵均方误差损失函数,进行城市噪声分类识别,有效提高分类器的分类识别能力。
[0041]
以多种城市噪声为例,使用mat elm
‑
ae网络进行分类,图2是整体的处理流程示意图,具体实现如下:
[0042]
步骤1、对采集到的城市噪声进行预加重、去噪、分帧、加窗,其中采用的一阶高通滤波器特性为h(z)=1
‑
z
‑1;帧长为1024,帧移为512,采用汉宁窗作为窗函数。
[0043]
步骤2、将经过预处理的噪声信号转换成时频图。
[0044]
分别取连续的11帧信号,对每一帧噪声信号进行dft,并去掉尾部的对称的频率点,计算能量,得到维数为11
×
513的二维时频图。
[0045]
步骤3、本实例堆叠2个矩阵随机自编码器,训练2个矩阵随机自编码器。
[0046]
n个样本的训练数据集x=[x1,x2,
…
,x
n
],其中表示第i张时频图,i=1,2,
…
,n。
[0047]
对于第一个矩阵随机自编码器,以x=[x1,x2,
…
,x
n
]作为输入,记y
(0)
=x,即我们设置隐藏层的维数为100
×
100,随机生成输入权重矩阵以及隐藏层偏置矩阵其中各元素值独立同分布,服从[
‑
1,1]间的均匀分布。然后,计算隐藏层输出为
[0048][0049]
其中g(
·
)取非线性的sigmoid函数作为激活函数。构建矩阵随机自编码器的损失函数如下:
[0050][0051]
其中是需进行训练获得的输出权重,c为正则项参数。采用随机梯度下降法求解上述损失函数,获得输出权重矩阵。最后,获得第1个矩阵随即自编码器的编码输出为:
[0052][0053]
对于第2个矩阵随机自编码器,我们以第1个矩阵随机自编码器的编码输出作为输入,其中并设置隐藏层的维数为100
×
100,以均匀分布随机生成输入权重矩阵以及隐藏层偏置矩阵计算隐藏层输出为
[0054][0055]
最后求解如下的损失函数:
[0056][0057]
得到第2个矩阵随机自编码器的输出权重和获得编码输出结果为:
[0058][0059]
步骤4、构建矩阵均方误差损失函数,进行城市噪声分类识别。
[0060]
基于经过2个矩阵随机自编码器后的编码输出构造如下的矩阵均方误差损失函数:
[0061]
[0062]
其中c为正则化参数,t=[t1,t2,
…
,t
n
]
t
表示训练样本的期望输出,为需要进行训练的输出权重,其中m1表示目标的类别数量。利用随机梯度下降法进行训练,获得训练好的β
u
和β
v
。
[0063]
步骤5、对新的声音信号进行分类预测。
[0064]
对于未知信号,通过预处理之后转换为时频图x
p
,并输入到多层矩阵随机神经网络中,即:
[0065][0066]
最后得到识别输出为:
[0067][0068]
取y
p
的元素中数值最大的元素所对应的位置即为该样本所属的类别。