1.本发明属于音频信号处理技术,涉及一种基于数据增强和卷积循环神经网络的环境声音分类方法。
背景技术:
2.环境声音分类为音频监控、场景检测、智能设备感知等方面起到了极其重大的作用,极大地扩展了机器感知人类所生活的环境的能力,为人们的生活提供相当大的便利,因此在信息技术高度发展的今天,环境噪声识别得到愈加广泛的使用。
3.目前的环境声音分类技术中,传统的声音识别算法一般有支持向量机、高斯混合模型、隐马尔可夫模型等,虽然他们在环境声音的识别分类方面起到一定的作用,但这些识别模型都只是符号化的系统,降低了建模能力,因此在实际环境中对不同质量的声音信号的识别性能大幅下降,分类效果远远达不到人们对环境噪声分类准确度的要求。人工神经网络的出现使得人们可以让机器具有类似于人的思考方式,人工神经网络能够创建抽象的数学模型,但现有的神经网络的网络结构形式单一,对环境噪声的分类效果并不理想。
技术实现要素:
4.本发明的目的在于提供一种基于数据增强和卷积循环神经网络的环境声音分类方法,对数gammatone频谱图特征进行数据增强,设计出与声音特征相适应的卷积循环神经网络并对环境声音进行识别分类,提高模型识别的准确率。
5.实现本发明目的的技术解决方案为:一种基于数据增强和卷积循环神经网络的环境声音分类方法,包括如下步骤:
6.对环境声音音频进行预处理,提取对数gammatone频谱图特征;
7.去除对数gammatone频谱图特征中的静音帧,并进行特征归一化;
8.设计基于卷积循环神经网络的环境声音分类系统;
9.设计基于特征图旋转或翻转的数据增强方法、cutout数据增强方法以及cutmix数据增强方法;
10.对esc
‑
10数据集合esc
‑
50数据集分别使用数据增强,并将增强数据用于卷积循环神经网络模型的训练,得到基于数据增强和卷积循环神经网络的环境声音分类系统,并验证该系统的分类准确性;
11.其中环境声音音频预处理包括:
12.对声音信号进行预加重,补充声音信号的高频部分;
13.对预加重后的声音信号进行分帧和加窗操作。
14.本发明提供一种基于数据增强和卷积循环神经网络的环境声音分类方法,与现有技术相比,本发明的优点为:(1)以区分性较强的声学特征对数gammatone频谱图特征为训练样本;(2)将静音帧等无关信息进行过滤,防止无关信息对分类性能的影响,提高分类准确性;(3)将特征值进行归一化,方便数据增强时进行特征组合;(4)与传统的环境声音分类
模型相比,本发明使用了卷积循环神经网络的分类模型,发挥卷积神经网络的特征提取和特征分类能力,以及循环神经网络的动态时间信息捕捉能力,具有更强的非线性函数拟合能力,更能统计学习样本特征和类别之间的对应关系;(5)对训练集进行数据增强,降低较小数据集对分类模型的影响,提高分类准确性,增强模型的鲁棒性;6.对训练集分别使用三种不同的数据增强方案,比较不同数据增强方式对环境声音分类的不同影响。
附图说明
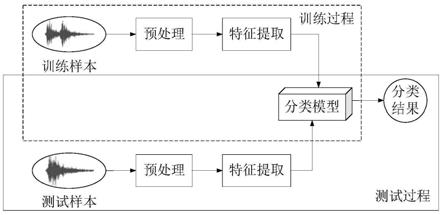
15.图1是基于卷积循环神经网络的环境声音分类系统框架;
16.图2是环境声音的特征提取流程图;
17.图3是卷积循环神经网络的结构图;
具体实施方式
18.一种基于数据增强和卷积循环神经网络的环境声音分类方法,包括如下步骤:
19.对环境声音音频进行预处理,提取对数gammatone频谱图特征;
20.去除对数gammatone频谱图特征中的静音帧等无关信息,并进行特征归一化;
21.设计基于卷积循环神经网络的环境声音分类系统;
22.设计基于特征图旋转或翻转的传统数据增强方法、cutout数据增强方法以及cutmix数据增强方法;
23.对esc
‑
10数据集合esc
‑
50数据集分别使用数据增强,并将增强数据用于卷积循环神经网络模型的训练,得到基于数据增强和卷积循环神经网络的环境声音分类系统,并验证该系统的分类准确性。
24.其中环境声音音频预处理包括:
25.对声音信号进行预加重,补充声音信号的高频部分;
26.对预加重后的声音信号进行分帧和加窗操作,分帧可以获取声音信号的局部稳定信号,加窗可以防止声音信号在分帧时切片处产生的信号突变,防止特征提取过程中的频谱泄露。
27.进一步的,声音信号所描述的场景特征包括狗吠,打雷,虫鸣,枪声,鸟叫,鸣笛及人类非语音这些环境声音中的一种或多种。
28.进一步的,对声音信号进行预加重,对高频分量进行补偿处理,该操作对噪声信号并没有影响,突出音频信号的高频部分。
29.进一步的,音频预加重的传递函数为:
30.h(z)=1
‑
αz
‑1,α
→131.α表示加重系数,z表示原始声音信号,h(z)为预加重后声音信号。
32.进一步的,为了获取一段音频中的局部特征,需要对音频进行分帧和加窗,声音信号的分帧操作可获得局部平稳的音频信号,相邻两帧之间有部分重叠,帧移占帧长的1/2;声音信号加窗是对分帧后的音频帧添加窗函数,可以防止在每帧音频切片的起始或终止位置的信号产生较大变化,使音频信号更加平滑,防止在后面的特征提取过程中发生频谱泄露。
33.进一步的,提取音频信号的对数gammatone频谱图特征,根据特征参数的维度确定
卷积循环神经网络的输入维度为128
×
128;第一层到第十层卷积层的卷积核的大小为3
×
3,步进长度为1
×
1,最大池化大小2
×
2,batchnormalization特征归一化,relu作为激活函数;第一层和第二层卷积层的卷积核的个数为32,第三层和第四层卷积层的卷积核个数为64,第五层和第六层卷积层的卷积核个数为128,第七层和第八层卷积层的卷积核个数为256,第九层和第十层卷积层的卷积核个数为512;一层时间分布层;循环神经网络部分使用两层gru门控循环单元,单元个数都为1024;两层全连接层,第一层隐藏单元的个数为1024,relu作为激活函数,dropout概率为0.3,第二层隐藏单元的个数为512,relu作为激活函数,dropout概率为0.6;输出层的输出单元的个数为环境声音的样本类别个数,softmax作为激活函数。
34.为了去除一段音频中的无声部分,确定音频信号的有效部分,需要对音频进行特征提取过程中进行特征过滤。
35.为了方便数据增强时的特征组合,需要对特征进行归一化处理,将特征值归一化到[0,1]之间或[0,255]的灰度化。
[0036]
为了发挥卷积神经网络特征提取和特征分类能力,以及循环神经网络动态时间信息捕捉能力,需要将卷积神经网络与循环神经网络进行结合,形成卷积循环神经网络分类模型。
[0037]
为了降低有限数据集对模型分类性能的影响,需要将训练集进行数据增强,增加训练样本容量,提高分类模型分类准确性的同时,提高分类模型的鲁棒性。
[0038]
进一步的,对esc
‑
10数据集和esc
‑
50数据集进行数据增强,以5
‑
折交叉验证的方式训练卷积循环神经网络分类模型。对每种数据集,按4:1的比例分成训练集和验证集,仅对训练集进行数据增强并用于模型训练,验证集用于验证模型精度。
[0039]
进一步的,对训练集分别进行传统数据增强、cutout数据增强和cutmix数据增强,比较三种增强方案对分类模型性能的影响。
[0040]
进一步的,传统数据增强是随机地对特征图进行水平翻转或逆时针旋转,cutout数据增强是随机地剪切并舍弃特征图中的部分区域,cutmix数据增强是以某种比例随机组合两种不同特征。其中,
[0041]
cutmix数据增强的实现公式如下:
[0042][0043]
其中x
a
,x
b
分别表示两种待组合的特征,y
a
,y
b
分别表示x
a
,x
b
所属的样本,m表示二进制掩码矩阵,
⊙
表示矩阵对应元素相乘,λ表示两种特征的组合率,分别表示两种特征组合后的特征和类别。
[0044]
进一步的,使用分类性能最好的数据增强方案,用esc
‑
50数据集评估训练好的卷积循环神经网络分类模型,验证数据增强用于基于卷积循环神经网络的环境声音分类系统的重要作用。
[0045]
下面结合附图和具体实施例对本发明作进一步详细描述。
[0046]
实施例
[0047]
一种基于数据增强和卷积循环神经网络的环境声音分类方法,包括:对环境声音
音频进行预处理,提取对数gammatone频谱图特征,去除特征中的静音帧,并对特征值进行归一化处理;设计基于卷积循环神经网络的环境声音分类系统,将用于特征提取的堆叠卷积神经网络与用于时间信息捕捉的循环神经网络相结合,实现图像特征向时间序列的转化,并将转化后的时间序列特征向量映射到全连接层隐藏空间,再由softmax层将特征图从隐藏空间映射到类别空间,完成特征分类;对数据集esc
‑
10和数据集esc
‑
50应用数据增强。
[0048]
如图1所示,基于卷积循环神经网络的环境声音分类系统框架,主要分为训练过程和测试过程。训练过程分为原始音频输入,预处理,特征提取,模型训练,输出声音类别。原始音频来源于esc
‑
10数据集和esc
‑
50数据中的音频文件,然后对其中的音频进行预处理,包括分帧和加窗,取帧长为1024,取帧移为512,将不稳定的音频分帧成多个切片,获取具有短时稳定的音频帧,然后对每帧音频进行汉明加窗,防止在每帧的起始或终止位置的特征参数有较大变化,防止特征提取过程中发生频谱泄露。提取到的音频特征对数gammatone频谱图特征输入至分类模型中进行训练,完成模型的训练阶段。在模型的测试过程中,对数据集进行同样的预处理和特征提取,但不同之处在于仅将特征样本输入至分类模型获取模型的分类结果,该结果将和特征样本的真实类别相比较,以验证模型对特征分类的正确与否,从而得到模型的分类准确性。无论是训练过程还是测试过程,都涉及到环境声音分类的两个主要部分:特征提取和特征分类,其中特征提取过程如下:
[0049]
如图2所示,首先对数据集的音频进行预加重,增加原始波形的高频分量,预加重参数设置为0.97。数据集esc
‑
10和数据集esc
‑
50的每个音频,其长度为5s左右,对其进行采样率为44100hz的重采样,得到长度为220500的音频采样点,对其进行帧长为1024,帧移为512的分帧处理,得到429个长度为1024的音频帧,接着对这429个音频帧进行加窗处理,加窗函数使用汉明窗,使429个音频帧的首尾两端的幅值变化更加平滑。接下来,对加窗后的音频帧采取傅里叶变换,将音频的时域信息转化为频域信息,得到大小为429
×
512的音频时频特征。然后对时频特征使用gammatone滤波器组进行滤波处理,其操作为时频特征与gammatone滤波器组矩阵的矩阵相乘,gammatone滤波器组的个数为128,即gammatone滤波器组矩阵的大小为128
×
512,时频特征经过gammatone滤波器组滤波后得到大小为429
×
128的gammatone频谱图特征。最后将gammatone频谱图特征映射到对数尺度,形成对数gammatone频谱图特征。
[0050]
将大小为429
×
128的对数gammatone频谱图特征进行分帧处理得到128
×
128的方形特征,然后进行[0,1]的归一化或[0,255]的灰度化,前者将特征矩阵的值与频谱图的绝对值的最大值相除后进行0.5倍的缩放和0.5的偏移,后者将特征矩阵的值与频谱图的绝对值的最大值相除后进行125倍的缩放和125的偏移。
[0051]
对处理后的对数gammatone频谱图特征进行数据增强,增强操作分别传统数据增强、cutout数据增强和cutmix数据增强。
[0052]
基于卷积神经网络的环境声音分类模型结构如图3所示,cnn虚线框部分以卷积
‑
卷积
‑
池化的堆叠方式构建卷积循环神经网络的卷积部分,将大小为128
×
128的对数gammatone频谱图特征进行卷积运算并在池化层的作用下特征图的大小逐层减半,最后一层的池化层的输出特征图大小为512
×4×
4。然后特征图经过时间分布层的转换,将特征图转换成大小为4
×
2048的时间序列,然后用两层gru网络提取时间序列中的时域信息。最后用两层全连接层对时间序列进行分类,并且在全连接层之后分别使用大小为0.3和0.6的
dropout层随机舍弃部分神经元的连接,防止模型过拟合。最后使用softmax作为模型的输出层,计算对数gammatone频谱图特征在类别空间的概率大小。