1.本发明实施例涉及音频识别领域,尤其涉及一种音频识别模型的训练方法与乐器对象识别方法。
背景技术:
2.互联网技术和音乐产业飞速发展的大前提下,越来越多的乐器得以在互联网平台中出现在大众的视野当中,特别是对于一些小众的传统民族、民间乐器,用以推广中国传统音乐与地域文化。现有的乐器识别模型不够多元化,只针对一种乐器进行识别,无法识别出多种乐器。
技术实现要素:
3.有鉴于此,本发明实施例的目的是提供一种音频识别模型的训练方法与乐器对象识别方法,用以解决现有技术中乐器识别效率低、不够准确的问题。
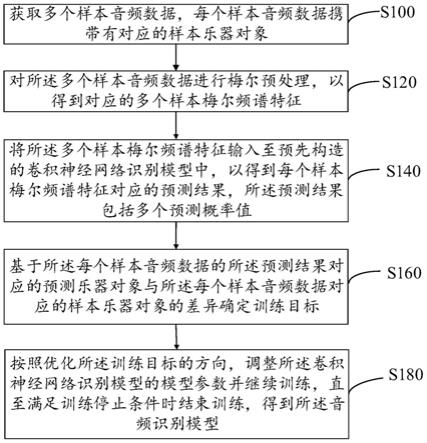
4.为实现上述目的,本发明实施例提供了一种音频识别模型的训练方法,包括:
5.获取多个样本音频数据,每个样本音频数据携带有对应的样本乐器对象;
6.对所述多个样本音频数据进行梅尔预处理,以得到对应的多个样本梅尔频谱特征;
7.将所述多个样本梅尔频谱特征输入至预先构造的卷积神经网络识别模型中,以得到每个样本梅尔频谱特征对应的预测结果,所述预测结果包括多个预测概率值;
8.基于所述每个样本音频数据的所述预测结果对应的预测乐器对象与所述每个样本音频数据对应的样本乐器对象的差异确定训练目标;
9.按照优化所述训练目标的方向,调整所述卷积神经网络识别模型的模型参数并继续训练,直至满足训练停止条件时结束训练,得到所述音频识别模型。
10.进一步地,所述对所述多个样本音频数据进行梅尔预处理,以得到对应的多个样本梅尔频谱特征包括:
11.构建提取参数,所述提取参数用于从所述多个样本音频数据中提取样本频谱特征;
12.基于所述提取参数从每个所述样本音频数据中,提取每个所述样本音频数据对应的频谱特征;
13.对每个样本频谱特征进行梅尔尺度变换,得到对应的变换梅尔频谱特征;
14.将每个变换梅尔频谱特征进行缩放处理,得到所述样本梅尔频谱特征。
15.进一步地,所述预先构造卷积神经网络识别模型的步骤包括:
16.根据所述样本梅尔频谱特征以及与所述样本梅尔频谱特征对应的乐器,构造映射函数;
17.基于所述映射函数对卷积神经网络模型进行修改,以得到卷积神经网络识别模型。
18.进一步地,基于所述每个样本音频数据的所述预测结果对应的预测乐器对象与所述每个样本音频数据对应的样本乐器对象的差异确定训练目标包括:
19.选取所述每个样本音频数据的所述预测结果中最大的预测概率值对应的预测乐器对象作为测试乐器对象;
20.判断所述每个样本音频数据的测试乐器对象是否为所述每个样本音频数据的样本乐器对象;
21.若不一致,则将所述训练目标确定为:所述每个样本音频数据的测试对象为所述每个样本音频数据的样本乐器对象。
22.进一步地,按照优化所述训练目标的方向,调整所述卷积神经网络识别模型的模型参数并继续训练,直至满足训练停止条件时结束训练,得到所述音频识别模型包括:
23.计算所述测试对象对应的样本概率值与所述样本乐器对象对应的预测概率值之间的误差值;
24.基于所述误差值调整所述卷积神经网络识别模型的模型参数并继续训练,直至满足训练停止条件时结束训练,得到所述音频识别模型;其中,所述训练停止条件为所述误差值小于预设阈值。
25.为实现上述目的,本发明实施例提供了一种基于音频识别模型的乐器对象识别方法,包括:
26.获取待识别音频数据;
27.基于提取参数从待识别音频数据中提取对应的目标频谱特征;
28.对每个目标频谱特征进行梅尔预处理,得到输入梅尔频谱特征;
29.将所述输入梅尔频谱特征输入至音频识别模型中,以输出所述待识别音频数据的目标概率值组;
30.从所述目标概率值组对应的乐器对象组中,确定所述待识别音频数据对应的目标乐器对象。
31.进一步地,所述对每个目标频谱特征进行梅尔预处理,得到输入梅尔频谱特征包括:
32.对每个目标频谱特征进行梅尔尺度变换,得到对应的目标梅尔频谱特征;
33.将所述目标梅尔频谱特征进行缩放处理,得到输入梅尔频谱特征。
34.为实现上述目的,本发明实施例提供了一种音频识别模型的训练系统,包括:
35.第一获取模块,用于获取多个样本音频数据,每个样本音频数据携带有对应的样本乐器对象;
36.第一预处理模块,用于对所述多个样本音频数据进行梅尔预处理,以得到对应的多个样本梅尔频谱特征;
37.第一识别模块,用于将所述多个样本梅尔频谱特征输入至预先构造的卷积神经网络识别模型中,以得到每个样本梅尔频谱特征对应的预测结果,所述预测结果包括多个预测概率值;
38.第一确定模块,用于基于所述每个样本音频数据的所述预测结果对应的预测乐器对象与所述每个样本音频数据对应的样本乐器对象的差异确定训练目标;
39.调整模块,用于按照优化所述训练目标的方向,调整所述卷积神经网络识别模型
的模型参数并继续训练,直至满足训练停止条件时结束训练,得到所述音频识别模型。
40.为实现上述目的,本发明实施例提供了一种乐器对象识别系统,包括:
41.第二获取模块,用于获取待识别音频数据;
42.提取模块,用于基于提取参数从待识别音频数据中提取对应的目标频谱特征;
43.第二预处理模块,用于对每个目标频谱特征进行梅尔预处理,得到输入梅尔频谱特征;
44.第二识别模块,用于将所述输入梅尔频谱特征输入至音频识别模型中,以输出所述待识别音频数据的概率值组;
45.第二确定模块,用于从所述概率值组对应的乐器对象组中,确定所述待识别音频数据对应的目标乐器对象。
46.为实现上述目的,本发明实施例提供了一种计算机设备,所述计算机设备包括存储器、处理器,所述存储器上存储有可在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时实现上述的音频识别模型的训练方法以及上述的基于音频识别模型的乐器对象识别方法的步骤。
47.为实现上述目的,本发明实施例提供了一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机程序,所述计算机程序可被至少一个处理器所执行,以使所述至少一个处理器执行上述的音频识别模型的训练方法以及上述的基于音频识别模型的乐器对象识别方法的步骤。
48.本发明实施例提供的音频识别模型的训练方法与乐器对象识别方法,通过梅尔预处理对提取的目标频谱特征进行处理,得到样本梅尔频谱特征,再输入至音频识别网络中,输出一组概率值,选取最大概率值对应的乐器的作为目标乐器,通过预处理提取特征的方式提升了模型识别效率。
附图说明
49.图1为本发明音频识别模型的训练方法实施例一的流程图。
50.图2为本发明音频识别模型的训练方法实施例一中构造卷积神经网络识别模型的流程图。
51.图3为本发明音频识别模型的训练系统实施例二的程序模块示意图。
52.图4为本发明乐器对象识别方法实施例一的流程图。
53.图5为本发明乐器对象识别系统实施例二的程序模块示意图。
54.图6为本发明计算机设备实施例三的硬件结构示意图。
具体实施方式
55.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
56.实施例一
57.参阅图1,示出了本发明实施例一之音频识别模型的训练方法的步骤流程图。可以
理解,本方法实施例中的流程图不用于对执行步骤的顺序进行限定。下面以计算机设备6为执行主体进行示例性描述。具体如下。
58.步骤s100、获取多个样本音频数据,每个样本音频数据携带有对应的样本乐器对象。
59.具体地,样本频音数据的音频格式不限于cd、wave、aiff、mpeg、mp3、mpeg-4等音频格式。本发明实施例采用的是wave格式。样本音乐对象优选设计为25个,包括:建鼓、应鼓、柷、埙、敔、賁鼓、雅鼓、竽、琴、管子、排箫、篪、板鼓、笙、瑟、鼗鼓、琵琶、箜篌、二胡、马头琴、三弦、箫、葫芦丝、编钟、编磬。本发明实施例使用的样本音频数据的格式为wav、长度4s、采样率44100hz、位宽16bit,共3400个样本音频数据,训练集和测试集划分比例为9:1。
60.步骤s120、对所述多个样本音频数据进行梅尔预处理,以得到对应的多个样本梅尔频谱特征。
61.具体地,构建样本频谱特征的提取参数p={pi|i=1,2,3},其中pi=(wi,hi)为提取特征所构造的参数对,wi为特征提取过程中所用的窗体尺寸参数,hi为特征提取过程中所用的步长参数。本发明实施例中p优选为:p={(1102,441),(2205,1102),(4410,2205)}。
62.示例性地,所述步骤s120包括:
63.步骤s121、构建提取参数,所述提取参数用于从所述多个样本音频数据中提取样本频谱特征。步骤s122、基于所述提取参数从每个所述样本音频数据中,提取每个所述样本音频数据对应的频谱特征。步骤s123、对每个样本频谱特征进行梅尔尺度变换,得到对应的变换梅尔频谱特征。步骤s124、将每个变换梅尔频谱特征进行缩放处理,得到所述样本梅尔频谱特征。
64.具体地,通过傅里叶变换函数基于提取参数对提取出每个样本音频数据中的频谱特征s={si|i=1,2,3},其中,si=fft(a,wi,hi)。fft为傅立叶变换函数,将音频从时域信号转化为频域中的频率分量。在此过程中选取振幅谱作为提取到的特征频谱。通过该预处理提取频谱特征的方式提升了模型识别效率,又有效降低了卷积神经网络识别模型中需要进行识别的参数数量。对提取的频谱特征进行梅尔尺度变换,得到梅尔频谱特征m=mel(s),mel操作表示梅尔尺度变换,这种变换方式可以将信号的频谱特征缩放到类人耳感知特征的坐标系统下,便于更好的进行分析与处理。然后将m转化为对数刻度,得到对数梅尔频谱特征l=log
10
(m+e),其中e=10-6
为调节系数,即变换梅尔频谱特征。
65.由于卷积神经网络模型对输入的频谱特征有特定的尺寸要求,因此需要将提取的变换梅尔频谱特征的尺寸进行缩放处理,得到每个样本音频数据的样本梅尔频谱特征t。
66.步骤s140、将所述多个样本梅尔频谱特征输入至预先构造的卷积神经网络识别模型中,以得到每个样本梅尔频谱特征对应的预测结果,所述预测结果包括多个预测概率值。
67.具体地,将样本梅尔频谱特征输入至预先构造的卷积神经网络识别模型中,以对卷积神经网络识别模型进行训练。每个样本音频特征输入至卷积神经网络识别模型中,输出每个样本音频数据的一组预测概率值。卷积神经网络识别模型基于vgg16模型进行构建。vgg16模型为包括13个卷积层和3个全链接层的vgg(visual geometry group network,视觉几何群网络)模型。卷积神经网络识别模型可以根据输入的样本音频数据输出对应的一组预测概率值,即预测结果,每组概率值的个数优选为25个,表示样本音频数据与各个预测乐器对象之间的概率值。经过特征工程的方式从音频当中进行识别特征的提取并将其作为
深度学习模型的输入可以更加准确的实现识别效果。
68.示例性地,参阅图2,所述预先构造卷积神经网络识别模型的步骤包括:
69.步骤s200、根据所述样本梅尔频谱特征以及与所述样本梅尔频谱特征对应的乐器,构造映射函数。步骤s202、基于所述映射函数对卷积神经网络模型进行修改,以得到卷积神经网络识别模型。
70.具体地,构造从识别特征t到乐器对象o之间的映射函数r,其中,o∈{o1,o2,
…
,om},o
ins
=r(log
10
(mel(fft(a,w,h)))+e),m为网络所能识别的乐器数量,具体由音频数据集当中所包含的乐器种类决定。卷积神经网络模型优选为vgg16识别模型,在其中增加样本乐器对象对应的乐器数量(25件)的网络结构,将映射函数r与改网络结构相关联。可以方便的通过修改适配乐器数量的网络结构实现乐器数量的变化。
71.步骤s160、基于所述每个样本音频数据的所述预测结果对应的预测乐器对象与所述每个样本音频数据对应的样本乐器对象的差异确定训练目标。
72.具体地,每个样本音频数据的预测结果对应的预测乐器对象与每个样本音频数据对应的样本乐器对象的差异为,预测结果中的最大概率值对应的预测乐器对象是否为样本乐器对象;也可以表示为:若最大概率值对应的预测乐器对象与样本乐器对象不一致,计算最大概率值与预测结果中样本乐器对象对应的预测概率值的差异,训练目标为输出的最大概率值对应的预测乐器对象为样本乐器对象。
73.示例性地,所述步骤s160包括:
74.步骤s161、选取所述每个样本音频数据的所述预测结果中最大的预测概率值对应的预测乐器对象作为测试乐器对象。步骤s162、判断所述每个样本音频数据的测试乐器对象是否为所述每个样本音频数据的样本乐器对象。步骤s163、若不一致,则将所述训练目标确定为:所述每个样本音频数据的测试对象为所述每个样本音频数据的样本乐器对象。
75.具体地,每个预测概率值携带有对应的与乐器对象标识,根据乐器对象标识获取对应的预测乐器对象。例如:a为建鼓、b为应鼓、c为柷,若某个样本音频数据输出的一组预测概率值为b=0.9,b=0.5,c=0.1,其他不做举例,则表示该样本音频数据对应的测试概率值为0.9,测试乐器对象为建鼓。将测试乐器对象与样本音频数据携带的样本乐器对象进行对比,从而确定训练目标。
76.步骤s180、按照优化所述训练目标的方向,调整所述卷积神经网络识别模型的模型参数并继续训练,直至满足训练停止条件时结束训练,得到所述音频识别模型。
77.具体地,训练目标为输出的预测结果中最大概率值对应的测试乐器对象为样本乐器对象,使得样本乐器对象输出的样本概率值最大。即,若输出的最大概率值达到80%以上,将样本乐器对象的样本概率值往0.8靠拢,并拉大其他概率值与样本概率值之间的差值,以训练得到音频识别模型。
78.示例性地,所述步骤s180包括:
79.步骤s181、计算所述测试对象对应的样本概率值与所述样本乐器对象对应的预测概率值之间的误差值。步骤s182、基于所述误差值调整所述卷积神经网络识别模型的模型参数并继续训练,直至满足训练停止条件时结束训练,得到所述音频识别模型;其中,所述训练停止条件为所述误差值小于预设阈值。
80.具体地,根据误差值调整卷积神经网络识别模型的模型参数,即,调整卷积神经网
络识别模型的映射函数r,可以通过adam优化器调整模型参数。再将进行尺度变换后的样本梅尔频谱特征输入至调节后卷积神经网络识别模型中,继续训练,直至音频识别模型训练成功。
81.示例性地,训练完成后,通过测试样本集对音频识别模型进行测试,若输出正确的样本音频乐器的样本乐器对象的正确率大于95%,则不用继续进行模型参数的调整。
82.实施例二
83.参阅图3,示出了本发明实施例二之基于音频识别模型的乐器对象识别方法的步骤流程图。可以理解,本方法实施例中的流程图不用于对执行步骤的顺序进行限定。下面以计算机设备6为执行主体进行示例性描述。具体如下。
84.步骤s300、获取待识别音频数据。
85.具体地,获取待识别音频数据,待识别音频数据的格式不做限制。可以对待识别音频数据进行预处理,例如去噪处理,将背景音弱化,以提高音频识别的精确度。
86.步骤s320、基于提取参数从待识别音频数据中提取对应的目标频谱特征。
87.具体地,通过傅里叶变换函数基于提取参数对提取出每个待识别音频数据中的目标频谱特征so={si|i=1,2,3},其中,si=fft(a,wi,hi)。fft为傅立叶变换函数,将音频从时域信号转化为频域中的频率分量。在此过程中选取振幅谱作为提取到的目标特征频谱。
88.步骤s340、对每个目标频谱特征进行梅尔预处理,得到输入梅尔频谱特征。
89.示例性地,所述步骤s340包括:
90.步骤s341、对每个目标频谱特征进行梅尔尺度变换,得到对应的目标梅尔频谱特征。步骤s342、将所述目标梅尔频谱特征进行缩放处理,得到输入梅尔频谱特征。
91.具体地,目标梅尔频谱特征为对数梅尔频谱特征,将目标频谱特征进行梅尔尺度变换,得到梅尔频谱特征m=mel(s),mel操作表示梅尔尺度变换,这种变换方式可以将信号的频谱特征缩放到类人耳感知特征的坐标系统下,便于更好的进行分析与处理。然后将m转化为对数刻度,得到对数梅尔频谱特征l=log
10
(m+e),其中e=10-6
为调节系数。将目标梅尔频谱特征进行尺度变换,以得到输入梅尔频谱特征。
92.步骤s360、将所述输入梅尔频谱特征输入至音频识别模型中,以输出所述待识别音频数据的目标概率值组。
93.具体地,所述音频识别模型输出一组目标概率值,该目标概率值组中对应的概率值为25个。
94.步骤s380、从所述目标概率值组对应的乐器对象组中,确定所述待识别音频数据对应的目标乐器对象。
95.具体地,从所述概率值组中获取最大概率作为目标概率值,并获取所述目标概率值的乐器对象作为所述待识别音频数据对应的目标乐器对象。
96.实施例三
97.请继续参阅图4,示出了本发明音频识别模型的训练系统实施例三的程序模块示意图。在本实施例中,音频识别模型的训练系统40可以包括或被分割成一个或多个程序模块,一个或者多个程序模块被存储于存储介质中,并由一个或多个处理器所执行,以完成本发明,并可实现上述音频识别模型的训练方法。本发明实施例所称的程序模块是指能够完成特定功能的一系列计算机程序指令段,比程序本身更适合于描述音频识别模型的训练系
统40在存储介质中的执行过程。以下描述将具体介绍本实施例各程序模块的功能:
98.第一获取模块400,用于获取多个样本音频数据,每个样本音频数据携带有对应的样本乐器对象。
99.第一预处理模块402,用于对所述多个样本音频数据进行梅尔预处理,以得到对应的多个样本梅尔频谱特征。
100.示例性地,所述第一预处理模块402还用于:
101.构建提取参数,所述提取参数用于从所述多个样本音频数据中提取样本频谱特征;基于所述提取参数从每个所述样本音频数据中,提取每个所述样本音频数据对应的频谱特征;对每个样本频谱特征进行梅尔尺度变换,得到对应的变换梅尔频谱特征;将每个变换梅尔频谱特征进行缩放处理,得到所述样本梅尔频谱特征。
102.第一识别模块404,用于将所述多个样本梅尔频谱特征输入至预先构造的卷积神经网络识别模型中,以得到每个样本梅尔频谱特征对应的预测结果,所述预测结果包括多个预测概率值。
103.第一确定模块406,用于基于所述每个样本音频数据的所述预测结果对应的预测乐器对象与所述每个样本音频数据对应的样本乐器对象的差异确定训练目标。
104.示例性地,所述第一确定模块406还用于:
105.选取所述每个样本音频数据的所述预测结果中最大的预测概率值对应的预测乐器对象作为测试乐器对象;判断所述每个样本音频数据的测试乐器对象是否为所述每个样本音频数据的样本乐器对象;若不一致,则将所述训练目标确定为:所述每个样本音频数据的测试对象为所述每个样本音频数据的样本乐器对象。
106.调整模块408,用于按照优化所述训练目标的方向,调整所述卷积神经网络识别模型的模型参数并继续训练,直至满足训练停止条件时结束训练,得到所述音频识别模型。
107.示例性地,所述调整模块408还用于:
108.计算所述测试对象对应的样本概率值与所述样本乐器对象对应的预测概率值之间的误差值;基于所述误差值调整所述卷积神经网络识别模型的模型参数并继续训练,直至满足训练停止条件时结束训练,得到所述音频识别模型;其中,所述训练停止条件为所述误差值小于预设阈值。
109.实施例四
110.请继续参阅图5,示出了本发明乐器对象识别系统实施例四的程序模块示意图。在本实施例中,乐器对象识别系统50可以包括或被分割成一个或多个程序模块,一个或者多个程序模块被存储于存储介质中,并由一个或多个处理器所执行,以完成本发明,并可实现上述乐器对象识别方法。本发明实施例所称的程序模块是指能够完成特定功能的一系列计算机程序指令段,比程序本身更适合于描述乐器对象识别系统50在存储介质中的执行过程。以下描述将具体介绍本实施例各程序模块的功能:
111.第二获取模块500,用于获取待识别音频数据。
112.提取模块502,用于基于提取参数从待识别音频数据中提取对应的目标频谱特征。
113.示例性地,所述提取模块502还用于:
114.对每个目标频谱特征进行梅尔尺度变换,得到对应的目标梅尔频谱特征;将所述目标梅尔频谱特征进行缩放处理,得到输入梅尔频谱特征。
115.第二预处理模块504,用于对每个目标频谱特征进行梅尔预处理,得到输入梅尔频谱特征。
116.第二识别模块506,用于将所述输入梅尔频谱特征输入至音频识别模型中,以输出所述待识别音频数据的概率值组。
117.第二确定模块508,用于从所述概率值组对应的乐器对象组中,确定所述待识别音频数据对应的目标乐器对象。
118.实施例五
119.参阅图6,是本发明实施例五之计算机设备的硬件架构示意图。本实施例中,所述计算机设备6是一种能够按照事先设定或者存储的指令,自动进行数值计算和/或信息处理的设备。该计算机设备6可以是机架式服务器、刀片式服务器、塔式服务器或机柜式服务器(包括独立的服务器,或者多个服务器所组成的服务器集群)等。如图6所示,所述计算机设备6至少包括,但不限于,可通过系统总线相互通信连接存储器61、处理器62、网络接口63、音频识别模型的训练系统40以及乐器对象识别系统50。其中:
120.本实施例中,存储器61至少包括一种类型的计算机可读存储介质,所述可读存储介质包括闪存、硬盘、多媒体卡、卡型存储器(例如,sd或dx存储器等)、随机访问存储器(ram)、静态随机访问存储器(sram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、可编程只读存储器(prom)、磁性存储器、磁盘、光盘等。在一些实施例中,存储器61可以是计算机设备6的内部存储单元,例如该计算机设备6的硬盘或内存。在另一些实施例中,存储器61也可以是计算机设备6的外部存储设备,例如该计算机设备6上配备的插接式硬盘,智能存储卡(smart media card,smc),安全数字(secure digital,sd)卡,闪存卡(flash card)等。当然,存储器61还可以既包括计算机设备6的内部存储单元也包括其外部存储设备。本实施例中,存储器61通常用于存储安装于计算机设备6的操作系统和各类应用软件,例如实施例三的音频识别模型的训练系统40的程序代码、实施例四的乐器对象识别系统50的程序代码等。此外,存储器61还可以用于暂时地存储已经输出或者将要输出的各类数据。
121.处理器62在一些实施例中可以是中央处理器(central processing unit,cpu)、控制器、微控制器、微处理器、或其他数据处理芯片。该处理器62通常用于控制计算机设备6的总体操作。本实施例中,处理器62用于运行存储器61中存储的程序代码或者处理数据,例如运行音频识别模型的训练系统40,以实现实施例一的音频识别模型的训练方法,以及运行乐器对象识别系统50,以实现实施例二的乐器对象识别方法。
122.所述网络接口63可包括无线网络接口或有线网络接口,该网络接口63通常用于在所述服务器6与其他电子装置之间建立通信连接。例如,所述网络接口63用于通过网络将所述服务器6与外部终端相连,在所述服务器6与外部终端之间的建立数据传输通道和通信连接等。所述网络可以是企业内部网(intranet)、互联网(internet)、全球移动通讯系统(global system of mobile communication,gsm)、宽带码分多址(wideband code division multiple access,wcdma)、4g网络、5g网络、蓝牙(bluetooth)、wi-fi等无线或有线网络。需要指出的是,图6仅示出了具有部件20-23的计算机设备6,但是应理解的是,并不要求实施所有示出的部件,可以替代的实施更多或者更少的部件。
123.在本实施例中,存储于存储器61中的所述音频识别模型的训练系统40或者所述乐
器对象识别系统50还可以被分割为一个或者多个程序模块,所述一个或者多个程序模块被存储于存储器61中,并由一个或多个处理器(本实施例为处理器62)所执行,以完成本发明。
124.实施例六
125.本实施例还提供一种计算机可读存储介质,如闪存、硬盘、多媒体卡、卡型存储器(例如,sd或dx存储器等)、随机访问存储器(ram)、静态随机访问存储器(sram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、可编程只读存储器(prom)、磁性存储器、磁盘、光盘、服务器、app应用商城等等,其上存储有计算机程序,程序被处理器执行时实现相应功能。本实施例的计算机可读存储介质用于计算机程序,被处理器执行时实现实施例一的音频识别模型的训练方法以及实现实施例二的乐器对象识别方法。
126.上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
127.通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。
128.以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。