1.本发明涉及音乐色彩可视化技术领域,尤其是涉及一种基于音乐语义的音乐色彩可视化方法。
背景技术:
2.目前,市面上已有许多成熟的音乐可视化工具,大多数音乐播放器中也都嵌有可视化功能,这些工具通过控制图像中形状和颜色的动画效果使歌曲变得生动,丰富了歌曲的视觉效果。其中,变化的形状和颜色可以反映音频特性,例如响度,频率和节奏等。在色彩设计理论中已有许多研究对颜色和语义之间的联系进行了探索,例如,快乐的颜色通常是明亮和温暖的,而悲伤的颜色通常是黑暗和柔和的。同时,音乐也具有内在的语义含义,音乐的语义可以通过相关的文字描述(例如歌词和歌曲描述)、音乐流派(例如摇滚,朋克,电子音乐等)以及视觉设计(例如专辑封面和现场表演海报)反映出来。自然而然地联想到将音乐的语义和色彩的语义相结合进行音乐可视化。但是,大多数现有音乐可视化中使用的颜色通常是随机生成的或从预设色板中选择的,没有考虑到相关的音乐语义和视觉设计。
技术实现要素:
3.本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于音乐语义的音乐色彩可视化方法。
4.本发明的目的可以通过以下技术方案来实现:
5.一种基于音乐语义的音乐色彩可视化方法,该方法包括:
6.获取包含音乐语义的内容信息;
7.初始化色板,色板中包括多个用于表征音乐色彩的颜色;
8.对内容信息和色板中的颜色信息分别进行编码并融合生成融合编码,基于融合编码采用预先训练的色板生成模型生成对应音乐语义的色板;
9.基于色板中的颜色对音乐进行可视化。
10.优选地,所述的内容信息包括表征音乐流派的类别信息、通过图像形式表征音乐语义的图像信息、通过文字形式表征音乐语音的文字信息。
11.优选地,所述的类别信息、图像信息和文字信息对应通过类别编码器、图像编码器和文字编码器分别进行编码。
12.优选地,所述的类别编码器为独热编码器,所述的图像编码器为基于vgg16模型的编码器,所述的文字编码器为基于bert模型的编码器。
13.优选地,所述的色板中的颜色信息的编码方式为:将色板中的各个颜色的rgb值组合成向量。
14.优选地,内容信息和色板中的颜色信息分别进行编码后通过多层感知机进行融合生成融合编码。
15.优选地,生成对应音乐语义的色板时采用递归形式逐个生成色板中的每个颜色,
具体为:一次生成一个颜色,每生成一个颜色后更新色板以及对应的融合编码,基于新的融合编码生成下一个颜色,直至完成色板中所有颜色的生成。
16.优选地,所述的色板生成模型为条件对抗生成网络,包括生成器和对抗器,生成色板时,将融合编码和噪音输入至所述的生成器,经过全联接层得到生成的颜色对应的颜色编码,颜色编码与融合编码输入至对抗器判断输出是否符合预期。
17.优选地,基于色板中的颜色对音乐进行可视化的方式为:采用可视化图形展示音乐播放进度,随机采用色板中的颜色对可视化图形进行着色。
18.优选地,对音乐进行可视化时还包括歌曲频率的同步可视化展示,具体为:提取歌曲频率,改变所述的可视化图形的尺寸大小对歌曲频率进行同步可视化展示。
19.与现有技术相比,本发明具有如下优点:
20.(1)本发明基于多模态融合编码和生成对抗网络,实现了基于音乐语义信息的音乐可视化方法,能够通过融合歌曲歌词中的语义、流派信息以及视觉设计中的图形特征来丰富音乐的可视化色彩,更加生动地展示音乐作品;
21.(2)本发明使用深度学习模型将音乐的语义信息和可视化效果自动关联,省去了人工匹配的过程,提高了整个流程的效率。
附图说明
22.图1为本发明色板生成模型训练过程的框架图;
23.图2为本发明采用色板生成模型生成色板的框架图;
24.图3为本发明基于音乐语义的音乐色彩可视化方法的框架图。
具体实施方式
25.下面结合附图和具体实施例对本发明进行详细说明。注意,以下的实施方式的说明只是实质上的例示,本发明并不意在对其适用物或其用途进行限定,且本发明并不限定于以下的实施方式。
26.实施例
27.本实施例提供一种基于音乐语义的音乐色彩可视化方法,该方法包括:
28.首先,获取包含音乐语义的内容信息,内容信息包括表征音乐流派的类别信息、通过图像形式表征音乐语义的图像信息、通过文字形式表征音乐语音的文字信息,本实施例中类别信息采用音乐流派、图像信息采用歌曲封面、文字信息采用歌词。
29.然后,初始化色板,色板中包括多个用于表征音乐色彩的颜色,本实施例中色板中设置5种颜色,初始化色板时,将色板中的所有颜色的rgb值均置为0。
30.其次,对内容信息和色板中的颜色信息分别进行编码并融合生成融合编码,基于融合编码采用预先训练的色板生成模型生成对应音乐语义的色板。
31.具体地,类别信息、图像信息和文字信息对应通过类别编码器、图像编码器和文字编码器分别进行编码。类别编码器为独热编码器,图像编码器为基于vgg16模型的编码器,文字编码器为基于bert模型的编码器。色板中的颜色信息的编码方式为:将色板中的各个颜色的rgb值组合成向量。内容信息和色板中的颜色信息分别进行编码后通过多层感知机进行融合生成融合编码。生成对应音乐语义的色板时采用递归形式逐个生成色板中的每个
颜色,具体为:一次生成一个颜色,每生成一个颜色后更新色板以及对应的融合编码,基于新的融合编码生成下一个颜色,直至完成色板中所有颜色的生成。
32.色板生成模型为条件对抗生成网络,包括生成器和对抗器,生成色板时,将融合编码和噪音输入至生成器,经过全联接层得到生成的颜色对应的颜色编码,颜色编码与融合编码输入至对抗器判断输出是否符合预期。
33.最后,基于色板中的颜色对音乐进行可视化展示,具体地:采用可视化图形展示音乐播放进度,随机采用色板中的颜色对可视化图形进行着色。对音乐进行可视化时还包括歌曲频率的同步可视化展示,具体为:提取歌曲频率,改变可视化图形的尺寸大小对歌曲频率进行同步可视化展示。
34.以下具体介绍本实施例对音乐色彩可视化的具体过程。
35.一、色板生成模型的训练
36.图1显示了本项目基于条件生成对抗网络(cgan)的模型的架构。在训练时给定多模态的音乐语义色彩数据集作为训练样本,将包含音乐语义的内容信息(歌曲封面、文字描述和流派)与色板中的前一个颜色作为多模态内容信息输入给到生成器,使生成器生成色板中的下一个颜色,判别器判断所生成的颜色是否符合输入的多模态内容信息。为了训练该模型,构建了一个独特的音乐色彩数据集来训练模型,其中包含来自189个中国乐队的948张图形设计图像,以及相应的歌曲文字描述、流派类别和5色色板数据。
37.二、采用色板生成模型生成色板
38.使用色板生成模型生成色板的具体框架如图2所示,歌曲封面、歌词和流派作为输入生成的于歌词相对应的一串色板,与歌曲的频率信息作为音乐可视化的输入信息,对歌曲进行可视化。本实施例中一句歌词对应输出一串色板,从而可以实现对每句歌词的可视化展示。
39.音乐相关的视觉设计过程可被概括为选定类别、确定文字主题、色彩设计、图像设计四个步骤,其中类别、文本、图像三方面的信息与色彩相互影响、配合与制约,最终呈现出富有魅力的视觉设计效果。因此,将音乐相关的视觉设计过程的影响因素抽象成类别、文本、图像三个维度的输入信息,选用现有编码器对不同类型的数据集行编码,编码后的向量经过多层感知机(mlp)得到融合编码。在模型训练过程中,融合编码包含了歌曲所包含的视觉、文字和流派的语义信息,作为内容向量输入至接下来的cgan中。
40.在模型的使用过程中,将歌词文本按句划分,每句歌词作为单独的输入的文本向量,也就是说每首歌会由几个到几十个不等的文本向量组成。将每个文本向量与歌曲封面、歌曲类别一起经过mlp合成多模态融合编码,输入至接下来的cgan中。
41.如图2所示,歌曲的每一句歌词都对应一个文本向量,和歌曲封面、歌曲类别一起组成融合编码,也就是说,一首歌将会转化为与歌词句数相等的融合编码,输入到cgan当中。相对应的,cgan也会输出同样数量的色板结果,每个色板结果都反映了相应歌词句的音乐语义。
42.此外,每个色板中颜色的相互关系对音乐可视化中的色彩设计十分重要,因此本模型采用递归预测色板颜色的方式来生成色板。这样做的另一个好处是能够将原始数据中的每一个5色色板都扩充成5个输入数据,相当于进行了数据增强,将原本948个数据组变成了4740个数据组,大大提高了数据量,对模型训练效果会有一定提升。选用cgan搭建色板生
成网络。把包含了音乐语义信息的融合编码作为条件输入分别给至cgan中的生成器和判别器,逐一生成颜色结果并判断结果是否符合融合编码。
43.在此过程中,包含两大主要步骤,总结如下:
44.1,多模态数据编码
45.这部分采用了预训练模型和多层感知机(mlp)结合的方式完成多模态内容的特征提取和融合。
46.多模态内容包括文字、图像、类别和色板,其中前三者是用户输入的内容,色板是模型生成的结果。对于文字,采用预训练的bert模型编码为定长向量;对于图像,采用预训练的vgg16模型编码为定长向量;对于类别,采用独热编码(one hot encoding)编码为定长向量;对于色板,直接将5个rgb值组合为一个15维的向量。
47.在得到编码结果后,将这4个定长向量连接为一个向量,再将这个组合而成的向量输入到多层感知机(mlp),得到融合编码。
48.2,对每句歌词生成对应色板
49.将歌曲歌词按句拆分,每一句歌词形成一个文本向量,分别对这些文本向量进行下面的递归生成色板过程,最终得到对应的一系列色板结果。
50.递归生成色板过程基于条件生成对抗网络,采用递归的思路生成色板中的颜色。
51.其中,条件生成对抗网络的条件为上一步的融合编码,模型可以根据这个融合编码生成一个颜色(即一组r、g、b值)。
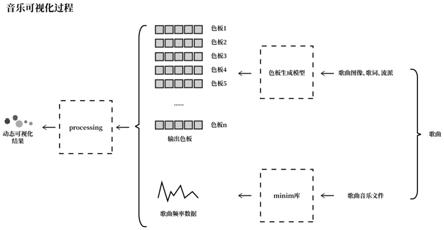
52.整个递归生成的过程如下所述:
53.1)将色板中的5个颜色全部初始化为0;
54.2)根据当前色板和用户输入生成融合编码;
55.3)把融合编码为做条件,输入cgan,生成一个颜色;
56.4)根据颜色更新色板;
57.5)重复2-4步,直到完成5个色板的生成。
58.三、可视化过程
59.可视化过程由图3展示,歌曲的图像、歌词、流派信息经过上述中的色板生成模型生成与歌词对应的色板结果,同时,歌曲的音乐文件经过声音数据处理模块minim库得到歌曲的频率数据。在图形编程软件processing中利用色板数据和歌曲频率数据对歌曲进行可视化,得到动态可视化结果。
60.频率信息可视化方法具体是:使用音频可视化组件库minim中的频率模块提取歌曲频率,取前50个频率作为x轴,并使用图形的尺寸大小表示幅度(例如,选择圆形为可视化图形,则直径可以用来表示歌曲频率的幅度)。颜色可视化部分分为有歌词与器乐两部分,有歌词部分的的图形颜色根据上一步d骤中所生成的色板数据着色,其分布随机。器乐(无歌词)部分的图形颜色由设计人员根据歌曲含义手动定义。根据歌曲的歌词时间轴,色彩和图形的变化与歌词的相应句子同步,跟随音乐播放产生动态视觉效果,形成动态音乐视频。
61.基于上述基于音乐语义的音乐色彩可视化方法,设计了相应的基于音乐语义的音乐色彩可视化系统,包括用户端和模型端,其具体业务流程为:
62.用户端:用户上传歌曲封面-》上传附带时间轴的歌曲歌词-》选择音乐流派-》得到跟随音乐语义和频率变化的动态可视化视频结果
63.模型端:用户上传图片、附带时间轴的字符串、选择歌曲流派类别-》对附带时间轴的字符串进行处理,得到时间点数组和分句歌词-》多模态内容编码模型生成每一句歌词所对应的融合编码-》色板生成模型根据融合编码递归生成每句歌词对应的色板-》以歌曲频率的幅度和色板结果进行可视化编程-》输出跟随音乐语义和频率变化的动态可视化视频。
64.上述实施方式仅为例举,不表示对本发明范围的限定。这些实施方式还能以其它各种方式来实施,且能在不脱离本发明技术思想的范围内作各种省略、置换、变更。