1.本发明涉及一种分类方法,具体是一种电子病历文本分类方法,属于自然语言处理应用到医疗电子病例技术领域。
背景技术:
2.文本分类是指建立文本与类别之间的关系模型,作为自然语言处理的基础性任务之一,在情感分析、社交平台舆论监测、垃圾邮件识别等方面都具有重大意义。文本分类的主要算法模型,基本上可分为三类:第一类是基于规则、第二类是基于统计和机器学习、第三类是基于深度学习的方法。
3.第一类基于规则的方法借助于专业人员的帮助,为预定义类别制定大量判定规则,与特定规则的匹配程度作为文本的特征表达,但是受限于人为主观性、规则模板的全面性和可扩展性,最主要的是规则模板完全不具备可迁移性,所以基于规则制定进行文本分类模型并没有得到有效的进展。
4.第二类基于统计和机器学习的文本分类算法主要包括决策树法(decision tree,dt)、朴素贝叶斯算法(naive bayesian,nb)、支持向量机算法(svm)、k-邻近法(k-nearest neighbors,knn)等算法。机器学习模型虽然一定程度上提高了文本分类的效果,但是仍需要人为的进行特征选择与特征提取,忽略了特征之间的关联性,通用性以及扩展性较差。
5.第三类基于深度学习的文本分类算法主要包括卷积神经网络(convolutional neural networks,cnn)、循环神经网络(recurrent neural network,rnn)、长短期记忆神经网络(long short-term memory,lstm)等,以及各类神经网络模型的变种融合;随着词向量模型的引入,可以将词序列转换为低维稠密的词向量,并包含丰富的语义信息,使得神经网络模型在文本分类任务得到广泛应用。注意力机制的引入,更加有效的对神经网络输出进行特征筛选与特征加权,降低噪声特征的干扰,获取文本的重要特征。目前应用神经网络组合模型的电子病历文本分类,受限于电子病历高维稀疏的文本特征、文本术语密集、语句成分缺失等问题,会造成模型收敛速度较慢、分类效果不佳的问题。
技术实现要素:
6.本发明的目的是提供一种电子病历文本分类方法,能够统筹电子病历文本数据集的局部和全局文本特征,具备较好的稳定性和鲁棒性,有效的提升电子病历文本分类模型的效果。
7.为了实现上述目的,本发明提供一种电子病历文本分类方法,包括以下步骤:
8.步骤1:对原始电子病历文本数据集进行预处理操作,包括句子分词、去除停用词、低频词,从而形成含有文本条目的原始语料库;
9.步骤2:将原始语料库转换为包括词编号与词的词表t1,利用词向量工具训练词表t1,将词训练表示为低维稠密的词向量,形成包含词编号和词向量的词表t2;
10.步骤3:利用步骤2中的词表t1将步骤1的原始语料库的文本条目转换为词编号序
列,再利用步骤2中的词表t2将步骤1的原始语料库的文本条目转换为词向量序列;
11.步骤4:利用步骤3所得的词向量序列作为并行结构的cnn-attention神经网络和bilstm-attention神经网络的输入,训练文本特征向量;
12.步骤5:拼接步骤4中cnn-attention神经网络和bilstm-attention神经网络的输出,作为神经网络的整体输出;
13.步骤6:连接两个全连接层对步骤5的整体输出进行降维,并使用softmax分类器计算文本所属标签类别的概率,直接输出文本类别的预测结果。
14.本发明针对原始语料库的任意句子s,结合所述的词表t1与词表t2,得到s在词表t1的转换下为词编号序列s1=(x1,x2,
…
,xn),在词表t2的转换下为词向量序列s2=(w1,w2,
…
,wn),其中,xi是词,wi是对应的词向量。
15.本发明的cnn-attention神经网络采用三层并行式结构,对于词向量序列s2=(w1,w2,
…
,wn)的输入,三层并行式结构中每层输出分别为c1、c2与c3,则对于三层并行式结构的整体输出c表示为:
16.c=concatenate([c1,c2,c3],axis=-1)
[0017]
其中,concatenate表示concatenate()函数,axis表示维度拼接的方式。
[0018]
本发明采用attention机制对三层并行式结构的整体输出c进行特征加权,计算注意力权重得分,并使用softmax函数对注意力权重得分计算权重向量a,对于词向量序列s2=(w1,w2,
…
,wn)的任意位置词向量wi,将对应的权重向量ai与输出向量ci进行点乘与累加,形成cnn-attention神经网络的输出att
cnn
:
[0019][0020]
本发明的bilstm-attention神经网络采用双向lstm神经网络,对于词向量序列s2=(w1,w2,
…
,wn)的输入,对于s2=(w1,w2,
…
,wn)的任意位置的词向量wi,单向lstm神经网络进行文本特征训练可获得输出,则bilstm神经网络的输出h由双向lstm神经网络的输出拼接得到:
[0021][0022]
本发明采用attention机制对bilstm神经网络的输出h进行特征加权,计算注意力权重得分,并使用softmax函数对注意力权重得分计算权重向量b,对于词向量序列s2=(w1,w2,
…
,wn)的任意位置的词向量wi,将对应的权重向量bi与输出向量hi进行点乘与累加,形成bilstm-attention神经网络的输出att
bilstm
:
[0023][0024]
结合cnn-attention神经网络的输出att
cnn
和bilstm-attention神经网络的输出att
bilstm
,则双通道神经网络的整体输出output表示为:
[0025]
output=concatenate([att
cnn
,att
bilstm
],axis=1)。
[0026]
本发明采用softmax分类器计算文本所属标签类别的概率,对于词编号序列s1=(x1,x2,
…
,xn),对于任意xi所在的原始语料库中的句子s,模型整体上计算句子s所属标签概率的损失函数loss可表示为:
[0027][0028]
其中,为softmax函数计算得到标签概率的归一化,y为真实标签分布的概率。
[0029]
本发明的词向量工具为word2vec,默认skip-gram模型。
[0030]
与现有技术相比,本发明首先对原始电子病历文本数据集进行预处理操作,从而形成原始语料库,通过词向量工具word2vec训练原始语料库,默认skip-gram模型,得到低维稠密的词向量,然后将文本数据集的每条数据以词编号的形式,对应转换为词向量序列作为输入,以cnn-attention神经网络和bilstm-attention神经网络的双通道结构训练文本特征向量,再将双通道结构的输出进行拼接,作为神经网络的总体输出,最后使用softmax分类器计算文本所属标签类别的概率;本发明提取了文本的局部特征和上下文关联信息,然后以注意力机制对各通道的输出信息进行特征加权,凸显特征词在上下文信息的重要程度,最后将输出结果进行融合,获取更为全面的文本特征,互补了cnn和bilstm提取特征的缺点,有效的缓解了因cnn丢失词序信息和bilstm处理文本序列的梯度问题;本发明能够统筹电子病历文本数据集的局部和全局文本特征,具备较好的稳定性和鲁棒性,有效的提升电子病历文本分类模型的效果。
附图说明
[0031]
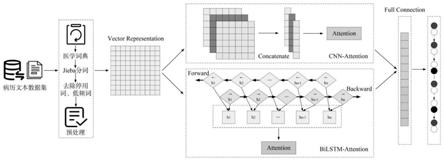
图1是本发明的流程图。
具体实施方式
[0032]
下面结合附图对本发明作进一步说明。
[0033]
如图1所示,一种电子病历文本分类方法,包括以下步骤:
[0034]
步骤1:对原始电子病历文本数据集进行预处理操作,包括句子分词、去除停用词、低频词,从而形成包含文本条目的原始语料库;
[0035]
步骤2:将原始语料库转换为包括词编号与词的词表t1,通过词向量工具word2vec训练原始语料库,默认skip-gram模型,得到低维稠密的词向量,训练词表t1,将词训练表示为低维稠密的词向量,形成包含词编号和词向量的词表t2;
[0036]
步骤3:利用步骤2中的词表t1将步骤1的原始语料库的文本条目转换为词编号序列,再利用步骤2中的词表t2将步骤1的原始语料库的文本条目转换为词向量序列;
[0037]
步骤4:利用步骤3所得的词向量序列作为并行结构的cnn-attention神经网络和bilstm-attention神经网络的输入,训练文本特征向量;
[0038]
步骤5:拼接步骤4中cnn-attention神经网络和bilstm-attention神经网络的输出,作为神经网络的整体输出;
[0039]
步骤6:连接两个全连接层对步骤5的整体输出进行降维,并使用softmax分类器计算文本所属标签类别的概率,直接输出文本类别的预测结果。
[0040]
实施例
[0041]
首先,收集并构造原始电子病历文本数据集,实验数据集来自徐州医科大学附属医院真实电子病历文本,对数据集进行脱敏处理后,从入院记录、病程记录与诊疗计划等方面,合理筛选包含疾病与诊断、症状与体征与治疗方面的1000条病历描述句,包含500条糖
尿病数据与500条帕金森病数据。
[0042]
对于原始电子病历数据集,首先利用jieba分词模块以精确模式对文本序列进行分词处理,在分词任务结束后,结合停用词表遍历分词结果,去除停用词,形成原始语料库。
[0043]
将原始语料库转换为词表t1,包括词编号与词,利用word2vec词向量工具训练词表t1,默认skip-gram模型,将词训练表示为低维稠密的词向量,形成词表t2,包含词编号和词向量。
[0044]
针对原始语料库的任意句子s,结合所述的词表t1与词表t2,得到s在词表t1的转换下为词编号序列s1=(x1,x2,
…
,xn),在词表t2的转换下为词向量序列s2=(w1,w2,
…
,wn),其中,xi是词,wi是对应的词向量。
[0045]
本发明的cnn-attention神经网络采用三层并行式结构,对于词向量序列s2=(w1,w2,
…
,wn)的输入,三层并行式结构中每层输出分别为c1、c2与c3,则对于三层并行式结构的整体输出c表示为:
[0046]
c=concatenate([c1,c2,c3],axis=-1)
[0047]
其中,concatenate表示concatenate()函数,axis表示维度拼接的方式。
[0048]
本发明采用attention机制对三层并行式结构的整体输出c进行特征加权,计算注意力权重得分,并使用softmax函数对注意力权重得分计算权重向量a,对于词向量序列s2=(w1,w2,
…
,wn)的任意位置词向量wi,将对应的权重向量ai与输出向量ci进行点乘与累加,形成cnn-attention神经网络的输出att
cnn
:
[0049][0050]
本发明的bilstm-attention神经网络采用双向lstm神经网络,对于词向量序列s2=(w1,w2,
…
,wn)的输入,对于s2=(w1,w2,
…
,wn)的任意位置的词向量wi,单向lstm神经网络进行文本特征训练可获得输出,则bilstm神经网络的输出h由双向lstm神经网络的输出拼接得到:
[0051][0052]
本发明采用attention机制对bilstm神经网络的输出h进行特征加权,计算注意力权重得分,并使用softmax函数对注意力权重得分计算权重向量b,对于词向量序列s2=(w1,w2,
…
,wn)的任意位置的词向量wi,将对应的权重向量bi与输出向量hi进行点乘与累加,形成bilstm-attention神经网络的输出att
bilstm
:
[0053][0054]
结合cnn-attention神经网络的输出att
cnn
和bilstm-attention神经网络的输出att
bilstm
,则双通道神经网络的整体输出output表示为:
[0055]
output=concatenate([att
cnn
,att
bilstm
],axis=1)。
[0056]
本发明采用softmax分类器计算文本所属标签类别的概率,对于词编号序列s1=(x1,x2,
…
,xn),对于任意xi所在的原始语料库中的句子s,模型整体上计算句子s所属标签概率的损失函数loss可表示为:
[0057][0058]
其中,为softmax函数计算得到标签概率的归一化,y为真实标签分布的概率。
[0059]
本发明实验软件环境为window10操作系统,python3.6编程语言,深度学习框架tensorflow1.14.0,keras2.2.5,分词工具jieba0.42;电子病历文本数据集采用交叉验证的方式进行实验,按照3:1:1的比例划分训练集、验证集与测试集;常采用精确率(preciscion,p)、召回率(recall,r)及f1值(f-measure)作为评价文本分类模型性能的指标:
[0060][0061][0062][0063]
其中,tp为正确文本预测为正确类别数目;fp为错误文本预测为正确类数目,fn为正确文本预测为错误类数目,f1值即为精确率与召回率的调和平均值。
[0064]
为了验证本发明所提方法的有效性,设置了四组对比实验:
[0065]
(1)cnn-attention:先利用cnn提取输入序列的局部特征,attention机制对文本特征进行特征加权,降低噪声特征对分类效果的影响;
[0066]
(2)bilstm-attention:bilstm对输入序列构造前后文语义信息,提取病历文本的高层特征,attention机制对文本特征进行特征加权,降低噪声特征对分类效果的影响;
[0067]
(3)cnn-bilstm-attention:先利用cnn提取输入序列的局部特征,再利用bilstm提取cnn输出的前后向语义信息,进一步构建病历文本的特征表达,然后使用attention机制对文本特征进行特征加权,降低噪声特征对分类效果的影响。
[0068]
(4)本发明的分类方法
[0069]
经多轮实验,并对实验结果进行交叉验证,各类方法的模型评价结果如下表所示,
[0070]
表1四种不同方法模型的文本分类结果(单位:%)
[0071]
模型精确率p召回率rf1值(1)96.8296.6896.75(2)95.0994.9295.00(3)98.0297.7897.90(4)98.8498.8798.85
[0072]
通过上表的实验结果可以得出,本发明的分类方法在评价指标结果中取得了最优异的效果,由此可以得到本发明分类方法在文本分类任务中的优越性。