1.本发明涉及计算机领域,具体涉及一种实时语音分离语音转写的方法。
背景技术:
2.在类似保险、银行柜台具有固定位置的服务对话场景中,需要在略微吵杂的环境中,对双方的对话进行有效的记录;现有的桌面指向拾音产品,只能对其使用者,即使用人进行近场拾音,无法同时获得对话中对人的语音,若场景中存在多人说话,需布局多个近场的拾音设备,且离说话人非常近,通常在20公分以内。本方法可以通过放在桌面端的麦克风阵列拾音器,实时判断分离不同方向的多个人声,并实时按多个不同角色,输出为对应的文本信息,该方法可有效的应用于多人讲话、同时讲话、移动讲话的多种不同场景。
3.远场使用场景中,复杂的噪声环境严重影响了语音转写的正确率,本发明可有效抑制使用环境中的噪音影响,包含环境噪音和其他非目标说话人的声音。
4.远场多人对话场景中,受复杂的噪声的影响,且对话场景中抢话,插话导致连续语音中多人的话术,本发明可实时有效的分离对话场景的多说话人语音,进行有效转写。
技术实现要素:
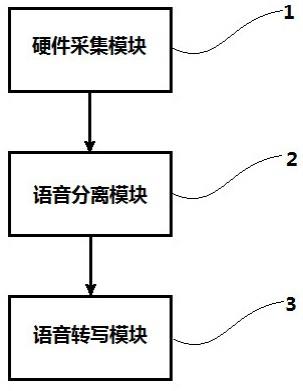
5.本发明提供一种实时语音分离语音转写的方法,通过硬件采集模块,得到多路麦克风的数字信号,经过语音分离模块对多说话人进行声源定位后对固定方向的声源成形,形成说话方向的滤波后的语音信号,进一步消除非目标方向的语音和干扰信号,然后语音转写模块把固定方向的语音信号转化为文字内容。
6.为了达到上述目的,本发明提供如下技术方案:一种实时语音分离语音转写的方法,包括:通过硬件采集模块对多人说话的声音采集,并得到多路麦克风的数字信号;通过语音分离模块将所述数字信号分离出多个单人的语音信号;将各个所述语音信号分别接入语音转写模块,转写成对应每个说话人的文字内容。
7.优选的,所述采集模块包含多个麦克风拾音模组;各个所述麦克风拾音模组的采样率为16khz的数字信号。
8.优选的,所述语音分离模块由doa声源定位、fixed beamformer固定方向波束成形,post filter后处理滤波器及post separator后处理时域分离器构成。
9.优选的,所述doa声源定位采用gws-srp-phat方法:第一步、先计算srp-phat得到每一帧的原始doa输出记为doa_peak_raw,同时对不同频率进行加权,用以平衡不同频率的空间谱分辨率和麦克风间距,提高doa精度,按5度为间隔,扫描0-360度srpout最大值为目前doa_peak_energy和doa_peak;第二步、对doa_peak进行中值滤波器平滑滤波得到doa_smooth,结合语音学和经验值设定,中值滤波器长度为h,当前时刻t,doa_smooth为中值滤波器的输出,即窗口h内排
序后的中值doa_smooth;第三步、为按指定的目标方向角doa_target和波束范围doa_beam,得到fixed beamformer的输入导向矢量doa_target_bf,同时输出平滑doa_smooth。
10.优选的,所述fixed beamformer固定方向波束成形通过采用modified tf-gsc结构分别输出目标说话方向空间滤波后的语音信号。
11.优选的,所述tf-gsc由fixed beamformer固定波束成形、blocking matrix矩塞矩阵、multichannel adaptive interference canceller构成;所述blocking matrix矩塞矩阵采用自适应滤波器adaptive blocking matrix,自适应滤波器adaptive blocking matrix和multichannel adaptive interference canceller 滤波器更新策略,本方法使用adaptive interference canceller
ꢀ‑
adaptive blocking matrix controller跟踪各自输入输出的后验信噪比变化,来判定目标方向和非目标方向是否包含语音,来控制两组滤波器是否更新。
12.优选的,所述post filter采用map-based后处理滤波器。
13.优选的,所述post filter后处理滤波器采用为后验信噪比作为随机变量,定义,复合高斯分布定义先验信噪比,as为modified tf-gsc输出,an为modified tf-gsc abm模块的输出,,为经验超参,,为高斯分布均值和方差,估计后处理滤波器的系数,进一步形成目标方向固定波束,消除残余方向的干扰信号。
14.优选的,所述post separator包含:相似度,pitch filter,doa_guide,窗口能量;预定义的输出的说话人数量为n_spk所述相似度为n_spk路分离信号的窗口的coherence,即谱相似度;所述pitch filter用于分别估计n_spk路语音信号的pitch差是否在预定义的delta-pitch内,即n_spk的基频是否相似;所述doa_guide用于同步判断窗口内当前帧属于n_spk路说话人的比例,予以加权。
15.本发明有益效果为:通过上述设置,本发明中硬件采集模块的麦克风拾音模组可方便、便捷的部署在柜台或桌面的任意位置采集语音信号,仅需配置角度参数;本发明语音分离模块可实时、有效的将多人对话按说话人分离,进行实时语音转写;同时,本发明中语音分离模块可有效降低环境噪声的干扰,包含环境噪音和其他非目标说话人的声音,对固定方向的声源进行转写,从而可有效的分离重叠的对话语音,进行有效的语音转写。
附图说明
16.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
17.图1为本发明应用方式示意图;图2为本发明局部工作示意图;图3为本发明modified tf_gsc结构示意图。
具体实施方式
18.下面将结合本发明的附图,对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
19.根据图1、图2中的流程步骤所示,一种实时语音分离语音转写的方法,包括:通过硬件采集模块对多人说话的声音采集,并得到多路麦克风的数字信号;通过语音分离模块将所述数字信号分离出多个单人的语音信号;将各个所述语音信号分别接入语音转写模块,转写成对应每个说话人的文字内容;所述采集模块包含多个麦克风拾音模组;各个所述麦克风拾音模组的采样率为16khz的数字信号。
20.在这里所述的硬件采集模块中的麦克风拾音模组以固定的角度进行排列,通过对环境中的说话人的语音进行采集,得到n_mic路(麦克风数量)麦克风模拟电信号,所述的麦克风拾音模组可以在会议桌或者银行柜台前进行摆放,对说话人位置进行预估,配置角度参数进行摆放,可有效对各个角度的说话人的语音进行有效采集,采集语音之后进过模拟数字转化,转化为n_mic路采样率为16khz的数字语音信号,为之后的数字信号域算法做出准备。
21.所述语音分离模块由doa声源定位、fixed beamformer固定方向波束成形,post filter后处理滤波器及post separator后处理时域分离器构成。
22.所述doa声源定位采用gws-srp-phat方法:第一步、先计算srp-phat得到每一帧的原始doa输出记为doa_peak_raw,同时对不同频率进行加权,用以平衡不同频率的空间谱分辨率和麦克风间距,提高doa精度,按5度为间隔,扫描0-360度srpout最大值为目前doa_peak_energy和doa_peak;第二步、对doa_peak进行中值滤波器平滑滤波得到doa_smooth,结合语音学和经验值设定,中值滤波器长度为h,当前时刻t,doa_smooth为中值滤波器的输出,即窗口h内排序后的中值doa_smooth;第三步、为按指定的目标方向角doa_target和波束范围doa_beam,得到fixed beamformer的输入导向矢量doa_target_bf,同时输出平滑doa_smooth。
23.利用guided-weighted-smoothed-srp-phat方法,先计算spr-phat得到每一帧(8ms)的原始doa输出记为doa_peak_raw,之后对不同频率进行加权,用以平衡不同频率的空间谱分辨率和麦克风间距,提高doa精度,按5度为间隔,扫描0-360度sprout最大值为目
前doa_peak_energy和doa_peak。
24.首先计算srp-phat,得到每一帧(8ms)的原始doa输出记为doa_peak1,记麦克风为p,q,则p,q,则p,q,则为srp是所有麦克风两两组合的gcc之和,令:srp值在t时刻和波达方向相关,相关,相关,对不同频率进行加权,用以平衡不同频率的空间分辨率和麦克风间距,提高doa精度;按每5度为间隔,扫描0-360度srpout最大值为目前doa_peak_energy和doa_peak。
25.对doa_peak进行中值滤波,平滑滤波得到doa_smooth,结合语音学和经验值设定中值滤波长度为h,当前时刻t,doa_smooth为中值滤波的输出,即窗口h内排序后的中值,得到doa_smooth=median_filter(即doa_peak)。
26.按指定的目标方向角doa_target和波束范围doa_beam,得到fixed beamformer的输入导向矢量doa_target_bf;同时输出平滑doa_smooth,通过if abs(doa_smooth
ꢀ–
doa_target)《doa_beam or 360
–
abs(doa_smooth-doa_target)》180:doa_target_bf=doa_smoothelse:doa_target_bf=doa_targetdoa_smooth=doa_smooth用于估计doa是不是在预设的范围内,其中abs为取绝对值运算符。
27.对输出的平滑doa_smooth使用固定方向波束成形,分别输出目标方向空间滤波后的语音数字信号。
28.所述fixed beamformer固定方向波束成形通过采用modified tf-gsc结构分别输
出目标说话方向空间滤波后的语音信号。所述tf-gsc由fixed beamformer固定波束成形、blocking matrix矩塞矩阵、multichannel adaptive interference canceller构成;所述blocking matrix矩塞矩阵采用自适应滤波器adaptive blocking matrix,自适应滤波器adaptive blocking matrix和multichannel adaptive interference canceller 滤波器更新策略,本方法使用adaptive interference canceller-adaptive blocking matrix controller跟踪各自输入输出的后验信噪比变化,来判定目标方向和非目标方向是否包含语音,来控制两组滤波器是否更新。固定波束采用modified tf_gsc结构。如图3所示:tf_gsc由fixed beamformer固定波束成形(简称fb)、blocking matrix矩塞矩阵(简称bm矩塞矩阵)、multichannel adaptive interference canceller构成(简称multichannel aic,多通道自适应相消器)bm采用自适应滤波器 adaptive bm(简称abm),同时使用aic-abm controller跟踪后验信噪比变化,来控制两组滤波器是否更新,分别输出目标说话方向空间滤波后的语音数字信号。
29.所述post filter采用map-based后处理滤波器,map即maximum a posteriori estimation 最大后验估计;所述post filter后处理滤波器采用为后验信噪比作为随机变量,定义,复合高斯分布定义先验信噪比,as为modified tf-gsc输出,an为modified tf_gsc abm模块的输出,,为经验超参,,为高斯分布均值和方差,估计后处理滤波器的系数,进一步形成目标方向固定波束,消除残余方向的干扰信号。
30.所述post separator包含:相似度,pitch filter,doa_guide,窗口能量;预定义的输出的说话人数量为n_spk所述相似度为n_spk路分离信号的窗口的coherence,即谱相似度;所述pitch filter用于分别估计n_spk路语音信号的pitch(基频)差是否在预定义的delta-pitch内,即n_spk的基频是否相似;所述doa_guide用于同步判断窗口内当前帧属于n_spk路说话人的比例,予以加权。
31.post separator的增益表示为:if spk1能量》spk2能量+delta_energy;mask_spk2=trueelse if:spk1能量《spk2 能量+delta_energymask_spk1=trueelse:if coherence》coherence_thresnhold and pitch差《delta-pitch:
if doa_guide=spk2:mask_spk1 =trueelse if doa_guide=spk1:mask_spk2=true利用post separator的增益估计n_spk(输出说话人数量)路分离信号的相似度,利用mask计算时域信号上生成遮掩滤波器,进一步消除残留干扰。
32.最后利用语音转写模块对消除残留干扰后的n_spk路分离语音数字信号分别进行转写,所述语音转写模块可以为每一路的数字语音信号分别转写为文字内容,不会对各路语音信号的干扰内容进行转写或者不区分进行转写,能够在多人会议的时候有效对每一位发言者进行单独的转写以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。