1.本发明涉及一种训练基于htk语音模型的方法。
背景技术:
2.语音模型训练是语音识别系统的功能模块。为了便于嵌入式语音识别中语音模型的开发,语音识别系统在开发前期,根据提供的语音样本文件完成语音模型的训练,生成基于c语言的语音模型。现有的手动编辑htk训练工具需要的输入文件和调用htk训练工具,造成了语音模型训练速度慢、步骤繁琐、易出错的问题,无法满足快速更换嵌入式语音识别系统中语音模型的需求。
技术实现要素:
3.本发明提供一种训练基于htk语音模型的方法。
4.本发明提供一种训练基于htk的语音模型方法,包括:
5.采用编写相应脚本处理基于htk的训练工具需要的输入文件,运行cmd命令调用训练步骤中需要的基于htk的训练工具,顺序将脚本文件执行命令和基于htk训练工具的调用命令写入批处理文件。
6.进一步的,上述方法中,采用编写相应脚本处理基于htk的训练工具需要的输入文件,运行cmd命令调用训练步骤中需要的基于htk的训练工具,顺序将脚本文件执行命令和基于htk训练工具的调用命令写入批处理文件,包括:
7.运用脚本生成基于htk训练工具需要的输入文件,顺序调用脚本文件执行命令和htk工具包的调用命令,自动完成训练语音模型功能。
8.进一步的,上述方法中,运用脚本生成基于htk训练工具需要的输入文件,顺序调用脚本文件执行命令和htk工具包的调用命令,自动完成训练语音模型功能,包括:
9.编写脚本,以完成原来的手动操作步骤;
10.基于编写的脚本,批处理完成自动化模型训练。
11.进一步的,上述方法中,编写脚本,以完成原来的手动操作步骤,包括:
12.第一步:编写grammar.py脚本,执行生成基于htk训练工具hparse的输入文件grammar,运行基于htk的训练工具hparse生成wordnet,完成源文件转换成词网络;
13.第二步:编写wordlist.py和beep.py脚本,执行生成基于htk训练工具hdman的输入文件wordlist和beep,运行基于htk训练工具hdman完成字典的生成;
14.第三步:调用基于htk训练工具中的perl脚本,执行生成基于htk工具的hled的输入文件trainwords.mlf和trainprompts,运行基于htk训练工具hled生成发音序列;
15.第四步:编写codetrain.py脚本,执行生成基于htk训练工具hcopy的输入文件codetrain.scp,运行基于htk训练工具hcopy完成语音样本特征参数的生成;
16.第五步:执行基于htk训练工具hcompv生成hmm初始化模型;
17.第六步:执行基于htk训练工具herest训练多次模型,编写脚本处理在多次训练过
程中需要手动操作的步骤,完成循环过程的自动化;
18.第七步:编写脚本,将hmm语言模型文件转换成嵌入式语音识别系统中的基于c语言的语音模型。
19.进一步的,上述方法中,基于编写的脚本,批处理完成自动化模型训练,包括:
20.第八步:初始化脚本运行环境;
21.第九步:执行运行脚本命令,将训练模型过程中手动处理文件过程转成自动化处理过程;
22.第十步:第九步生成的文件作为本步的输入文件,调用相应的基于htk训练工具,输出语音模型训练需要的过程中间文件;
23.第十一步:根据模型训练过程步骤循环执行第九步和第十步,直到生成语言模型文件;
24.第十二步:执行脚本命令生成嵌入式识别系统中基于c语言的语音模型。
25.与现有技术相比,本发明取得了如下有益效果:
26.本发明首次采用脚本自动化处理语音模型训练中的手动操作过程,通过脚本文件的顺序执行将手动操作过程转化成了自动操作过程,降低了手动编辑输入文件过程中的错误率。
27.另外,本发明首次采用批处理语音模型训练的整个过程,将自动处理输入文件的脚本执行命令与调用基于htk训练工具的调用命令集顺序写入批处理文件,完成了语音模型训练的全自动化的过程,提高了训练模型的效率。
附图说明
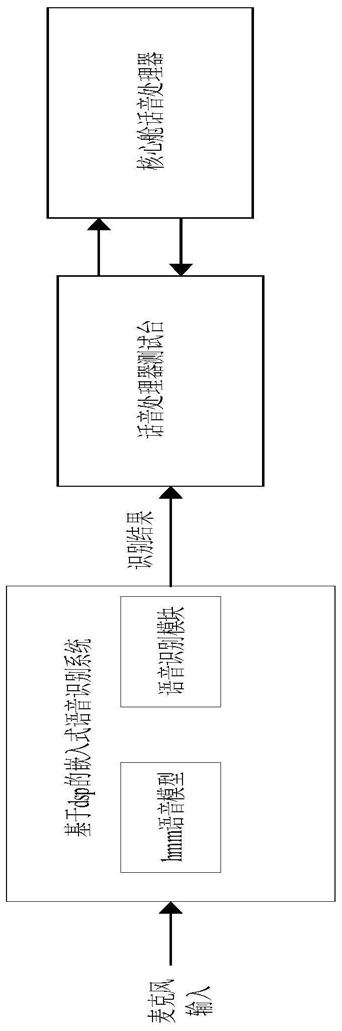
28.图1是本发明一实施例的语音模型运行环境的示意图;
29.图2是本发明一实施例的训练语音模型流程图;
30.图3是本发明一实施例的批处理操作流程图。
具体实施方式
31.下面结合附图对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式,但本发明的保护范围不限于下述的实施例。
32.如图2和3所示,本发明提供一种训练基于htk的语音模型方法,其特征在于,包括:
33.采用编写相应脚本处理基于htk的训练工具需要的输入文件,运行cmd命令调用训练步骤中需要的基于htk的训练工具,顺序将脚本文件执行命令和基于htk训练工具的调用命令写入批处理文件。
34.在此,针对训练样本多、训练语音模型步骤繁琐,且每一步需要手动编辑大量中间文件易出错的实际情况,该训练方式采用编写相应脚本处理基于htk的训练工具需要的输入文件,运行cmd命令调用训练步骤中需要的基于htk的训练工具,顺序将脚本文件执行命令和基于htk训练工具的调用命令写入批处理文件,实现了语音模型训练的自动化。
35.本发明针对手动训练语音模型速度慢、步骤繁琐、易出错的情况,研究了一种自动化训练语音模型的方法。通过该脚本处理手动步骤,串行执行操作命令的批处理方法可以高效自动生成嵌入式语音识别系统需要的语音模型,提高了开发语音识别系统的速度。
36.本发明的训练基于htk的语音模型方法一实施例中,采用编写相应脚本处理基于htk的训练工具需要的输入文件,运行cmd命令调用训练步骤中需要的基于htk的训练工具,顺序将脚本文件执行命令和基于htk训练工具的调用命令写入批处理文件,包括:
37.运用脚本生成基于htk训练工具需要的输入文件,顺序调用脚本文件执行命令和htk工具包的调用命令,自动完成训练语音模型功能。
38.本发明的训练基于htk的语音模型方法一实施例中,运用脚本生成基于htk训练工具需要的输入文件,顺序调用脚本文件执行命令和htk工具包的调用命令,自动完成训练语音模型功能,包括:
39.编写脚本,以完成原来的手动操作步骤;
40.基于编写的脚本,批处理完成自动化模型训练。
41.在此,本发明的一种自动化训练基于htk语音模型的方法是根据嵌入式语音系统需要依据设计需求更换语音模型的实际情况,采用脚本处理训练模型中需要手动操作的步骤,并顺序将执行过程转化成操作命令写入批处理文件,完成自动化处理过程,提高了模型训练的速度。
42.具体的,训练基于htk的语音模型方法包含了如下两个部分:
43.第一部分、编写脚本,以完成原来的手动操作步骤方法:
44.第一步:编写grammar.py脚本,执行生成基于htk训练工具hparse的输入文件grammar,运行基于htk的训练工具hparse生成wordnet,完成源文件转换成词网络;
45.第二步:编写wordlist.py和beep.py脚本,执行生成基于htk训练工具hdman的输入文件wordlist和beep,运行基于htk训练工具hdman完成字典的生成;
46.第三步:调用基于htk训练工具中的perl脚本,执行生成基于htk工具的hled的输入文件trainwords.mlf和trainprompts,运行基于htk训练工具hled生成发音序列;
47.第四步:编写codetrain.py脚本,执行生成基于htk训练工具hcopy的输入文件codetrain.scp,运行基于htk训练工具hcopy完成语音样本特征参数的生成;
48.第五步:执行基于htk训练工具hcompv生成hmm初始化模型;
49.第六步:执行基于htk训练工具herest训练多次模型,编写脚本处理在多次训练过程中需要手动操作的步骤,完成循环过程的自动化;
50.第七步:编写脚本,将hmm语言模型文件转换成嵌入式语音识别系统中的基于c语言的语音模型;
51.第二部分、批处理完成自动化模型训练的方法:
52.第八步:初始化脚本运行环境;
53.第九步:执行运行脚本命令,将训练模型过程中手动处理文件过程转成自动化处理过程;
54.第十步:第九步生成的文件作为本步的输入文件,调用相应的基于htk训练工具,输出语音模型训练需要的过程中间文件;
55.第四步:根据模型训练过程步骤循环执行第九步和第十步,直到生成语言模型文件;
56.第五步:执行脚本命令生成嵌入式识别系统中基于c语言的语音模型。
57.在此,通过脚本可快速完成基于htk训练工具生成hmm模型需要的输入文件。将脚
本文件执行命令和基于htk训练工具调用命令顺序写入批处理文件。运行批处理文件自动化完成整个语音模型的训练,大大提高了语音模型训练速度,降低了训练过程中因为手动编辑文件出现的低级错误,将训练过程串联化。
58.图1为语音模型运行环境。图1所示,本实施例结果运行在语音处理器的地测设备环境中。根据话音处理器测试台的指令需求,选取200个语音样本进行自动化模型训练,训练的基于c语言的语音模型移植到基于dsp的嵌入式语音识别系统中。麦克风输入语音命令,嵌入式语音识别系统将识别结果通过网络接口传给话音处理器测试台,测试台根据指令执行相应操作测试核心舱话音处理器,实现了对核心舱话音处理器的自动化测试。
59.以上应用了具体个例对本发明进行阐述,并不用以限制本发明。