1.本发明涉及音频处理领域,尤其涉及一种噪声消除装置及其检测方法。
背景技术:
2.目前处理语音噪声大多数采用基于深度学习的算法,这种语音降噪方法主要分为两个类:一种是基于tf时频域的方法,包括基于mask和非基于mask的方法;另一种是基于时域的方法。但是基于深度学习的算法需要的前置学习过程很长,所需的计算量极大,且不能直接应用于全部场景的语音降噪。
3.cn101903942b提供了一种噪声消除系统,其用于生成待被添加至期望信号以减轻环境噪声的影响的噪声消除信号。检测器适于检测所述输入信号在所述无语音期内的量值;当所述输入信号处于一阈值以上时在第一模式下运行,当所述输入信号处于该阈值以下时在第二模式下运行。
4.cn111095405a提供了噪声消除算法的动态选择以及麦克风的动态激活和去激活,以在环境噪声阻止话音导航准确地解释话音命令的情况下为话音检测装置提供多模式噪声消除。当检测到超过阈值的环境噪声时,选择最适合于该情况的特定噪声消除算法,并且激活一个或多个噪声检测麦克风。接收到最高水平的环境噪声的(多个)噪声检测麦克风可以保持激活,而其余噪声检测麦克风可以被去激活。然后,可以通过使用所选噪声消除算法消除从已激活的(多个)噪声检测麦克风接收的环境噪声信号来优化由语音麦克风接收的语音信号。
5.然而上述噪声处理方法处理效果不好,不能针对不同的噪音进行具体的分析和处理。
技术实现要素:
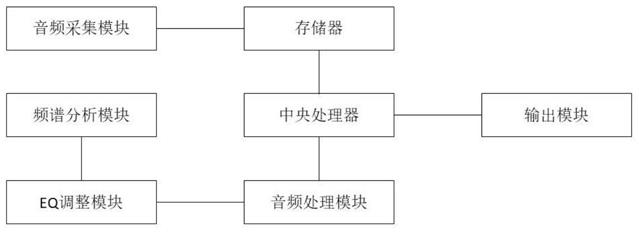
6.针对上述内容,为解决上述问题,提供一种噪声消除装置,包括音频采集模块、存储器、中央处理器、音频处理模块、eq调整模块、频谱分析模块和输出模块;
7.音频采集模块用于连接麦克风、声卡或者其他录音设备,并获取音频数据;音频采集模块将采集的音频数据储存在存储模块内;
8.中央处理器连接存储器,并将存储器内的音频数据发送给音频处理模块进行音频处理,实现噪声消除;
9.音频处理模块将进行噪声消除后的音频数据储存在存储器中,中央处理器将存储器中的噪声消除后的音频数据通过输出模块输出;
10.音频处理模块连接频谱分析模块和eq调整模块;频谱分析模块用于音频数据进行频谱分析,eq调整模块用于对音频数据进行eq调整。
11.音频采集模块的采样率为44100hz,比特率为128bit,输出模块输出的音频采样率为44100hz,比特率为128bit。
12.一种利用所述的噪声消除装置执行噪声检测的方法,包括如下步骤:
13.步骤1、音频采集模块采集待检测的音频数据,采样率为44100hz,比特率为128bit,并将待检测的音频数据储存在存储器中;
14.步骤2、中央处理器从存储器中调用待检测的音频数据并发送给音频处理模块;
15.步骤3、音频处理模块将音频进行分割;分割的基准为,设置能量阈值a0,如果连续50ms以上的音频其能量都小于a0或者都大于a0,则将其从待检测音频数据中分割出来作为一个音频片段;
16.步骤4、将能量小于a0的音频片段分别进行频谱分析,并将分析出的每一个频谱进行多峰拟合,得到拟合峰的个数和全部拟合峰强度的极差;并将拟合后的频谱进行相似度分析,相似度分析时将拟合峰个数、每个拟合峰的频率、每个拟合峰的强度和拟合峰强度的极差作为相似度的计算参数;并将相似度大于阈值的频谱对应的音频片段分成一组,计算每一组音频片段的总时长;
17.步骤5、选择步骤4中总时长最长的一组音频片段,并将该组音频片段标记为背景噪声;并将背景噪声进行拼接,并对拼接后的背景噪声进行频谱分析,得到背景噪声频谱;
18.步骤6、将能量大于a0的音频片段按照时长进行排序,将时长小于150ms的音频片段标记为偶然噪声;将偶然噪声对应的音频片段进行频谱分析,并将分析出的每一个频谱进行多峰拟合,得到拟合峰的个数和全部拟合峰强度的极差;并将拟合后的频谱进行相似度分析,相似度分析时将拟合峰个数、每个拟合峰的频率、每个拟合峰的强度和拟合峰强度的极差作为相似度的计算参数;并将相似度大于阈值的频谱对应的偶然噪声音频片段分成一组,计算每一组音频片段的总时长;
19.步骤7、选择步骤6中总时长最长的一组偶然噪声音频片段,并将该组偶然噪声音频片段标记为多发偶然噪声;并将多发偶然噪声进行拼接,并对拼接后的多发偶然噪声进行频谱分析,得到多发偶然噪声频谱;
20.步骤8、选择能量大于a0的音频片段按照时长进行排序,将时长大于150ms的音频片段进行语音识别,并对语音识别的结果进行语义分析,若语音识别出的结果语义完整则将其对应的音频片段标记为普通语音;如果语音识别出的结果匹配度低于阈值或者语义不清,则将其对应的音频片段标记为语音噪声。
21.一种利用所述的噪声消除装置执行噪声消除的方法,其特征在于利用所述的噪声检测的方法,具体包括如下步骤:
22.步骤a、音频采集模块采集待检测的音频数据,并利用所述的噪声检测的方法的步骤1
‑
8进行噪声检测;
23.步骤b、将音频数据中的能量小于a0的音频片段、偶然噪声对应的音频片段和语音噪声对应的音频片段直接静音;
24.步骤c、将普通语音对应的音频片段进行频谱分析,然后进行eq调整,在普通语音对应的音频片段的频谱上对背景噪声频谱对应的拟合峰的频率出进行减弱,减弱的幅度与背景噪声频谱对应的拟合峰的强度相同;
25.步骤d、将普通语音对应的音频片段进行进一步分割,每一个分段的时长与多发偶然噪声对应的音频片段的平均时长相同,并将分段后的普通语音音频片段进行频谱分析,并将其与多发偶然噪声频谱进行相似度分析;
26.步骤e、筛选出步骤d中相似度大于阈值的普通语音音频片段,然后在其频谱上对
多发偶然噪声频谱对应的拟合峰的频率出进行减弱,减弱的幅度与多发偶然噪声频谱对应的拟合峰的强度相同;
27.步骤f、将全部的音频片段按照其原始顺序进行拼接,得到噪声消除后的音频数据。
28.本发明的有益效果为:
29.本发明将音频数据进行分割,并按照其特征分成背景噪声、偶然噪声和语音噪声,并且进一步将偶然噪声中提取出多发偶然噪声;进一步利用背景噪声、偶然噪声对语音音频进行进一步的降噪处理;处理效果更准确,精度更好,降噪效果更好;
30.利用背景噪声的频谱对语音数据进行一次eq调节,实现了整体的背景噪声的降噪;进一步的利用多发偶然噪声对语音数据进行二次eq调节,进一步实现了对偶然噪声的降噪;充分利用语音识别的方法对噪声进行进一步的识别,识别准确度更高,效果更好。
附图说明
31.图1为本发明整体架构示意图。
具体实施方式
32.本发明的优点、特征以及达成所述目的的方法通过附图及后续的详细说明将会明确。
33.实施例1:
34.本发明所称eq调整即为图形均衡器,是音频处理中经常使用的一种音频处理效果器,eq调整的范围为5~20000hz。
35.一种噪声消除装置,包括音频采集模块、存储器、中央处理器、音频处理模块、eq调整模块、频谱分析模块和输出模块;
36.音频采集模块用于连接麦克风、声卡或者其他录音设备,并获取音频数据;音频采集模块将采集的音频数据储存在存储模块内;
37.中央处理器连接存储器,并将存储器内的音频数据发送给音频处理模块进行音频处理,实现噪声消除;
38.音频处理模块将进行噪声消除后的音频数据储存在存储器中,中央处理器将存储器中的噪声消除后的音频数据通过输出模块输出;
39.音频处理模块连接频谱分析模块和eq调整模块;频谱分析模块用于音频数据进行频谱分析,eq调整模块用于对音频数据进行eq调整。
40.音频采集模块的采样率为44100hz,比特率为128bit,输出模块输出的音频采样率为44100hz,比特率为128bit。
41.实施例2:
42.一种利用所述的噪声消除装置执行噪声检测的方法,包括如下步骤:
43.步骤1、音频采集模块采集待检测的音频数据,采样率为44100hz,比特率为128bit,并将待检测的音频数据储存在存储器中;
44.步骤2、中央处理器从存储器中调用待检测的音频数据并发送给音频处理模块;
45.步骤3、音频处理模块将音频进行分割;分割的基准为,设置能量阈值a0,如果连续
50ms以上的音频其能量都小于a0或者都大于a0,则将其从待检测音频数据中分割出来作为一个音频片段;
46.步骤4、将能量小于a0的音频片段分别进行频谱分析,并将分析出的每一个频谱进行多峰拟合,得到拟合峰的个数和全部拟合峰强度的极差;并将拟合后的频谱进行相似度分析,相似度分析时将拟合峰个数、每个拟合峰的频率、每个拟合峰的强度和拟合峰强度的极差作为相似度的计算参数;并将相似度大于阈值的频谱对应的音频片段分成一组,计算每一组音频片段的总时长;
47.相似度分析的具体方法可采用欧氏距离、马氏距离或者皮尔逊相关系数;多峰拟合时采用的拟合函数为高斯函数。
48.步骤5、选择步骤4中总时长最长的一组音频片段,并将该组音频片段标记为背景噪声;并将背景噪声进行拼接,并对拼接后的背景噪声进行频谱分析,得到背景噪声频谱;
49.步骤6、将能量大于a0的音频片段按照时长进行排序,将时长小于150ms的音频片段标记为偶然噪声;将偶然噪声对应的音频片段进行频谱分析,并将分析出的每一个频谱进行多峰拟合,得到拟合峰的个数和全部拟合峰强度的极差;并将拟合后的频谱进行相似度分析,相似度分析时将拟合峰个数、每个拟合峰的频率、每个拟合峰的强度和拟合峰强度的极差作为相似度的计算参数;并将相似度大于阈值的频谱对应的偶然噪声音频片段分成一组,计算每一组音频片段的总时长;
50.步骤7、选择步骤6中总时长最长的一组偶然噪声音频片段,并将该组偶然噪声音频片段标记为多发偶然噪声;并将多发偶然噪声进行拼接,并对拼接后的多发偶然噪声进行频谱分析,得到多发偶然噪声频谱;
51.步骤8、选择能量大于a0的音频片段按照时长进行排序,将时长大于150ms的音频片段进行语音识别,并对语音识别的结果进行语义分析,若语音识别出的结果语义完整则将其对应的音频片段标记为普通语音;如果语音识别出的结果匹配度低于阈值或者语义不清,则将其对应的音频片段标记为语音噪声。
52.实施例3:
53.一种利用所述的噪声消除装置执行噪声消除的方法,其特征在于利用所述的噪声检测的方法,具体包括如下步骤:
54.步骤a、音频采集模块采集待检测的音频数据,并利用所述的噪声检测的方法的步骤1
‑
8进行噪声检测;
55.步骤b、将音频数据中的能量小于a0的音频片段、偶然噪声对应的音频片段和语音噪声对应的音频片段直接静音;
56.步骤c、将普通语音对应的音频片段进行频谱分析,然后进行eq调整,在普通语音对应的音频片段的频谱上对背景噪声频谱对应的拟合峰的频率出进行减弱,减弱的幅度与背景噪声频谱对应的拟合峰的强度相同;
57.步骤d、将普通语音对应的音频片段进行进一步分割,每一个分段的时长与多发偶然噪声对应的音频片段的平均时长相同,并将分段后的普通语音音频片段进行频谱分析,并将其与多发偶然噪声频谱进行相似度分析;
58.步骤e、筛选出步骤d中相似度大于阈值的普通语音音频片段,然后在其频谱上对多发偶然噪声频谱对应的拟合峰的频率出进行减弱,减弱的幅度与多发偶然噪声频谱对应
的拟合峰的强度相同;
59.步骤f、将全部的音频片段按照其原始顺序进行拼接,得到噪声消除后的音频数据。
60.以上所述,仅为本发明的优选实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。