1.本发明涉及信号处理技术领域,具体涉及一种信号处理方法及设备、处理芯片。
背景技术:
2.深度神经网络(deep neural networks,简称dnn)的研究近年来取得了飞速发展并得到初步应用。然而深度神经网络算法通常需要消耗大量的算力,大量的算力消耗也会带来更大的功耗,例如经典的深度卷积网络(cnn)模型alexnet,需要进行至少7.2亿次的乘法运算,一般功耗在10瓦到100瓦左右。
3.为了提升分类精度,深度神经网络的结构也越来越复杂,目前已经出现超过了1000层的深度神经网络,即使在边缘端,深度神经网络一般都需要50层左右。由于芯片算力资源和存储资源的限制,在对复杂的深度神经网络进行硬件加速时,由于芯片计算资源、存储资源的限制,很少能够将整个深度神经网络一次性映射到芯片上。目前一般会采用流线化运算方式,例如将第一层映射到芯片上,芯片进行运算,同时将第二层的权重准备好,芯片将第一层算完后,进行第二层运算。以此类推,直到全部层运算完毕。
4.脉冲神经网络(spiking neural network,简称snn)近年来以其低功耗和更接近人脑的特点吸引了学术界和产业界的关注。在脉冲神经网络中,轴突是接收脉冲的单元,神经元是发送脉冲的单元,一个神经元通过树突连接到多个轴突,树突和轴突的连接点称为突触。轴突接收到脉冲后,所有和这一轴突有突触连接的树突会收到脉冲,进而影响到树突下游神经元。神经元将来自多个轴突的脉冲相加并与之前的膜电压累加,如果数值超过阈值,就向下游发送一个脉冲。脉冲神经网络内传播的是1比特的脉冲,脉冲的激活频率比较低,并且只需要加减法运算,没有乘法运算,算力消耗和功耗都较深度神经网络更低;由此,可以将深度神经网络脉冲化转成脉冲神经网络,从而能够充分利用脉冲神经网络的低功耗优势。
5.然而,用脉冲神经网络硬件对脉冲化后的深度神经网络进行加速时,也遇到资源不足的问题。若脉冲化后的深度神经网络的规模较大,需要将该网络映射到多片芯片,多片芯片并行工作,则会导致成本过高的问题。
技术实现要素:
6.本发明的目的是提供了一种信号处理方法及设备、处理芯片,能够利用单个处理芯片实现复杂脉冲神经网络的流线运算,降低了对处理芯片的算力要求;同时,适用于深度神经网络脉冲化得到的脉冲神经网络,避免了复杂网络需要映射到多个芯片带来的成本消耗。
7.为实现上述目的,本发明提供了一种信号处理方法,包括:将待处理的音视频信号编码为持续多个脉冲周期的输入脉冲信号;在处理芯片被配置在所述输入脉冲信号的每个所述脉冲周期时,脉冲神经网络的各层被依次映射到处理芯片中,所述处理芯片基于所述脉冲周期内的所述输入脉冲信号,得到在所述脉冲周期内所述脉冲神经网络的输出脉冲信
号;根据所述多个脉冲周期内所述脉冲神经网络的输出脉冲信号,得到所述音视频信号经过所述脉冲神经网络处理后的处理结果。
8.本发明还提供了一种处理芯片,用于执行上述的信号处理方法。
9.本发明还提供了一种信号处理设备,包括:上述的处理芯片。
10.本发明实施例中,先将待处理的音视频信号编码为持续多个脉冲周期的输入脉冲信号,在处理芯片被配置在所述输入脉冲信号的每个所述脉冲周期时,脉冲神经网络的各层被依次映射到处理芯片中,所述处理芯片基于所述脉冲周期内的所述输入脉冲信号,得到在所述脉冲周期内所述脉冲神经网络的输出脉冲信号,继而再根据所述多个脉冲周期内所述脉冲神经网络的输出脉冲信号,得到所述音视频信号经过所述脉冲神经网络处理后的处理结果。即在利用脉冲神经网络对包括多个脉冲周期的输入脉冲信号的处理时,先对层进行流线运算,然后再对周期进行流线运算,从而能够利用单个处理芯片实现复杂脉冲神经网络的流线运算,降低了对处理芯片的算力要求;同时,适用于深度神经网络脉冲化得到的脉冲神经网络,避免了复杂网络需要映射到多个芯片带来的成本消耗。
11.在一个实施例中,在处理芯片被配置在所述输入脉冲信号的每个所述脉冲周期时,脉冲神经网络的各层被依次映射到处理芯片中,所述处理芯片基于所述脉冲周期内的所述输入脉冲信号,得到在所述脉冲周期内所述脉冲神经网络的输出脉冲信号,包括:在处理芯片被配置在所述输入脉冲信号的第一个脉冲周期时,脉冲神经网络的各层被依次映射到处理芯片中,所述处理芯片基于所述第一个脉冲周期内的所述输入脉冲信号,得到在所述第一个脉冲周期内所述脉冲神经网络的输出脉冲信号;在处理芯片被配置在所述输入脉冲信号的第n个脉冲周期时,脉冲神经网络的各层被依次映射到处理芯片中,所述处理芯片基于第n个脉冲周期内的所述输入脉冲信号与第n
‑
1个脉冲周期内所述脉冲神经网络在各层的膜电压,得到在所述第n个脉冲周期内所述脉冲神经网络的输出脉冲信号。
12.在一个实施例中,在处理芯片被配置在所述输入脉冲信号的第一个脉冲周期时,脉冲神经网络的各层被依次映射到处理芯片中,所述处理芯片基于所述第一个脉冲周期内的所述输入脉冲信号,得到在所述第一个脉冲周期内所述脉冲神经网络的输出脉冲信号,包括:在处理芯片被配置在所述输入脉冲信号的第一个脉冲周期时,若所述脉冲神经网络的第一层被映射到所述处理芯片,所述处理芯片根据所述第一个脉冲周期内的所述输入脉冲信号,得到在所述第一个脉冲周期内所述脉冲神经网络在第一层的膜电压与输出脉冲信号;若所述脉冲神经网络的第m层被映射到所述处理芯片,所述处理芯片根据所述第一个脉冲周期内所述脉冲神经网络在第m
‑
1层的输出脉冲信号,得到在所述第一个脉冲周期内所述脉冲神经网络在第m层的膜电压与输出脉冲信号;m为大于1的整数;将所述第一个脉冲周期内所述脉冲神经网络在最后一层的输出脉冲信号作为所述脉冲神经网络的输出脉冲信号。
13.在一个实施例中,在处理芯片被配置在所述输入脉冲信号的第n个脉冲周期时,脉冲神经网络的各层被依次映射到处理芯片中,所述处理芯片基于第n个脉冲周期内的所述输入脉冲信号与第n
‑
1个脉冲周期内所述脉冲神经网络在各层的膜电压,得到在所述第n个脉冲周期内所述脉冲神经网络的输出脉冲信号,包括:在处理芯片被配置在所述输入脉冲信号的第n个脉冲周期时,在所述脉冲神经网络的第一层被映射到所述处理芯片时,所述处理芯片根据所述第n个脉冲周期内的所述输入脉冲信号与第n
‑
1个脉冲周期内所述脉冲神
经网络在第一层的膜电压,得到在所述第n个脉冲周期内所述脉冲神经网络在第一层的膜电压与输出脉冲信号;在所述脉冲神经网络的第m层被映射到所述处理芯片时,所述处理芯片根据所述第n个脉冲周期内所述脉冲神经网络在第m
‑
1层的输出脉冲信号与第n
‑
1个脉冲周期内所述脉冲神经网络在第m层的膜电压,得到在所述第n个脉冲周期内所述脉冲神经网络在第m层的膜电压与输出脉冲信号,m为大于1的整数;将所述第n个脉冲周期内所述脉冲神经网络在最后一层的输出脉冲信号作为所述脉冲神经网络的输出脉冲信号。
14.在一个实施例中,在所述脉冲神经网络的第一层被映射到所述处理芯片时,所述处理芯片根据所述第n个脉冲周期内的所述输入脉冲信号与第n
‑
1个脉冲周期内所述脉冲神经网络在第一层的膜电压,得到在所述第n个脉冲周期内所述脉冲神经网络在第一层的膜电压与输出脉冲信号,包括:在所述脉冲神经网络的第一层被映射到所述处理芯片时,所述处理芯片计算所述第n个脉冲周期内的所述输入脉冲信号与所述脉冲神经网络在第一层的权重乘积,并计算所述乘积与所述第n
‑
1个脉冲周期内所述脉冲神经网络在第一层的膜电压的和,作为在所述第n个脉冲周期内所述脉冲神经网络在第一层的膜电压;根据所述第n个脉冲周期内所述脉冲神经网络在第一层的膜电压与预设的膜电压阈值,得到在所述第n个脉冲周期内所述脉冲神经网络在第一层的输出脉冲信号。
15.在一个实施例中,在所述脉冲神经网络的第m层被映射到所述处理芯片时,所述处理芯片根据所述第n个脉冲周期内所述脉冲神经网络在第m
‑
1层的输出脉冲信号与第n
‑
1个脉冲周期内所述脉冲神经网络在第m层的膜电压,得到在所述第n个脉冲周期内所述脉冲神经网络在第m层的膜电压与输出脉冲信号,包括:在所述脉冲神经网络的第m层被映射到所述处理芯片时,所述处理芯片计算所述第n个脉冲周期内所述脉冲神经网络在第m
‑
1层的输出脉冲信号与所述脉冲神经网络在第m层的权重乘积,并计算所述乘积与所述第n
‑
1个脉冲周期内所述脉冲神经网络在第m层的膜电压的和,作为在所述第n个脉冲周期内所述脉冲神经网络在第m层的膜电压;根据所述第n个脉冲周期内所述脉冲神经网络在第m层的膜电压与预设的膜电压阈值,得到在所述第n个脉冲周期内所述脉冲神经网络在第m层的输出脉冲信号。
16.在一个实施例中,所述处理芯片用于同时映射脉冲神经网络中的两层;所述处理芯片包括多个神经元核,所述多个神经元核被分为两组,每组神经元核用于映射所述脉冲神经网络中的至少一层;脉冲神经网络的各层被依次映射到所述处理芯片,在所述脉冲神经网络的第m
‑
1层被映射所述处理芯片中的一组神经元核中时,所述脉冲神经网络的第m层被映射所述处理芯片中的另一组神经元核中,m为大于1的整数。
17.在一个实施例中,所述处理芯片所包含的每个神经元核的缓存空间均包括:第一缓存空间与第二缓存空间;对于每个所述神经元核,所述神经元核的第一缓存空间缓存有脉冲神经网络的第m
‑
1层的权重时,所述神经元核的第二缓存空间缓存有脉冲神经网络的第m层的权重,m为大于1的整数。
附图说明
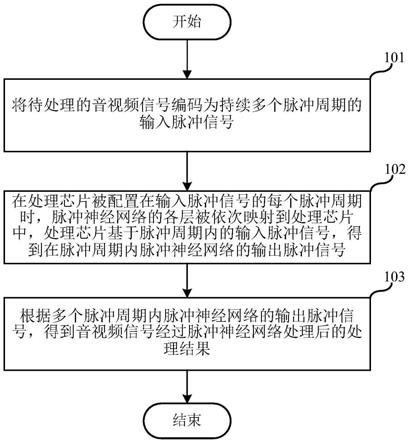
18.图1是根据本发明第一实施例中的信号处理方法的具体流程图;
19.图2是根据本发明第二实施例中的信号处理方法的具体流程图;
20.图3是图2中的信号处理方法的子步骤2021的具体流程图;
21.图4是图2中的信号处理方法的子步骤2022的具体流程图;
22.图5是根据本发明第二实施例中的3层脉冲神经网络的信号处理时序图;
23.图6是根据本发明第三实施例中的处理芯片的示意图;
24.图7是根据本发明第三实施例中的处理芯片中的神经元核的示意图;
25.图8是根据本发明第四实施例中的处理芯片的示意图;
26.图9是根据本发明第四实施例中的处理芯片进行信号处理的示意图;
27.图10是根据本发明第五实施例中的信号处理设备的示意图。
具体实施方式
28.以下将结合附图对本发明的各实施例进行详细说明,以便更清楚理解本发明的目的、特点和优点。应理解的是,附图所示的实施例并不是对本发明范围的限制,而只是为了说明本发明技术方案的实质精神。
29.在下文的描述中,出于说明各种公开的实施例的目的阐述了某些具体细节以提供对各种公开实施例的透彻理解。但是,相关领域技术人员将认识到可在无这些具体细节中的一个或多个细节的情况来实践实施例。在其它情形下,与本技术相关联的熟知的装置、结构和技术可能并未详细地示出或描述从而避免不必要地混淆实施例的描述。
30.除非语境有其它需要,在整个说明书和权利要求中,词语“包括”和其变型,诸如“包含”和“具有”应被理解为开放的、包含的含义,即应解释为“包括,但不限于”。
31.在整个说明书中对“一个实施例”或“一实施例”的提及表示结合实施例所描述的特定特点、结构或特征包括于至少一个实施例中。因此,在整个说明书的各个位置“在一个实施例中”或“在一实施例”中的出现无需全都指相同实施例。另外,特定特点、结构或特征可在一个或多个实施例中以任何方式组合。
32.如该说明书和所附权利要求中所用的单数形式“一”和
“”
包括复数指代物,除非文中清楚地另外规定。应当指出的是术语“或”通常以其包括“或/和”的含义使用,除非文中清楚地另外规定。
33.在以下描述中,为了清楚展示本发明的结构及工作方式,将借助诸多方向性词语进行描述,但是应当将“前”、“后”、“左”、“右”、“外”、“内”、“向外”、“向内”、“上”、“下”等词语理解为方便用语,而不应当理解为限定性词语。
34.本发明第一实施方式涉及一种信号处理方法,应用于处理芯片,处理芯片可以采用该信号处理方法映射脉冲神经网络对音视频信号进行处理,得到相应的处理结果,该处理结果可以用于音视频信号的分类。其中,脉冲神经网络也可以是由深度神经网络脉冲化得到。
35.本实施例的信号处理方法的具体流程如图1所示。
36.步骤101,将待处理的音视频信号编码为持续多个脉冲周期的输入脉冲信号。
37.具体而言,处理芯片在接收到待处理的音视频信号后,可以利用处理芯片中的脉冲编码模块将该音视频信号编码为包括x个脉冲周期的输入脉冲信号,x为大于1的整数,x个脉冲周期的输入脉冲信号可以分别表示为:per(1)、per(2)、
……
、per(x),per(n)则表示x个脉冲周期中的第n个脉冲周期,1<n≤x。需要说明的是,本实施例中以处理芯片中包括脉冲编码模块为例进行说明,然不限于此,还可以由处理芯片连接的外部编码模块对音视
频信号进行编码,然后将编码得到的包括x个脉冲周期的输入脉冲信号直接输入到处理芯片。
38.步骤102,在处理芯片被配置在输入脉冲信号的每个脉冲周期时,脉冲神经网络的各层被依次映射到处理芯片中,处理芯片基于脉冲周期内的输入脉冲信号,得到在脉冲周期内脉冲神经网络的输出脉冲信号。
39.具体而言,在利用脉冲神经网络对包括x个脉冲周期的输入脉冲信号的处理时,先对层进行流线运算,然后再对周期进行流线运算,按照输入脉冲信号的周期顺序,依次将处理芯片配置在输入脉冲信号的每个脉冲周期;脉冲神经网络包括y层,y为大于1的整数,脉冲神经网络的y个层的可以分别表示为:layer(1)、layer(2)、
……
、layer(y),layer(m)则表示脉冲神经网络的y个层中的第m层,1<m≤y。在处理芯片被配置在每个脉冲周期时,处理芯片按照层的顺序依次映射脉冲神经网络的layer(1)至layer(y),处理芯片将映射layer(y)层时的输出,作为在该脉冲周期内脉冲神经网络的输出脉冲信号;由此,可以得到在各个脉冲周期内脉冲神经网络的输出脉冲信号。
40.步骤103,根据多个脉冲周期内脉冲神经网络的输出脉冲信号,得到音视频信号经过脉冲神经网络处理后的处理结果。
41.具体而言,按照脉冲周期的顺序,将脉冲神经网络的输出脉冲信号进行组合,得到音视频信号经过脉冲神经网络处理后的处理结果,该处理结果可以用于音视频信号的分类。
42.本实施例提供了一种信号处理方法,先将待处理的音视频信号编码为持续多个脉冲周期的输入脉冲信号,在处理芯片被配置在输入脉冲信号的每个脉冲周期时,脉冲神经网络的各层被依次映射到处理芯片中,处理芯片基于脉冲周期内的输入脉冲信号,得到在脉冲周期内脉冲神经网络的输出脉冲信号,继而再根据多个脉冲周期内脉冲神经网络的输出脉冲信号,得到音视频信号经过脉冲神经网络处理后的处理结果。即在利用脉冲神经网络对包括多个脉冲周期的输入脉冲信号的处理时,先对层进行流线运算,然后再对周期进行流线运算,从而能够利用单个处理芯片实现复杂脉冲神经网络的流线运算,降低了对处理芯片的算力要求;同时,适用于深度神经网络脉冲化得到的脉冲神经网络,避免了复杂网络需要映射到多个芯片带来的成本消耗。
43.本发明的第二实施例涉及一种信号处理方法,本实施方式相对于第一实施方式而言:本实施例提供了在处理芯片被配置在输入脉冲信号的每个脉冲周期时,脉冲神经网络的各层被依次映射到处理芯片中,处理芯片基于脉冲周期内的输入脉冲信号,得到在脉冲周期内脉冲神经网络的输出脉冲信号的一种具体实现方式。
44.本实施例的信号处理方法的具体流程如图2所示。
45.步骤201,将待处理的音视频信号编码为持续多个脉冲周期的输入脉冲信号。与第一实施例的步骤101大致相同,在此不再赘述。
46.步骤202,包括以下子步骤:
47.子步骤2021,在处理芯片被配置在输入脉冲信号的第一个脉冲周期时,脉冲神经网络的各层被依次映射到处理芯片中,处理芯片基于第一个脉冲周期内的输入脉冲信号,得到在第一个脉冲周期内脉冲神经网络的输出脉冲信号。
48.请参考图3,子步骤2021包括:
49.子步骤20211,在处理芯片被配置在输入脉冲信号的第一个脉冲周期时,若脉冲神经网络的第一层被映射到处理芯片,处理芯片根据第一个脉冲周期内的输入脉冲信号,得到在第一个脉冲周期内脉冲神经网络在第一层的膜电压与输出脉冲信号。
50.子步骤20212,若脉冲神经网络的第m层被映射到处理芯片,处理芯片根据第一个脉冲周期内脉冲神经网络在第m
‑
1层的输出脉冲信号,得到在第一个脉冲周期内脉冲神经网络在第m层的膜电压与输出脉冲信号;m为大于1的整数。
51.子步骤20213,将第一个脉冲周期内脉冲神经网络在最后一层的输出脉冲信号作为脉冲神经网络的输出脉冲信号。
52.具体而言,在处理芯片被配置在输入脉冲信号的第一个脉冲周期per(1)时,在第一个脉冲周期per(1)内,脉冲神经网络的各层被依次映射到处理芯片中,处理芯片在映射脉冲神经网络的各层时,无需进行膜电压的累加。
53.当脉冲神经网络的第一层layer(1)被映射到处理芯片时,处理芯片中缓存了脉冲神经网络的第一层layer(1)的权重,此时将第一个脉冲周期per(1)的输入脉冲信号作为处理芯片的输入,处理芯片计算第一个脉冲周期per(1)的输入脉冲信号与第一层layer(1)的权重的乘积,该乘积即为第一个脉冲周期内脉冲神经网络在第一层的膜电压,处理芯片中预设有膜电压阈值,然后将第一个脉冲周期per(1)内脉冲神经网络在第一层layer(1)的膜电压与该膜电压阈值进行比较,当第一个脉冲周期per(1)内脉冲神经网络在第一层layer(1)的膜电压大于或等于该膜电压阈值时,则在第一个脉冲周期内脉冲神经网络在第一层layer(1)的输出脉冲信号为1;当第一层layer(1)的膜电压小于该膜电压阈值时,则在第一个脉冲周期per(1)内脉冲神经网络在第一层layer(1)的输出脉冲信号为0。
54.当脉冲神经网络的第m层layer(m)被映射到处理芯片时,处理芯片中缓存脉冲神经网络的第m层layer(m)的权重,此时以第一个脉冲周期per(1)内脉冲神经网络的第m
‑
1层的输出脉冲信号作为处理芯片的输入,处理芯片计算第一个脉冲周期per(1)内脉冲神经网络的第m
‑
1层的输出脉冲信号与第m层layer(m)的权重的乘积,该乘积即为第一个脉冲周期内脉冲神经网络在第m层layer(m)的膜电压,处理芯片中预设有膜电压阈值,然后将第一个脉冲周期内脉冲神经网络在第m层layer(m)的膜电压与该膜电压阈值进行比较,当第m层layer(m)的膜电压大于或等于该膜电压阈值时,则在第一个脉冲周期内脉冲神经网络在第m层layer(m)的输出脉冲信号为1;当第m层layer(m)的膜电压小于该膜电压阈值时,则在第一个脉冲周期内脉冲神经网络在第m层layer(m)的输出脉冲信号为0。
55.以m=2为例,此时脉冲神经网络的第二层layer(2)被映射到处理芯片,处理芯片中缓存脉冲神经网络的第二层layer(2)的权重,此时以第一个脉冲周期per(1)内脉冲神经网络的第一层layer(1)的输出脉冲信号作为处理芯片的输入,处理芯片计算第一个脉冲周期per(1)内脉冲神经网络的第一层的输出脉冲信号与第二层layer(2)的权重的乘积,该乘积即为第一个脉冲周期内脉冲神经网络在第二层layer(2)的膜电压,处理芯片中预设有膜电压阈值,然后将第一个脉冲周期内脉冲神经网络在第二层layer(2)的膜电压与该膜电压阈值进行比较,当第二层layer(2)的膜电压大于或等于该膜电压阈值时,则在第一个脉冲周期内脉冲神经网络在第二层layer(2)的输出脉冲信号为1;当第二层layer(2)的膜电压小于该膜电压阈值时,则在第一个脉冲周期内脉冲神经网络在第二层layer(2)的输出脉冲信号为0。
56.以此类推,直至m=y,脉冲神经网络的最后一层layer(y)被映射到处理芯片中缓存脉冲神经网络的第y层layer(y)的权重,此时以第一个脉冲周期per(1)内脉冲神经网络的第y
‑
1层的输出脉冲信号作为处理芯片的输入,处理芯片计算第一个脉冲周期per(1)内脉冲神经网络的第y
‑
1层的输出脉冲信号与第y层layer(y)的权重的乘积,该乘积即为第一个脉冲周期内脉冲神经网络在第y层layer(y)的膜电压,处理芯片中预设有膜电压阈值,然后将第一个脉冲周期内脉冲神经网络在第y层layer(y)的膜电压与该膜电压阈值进行比较,当第y层layer(y)的膜电压大于或等于该膜电压阈值时,则在第一个脉冲周期内脉冲神经网络在第y层layer(y)的输出脉冲信号为1;当第y层layer(y)的膜电压小于该膜电压阈值时,则在第一个脉冲周期内脉冲神经网络在第y层layer(y)的输出脉冲信号为0。
57.随后将第一个脉冲周期per(1)内脉冲神经网络在最后一层layer(y)的输出脉冲信号作为第一个脉冲周期per(1)内脉冲神经网络的输出脉冲信号。
58.子步骤2022,在处理芯片被配置在输入脉冲信号的第n个脉冲周期时,脉冲神经网络的各层被依次映射到处理芯片中,处理芯片基于第n个脉冲周期内的输入脉冲信号与第n
‑
1个脉冲周期内脉冲神经网络在各层的膜电压,得到在第n个脉冲周期内脉冲神经网络的输出脉冲信号。
59.请参考图4,子步骤2022包括:
60.子步骤20221,在处理芯片被配置在输入脉冲信号的第n个脉冲周期时,在脉冲神经网络的第一层被映射到处理芯片时,处理芯片根据第n个脉冲周期内的输入脉冲信号与第n
‑
1个脉冲周期内脉冲神经网络在第一层的膜电压,得到在第n个脉冲周期内脉冲神经网络在第一层的膜电压与输出脉冲信号。
61.子步骤20222,在脉冲神经网络的第m层被映射到处理芯片时,处理芯片根据第n个脉冲周期内脉冲神经网络在第m
‑
1层的输出脉冲信号与第n
‑
1个脉冲周期内脉冲神经网络在第m层的膜电压,得到在第n个脉冲周期内脉冲神经网络在第m层的膜电压与输出脉冲信号,m为大于1的整数。
62.子步骤20223,将第n个脉冲周期内脉冲神经网络在最后一层的输出脉冲信号作为脉冲神经网络的输出脉冲信号。
63.具体而言,在处理芯片被配置在输入脉冲信号的第n个脉冲周期per(n)时,在第n个脉冲周期per(n)内,脉冲神经网络的各层被依次映射到处理芯片中,处理芯片在映射脉冲神经网络的各层时,还需要与第n
‑
1个脉冲周期的各层的膜电压的进行累加。
64.当脉冲神经网络的第一层layer(1)被映射到处理芯片时,处理芯片中缓存了脉冲神经网络的第一层layer(1)的权重,此时将第n个脉冲周期per(n)的输入脉冲信号作为处理芯片的输入,处理芯片计算第n个脉冲周期per(n)的输入脉冲信号与第一层layer(1)的权重的乘积,然后计算该乘积与第n
‑
1个脉冲周期per(n
‑
1)内脉冲神经网络在第一层layer(1)的膜电压的和,作为在第n个脉冲周期per(n)内脉冲神经网络在第一层layer(1)的膜电压,处理芯片中预设有膜电压阈值,然后将第n个脉冲周期per(n)内脉冲神经网络在第一层layer(1)的膜电压与该膜电压阈值进行比较,当第一层layer(1)的膜电压大于或等于该膜电压阈值时,则在第n个脉冲周期per(n)内脉冲神经网络在第一层layer(1)的输出脉冲信号为1;当第一层layer(1)的膜电压小于该膜电压阈值时,则在第n个脉冲周期per(n)内脉冲神经网络在第一层layer(1)的输出脉冲信号为0。
65.当脉冲神经网络的第m层layer(m)被映射到处理芯片时,处理芯片中缓存脉冲神经网络的第m层layer(m)的权重,此时以第n个脉冲周期per(n)内脉冲神经网络的第m
‑
1层的输出脉冲信号作为处理芯片的输入,处理芯片计算第n个脉冲周期per(n)内脉冲神经网络的第m
‑
1层的输出脉冲信号与第m层layer(m)的权重的乘积,然后计算该乘积与第n
‑
1个脉冲周期per(n
‑
1)内脉冲神经网络在第m层layer(m)的膜电压的和,作为在第n个脉冲周期per(n)内脉冲神经网络在第m层layer(m)的膜电压,处理芯片中预设有膜电压阈值,然后将第m层layer(m)的膜电压与该膜电压阈值进行比较,当第m层layer(m)的膜电压大于或等于该膜电压阈值时,则在第n个脉冲周期内脉冲神经网络在第m层layer(m)的输出脉冲信号为1;当第m层layer(m)的膜电压小于该膜电压阈值时,则在第n个脉冲周期内脉冲神经网络在第m层layer(m)的输出脉冲信号为0。
66.以m=2为例,此时脉冲神经网络的第二层layer(2)被映射到处理芯片,处理芯片中缓存脉冲神经网络的第二层layer(2)的权重,此时以第n个脉冲周期per(n)内脉冲神经网络的第一层layer(1)的输出脉冲信号作为处理芯片的输入,处理芯片计算第n个脉冲周期per(n)内脉冲神经网络的第一层layer(1)的输出脉冲信号与第二层layer(2)的权重的乘积,然后计算该乘积与第n
‑
1个脉冲周期per(n
‑
1)内脉冲神经网络在第2层layer(2)的膜电压的和,作为在第n个脉冲周期per(n)内脉冲神经网络在第二层layer(2)的膜电压,处理芯片中预设有膜电压阈值,然后将第n个脉冲周期per(n)内脉冲神经网络在第二层layer(2)的膜电压与该膜电压阈值进行比较,当第二层layer(2)的膜电压大于或等于该膜电压阈值时,则在第n个脉冲周期内脉冲神经网络在第二层layer(2)的输出脉冲信号为1;当第二层layer(2)的膜电压小于该膜电压阈值时,则在第n个脉冲周期内脉冲神经网络在第二层layer(2)的输出脉冲信号为0。
67.以此类推,当m=y,脉冲神经网络的最后一层layer(y)被映射到处理芯片中缓存脉冲神经网络的第y层layer(y)的权重,此时以第n个脉冲周期per(n)内脉冲神经网络的第y
‑
1层的输出脉冲信号作为处理芯片的输入,处理芯片计算第n个脉冲周期per(n)内脉冲神经网络的第y
‑
1层的输出脉冲信号与第y层layer(y)的权重的乘积,然后计算该乘积与第n
‑
1个脉冲周期per(n
‑
1)内脉冲神经网络在第y层layer(y)的膜电压的和,作为在第n个脉冲周期per(n)内脉冲神经网络在第y层layer(y)的膜电压,处理芯片中预设有膜电压阈值,然后将第n个脉冲周期per(n)内脉冲神经网络在第y层layer(y)的膜电压与该膜电压阈值进行比较,当第y层layer(y)的膜电压大于或等于该膜电压阈值时,则在第n个脉冲周期内脉冲神经网络在第y层layer(y)的输出脉冲信号为1;当第y层layer(y)的膜电压小于该膜电压阈值时,则在第n个脉冲周期per(n)内脉冲神经网络在第y层layer(y)的输出脉冲信号为0。
68.随后将第n个脉冲周期内脉冲神经网络最后一层layer(y)的输出脉冲信号作为第n个脉冲周期内脉冲神经网络的输出脉冲信号。重复上述过程,直至n=x,从而能够得到在各个脉冲周期内脉冲神经网络的输出脉冲信号。
69.举例来说,请参考图5,图中脉冲神经网络包括3层,分别为第一层layer(1)、第二层layer(2)以及第三层layer(3),输入脉冲信号包括2个脉冲周期,分别为第一脉冲周期per(1)和第二脉冲周期per(2),t(0)至t(7)表示处理芯片的运算周期,由图3可见,在t(0)运算周期中,主要是执行处理芯片的配置,包括权重配置、寄存器配置等,在t(1)至t(3)运
算周期,表示处理芯片配置在第一脉冲周期per(1),并依次映射layer(1)至layer(3)得到第一脉冲周期per(1)内脉冲神经网络的输出脉冲信号,在t(4)至t(6)运算周期,表示处理芯片配置在第二脉冲周期per(2),并依次映射layer(1)至layer(3)得到第二脉冲周期per(2)内脉冲神经网络的输出脉冲信号。
70.步骤203,根据多个脉冲周期内脉冲神经网络的输出脉冲信号,得到音视频信号经过脉冲神经网络处理后的处理结果。与第一实施例的步骤103大致相同,在此不再赘述。
71.本发明的第三实施例涉及一种处理芯片,处理芯片用于第一或第二实施例中的信号处理方法映射脉冲神经网络对音视频信号进行处理,得到相应的处理结果,该处理结果可以用于音视频信号的分类。其中,脉冲神经网络也可以是由深度神经网络脉冲化得到。
72.请参考图6,处理芯片10包括多个神经元核11;请参考图7,每个神经元核11包括:运算单元111、第一缓存112、第二缓存113以及第三缓存114。
73.运算单元111用于进行脉冲神经网络的层映射运算。
74.第一缓存112用于缓存输入的脉冲信号,第二缓存113用于缓存层权重,第三缓存114用于缓存运算单元111计算得到的膜电压。
75.在一个例子中,每个神经元核11的第二缓存空间113均包括:第一缓存空间与第二缓存空间。
76.对于每个神经元核11,神经元核11的第一缓存空间缓存有脉冲神经网络的第m
‑
1层的权重时,神经元核的第二缓存空间缓存有脉冲神经网络的第m层的权重,m为大于1的整数。即在第二缓存113中设置两个缓存空间,两个缓存空间分别用于缓存脉冲神经网络相邻两层的权重,从而可以减少从外部存储器的权重加载,提升运算效率。
77.本发明的第四实施例涉及一种处理芯片,本实施例相对于第三实施例而言,主要改进之处在于:在处理芯片能够同时映射脉冲神经网络中的两层,将处理芯片中的神经元核分为两组进行脉冲神经网络的层乒乓映射。
78.本实施例中,处理芯片包括多个神经元核,多个神经元核被分为两组,每组神经元核用于映射脉冲神经网络中的至少一层;脉冲神经网络的各层被依次映射到处理芯片,在脉冲神经网络的第m
‑
1层被映射处理芯片中的一组神经元核中时,脉冲神经网络的第m层被映射处理芯片中的另一组神经元核中,m为大于1的整数。需要说明的是,本实施例以在处理芯片能够同时映射脉冲神经网络中的两层为例进行说明,然不限于此,若处理芯片能够同时映射脉冲神经网络中的p层,则可以将处理芯片中的多个神经元核分为p组,每组神经元核用于映射脉冲神经网络中的至少一层,从而处理芯片每次可以映射脉冲神经网络的p层。
79.请参考图8,处理芯片10连接到外部存储器20,处理芯片10包括16个神经元核1,16个神经元核被分为两组,分别记作第一组part0与第二组part1,part0和part1能够分别映射神经网络的一层,图中将第一组part0中的神经元核记作神经元核0,将第二组part1中的神经元核记作神经元核1;外部存储器20用于存储脉冲神经网络的配置信息,例如脉冲神经网络各层的权重以及寄存器配置等。
80.在处理芯片10的第k个运算周期t(k),part0被映射到第n个脉冲周期per(n)脉冲神经网络的第m层layer(m),part0的内部缓存了从外部存储器20读出的layer(m)的权重,也存储了第n
‑
1个脉冲周期per(n
‑
1)脉冲神经网络的第m层layer(m)的膜电压;part0在进行运算时,save_potential_part0将part0计算得到第n个脉冲周期per(n)脉冲神经网络的
第m层layer(m)的膜电压写入到外部存储器20中,load_potential_part1将外部存储器20中的周期per(n
‑
1)内脉冲神经网络在第m+1层layer(m+1)的膜电压写入到part1中;load_weight_part1将外部存储器20中的脉冲神经网络第m+1层layer(m+1)的权重写入到part1;同时part0将计算得到的第m层layer(m)的输出脉冲信号spikeout_part0发送给part1作为在第k+1个运算周期t(k+1)中part1的输入数据。当part0运算结束,运算周期t(k)结束。
81.在运算周期t(k+1),part1被映射到第n个脉冲周期per(n)脉冲神经网络的第m+1层layer(m+1)。part1进行运算时,save_potential_part1将part1计算得到第n个脉冲周期per(n)脉冲神经网络的第m+1层layer(m+1)的膜电压运算结果写到外部存储器20中,load_potential_part0将外部存储器20中的周期per(n
‑
1)脉冲神经网络的第m+2层layer(m+2)的膜电压写入到part0中;load_weight_part0将外部存储器20中脉冲神经网络第m+2层layer(m+2)的权重写入到part0;同时part1将第n个脉冲周期per(n)脉冲神经网络的第m+1层layer(m+1)的输出脉冲信号spikeout_part1发送给part0作为第k+2个运算周期t(k+2)中part0的输入数据。当part1运算结束,运算周期t(k+1)结束。
82.重复上述过程能够得到各个脉冲周期内脉冲神经网络的输出脉冲信号;需要说明的是,在处理芯片10被映射到脉冲神经网络的第一层layer(1)时,part0的输入数据为输入脉冲信号;在处理芯片10被映射到脉冲神经网络的最后一层layer(y)时,若y是偶数,part1执行脉冲神经网络的最后一层layer(y)的映射运算,下一个运算周期由part0进行第n+1个脉冲周期per(n+1)的第一层layer(1)的运算。此时,load_potential_part0将外部存储器20中的第n个脉冲周期per(n)的第一层layer(1)的膜电压写入到part0中,load_weight_part0将外部存储器20中脉冲神经网络的第一层layer(1)的权重写入到part0;同时将n+1个脉冲周期per(n+1)的输入脉冲信号enc_out作为part0的输入数据。load_potential_part1没有操作,load_weight_part1没有操作,part1不会将第n个脉冲周期内脉冲神经网络的最后一层layer(y)的输出脉冲信号spikeout_part1发送给part0。
83.若y是奇数,part0执行脉冲神经网络的最后一层layer(y)的映射运算,如果输入脉冲信号只能接入part0,那么将由part0进行第n+1个脉冲周期per(n+1)的第一层layer(1)的运算。其中,本运算周期part0正使用layer(y)的权重进行运算,不会向part0中写入layer(1)的权重。当处于最后一个脉冲周期per(x)时,处理芯片10无需对计算得到脉冲神经网络各层的膜电压进行保存。在下一个运算周期,load_potential_part0将外部存储器20中的第n个脉冲周期per(n)的第一层layer(1)的膜电压写入到part0中,load_weight_part0将外部存储器20中脉冲神经网络的第一层layer(1)的权重写入到part0;同时将n+1个脉冲周期per(n+1)的输入脉冲信号enc_out作为part0的输入数据。load_potential_part1没有操作,load_weight_part1没有操作。在下一个运算周期内part0进行第n+1个脉冲周期per(n+1)的第一层layer(1)的运算。
84.若y是奇数,part0执行脉冲神经网络的最后一层layer(y)的映射运算,如果输入脉冲信号能接入part1,下一个运算周期也可以由part1进行第n+1个脉冲周期per(n+1)的第一层layer(1)的运算。此时,load_potential_part1将外部存储器20中的第n个脉冲周期per(n)的第一层layer(1)的膜电压写入到part1中,load_weight_part1将外部存储器20中脉冲神经网络的第一层layer(1)的权重写入到part1;同时将n+1个脉冲周期per(n+1)的输入脉冲信号enc_out作为part1的输入数据。load_potential_part0没有操作,load_
weight_part0没有操作,part0不会将第n个脉冲周期内脉冲神经网络的最后一层layer(y)的输出脉冲信号spikeout_part0发送给part1。
85.下面结合图9进行进一步说明,图9脉冲神经网络包括3层,分别为第一层layer(1)、第二层layer(2)以及第三层layer(3),输入脉冲信号包括2个脉冲周期,分别为第一脉冲周期per(1)和第二脉冲周期per(2),enc_out(1)表示第一脉冲周期per(1)的输入脉冲信号、enc_out(2)表示第二脉冲周期per(2)的输入脉冲信号,t(0)至t(7)表示处理芯片的运算周期。其中,处理芯片10得到的包括n个脉冲周期的输入脉冲信号enc_out只接入到part0,脉冲神经网络的第一层layer(1)只会映射到part0。当part0被映射到脉冲神经网络的第一层layer(1)时,part0的输入为输入脉冲信号enc_out;否则part0的输入为part1的输出脉冲信号,part1的输入均为part0的输出脉冲信号,第三层layer(3)的输出脉冲信号即为脉冲神经网络的输出脉冲信号。
86.处理芯片10在运算周期t(0)内没有运算,第一脉冲周期per(1)的输入脉冲信号输出到part0,写入到part0的内部缓存中,layer(1)的权重从外部存储器20读出,写入part0的内部缓存中。
87.处理芯片10在运算周期t(1)内执行第一脉冲周期per(1)的layer(1)运算,运算由part0完成,part1不运算;同时part0的输出脉冲信号给part1,写入到part1的内部缓存中;part0将计算得到第一脉冲周期per(1)的layer(1)的膜电压写入到外部存储器20中;从外部存储器20读取layer(2)的权重,并写入part1的内部缓存中。
88.处理芯片10在运算周期t(2)内执行第一脉冲周期per(1)的layer(2)运算,运算由part1完成,part0不运算;同时part1的输出脉冲信号给part0,写入到part0的内部缓存中;part1将计算得到第一脉冲周期per(1)的layer(2)的膜电压写入到外部存储器20中;从外部存储器20读取layer(3)的权重,并写入part0的内部缓存中。
89.处理芯片10在运算周期t(3)内执行第一脉冲周期per(1)的layer(3)运算,运算由part0完成,part1不运算;同时part0的输出脉冲信号作为第一脉冲周期per(1)内脉冲神经网络的输出;part0将计算得到第一脉冲周期per(1)的layer(3)的膜电压写入到外部存储器20中。
90.处理芯片10在运算周期t(4)内没有运算;第二脉冲周期per(2)的输入脉冲信号输出到part0,写入到part0的内部缓存中;从外部存储器20读取layer(1)的权重,并写入part0的内部缓存中;从外部存储器20读取第一脉冲周期per(1)的layer(1)的膜电压,并写入part0的内部缓存中。
91.处理芯片10在运算周期t(5)内执行第二脉冲周期per(2)的layer(1)运算,运算由part0完成,part1不运算;同时part0的输出脉冲信号给part1,写入到part1的内部缓存中;part0将计算得到第二脉冲周期per(2)的layer(1)的膜电压写入到外部存储器20中;从外部存储器20读取layer(2)的权重,并写入part1的内部缓存中;从外部存储器20读取第一脉冲周期per(1)的layer(2)的膜电压,并写入part1的内部缓存中。
92.处理芯片10在运算周期t(6)内执行第二脉冲周期per(2)的layer(2)运算,运算由part1完成,part0不运算;同时part1的输出脉冲信号给part0,写入到part0的内部缓存中;part1将计算得到第二脉冲周期per(2)的layer(2)的膜电压写入到外部存储器20中;从外部存储器20读取layer(3)的权重,并写入part0的内部缓存中;从外部存储器20读取第一脉
冲周期per(1)的layer(3)的膜电压,并写入part0的内部缓存中。
93.处理芯片10在运算周期t(7)内执行第二脉冲周期per(2)的layer(3)运算,运算由part0完成,part1不运算;同时part0的输出脉冲信号作为层第二脉冲周期per(2)内脉冲神经网络的输出。
94.由上可知,在每个运算周期中仅有一组神经元核进行运算,另一组神经元核加载权重,运算与权重加载发生在不同组的神经元核中,从而能够充分利用处理芯片的资源,进一步提升了处理芯片的利用。
95.本发明第五实施例涉及一种信号处理设备,例如为笔记本电脑、台式主机、平板电脑等电子设备,请参考图10,信号处理设备包括第三实施例或第四实施例中的处理芯片10以及与处理芯片10连接的外部存储器20。
96.以上已详细描述了本发明的较佳实施例,但应理解到,若需要,能修改实施例的方面来采用各种专利、申请和出版物的方面、特征和构思来提供另外的实施例。
97.考虑到上文的详细描述,能对实施例做出这些和其它变化。一般而言,在权利要求中,所用的术语不应被认为限制在说明书和权利要求中公开的具体实施例,而是应被理解为包括所有可能的实施例连同这些权利要求所享有的全部等同范围。