1.本发明涉及计算机软件技术领域,具体涉及一种基于机器视觉的纠正发音的方法。
背景技术:
2.通常情况下,学习各种语言都会朗读、跟读来提升自身的发音能力,多数情况下学习者无法得知自身发音是否准确。故而,市面上出现了多种自带发音测评功能或者发音纠正功能的语言学习软件。
3.现有的语言学习软件所得到的发音测评结果无法指正具体发音错误,导致发音测评结果缺乏针对性。对此,已有中国专利出公开相应的语言学习的纠正发音的装置,通过输出预设的标准发音音频和标准口型影像,并获取跟读时的用户发音和用户口型,实时输出用户发音和用户口型影像;将用户发音与标准发音音频进行比对,将用户口型影像与标准口型影像进行比对,从而评估用户发音的准确度,辅助用户调整自己的发音口型和发音音调,达到纠正用户错误发音的效果。但是,对于某些混淆发音来说,比如平舌音与翘舌音,标准发音音频与标准口型影响存在很大的相似之处,会使得无法准确地识别并纠正发音错误。
技术实现要素:
4.本发明提供一种基于机器视觉的纠正发音的方法,解决了现有技术无法准确识别并纠正混淆发音的技术问题。
5.本发明提供的基础方案为:一种基于机器视觉的纠正发音的方法,包括:
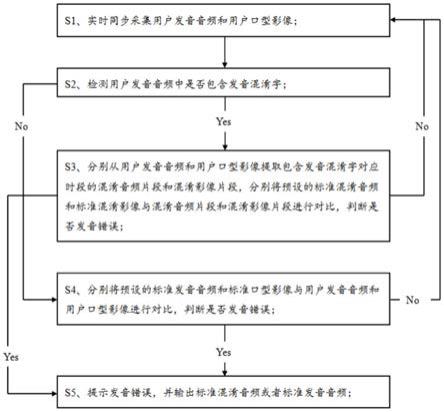
6.s1、实时同步采集用户发音音频和用户口型影像;
7.s2、检测用户发音音频中是否包含发音混淆字:若是,进行s3;若否,进行s4;
8.s3、分别从用户发音音频和用户口型影像提取包含发音混淆字对应时段的混淆音频片段和混淆影像片段,分别将预设的标准混淆音频和标准混淆影像与混淆音频片段和混淆影像片段进行对比,判断是否发音错误:若是,进行s5;若否,返回s1;
9.s4、分别将预设的标准发音音频和标准口型影像与用户发音音频和用户口型影像进行对比,判断是否发音错误:若是,进行s5;若否,返回s1;
10.s5、提示发音错误,并输出标准混淆音频或者标准发音音频。
11.本发明的工作原理及优点在于:实时同步采集用户发音音频和用户口型影像,确保用户发音音频和用户口型影像在时间上是相互对应的;为了识别并纠正混淆发音,需要检测用户发音音频中是否包含发音混淆字,如果包含发音混淆字,就需要分别从用户发音音频和用户口型影像提取包含发音混淆字对应时段的混淆音频片段和混淆影像片段,并分别将标准混淆音频和标准混淆影像与混淆音频片段和混淆影像片段进行对比,判断是否发音错误。通过这样的方式,不仅能够对平常的发音进行纠正,还能够对混淆发音进行纠正,避免遗漏掉对混淆发音的纠正。
12.本发明既能对平常的发音进行纠正,又能对混淆发音进行纠正,避免遗漏掉对混淆发音的纠正,解决了现有技术无法准确识别并纠正混淆发音的技术问题。
13.进一步,s2中,检测用户发音音频中是否包含发音混淆字包括:将用户发音音频转化成发音数字信号,并对数字信号进行特征提取,得到发音特征的关键参数,根据关键参数判定是否包含发音混淆字。
14.有益效果在于:由于多数发音混淆字的发音特征具有相似之处,关键参数则可以对发音特征进行量化,故而可以精确地检测用户发音音频中是否包含发音混淆字。
15.进一步,s3中,从用户发音音频和用户口型影像提取包含发音混淆字对应时段的混淆音频片段和混淆影像片段之前,检测发音起始点和发音结束点,并剪切掉用户发音音频和用户口型影像中发音起始点之前的部分以及发音结束点之后的部分。
16.有益效果在于:通过这样的方式,对用户发音音频和用户口型影像进行“掐头去尾”的处理,确保用户发音音频和用户口型影像均是对应有声音的,减少处理的运算量。
17.进一步,s5中,还包括根据标准混淆音频得到标准混淆波形图,或者根据标准发音音频得到标准发音波形图,并显示标准混淆波形图或者标准发音波形图。
18.有益效果在于:这样显示出标准混淆波形图或者标准发音波形图,便于用户进行查看,并根据标准混淆波形图或者标准发音波形图模仿发音,提高纠正效率。
19.进一步,s5中,还包括显示标准混淆影像或者标准口型影像,标准混淆影像与标准混淆波形图同步对比显示,或者标准口型影像与标准发音波形图同步对比显示。
20.有益效果在于:这样进行对比显示,便于同步对比观察发音的变化特点与口型的变化特点,更加准确地指导用户纠正发音变化与口型变化。
21.进一步,s5中,还包括根据标准混淆音频或者标准发音音频给出纠正建议。
22.有益效果在于:直接给出纠正建议,相较于给出标准混淆音频或者标准发音音频来说,这种纠正更加快速、直接。
23.进一步,s3中,以音素为单位将标准混淆音频与混淆音频片段进行对比;s4中,以音素为单位将标准发音音频与用户发音音频进行对比。
24.有益效果在于:音素是根据语音的自然属性划分出来的最小语音单位,依据音节里的发音动作来分析,一个动作构成一个音素,这样可以更加精细、更加准确地对比发音特点。
25.进一步,s3中,以帧为单位将标准混淆影像与混淆影像片段进行对比;s4中,以帧为单位将标准口型影像与用户口型影像进行对比。
26.有益效果在于:帧是影像动画中最小单位的单幅影像画面,连续的帧就可以形成动画,这样可以更加精细、更加准确地对比发音的动作、发音时的口型变化规律。
27.进一步,s3中,从用户发音音频和用户口型影像提取包含发音混淆字对应时段的混淆音频片段和混淆影像片段之前,对用户发音音频和用户口型影像进行降噪处理。
28.有益效果在于:这样可以提高用户发音音频和用户口型影像的质量,确保提取过程的准确性与精确性。
附图说明
29.图1为本发明一种基于机器视觉的纠正发音的方法实施例的流程图。
具体实施方式
30.下面通过具体实施方式进一步详细的说明:
31.实施例1
32.实施例基本如附图1所示,包括:
33.s1、实时同步采集用户发音音频和用户口型影像;
34.s2、检测用户发音音频中是否包含发音混淆字:若是,进行s3;若否,进行s4;
35.s3、分别从用户发音音频和用户口型影像提取包含发音混淆字对应时段的混淆音频片段和混淆影像片段,分别将预设的标准混淆音频和标准混淆影像与混淆音频片段和混淆影像片段进行对比,判断是否发音错误:若是,进行s5;若否,返回s1;
36.s4、分别将预设的标准发音音频和标准口型影像与用户发音音频和用户口型影像进行对比,判断是否发音错误:若是,进行s5;若否,返回s1;
37.s5、提示发音错误,并输出标准混淆音频或者标准发音音频。
38.具体实施过程如下:
39.s1、实时同步采集用户发音音频和用户口型影像。比如说,通过拾音器实时采集朗读或者跟读时的用户发音音频,通过摄像头实时采集朗读或者跟读时的用户口型影像,用户发音音频和用户口型影像的采集是同步进行的。
40.s2、检测用户发音音频中是否包含发音混淆字:若是,进行s3;若否,进行s4。在本实施例中,考虑到多数发音混淆字的发音特征具有相似之处,比如说平舌音和翘舌音、前鼻韵和后鼻韵,关键参数可以对发音特征进行量化,故而,将用户发音音频转化成发音数字信号,对数字信号进行特征提取,得到发音特征的关键参数,比如说音调、频率,根据关键参数判定是否包含发音混淆字,这样可以精确地检测用户发音音频中是否包含发音混淆字。
41.s3、分别从用户发音音频和用户口型影像提取包含发音混淆字对应时段的混淆音频片段和混淆影像片段,分别将预设的标准混淆音频和标准混淆影像与混淆音频片段和混淆影像片段进行对比,判断是否发音错误:若是,进行s5;若否,返回s1。
42.在本实施例中,首先,从用户发音音频和用户口型影像提取包含发音混淆字对应时段的混淆音频片段和混淆影像片段之前,检测发音起始点和发音结束点,并剪切掉用户发音音频和用户口型影像中发音起始点之前的部分以及发音结束点之后的部分,对用户发音音频和用户口型影像进行“掐头去尾”的处理,确保用户发音音频和用户口型影像均是对应有声音的,减少后续处理的运算量。然后,以音素为单位将标准混淆音频与混淆音频片段进行对比,得到发音准确度的第一评分;以帧为单位将标准混淆影像与混淆影像片段进行对比,得到发音准确度的第二评分;根据预设的第一评分和第二评分的权重值计算发音准确度的第一总评分,根据第一总评分判断是否发音错误,比如说,发音准确度的第一总评分低于预设评分阈值就判定发音错误。
43.s4、分别将预设的标准发音音频和标准口型影像与用户发音音频和用户口型影像进行对比,判断是否发音错误:若是,进行s5;若否,返回s1。在本实施例中,以音素为单位将标准发音音频与用户发音音频进行对比,得到发音准确度的第三评分;以帧为单位将标准口型影像与用户口型影像进行对比,得到发音准确度的第四评分;根据预设的第三评分和第四评分的权重值计算发音准确度的第二总评分,根据第二总评分判断是否发音错误,比如说,发音准确度的第二总评分低于预设评分阈值就判定发音错误。由于音素是根据语音
的自然属性划分出来的最小语音单位,依据音节里的发音动作来分析,这样可以更加精细、更加准确地对比发音特点;同时,帧是影像动画中最小单位的单幅影像画面,这样可以更加精细地对比发音的动作、发音时的口型变化规律。
44.s5、提示发音错误,并输出标准混淆音频或者标准发音音频。
45.在本实施例中,在提示发音错误,并输出标准混淆音频或者标准发音音频之后,根据标准混淆音频或者标准发音音频给出纠正建议,具体如下:根据标准混淆音频得到标准混淆波形图,或者根据标准发音音频得到标准发音波形图,并显示标准混淆波形图或者标准发音波形图,便于根据标准混淆波形图或者标准发音波形图模仿发音,提高纠正效率;与此同时,显示标准混淆影像或者标准口型影像,而且,标准混淆影像与标准混淆波形图同步对比显示,或者标准口型影像与标准发音波形图同步对比显示,这样进行对比显示,便于同步对比观察发音的变化特点与口型的变化特点,更加准确地指导用户纠正发音变化与口型变化。这样可以直接给出纠正建议,相较于给出标准混淆音频或者标准发音音频来说,这种纠正更加快速、直接。
46.本方案中,实时同步采集用户发音音频和用户口型影像,确保用户发音音频和用户口型影像在时间上是相互对应的;为了识别并纠正混淆发音,需要检测用户发音音频中是否包含发音混淆字,如果包含发音混淆字,就需要分别从用户发音音频和用户口型影像提取包含发音混淆字对应时段的混淆音频片段和混淆影像片段,并分别将标准混淆音频和标准混淆影像与混淆音频片段和混淆影像片段进行对比,判断是否发音错误,从而能够有效地对混淆发音进行纠正。
47.实施例2
48.与实施例1不同之处仅在于,s3中,从用户发音音频和用户口型影像提取包含发音混淆字对应时段的混淆音频片段和混淆影像片段之前,对用户发音音频和用户口型影像进行降噪处理,比如说采用高斯滤波,这样可以提高用户发音音频和用户口型影像的质量,确保提取过程的准确性与精确性。
49.实施例3
50.与实施例2不同之处仅在于,s3中还检测用户发音音频中是否包含发音混淆方言:若是,分别从用户发音音频和用户口型影像提取包含发音混淆方言对应时段的混淆音频片段和混淆影像片段,分别将发音混淆方言对应的预设的标准混淆音频和标准混淆影像与混淆音频片段和混淆影像片段进行对比,判断是否发音错误:若是,进行s5;若否,返回s1。在本实施例中,考虑这样的情况:由于汉语文化博大精深,各地都有独特的地方性方言,特别是四川方言,很多方言的发音均有对应的普通话的发音,但是两者的意思却完全不同。比如说,四川方言“不知道具体情况,不要乱kai qiang”,这句四川方言中的发音“kai qiang”是指“开腔”,极有可能被听者理解为“开枪”。类似这种发音相同,但是意思的不同的方言还有很多,本实施例中,将这种发音相同、意思不同的方言定义为发音混淆方言。
51.在本实施例中,检测用户发音音频中是否包含有发音混淆方言的具体过程如下:首先,从预先建立的方言数据库中提取四川方言的语音特征,建立卷积神经网络模型,并对卷积神经网络模型进行训练。方言数据库中包含全国各地的方言数据,例如,语音特征、语言含义以及文本数据;特别地,还包含发音相同、意思不同的发音混淆方言,并且基于hadoop平台建方言数据库。然后,使用vad技术对用户发音音频按频率进行分段处理,对分
段处理后的用户发音音频进行降噪处理,之后提取用户发音音频的语音特征。最后,将训练后的卷积神经网络模型进行语音特征匹配检测,检测用户发音音频的语音特征是否存在于方言数据库中:若匹配成功,表明用户发音音频中包含有发音混淆方言;反之,若匹配失败,表明用户发音音频中不包含有发音混淆方言。通过这样的方式,既能够纠正平常的发音,又能够纠正发音混淆方言,进而避免发音受到方言的影响,提高纠正的有效性。
52.以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述,所属领域普通技术人员知晓申请日或者优先权日之前发明所属技术领域所有的普通技术知识,能够获知该领域中所有的现有技术,并且具有应用该日期之前常规实验手段的能力,所属领域普通技术人员可以在本技术给出的启示下,结合自身能力完善并实施本方案,一些典型的公知结构或者公知方法不应当成为所属领域普通技术人员实施本技术的障碍。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本技术要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。