1.本发明涉及语音识别技术领域,尤其涉及一种中文语音声学训练模型构建方法和基于中文语音声学训练模型的测试方法。
背景技术:
2.语音识别作为人工智能中重要的组成部分,近年来得到越来越多的关注,也取得了长足的发展和进步。深度神经网络(deep neural network,dnn)因其出色的分类能力和非线性关系的表达能力,被越来越广泛的应用在语音识别声学和语言模型的建模过程中,极大的提升了语音识别的性能。最近几年,研究人员更提出了端到端的学习方法,对整个学习过程取消了传统声学和语言模型的划分,将学习完全交给深度学习模型以完成从原始数据到期望输出的直接映射,省去了原本每个独立任务执行前必要的大量标注和资源准备工作,避免了独立任务衔接时引入的误差,提高了语音识别的性能,同时也提高了语音识别应用落地的速度。
3.但是,众所周知,语音识别声学模型建模,音素集的设计极为关键,每个语言都会根据各自发音的特点,构建符合该语言特征的音素集用于声学模型的建模,进而影响语音识别的性能。中文有别于印欧语系、阿尔泰语系、部分汉藏语系等大多数语言,属于一种有调语言,声调在表意上是不可或缺的,因此中文音素集的构建存在各种可能和变化,在语音识别的性能上也有不同的优缺点。以pian2这个发音为例,存在以下几种常见的音素拆分形式:
4.1.声母独立、韵母和声调合并,声调按1声~5声标识。例如:pian2 p ian2。
5.2.合并声母和介音,韵腹和韵尾合并,声调按1声~5声标识。例如:pian2pi an2。
6.3.声母、介音独立,韵腹和韵尾合并,声调按1声~5声标识。例如:pian2p i an2。
7.4.声母独立、韵母拆成两部分,声调根据基频高低在两个子韵母上按high/middle/low标识。例如:pian2 p ia_l an_h。
8.针对以上的示例,传统语音识别的技术方案会出现几个缺陷。
9.第一,个别发音和声调的组合在训练语料里出现次数过少,导致个别音素训练不完全。第二,中文存在声调组合变调的发音规律,实际发音与单字发音不同,词典中可能未能体现这种变调情形,导致引入错误发音或者缺少正确发音。第三,训练语料中的说话人存在轻微口音(声母、韵母,声调其中之一变化)导致发音和标注不一致。这些都将为中文语言模型训练的数据准备带来困难,为训练过程引入负面的影响。
技术实现要素:
10.本发明的目的在于,解决中文声学模型训练中存在的上述问题,提供了一种中文语音声学训练模型构建方法和基于中文语音声学训练模型的测试方法。
11.中文语音声学训练模型构建方法包括:
12.准备语音训练资源;
13.将语音训练资源通过三音素gmm模型进行时间轴的对齐,得到有调发音结果;
14.将有调发音结果拆分为无调发音对齐结果和声调对齐结果;
15.通过有调发音结果训练神经网络模型;
16.基于神经网络模型构建中文语音声学训练模型。
17.优选的,无调发音对齐结果包括声母和去调韵母的音素对齐形式,且无调发音对齐结果的分类数目为声母数和韵母数的总和,中文发音有23个声母和24个韵母,所以无调发音对齐结果的分类数目为47。
18.优选的,声调对齐结果包括:阴平、阳平、上声、去声、轻声以及一个无调标注的对齐结果,该无调标注用于标识非语音段以及不含调性语音段的声调,声调对齐结果的分类数目为6。
19.优选的,神经网络模型包含1个输入层、n个隐藏层和1个输出层,输出层是基于有调音素对应的三音素绑定后的状态集,其中,n为正整数。
20.优选的,构建中文语音声学训练模型,包括:
21.神经网络模型训练完成后,去除神经网络模型的输出层;
22.构建无调发音分类任务输出层和声调分类任务输出层;
23.将无调发音分类任务输出层和声调分类任务输出层分别与第n个隐藏层做全连接处理;
24.进行分任务训练,获得中文语音声学训练模型。
25.优选的,无调发音分类任务输出层输出声母和无调韵母,无调发音分类任务输出层的节点由中文音素确定,无调发音分类任务输出层的节点数与无调发音对齐结果的分类数目一致。
26.优选的,声调分类任务输出层输出阴平、阳平、上声、去声、轻声或无调标注,该无调标注用于标识非语音段以及不含调性语音段的声调,声调分类任务输出层的节点由中文发音确定,声调分类任务输出层的节点数与声调对齐结果的分类数目一致。
27.基于中文语音声学训练模型的测试方法包括:
28.接收测试语音;
29.将测试语音输入中文语音声学训练模型,通过无调发音分类任务输出层和声调分类任务输出层获得对应的无调发音输出结果和声调输出结果;
30.将无调发音输出结果和声调输出结果分别进行时间轴的对齐,融合得到的对齐结果,得到音节输出;
31.将音节输出进行反向映射,完成音节到中文的转换,得到最终识别结果。
32.优选的,将无调发音输出结果和声调输出结果分别进行时间轴的对齐,融合得到的对齐结果,包括:以m倍帧率,每m帧做一次无调发音和声调的平滑对齐结果融合,以m帧内占比最大的平滑对齐结果融合作为该m帧有调发音的解码结果,其中,m为正整数。
33.优选的,音节输出由相邻的相同解码结果合并获得。
附图说明
34.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于
本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
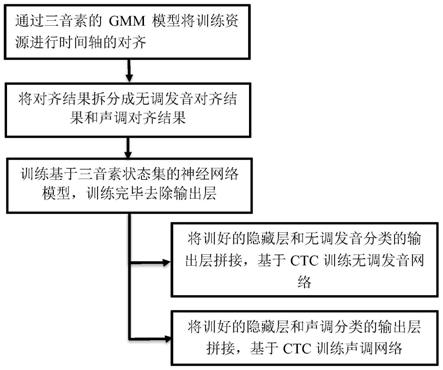
35.图1为本发明的中文语音声学训练模型构建的整体流程图;
36.图2为基于中文语音声学训练模型的测试流程图;
37.图3为神经网络模型示意图(拼接前);
38.图4为中文语音声学训练模型示意图(拼接后)。
具体实施方式
39.为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
40.下面对本发明结合附图作进一步详细的说明。
41.如图1所示,本发明提供了一种针对中文语音声学训练模型构建的方法,图2示意了针对中文语音声学训练模型的测试方法的流程。考虑到中文是有调语言,本发明将中文发音拆解为无调发音和声调两部分进行多任务训练。
42.实施例一
43.本实施例提供一种针对中文语音声学训练模型构建的方法,包括:
44.准备语音训练资源;
45.将语音训练资源基于三音素gmm模型通过kaldi指令进行对齐,得到有调发音结果。此处的对齐是采用声母独立、韵母和声调合并,声调按1声~5声标识的音素结构,声调归并在音素中以作标识,例如pian2,在对齐之后可以获得p和ian2的各自对应区间。如果有较为成熟的神经网络模型也可代替此处的三音素gmm模型。
46.将有调发音结果拆分为无调发音对齐结果和声调对齐结果。无调发音对齐结果包括声母和去调韵母的音素对齐形式,无调发音对齐结果的分类数目为声母数和韵母数的总和,中文发音有23个声母和24个韵母,所以无调发音对齐结果的分类数目为47;声调对齐结果除了阴平、阳平、上声、去声、轻声,还添加了一个无调标识,该无调标注用于标识非语音段以及不含调性语音段的声调,声调对齐结果的分类数目为6。
47.通过有调发音结果训练神经网络模型。神经网络模型包含1个输入层、n个隐藏层和1个输出层,输出层是基于有调音素对应的三音素绑定后的状态集,其中,n为正整数。此处训练神经网络模型可以使用tdnn,lstm等框架结构。
48.神经网络模型训练完成后,去除神经网络模型的输出层。
49.构建无调发音分类任务输出层和声调分类任务输出层。其中无调发音分类任务输出层输出声母和无调韵母,无调发音分类任务输出层的节点由中文音素确定,无调发音分类任务输出层的节点数与无调发音对齐结果的分类数目一致;声调分类任务输出层的节点由中文发音确定,声调分类任务输出层输出阴平、阳平、上声、去声、轻声或无调标注,该无调标注用于标识非语音段以及不含调性语音段的声调,声调分类任务输出层的节点数与声调对齐结果的分类数目一致。
50.将无调发音分类任务输出层和声调分类任务输出层分别与第n个隐藏层做全连接
处理。
51.基于ctc进行分任务训练,获得中文语音声学训练模型,中文声学训练模型包括第一神经网络分类模型和第二神经网络分类模型。
52.到此训练模型构建部分结束。
53.实施例二
54.本实施例提供一种基于中文语音声学训练模型的测试方法,包括:
55.接收测试语音;
56.将测试语音输入中文语音声学训练模型,通过无调发音分类任务输出层和声调分类任务输出层获得对应的无调发音输出结果和声调输出结果;
57.将无调发音输出结果和声调输出结果分别进行时间轴的对齐,以m倍帧率,每m帧做一次无调发音和声调的平滑对齐结果融合,以m帧内占比最大的平滑对齐结果融合作为该m帧有调发音的解码结果,将相邻的相同解码结果合并,得到音节输出;
58.将音节输出进行反向映射,完成音节到中文的转换,得到最终识别结果。