1.本公开的实施方式涉及音频处理技术领域,更具体地,本公开的实施方式涉及一种音频处理方法和装置、计算机可读存储介质和计算设备。
背景技术:
2.本部分旨在为权利要求书中陈述的本公开的实施方式提供背景或上下文。此处的描述不因为包括在本部分中就承认是现有技术。
3.近年来,随着人工智能技术的不断发展,音频的自动化处理越来越普遍,在音频处理的诸多类型之中,为音频生成摘要越来越受到大家的青睐。为音频生成摘要,可以是针对特定音频生成用以描述音频内容的自然语言。例如给定一段开关门的音频,可能会生成下述摘要:门在缓慢地回来旋转时发出吱吱声。但是,相关技术中用于为音频生成摘要的音频摘要生成模型的准确率和效率都较低。
技术实现要素:
4.在本上下文中,本公开的实施方式期望提供一种音频处理方法和装置、计算机可读存储介质和计算设备,以提高音频摘要的生成准确率和效率。
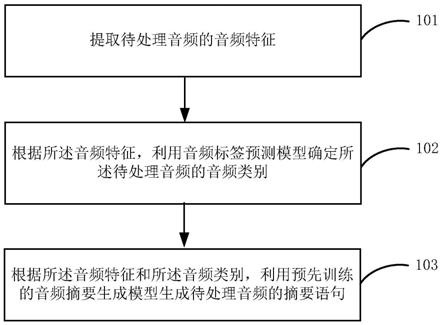
5.在本公开实施方式的第一方面中,提供了一种音频处理方法,包括:
6.提取待处理音频的音频特征;
7.根据所述音频特征,利用音频标签预测模型确定所述待处理音频的音频类别;
8.根据所述音频特征和所述音频类别,利用预先训练的音频摘要生成模型生成待处理音频的摘要语句。
9.在本公开的一个实施例中,所述提取待处理音频的音频特征,包括:
10.采用预设频率对所述待处理音频进行采样处理,得到采样结果;
11.对采样结果进行特征提取,得到特征序列,作为所述音频特征。
12.在本公开的另一个实施例中,所述根据所述音频特征,利用音频标签预测模型确定所述待处理音频的音频类别,包括:
13.将所述音频特征输入至所述音频标签预测模型,所述音频标签预测模型输出标签库中的至少一个音频标签的评分;
14.根据评分从所述至少一个音频标签中选择预设数量的音频标签,作为保留标签;
15.从标签库中确定每个所述保留标签对应的候选音频类别;
16.从预设数量的所述候选音频类别中确定一个作为所述待处理音频的音频类别。
17.在本公开的又一个实施例中,还包括:
18.在所述输出标签库中的至少一个音频标签的评分之后,对所述评分进行归一化处理;
19.所述根据评分从所述至少一个音频标签中选择预设数量的音频标签,作为保留标签,包括:
20.根据归一化处理后的评分从所述至少一个音频标签中选择预设数量的音频标签,作为保留标签。
21.在本公开的再一个实施例中,所述根据评分从所述至少一个音频标签中选择预设数量的音频标签,作为保留标签,包括:
22.在所述至少一个音频标签中,保留评分高于预设评分阈值的音频标签;
23.响应于保留的音频标签的数量小于或等于所述预设数量,将保留的音频标签全部作为保留标签;
24.响应于保留的音频标签的数量大于所述预设数量,按照评分从大到小的顺序从保留的音频标签中,选择预设数量的音频标签作为保留标签。
25.在本公开的再一个实施例中,所述标签库内具有多个音频标签,所述多个音频标签之间具有树形层级关系,每个音频标签均具有上一级和/或下一级音频标签,所述标签库中的至少一个音频标签预先标记为第一类标签;
26.所述从标签库中确定每个所述保留标签对应的候选音频类别,包括:
27.响应于所述保留标签为第一类标签,确定所述第一类标签为所述保留标签对应的候选音频类别;
28.否则,以所述保留标签为起始层级,在标签库中逐级确定上级音频标签,直至所述上级音频标签为第一类标签,确定所述第一类标签为所述保留标签对应的候选音频类别。
29.在本公开的再一个实施例中,还包括:
30.将所述标签库中的至少一个音频标签标记为第一类标签。
31.在本公开的再一个实施例中,所述从预设数量的候选音频类别中确定一个作为所述待处理音频的音频类别:
32.确定每个所述候选音频类别的综合评分,其中,所述综合评分为所述候选音频类别对应的全部下级音频标签的评分的和;
33.确定综合评分最高的所述候选音频类别为所述待处理音频的音频类别。
34.在本公开的再一个实施例中,所述根据所述音频特征和所述音频类别,利用预先训练的音频摘要生成模型生成待处理音频的摘要语句,包括:
35.所述音频摘要生成模型的编码模块对所述音频特征进行编码,得到编码向量;
36.所述音频摘要生成模型的解码模块根据所述编码向量和初始词序列,生成所述待处理音频的摘要语句,其中,所述初始词序列包括初始词向量和所述音频类别的标签词向量。
37.在本公开的再一个实施例中,所述根据所述编码向量和初始词序列,生成所述待处理音频的摘要语句,包括:
38.根据所述编码向量和所述初始词序列,生成所述摘要语句的第一组词向量;
39.根据所述初始词序列和前i组词向量组成的词序列,以及所述编码向量生成第i+1组词向量,直至生成终止词向量,其中,i≥1,每组词向量均包括至少一个词向量。
40.在本公开的再一个实施例中,所述根据所述编码向量和所述初始词序列,生成所述摘要语句的第一组词向量,包括:
41.将所述初始词序列嵌入所述编码向量内,形成第一向量,并通过解码所述第一向量生成所述摘要语句的第一组词向量;
42.根据所述初始词序列和前i组词向量组成的词序列,以及所述编码向量生成第i+1组词向量,包括:
43.将所述初始词序列和前i组词向量组成的词序列嵌入所述编码向量内,形成第二向量,并通过解码所述第二向量生成第i+1组词向量。
44.在本公开的再一个实施例中,按照下述方式生成第i+1组词向量:
45.确定预设词表中至少一个词向量的目标概率,所述目标概率为所述词向量属于所述第i+1组词向量的概率;
46.根据所述至少一个词向量的目标概率,生成所述第i+1组词向量。
47.在本公开的再一个实施例中,还包括:
48.提取训练集中的训练音频的音频特征,其中,所述训练音频标记有类别标签和摘要标签;
49.将所述训练音频的音频特征和类别标签输入至所述音频摘要生成模型中,所述音频摘要生成模型输出所述训练音频的预测标签;
50.根据所述摘要标签和所述预测标签确定网络损失值,并根据所述网络损失值调整所述音频摘要生成模型的编码模块和解码模块的网络参数。
51.在本公开实施方式的第二方面中,提供了一种音频处理装置,包括:
52.特征模块,用于提取待处理音频的音频特征;
53.类别模块,用于根据所述音频特征,利用音频标签预测模型确定所述待处理音频的音频类别;
54.摘要模块,用于根据所述音频特征和所述音频类别,利用预先训练的音频摘要生成模型生成待处理音频的摘要语句。
55.在本公开的一个实施例中,所述特征模块具体用于:
56.采用预设频率对所述待处理音频进行采样处理,得到采样结果;
57.对采样结果进行特征提取,得到特征序列,作为所述音频特征。
58.在本公开的另一个实施例中,所述类别模块具体用于:
59.将所述音频特征输入至所述音频标签预测模型,所述音频标签预测模型输出标签库中的至少一个音频标签的评分;
60.根据评分从所述至少一个音频标签中选择预设数量的音频标签,作为保留标签;
61.从标签库中确定每个所述保留标签对应的候选音频类别;
62.从预设数量的所述候选音频类别中确定一个作为所述待处理音频的音频类别。
63.在本公开的又一个实施例中,所述类别模块还用于:
64.在所述输出标签库中的至少一个音频标签的评分之后,对所述评分进行归一化处理;
65.所述类别模块用于根据评分从所述至少一个音频标签中选择预设数量的音频标签,作为保留标签时,具体用于:
66.根据归一化处理后的评分从所述至少一个音频标签中选择预设数量的音频标签,作为保留标签。
67.在本公开的再一个实施例中,所述类别模块用于根据评分从所述至少一个音频标签中选择预设数量的音频标签,作为保留标签时,具体用于:
68.在所述至少一个音频标签中,保留评分高于预设评分阈值的音频标签;
69.响应于保留的音频标签的数量小于或等于所述预设数量,将保留的音频标签全部作为保留标签;
70.响应于保留的音频标签的数量大于所述预设数量,按照评分从大到小的顺序从保留的音频标签中,选择预设数量的音频标签作为保留标签。
71.在本公开的再一个实施例中,所述标签库内具有多个音频标签,所述多个音频标签之间具有树形层级关系,每个音频标签均具有上一级和/或下一级音频标签,所述标签库中的至少一个音频标签预先标记为第一类标签;
72.所述类别模块用于从标签库中确定每个所述保留标签对应的候选音频类别时,具体用于:
73.响应于所述保留标签为第一类标签,确定所述第一类标签为所述保留标签对应的候选音频类别;
74.否则,以所述保留标签为起始层级,在标签库中逐级确定上级音频标签,直至所述上级音频标签为第一类标签,确定所述第一类标签为所述保留标签对应的候选音频类别。
75.在本公开的再一个实施例中,还包括标记模块,用于:
76.将所述标签库中的至少一个音频标签标记为第一类标签。
77.在本公开的再一个实施例中,所述摘要模块具体用于:
78.确定每个所述候选音频类别的综合评分,其中,所述综合评分为所述候选音频类别对应的全部下级音频标签的评分的和;
79.确定综合评分最高的所述候选音频类别为所述待处理音频的音频类别。
80.在本公开的再一个实施例中,所述摘要模块用于根据所述音频特征和所述音频类别,利用预先训练的音频摘要生成模型生成待处理音频的摘要语句时,具体用于:
81.所述音频摘要生成模型的编码模块对所述音频特征进行编码,得到编码向量;
82.所述音频摘要生成模型的解码模块根据所述编码向量和初始词序列,生成所述待处理音频的摘要语句,其中,所述初始词序列包括初始词向量和所述音频类别的标签词向量。
83.在本公开的再一个实施例中,所述摘要模块用于根据所述编码向量和初始词序列,生成所述待处理音频的摘要语句时,具体用于:
84.根据所述编码向量和所述初始词序列,生成所述摘要语句的第一组词向量;
85.根据所述初始词序列和前i组词向量组成的词序列,以及所述编码向量生成第i+1组词向量,直至生成终止词向量,其中,i≥1,每组词向量均包括至少一个词向量。
86.在本公开的再一个实施例中,所述摘要模块用于根据所述编码向量和所述初始词序列,生成所述摘要语句的第一组词向量时,具体用于:
87.将所述初始词序列嵌入所述编码向量内,形成第一向量,并通过解码所述第一向量生成所述摘要语句的第一组词向量;
88.根据所述初始词序列和前i组词向量组成的词序列,以及所述编码向量生成第i+1组词向量,包括:
89.将所述初始词序列和前i组词向量组成的词序列嵌入所述编码向量内,形成第二向量,并通过解码所述第二向量生成第i+1组词向量。
90.在本公开的再一个实施例中,所述摘要模块用于按照下述方式生成第i+1组词向量:
91.确定预设词表中至少一个词向量的目标概率,所述目标概率为所述词向量属于所述第i+1组词向量的概率;
92.根据所述至少一个词向量的目标概率,生成所述第i+1组词向量。
93.在本公开的再一个实施例中,还包括训练模块,用于:
94.提取训练集中的训练音频的音频特征,其中,所述训练音频标记有类别标签和摘要标签;
95.将所述训练音频的音频特征和类别标签输入至所述音频摘要生成模型中,所述音频摘要生成模型输出所述训练音频的预测标签;
96.根据所述摘要标签和所述预测标签确定网络损失值,并根据所述网络损失值调整所述音频摘要生成模型的编码模块和解码模块的网络参数。
97.在本公开实施方式的第三方面中,提供了一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现第一方面所述的方法。
98.在本公开实施方式的第四方面中,提供了一种计算设备,所述计算设备包括存储器、处理器,所述存储器用于存储可在处理器上运行的计算机指令,所述处理器用于在执行所述计算机指令时实现第一方面所述的方法。
99.根据本公开实施方式的音频处理方法和装置、计算机可读存储介质和计算设备,通过提取待处理音频的音频特征,再根据所述音频特征,利用音频标签预测模型确定所述待处理音频的音频类别,最后根据所述音频特征和所述音频类别,利用预先训练的音频摘要生成模型生成待处理音频的摘要语句。由于生成摘要语句时结合了音频特征和音频类别,音频类别能够指示摘要语句的生成方向,从而缩小摘要语句的选择范围,因此相对于相关技术中仅利用音频特征生成的摘要语句,准确率和效率得到了极大的提高。
附图说明
100.通过参考附图阅读下文的详细描述,本公开示例性实施方式的上述以及其他目的、特征和优点将变得易于理解。在附图中,以示例性而非限制性的方式示出了本公开的若干实施方式,其中:
101.图1示意性地示出了根据本公开实施方式的一种音频处理方法的流程;
102.图2示意性地示出了根据本公开一实施例的确定音频类别的方式的流程;
103.图3示意性地示出了根据本公开一实施例的标签库的部分标签示意图;
104.图4示意性地示出了根据本公开另一实施例的标签库的部分标签示意图;
105.图5示意性地示出了根据本公开一实施例的生成音频摘要的方式的流程;
106.图6示意性地示出了根据本公开一实施例的生成音频摘要的过程的示意图;
107.图7示意性地示出了根据本公开一实施例的一种音频处理装置的结构;
108.图8示意性地示出了根据本公开一实施例的计算机可读存储介质;
109.图9示意性地示出了根据本公开一实施例的计算设备的结构示意图。
110.在附图中,相同或对应的标号表示相同或对应的部分。
具体实施方式
111.下面将参考若干示例性实施方式来描述本公开的原理和精神。应当理解,给出这些实施方式仅仅是为了使本领域技术人员能够更好地理解进而实现本公开,而并非以任何方式限制本公开的范围。相反,提供这些实施方式是为了使本公开更加透彻和完整,并且能够将本公开的范围完整地传达给本领域的技术人员。
112.本领域技术人员知道,本公开的实施方式可以实现为一种系统、装置、设备、方法或计算机程序产品。因此,本公开可以具体实现为以下形式,即:完全的硬件、完全的软件(包括固件、驻留软件、微代码等),或者硬件和软件结合的形式。
113.根据本公开的实施方式,提出了一种音频处理方法和装置、计算机可读存储介质和计算设备。在本文中,需要理解的是,附图中的任何元素数量均用于示例而非限制,以及任何命名都仅用于区分,而不具有任何限制含义。
114.下面参考本公开的若干代表性实施方式,详细阐释本公开的原理和精神。
115.aac(automatic speech recognition,自动音频摘要)模型等音频摘要生成模型在生成摘要的过程中,需要提取音频事件、音频场景、音频中各个音源的时间先后,前后景等逻辑关系等,任务较为复杂。因此相关技术中,为提高摘要生成的准确率和效率主要采用下述两种方式。
116.第一种方式,引入更多的训练数据。引入更多的训练数据可以使模型训练更加充分,但音频摘要生成模型的训练数据标注成本高,花费巨大,而且对于摘要结果较差的音频,标注难度更高。
117.第二种方式,引入预训练模型作为编码器。利用其他任务的训练数据对编码器进行提前训练,利用训练得到的参数对音频摘要生成模型的参数进行初始化。这种方式对于迁移任务的相关性要求很高,且提升的幅度比较有限。
118.综上所述,目前的方法只能引入大量的资源去进行数据标注或引入类似的任务进行模型预训练工作,而且上述两种方式对音频摘要的生成准确率和效率提升均不明显。
119.基于此,本公开的实施例提供了一种音频处理方法,该音频处理方法可以用于为待处理音频生成摘要,摘要是由至少一个词组成的语句,用于描述音频内容。该方法通过音频标签预测(audio tag,at)模型预测待处理音频的类别,该类别能够指示摘要语句的生成方向,从而缩小摘要语句的选择范围,因此该方法既无需引入大量资源去进行数据标注,也无需引入相关任务进行模型训练,且能够极大的提高摘要生成的准确率和效率。
120.本公开实施例所提供的音频处理方法可以应用于多种音频处理场景,例如音频处理的网站具有摘要生成的功能,用户可以输入一段音频,并启动该段音频启动摘要生成的功能,则该网站可以针对该段音频运行本实施例提供的方法,得到音频摘要并由网站显示给客户;再例如音频处理的应用程序具有摘要生成的功能,用户可以输入一段音频,并启动该段音频启动摘要生成的功能,则该网站可以针对该段音频运行本实施例提供的方法,得到音频摘要并由网站显示给客户。
121.请参照附图1,其示出了本公开的一个实施例提供了一种音频处理方法的流程,包括步骤s101至步骤s103。
122.其中,该音频处理方法可以用于为待处理音频生成摘要,摘要是由至少一个词组成的语句,用于描述音频内容。另外,该音频处理方法可以由终端设备或服务器等电子设备
执行,终端设备可以为用户设备(user equipment,ue)、移动设备、用户终端、终端、蜂窝电话、无绳电话、个人数字处理(personal digital assistant,pda)手持设备、计算设备、车载设备、可穿戴设备等,该方法可以通过处理器调用存储器中存储的计算机可读指令的方式来实现。或者,可以通过服务器执行该方法,服务器可以为本地服务器、云端服务器等。
123.在步骤s101中,提取待处理音频的音频特征。
124.本步骤中,可以先采用预设频率对所述待处理音频进行采样处理,得到采样结果;再对采样结果进行特征提取,得到特征序列,作为所述音频特征。
125.采样频率的选取可以根据步骤s102中的音频标签预测模型确定,这是因为采样频率可以影响采样结果,采样结果又可以影响音频特征,而音频特征又可以与音频标签预测模型匹配。可选的,采用32k采样频率对待处理音频进行采样处理,即在1秒钟内对待处理音频采样32000个点。
126.可以采用预先训练的特征提取网络对采样结果进行特征提取。例如,音频特征可以为对数梅尔频谱图。
127.在步骤s102中,根据所述音频特征,利用音频标签预测模型确定所述待处理音频的音频类别。
128.本步骤中,音频标签预测(audio tag,at)模型可以先利用步骤s101中提取的音频特征预测该待处理音频的音频标签,然后再根据预测得到的音频标签确定待处理音频的音频类别。上述预测得到的每个音频标签均是该待处理音频可能的类别,而且这些音频标签可以是标签库中的标签,标签库中的标签包括各场景下各类别的音频标签。
129.可选的,采用pann作为at模型,pann是利用多种cnn架构作为特征提取器来预测音频标签的模型。
130.另外,该音频标签预测模型可以预先经过训练,从而能够准确预测音频标签。训练时,可以利用预测的音频标签和音频标签的真值对模型的参数进行调整,直至模型收敛。
131.在步骤s103中,根据所述音频特征和所述音频类别,利用预先训练的音频摘要生成模型生成待处理音频的摘要语句。
132.其中,音频摘要生成模型可以是aac(automatic speech recognition,自动音频摘要)模型,acc模型可以采用seq2seq模型架构。音频摘要生成模型可以包括编码模块(encoder)和解码模块(decoder),encoder可以由多个卷积层(cnn)堆叠组成,decoder可以采用transformer结构。
133.可选的,音频摘要生成模型可以采用逐词生成的方式,生成音频摘要,也就是说,音频摘要生成模型并非一次性生成整个音频摘要,而是逐个生成音频摘要的各部分,进而得到整个音频摘要;而且还可以在生成后续部分时利用先前已经生成的部分。
134.在生成音频摘要的过程中,音频类别能够指示音频摘要的方向,限制音频摘要的范围。例如,在音频类别为人声的情况下,则音频摘要必然是和人声相关的,在音频类别为音乐的情况下,则音频摘要必然是和音乐相关的。如果没有音频类别的指示,则音频摘要的选择范围是无边界的,因此生成音频摘要的难度较高,进而造成准确率和效率均较低。
135.根据本公开实施方式的音频处理方法和装置、计算机可读存储介质和计算设备,通过提取待处理音频的音频特征,再根据所述音频特征,利用音频标签预测模型确定所述待处理音频的音频类别,最后根据所述音频特征和所述音频类别,利用预先训练的音频摘
要生成模型生成待处理音频的摘要语句。由于生成摘要语句时结合了音频特征和音频类别,音频类别能够指示摘要语句的方向,从而缩小摘要语句的范围,因此相对于相关技术中仅利用音频特征生成的摘要语句,准确率和效率得到了极大的提高。
136.在介绍了本公开的基本原理之后,下面具体介绍本公开的各种非限制性实施方式。
137.本公开的一些实施例中,可以按照如图2所示的方式确定待处理音频的音频类别,包括步骤s201至步骤s204。
138.在步骤s201中,将所述音频特征输入至所述音频标签预测模型,所述音频标签预测模型输出标签库中的至少一个音频标签的评分。
139.其中,标签库内的音频标签可以包含音频所覆盖的常见类别。所述标签库内具有多个音频标签,所述多个音频标签之间具有树形层级关系,每个音频标签均具有上一级和/或下一级音频标签,即第一级标签仅具有下一级标签,最后一级标签仅具有上一级标签,其他级的标签既具有上一级标签,也具有下一级标签。可选的,本实施例中的标签库共具有527个标签,请参照附图3,其示出了标签库中的第一级标签和第二级标签,共包括7个第一级标签和43个第二级标签。
140.某个音频标签的评分,用于表征该音频标签与待处理音频的音频内容相契合的概率,例如待处理音频为打猎场景下的音频内容,其中包括猎枪声、猎狗的叫声等,音频标签为打猎,音频标签的评分为0.85,则该评分说明音频标签与待处理音频的音频内容之间契合的概率为0.85。
141.可选的,音频标签预测模型输出标签库中每个音频标签的评分。需要注意的是,标签库中的音频标签较多,因此针对某个待处理音频输出评分时,部分音频标签的评分可以为0,即表示这些音频标签与该待处理音频毫不相关。
142.在步骤s202中,根据评分从所述至少一个音频标签中选择预设数量的音频标签,作为保留标签。
143.本步骤中,可以在所述至少一个音频标签中,保留评分高于预设评分阈值的音频标签;然后响应于保留的音频标签的数量小于或等于所述预设数量,将保留的音频标签全部作为保留标签,响应于保留的音频标签的数量大于所述预设数量,按照评分从大到小的顺序从保留的音频标签中,选择预设数量的音频标签作为保留标签。也就是说,按照评分阈值和预设数量两个维度从至少一个音频标签中挑选保留标签,尽量保留预设数量的标签,但同时要保证所有保留标签的评分均大于评分阈值,这样能够使与待处理音频的音频内容质检契合的概率较高的标签得以保留,同时去除与待处理音频的音频内容质检契合的概率较低的干扰标签。可选的,预设数量为10。
144.需要注意的是,为了使评分的比较更加方便,可以在得到所述标签库中的至少一个音频标签的评分之后,对所述评分进行归一化处理,进而预设的评分阈值可以针对归一化后的评分进行设置,即根据归一化处理后的评分从所述至少一个音频标签中选择预设数量的音频标签,作为保留标签。可选的,将评分阈值设置为0.01。
145.在步骤s203中,从标签库中确定每个所述保留标签对应的候选音频类别。
146.其中,所述标签库中的至少一个音频标签预先标记为第一类标签。第一类标签表示可以用来作为音频的类别的标签,而其他标签则不能用来作为音频的类别。请参照附图
4,其为第一级标签sounds of things之下的全部标签的省略版示意图,其中第一级标签sounds of things、第二级标签vehicle和第三级标签motor vehicle(road)均被标记为第一类标签。
147.基于上述标签库的结构,本步骤可以响应于,确定所述第一类标签为所述保留标签对应的候选音频类别;否则(即所述保留标签为非第一类标签),以所述保留标签为起始层级,在标签库中逐级确定上级音频标签,直至所述上级音频标签为第一类标签,确定所述第一类标签为所述保留标签对应的候选音频类别。
148.也就是说,当保留标签为第一类标签时,由于其可以用来作为音频的类别,因此将保留标签本身确定为其对应的候选音频类别;而当保留标签不为第一类标签时,由于其不可以用来作为音频的类别,则将该保留标签的上级标签中,与其级别差距最小的第一类标签作为其对应的候选音频类别。换句话说,每个第一类标签不但要作为其本身对应的候选音频类别,还要作为其下级的所有非第一类标签对应的候选音频类别。另外,可以预先建立每个第一类标签的标签映射表,该映射表内可以记载每个第一类标签对应的全部非第一类标签,即记载用该第一类标签作为候选音频类别的全部标签,从而方便在本步骤中确定候选音频类别。
149.例如,图4所示出的motor vehicle(road)的下级标签包括car,truck,bus等,同时也包括这些下级标签的下级标签,如car alarm等等。如果保留标签为car,那么car就应该映射到motor vehicle(road)上,将motor vehicle(road)作为对应的候选标签类别,不需要继续向上映射到vehicle和sounds of things;如果保留标签为boat,water vehicle,那么就应该映射到vehicle上,将vehicle作为对应的候选音频类别;如果保留标签为engine,那么应该映射到sounds of things上,将sounds of things作为对应的候选音频类别。
150.需要注意的是,还可以提前将所述标签库中的至少一个音频标签标记为第一类标签。选择第一类标签时,可以直接将较为上级的标签选择为第一类标签,例如将全部的第一级标签和全部的第二级标签选择为第一类标签,因为较为上级的标签具有一定的概括性和代表性;还可以将训练集中出现频率较高的训练音频的标签选择为第一类标签,例如将出现频率前13的训练音频的标签作为均标记为第一类标签,这些出现频率较高的标签具有一定的热度,因此这些标签出现的概率高,作为类别能够具有一定的针对性。通过预先标记第一类标签,能够使后续确定的候选音频类别较为准确,既具备作为音频类别的资格,又不至于级别过高而导致没有针对性。
151.在步骤s204中,从预设数量的所述候选音频类别中确定一个作为所述待处理音频的音频类别。
152.本步骤中,可以先确定每个所述候选音频类别的综合评分,其中,所述综合评分为所述候选音频类别对应的全部下级音频标签的评分的和;再确定综合评分最高的所述候选音频类别为所述待处理音频的音频类别。可以利用上述步骤s203中提到的标签映射表确定每个候选音频类别的全部下级音频标签。通过综合评分从多个候选音频类别中确定待处理音频的类别,准确方便,结果可靠。
153.当候选音频类别的下级标签均在步骤s201输出了评分,则直接将每个标签的评分进行求和处理,当候选音频类别的下级标签中只有部分在步骤s201输出了评分,则将未输出评分的标签的评分记为0,然后再将每个标签的评分进行求和处理。
154.可选的,采用下述公式计算综合评分:
155.s
c
=∑
l∈f(c)
s
l
;
156.其中,f(c)为候选音频类别c对应的所有下级标签的集合;s
l
标签l的评分。
157.例如,在图4所示出的简略版便签库中,当候选音频类别为sounds of things时,则其下级的所有标签(包括第一类标签和非第一类标签)的评分之和为其综合评分。
158.本公开的一些实施例中,可以按照如图5所示的方式生成待处理音频的摘要语句,包括步骤s501至步骤s502。
159.在步骤s501中,所述音频摘要生成模型的编码模块对所述音频特征进行编码,得到编码向量。
160.其中,编码向量可以为向量形式的音频编码序列。
161.在步骤s502中,所述音频摘要生成模型的解码模块根据所述编码向量和初始词序列,生成所述待处理音频的摘要语句,其中,所述初始词序列包括初始词向量(sos)和所述音频类别的标签词向量。
162.其中,解码模块预测结果序列时,结果序列的第一个位置预测音频类别,后续位置正常预测音频摘要。本步骤将上述步骤得到的音频类别直接添加至结果序列的第一个位置,从而指导预测过程。也就是说,将<sos>和音频类别组成一个初始序列,解码模块会从这个初始序列开始解码,结合编码模块得到的编码向量,采用贪心搜索或beam
‑
search等搜索方法逐个生成音频摘要语句的各个词向量,直到达到<eos>标记为止。
163.可选的,先根据所述编码向量和所述初始词序列,生成所述摘要语句的第一组词向量,例如,可以将所述初始词序列嵌入所述编码向量内,形成第一向量,并通过解码所述第一向量生成所述摘要语句的第一组词向量;再根据所述初始词序列和前i组词向量组成的词序列,以及所述编码向量生成第i+1组词向量,直至生成终止词向量(eos),其中,i≥1,每组词向量均包括至少一个词向量,例如,可以将所述初始词序列和前i组词向量组成的词序列嵌入所述编码向量内,形成第二向量,并通过解码所述第二向量生成第i+1组词向量。
164.其中,可以按照下述方式生成第i+1组词向量:先确定预设词表中至少一个词向量的目标概率,所述目标概率为所述词向量属于所述第i+1组词向量的概率;再根据所述至少一个词向量的目标概率,生成所述第i+1组词向量。
165.在一个示例中,待处理音频的所确定的音频类别为tga_human
‑
voice,则首先利用编码模块得到编码向量,随后要求解码模块根据编码向量和文本序列“<sos>tga_human
‑
voice”开始预测下一个词向量,预测得到的词向量会加入到文本序列的末尾继续输入解码模块进行预测,以此循环直到遇到句末标记<eos>后停止生成,这个过程中可以采用贪心搜索或beam
‑
search进行路径的搜索。
166.本公开的一些实施例中,还可以预先按照下述方式对音频摘要生成模块进行训练:首先,提取训练集中的训练音频的音频特征,其中,所述训练音频标记有类别标签和摘要标签;接下来,将所述训练音频的音频特征和类别标签输入至所述音频摘要生成模型中,所述音频摘要生成模型输出所述训练音频的预测标签;最后,根据所述摘要标签和所述预测标签确定网络损失值,并根据所述网络损失值调整所述音频摘要生成模型的编码模块和解码模块的网络参数。
167.通过上述训练过程,能够使音频摘要生成模型较准确生成音频摘要,上述训练过
程使用的训练音频预先标记了类别标签。需要理解的是,也可以使用未标记类别标签的训练音频进行训练,这里举一个例子说明训练的详细过程,以clotho训练集中的一个音频“00332lake beach 1.wav”为例,音频类别确认为tga_human
‑
voice。该音频正确的音频摘要为”children play and adults converse in a noisy city area.”。在训练时,会将包括tga_human
‑
voice在内的14个标签也视为单词加入到预设词表中。训练算法首先要求解码模块根据编码模块得到的编码向量和已生成文本序列<sos>预测出tga_human
‑
voice;随后要求解码模块根据编码向量和已生成文本序列“<sos>tga_human
‑
voice”预测出children;第三步,根据编码向量和已生成文本序列“<sos>tga_human
‑
voice children”预测出下一个词play,以此类推,直到要求解码模块根据编码向量和已生成文本序列“tga_human
‑
voice children play and adults converse in a noisy city area.”预测出<eos>为止。
168.本实施例提供的训练方法,增加了音频类别这一维度,从而提升了模型的训练稳定性和训练效果。
169.请参照附图6,其示例性的示出了本公开的一个实施例生成音频摘要的过程。从图中可以看出,预先提取的音频特征预先被输入至at任务模型内,然后at任务模型的输出通过音频类别确认步骤得到音频类别;然后预先提取的音频特征还被aac模型的编码模块编码得到编码向量,同时由sos、上述音频类别以及已经生成的音频摘要的词向量被解码模块嵌入到上述编码向量中,并进一步通过解码上述嵌入结果得预设词表的概率分布,进而根据概率分布确定下一个词向量。
170.图6所示出的过程是音频摘要的中间的某个词向量的生成过程,即每个词向量均按照上述过程生成。需要注意的是,当生成第一个词向量时,输入至解码模块的为sos和音频类别,而且当得到的下一个词向量为eos时,停止音频摘要的生成。
171.请参照下表,其示出了相关技术中音频摘要生成方法得到的音频摘要,和使用本公开提供的音频处理方法得到的音频摘要。从表中可以看出,通过音频类别的引导,可以生成关于鸟叫的描述;但相关技术中不添加这一策略,生成的描述同人工编写的标准答案相差甚远。
172.表1:音频摘要生成结果对比表
[0173][0174]
本公开实施例还提供了一种音频处理装置,请参照附图7,其示出了该装置的结构,包括:
[0175]
特征模块701,用于提取待处理音频的音频特征;
[0176]
类别模块702,用于根据所述音频特征,利用音频标签预测模型确定所述待处理音频的音频类别;
[0177]
摘要模块703,用于根据所述音频特征和所述音频类别,利用预先训练的音频摘要生成模型生成待处理音频的摘要语句。
[0178]
在本公开的一个实施例中,所述特征模块具体用于:
[0179]
采用预设频率对所述待处理音频进行采样处理,得到采样结果;
[0180]
对采样结果进行特征提取,得到特征序列,作为所述音频特征。
[0181]
在本公开的另一个实施例中,所述类别模块具体用于:
[0182]
将所述音频特征输入至所述音频标签预测模型,所述音频标签预测模型输出标签库中的至少一个音频标签的评分;
[0183]
根据评分从所述至少一个音频标签中选择预设数量的音频标签,作为保留标签;
[0184]
从标签库中确定每个所述保留标签对应的候选音频类别;
[0185]
从预设数量的所述候选音频类别中确定一个作为所述待处理音频的音频类别。
[0186]
在本公开的又一个实施例中,所述类别模块还用于:
[0187]
在所述输出标签库中的至少一个音频标签的评分之后,对所述评分进行归一化处理;
[0188]
所述类别模块用于根据评分从所述至少一个音频标签中选择预设数量的音频标签,作为保留标签时,具体用于:
[0189]
根据归一化处理后的评分从所述至少一个音频标签中选择预设数量的音频标签,作为保留标签。
[0190]
在本公开的再一个实施例中,所述类别模块用于根据评分从所述至少一个音频标签中选择预设数量的音频标签,作为保留标签时,具体用于:
[0191]
在所述至少一个音频标签中,保留评分高于预设评分阈值的音频标签;
[0192]
响应于保留的音频标签的数量小于或等于所述预设数量,将保留的音频标签全部作为保留标签;
[0193]
响应于保留的音频标签的数量大于所述预设数量,按照评分从大到小的顺序从保留的音频标签中,选择预设数量的音频标签作为保留标签。
[0194]
在本公开的再一个实施例中,所述标签库内具有多个音频标签,所述多个音频标签之间具有树形层级关系,每个音频标签均具有上一级和/或下一级音频标签,所述标签库中的至少一个音频标签预先标记为第一类标签;
[0195]
所述类别模块用于从标签库中确定每个所述保留标签对应的候选音频类别时,具体用于:
[0196]
响应于所述保留标签为第一类标签,确定所述第一类标签为所述保留标签对应的候选音频类别;
[0197]
否则,以所述保留标签为起始层级,在标签库中逐级确定上级音频标签,直至所述上级音频标签为第一类标签,确定所述第一类标签为所述保留标签对应的候选音频类别。
[0198]
在本公开的再一个实施例中,还包括标记模块,用于:
[0199]
将所述标签库中的至少一个音频标签标记为第一类标签。
[0200]
在本公开的再一个实施例中,所述摘要模块具体用于:
[0201]
确定每个所述候选音频类别的综合评分,其中,所述综合评分为所述候选音频类别对应的全部下级音频标签的评分的和;
[0202]
确定综合评分最高的所述候选音频类别为所述待处理音频的音频类别。
[0203]
在本公开的再一个实施例中,所述摘要模块用于根据所述音频特征和所述音频类别,利用预先训练的音频摘要生成模型生成待处理音频的摘要语句时,具体用于:
[0204]
所述音频摘要生成模型的编码模块对所述音频特征进行编码,得到编码向量;
[0205]
所述音频摘要生成模型的解码模块根据所述编码向量和初始词序列,生成所述待处理音频的摘要语句,其中,所述初始词序列包括初始词向量和所述音频类别的标签词向量。
[0206]
在本公开的再一个实施例中,所述摘要模块用于根据所述编码向量和初始词序列,生成所述待处理音频的摘要语句时,具体用于:
[0207]
根据所述编码向量和所述初始词序列,生成所述摘要语句的第一组词向量;
[0208]
根据所述初始词序列和前i组词向量组成的词序列,以及所述编码向量生成第i+1组词向量,直至生成终止词向量,其中,i≥1,每组词向量均包括至少一个词向量。
[0209]
在本公开的再一个实施例中,所述摘要模块用于根据所述编码向量和所述初始词序列,生成所述摘要语句的第一组词向量时,具体用于:
[0210]
将所述初始词序列嵌入所述编码向量内,形成第一向量,并通过解码所述第一向量生成所述摘要语句的第一组词向量;
[0211]
根据所述初始词序列和前i组词向量组成的词序列,以及所述编码向量生成第i+1组词向量,包括:
[0212]
将所述初始词序列和前i组词向量组成的词序列嵌入所述编码向量内,形成第二向量,并通过解码所述第二向量生成第i+1组词向量。
[0213]
在本公开的再一个实施例中,所述摘要模块用于按照下述方式生成第i+1组词向量:
[0214]
确定预设词表中至少一个词向量的目标概率,所述目标概率为所述词向量属于所述第i+1组词向量的概率;
[0215]
根据所述至少一个词向量的目标概率,生成所述第i+1组词向量。
[0216]
在本公开的再一个实施例中,还包括训练模块,用于:
[0217]
提取训练集中的训练音频的音频特征,其中,所述训练音频标记有类别标签和摘要标签;
[0218]
将所述训练音频的音频特征和类别标签输入至所述音频摘要生成模型中,所述音频摘要生成模型输出所述训练音频的预测标签;
[0219]
根据所述摘要标签和所述预测标签确定网络损失值,并根据所述网络损失值调整所述音频摘要生成模型的编码模块和解码模块的网络参数。
[0220]
本公开实施例还提供了一种计算机可读存储介质。如图8所示,该存储介质上存储有计算机程序801,该计算机程序801被处理器执行时可以执行本公开任一实施例的广告推送方法。
[0221]
本公开实施例还提供了一种计算设备,该设备可以包括存储器、处理器,所述存储器用于存储可在处理器上运行的计算机指令,所述处理器用于在执行所述计算机指令时实现本公开任一实施例的广告推送方法。
[0222]
图9示例了一种该计算设备的结构,如图9所示,该计算设备90可以包括但不限于:处理器91、存储器92、连接不同系统组件(包括存储器92和处理器91)的总线93。
[0223]
其中,存储器92存储有计算机指令,该计算机指令可以被处理器91执行,使得处理器91能够执行本公开任一实施例的广告推送方法。存储器92可以包括随机存取存储单元ram921、高速缓存存储单元922和/或只读存储单元rom923。该存储器92还可以包括:具有一组程序模块924的程序工具925,该程序模块924包括但不限于:操作系统、一个或多个应用程序、其他程序模块和程序数据,这些程序模块一种或多种组合可以包含网络环境的实现。
[0224]
总线93例如可以包括数据总线、地址总线和控制总线等。该计算设备90还可以通过i/o接口94与外部设备95通信,该外部设备95例如可以是键盘、蓝牙设备等。该计算设备90还可以通过网络适配器96与一个或多个网络通信,例如,该网络可以是局域网、广域网、公共网络等。如图9所示,该网络适配器96还可以通过总线93与计算设备90的其他模块进行通信。
[0225]
此外,尽管在附图中以特定顺序描述了本公开方法的操作,但是,这并非要求或者暗示必须按照该特定顺序来执行这些操作,或是必须执行全部所示的操作才能实现期望的结果。附加地或备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,和/或将一个步骤分解为多个步骤执行。
[0226]
虽然已经参考若干具体实施方式描述了本公开的精神和原理,但是应该理解,本
公开并不限于所公开的具体实施方式,对各方面的划分也不意味着这些方面中的特征不能组合以进行受益,这种划分仅是为了表述的方便。本公开旨在涵盖所附权利要求的精神和范围内所包括的各种修改和等同布置。