1.本发明属于模式识别技术领域,具体涉及一种语音识别方法。
背景技术:
2.输入序列的时序信息在许多序列学习任务中起着至关重要的作用,尤其是在语音识别中。基于循环神经网络的模型可以通过沿时间维度递归计算其隐藏状态来学习序列的时序信息。基于卷积神经网络的模型可以通过填充算子隐式地学习输入序列的位置信息。近年来,基于transformer的模型已经在机器翻译、语言建模和语音识别等各种序列学习任务中表现出极大的优越性。基于transformer的模型利用自注意力机制对输入序列中不同元素之间的依赖性进行建模,这提供了比循环神经网络更高效的并行计算,并且可以对元素之间的上下文依赖性建模比卷积神经网络更长。
3.基于transformer的模型摒弃了递归的计算,仅利用自注意力机制就可以建模输入序列中元素之间的全局依赖,但是自注意力机制不能对序列的时序信息进行建模。因此,近年来涌现了一些将输入序列中元素的相对或绝对位置信息加入到基于transformer的模型中的工作。
4.第一种做法是采用绝对位置编码,例如通过三角位置编码将绝对位置信息到输入序列中。具体而言,输入序列中每个元素的绝对位置被编码成一个向量,其维度等于输入序列的维度,通常将位置编码序列和输入序列相加;除了采用预先定义的函数来编码输入序列中元素的绝对位置信息,还可以采用一组可学习的向量来编码绝对元素的位置信息,这种可学习的位置编码可以取得与三角位置编码相当的性能。但是,它不能外推到比训练集中语料更长的长度。
5.第二种做法是采用相对位置编码,通常在计算注意力时加入相对位置信息。最初的相对位置编码方法是用输入序列中任意两个元素之间的距离来代替绝对位置信息,在两个机器翻译任务上取得了显著的提升。后来该方法推广到语言模型上,帮助语言模型建模段落之间的长时依赖。还有一些工作还在语音识别任务中将相对位置编码用于声学建模,使得自注意力模块更好地处理不同的输入长度。但是,相对位置编码增加了模型的参数量,且相对位置编码的矩阵运算实现起来较为繁琐。
技术实现要素:
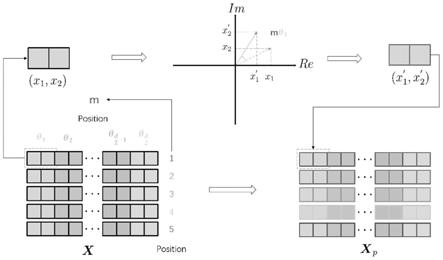
6.为了克服现有技术的不足,本发明提供了一种基于旋转位置编码(rotary position embedding,rope)的端到端语音识别方法,并利用旋转位置编码增强卷积自注意力网络(conformer)对声学特征的建模能力。首先通过旋转矩阵对输入序列中元素的绝对位置信息进行编码,然后在多头自注意力模块的输入向量的内积中加入相对位置信息,构建基于卷积自注意力网络的端到端语音识别模型,再通过语音识别模型将输入语音转换为文本信息。本发明在aishell
‑
1和librispeech语料库上进行了实验,实验结果表明,用旋转位置编码增强的conformer比原始conformer在语音识别任务上表现更好。在aishell
‑
1数
据集的测试集上实现了4.69%的字错误率,在librispeech数据集的“test
‑
clean”和“test
‑
other”集上分别实现了2.1%和5.1%的词错误率。
7.本发明解决其技术问题所采用的技术方案包括如下步骤:
8.步骤1:构建基于卷积自注意力网络的端到端语音识别模型;
9.步骤1
‑
1:去掉卷积自注意力网络在下采样层的位置编码,在每个编码器的多头自注意力模块之前加入旋转位置编码,具体如下:
10.在多头自注意力模块的输入序列的内积中加入相对位置信息:
11.q
m
=f
q
(x
m
,m)
12.k
n
=f
k
(x
n
,n)
13.<f
q
(x
m
,m),f
k
(xn,n)>=g(x
m
,x
n
,m
‑
n)
ꢀꢀꢀ
(1)
14.其中q
m
是给x
m
添加位置信息后得到的输出,k
n
是给x
n
添加位置信息后得到的输出,是多头自注意力模块输入序列的第m个和第n个元素,t是序列长度,d是维度;q
m
和k
n
的内积由函数g(
·
)表示,分别通过函数f
q
(
·
)、f
k
(
·
)加入第m个和第n个元素的位置信息,函数g(
·
)只取x
m
、x
n
及其相对位置m
‑
n作为输入变量;函数f
q
(
·
)、f
k
(
·
)分别表示给x
m
和x
n
添加位置信息的函数;
15.步骤1
‑
2:求解符合等式(1)的函数f
q
(
·
)和f
k
(
·
)完成旋转位置编码;
16.步骤1
‑2‑
1:当维度d=2时,解为:
17.f
q
(x
m
,m)=(x
m
w
q
)e
imθ
18.f
k
(x
m
,m)=(x
m
w
k
)e
imθ
19.g(x
m
,x
n
,m
‑
n)=re[(x
m
w
q
)(x
n
w
k
)
*
e
i(m
‑
n)θ
]
ꢀꢀꢀ
(2)其中分别是多头自注意力模块查询向量和键向量的线性层的权重矩阵,d
m
是多头自注意力模块的隐层维度,re[
·
]表示复数的实部,(x
n
w
k
)
*
表示(x
n
w
k
)的共轭复数,是一个非零常数;
[0020]
步骤1
‑2‑
2:根据内积的线性可加性,将式(2)的解推广到任意偶数维度d,将d维空间划分为d/2子空间,并进行组合:
[0021][0022][0023]
其中
[0024][0025]
θ={θ
i
=10000
‑
2(i
‑
1)/d
,i∈[1,2,...,d/2]}
ꢀꢀꢀ
(5)
[0026][0027]
步骤1
‑
3:通过步骤1
‑2‑
1和步骤1
‑2‑
2构造了基于卷积自注意力网络的端到端语音识别模型;
[0028]
步骤2:采用语料库数据,使用adam优化器,设定训练参数,训练基于卷积自注意力网络的端到端语音识别模型;
[0029]
步骤3:将待识别语音输入训练完成的基于卷积自注意力网络的端到端语音识别模型,语音识别模型进行识别输出相应的文本。
[0030]
优选地,所述语料库为普通话语料库aishell
‑
1和英语语音语料库librispeech。
[0031]
优选地,所述使用adam优化器进行训练时,学习率峰值为0.0005,并进行30000次步骤的预热。
[0032]
本发明的有益效果如下:
[0033]
本发明在aishell
‑
1和librispeech语料库上进行了实验,在
‘
test
‑
clean’和
‘
test
‑
other’语料库上的错误率分别比原始conformer相对降低了8.70%和7.27%。此外,本发明相比于绝对位置编码和相对位置编码,参数量更少,性能更好,实现起来更简单,是一种简单却很有效的方法。
附图说明
[0034]
图1为本发明方法的旋转位置编码计算过程示意图。
[0035]
图2为conformer的架构。
[0036]
图3为conformer的编码器模块的架构。
具体实施方式
[0037]
下面结合附图和实施例对本发明进一步说明。
[0038]
本发明提出了旋转位置编码,并采用旋转位置编码取代了原始conformer中的位置编码,使得用旋转位置编码增强的conformer比原始conformer表现更好,在两个数据集上的错误率显著下降。
[0039]
一种基于旋转位置编码增强卷积自注意力网络的语音识别方法,包括如下步骤:
[0040]
步骤1:构建基于卷积自注意力网络的端到端语音识别模型;
[0041]
步骤1
‑
1:如图2所示,去掉卷积自注意力网络在下采样层的位置编码,在每个编码器的多头自注意力模块之前加入旋转位置编码,具体如下:
[0042]
每个conformer编码器块包含两个前馈(ffn)模块,中间夹有多头自注意模块(mhsa)和卷积(conv)模块,如图3所示;
[0043]
如图1所示,在多头自注意力模块的输入序列的内积中加入相对位置信息:
[0044]
q
m
=f
q
(x
m
,m)
[0045]
k
n
=f
k
(x
n
,n)
[0046]
<f
q
(x
m
,m),f
k
(x
n
,n)>=g(x
m
,x
n
,m
‑
n)
ꢀꢀꢀ
(1)
[0047]
其中是多头自注意力模块输入序列的第m个和第n个元素,t是序列长度,d是维度;q
m
和k
n
的内积由函数g(
·
)表示,分别通过函数f
q
(
·
)、f
k
(
·
)加入第m个和第n个元素的位置信息,函数g(
·
)只取x
m
、x
m
及其相对位置m
‑
n作为输入变量;
[0048]
步骤1
‑
2:求解符合等式(1)的函数f
q
(
·
)和f
k
(
·
)完成旋转位置编码;
[0049]
步骤1
‑2‑
1:当维度d=2时,解为:
[0050]
f
q
(x
m
,m)=(x
m
w
q
)e
imθ
[0051]
f
k
(x
m
,m)=(x
m
w
k
)e
imθ
[0052]
g(x
m
,x
n
,m
‑
n)=re[(x
m
w
q
)(x
n
w
k
)
*
e
i(m
‑
n)θ
]
ꢀꢀꢀ
(2)其中分别是多头自注意力模块查询向量和键向量的线性层的权重矩阵,d
m
是多头自注意力模块的隐层维度,re[
·
]表示复数的实部,(x
n
w
k
)
*
表示(x
n
w
k
)的共轭复数,是一个非零常数;
[0053]
步骤1
‑2‑
2:根据内积的线性可加性,将式(2)的解推广到任意偶数维度d,将d维空间划分为d/2子空间,并进行组合:
[0054][0055][0056]
其中
[0057][0058]
θ={θ
i
=10000
‑
2(i
‑
1)/d
,i∈[1,2,...,d/2]}
ꢀꢀꢀ
(5)
[0059][0060]
步骤1
‑
3:通过步骤1
‑2‑
1和步骤1
‑2‑
2构造了基于卷积自注意力网络的端到端语音识别模型;
[0061]
本发明为编码器添加位置编码的方式主要有两个方面:
[0062]
编码器中采用了乘性位置编码方法,而不是加性位置编码。
[0063]
此外,本发明没有编码器的开头添加位置编码,而是在每个自注意力层的查询向量和键向量中添加位置编码。
[0064]
而在解码器中的位置编码是绝对位置编码,以加性位置编码的方式添加在解码器最前面;
[0065]
步骤2:采用语料库数据,使用adam优化器,设定训练参数,训练基于卷积自注意力网络的端到端语音识别模型;
[0066]
步骤3:将待识别语音输入训练完成的基于卷积自注意力网络的端到端语音识别模型,语音识别模型进行识别输出相应的文本。
[0067]
具体实施例:
[0068]
1、数据准备:
[0069]
在实验中,实验数据采用普通话语料库aishell
‑
1和英语语音语料库librispeech。前者有170小时的标记语音,而后者包括970小时的标记语料和额外的800m词标记纯文本语料库,用于构建语言模型。
[0070]
2、数据处理:
[0071]
提取80维的对数梅尔滤波器组特征,帧长为25ms,帧移为10ms,并且对特征进行归一化,使每个说话人的特征均值为0,方差为1。aishell
‑
1的词典包含4231个标签,
librispeech的词典包含了用字节对编码算法产生5000个标签。此外,aishell
‑
1和librispeech的词汇表具有填充符号“pad”、未知符号“unk”和句尾符号“eos”。
[0072]
3、搭建网络:
[0073]
本发明提出的模型包含12个编码器块和6个解码器块。自注意力层与编码器
‑
解码器之间的注意力层均采用4个头。二维卷积的前端使用两个3
×
3卷积层,具有256个通道,激活函数为relu,步长为2,所有注意力层的隐层维度为256,前馈层的隐层维度和输出维度分别为256和2048。
[0074]
对于模型训练,使用adam优化器,学习率峰值为0.0005,并进行30000次步骤的预热。使用specaugment方法进行数据增强。对于与注意力模型的联合训练,将ctc权重设置为0.3。在测试阶段,将联合解码的ctc权重设置为0.6。使用基于transformer的语言模型来优化结果。speech
‑
transformer使用transformer架构进行声学建模和语言建模。ldsa用局部密集合成器注意力模块替换了transformer编码器中的自注意力模块。gsa
‑
transformer用基于高斯的注意力取代了自注意力模块。conformer将transformer架构与卷积结构相结合。
[0075]
4、实验效果:
[0076]
表1在librispeech数据集上的比较结果
[0077][0078]
其中wer表示词错误率,cer表示字错误率。
[0079]
从表1中可以看出,使用本发明所提出的旋转位置编码增强的conformer在这些语音识别模型中取得了最好的性能。本发明模型在“test
‑
clean”和“test
‑
other”上分别取得了2.1%和5.5%的词错误率,与原始的conformer相比,词错误率相对降低了8.70%和7.27%。
[0080]
表2在aishell
‑
1数据集上的比较结果
[0081][0082]
从表2中可以看出,本发明在开发集和测试集的字错误率分别为4.34%和4.69%,与原始conformer相比,开发集和测试集的字错误率相对降低分别为4.00%和3.90%。因
此,本发明所提出的模型明显优于其他比较方法。
[0083]
表3在librispeech数据集上的位置编码方法之间的比较结果
[0084][0085]
表4在aishell
‑
1数据集上的位置编码方法之间的比较结果
[0086][0087]
本实施例还将旋转位置编码与conformer中的其他位置编码进行了比较,例如绝对位置编码和相对位置编码。表3列出了librispeech数据集上的结果,表4列出了aishell
‑
1上的结果。ape表示绝对位置编码,rpe分别表示相对位置编码。从表3和表4可以看出,相对位置编码比绝对位置编码性能更好,本发明提出的旋转位置编码在librispeech和aishell
‑
1数据集上都取得了最好的性能。