1.本发明涉及信号处理技术领域,特别是涉及一种基于矢量语音传感器阵列的语音增强方法及装置。
背景技术:
2.自然界中存在各种各样的噪声,包括环境噪声、干扰语音以及设备内部的噪声等,在拾音过程中,这些噪声不可避免的会被引入到拾音结果中,影响拾音效果,降低目标语音的质量以及可懂度。为减小噪声对拾音结果的影响,需要采用语音增强技术对各类噪声予以去除。语音增强技术包括单麦克风语音增强技术,麦克风阵列语音增强技术可以充分利用语音和噪声信号的空间信息,相对于单麦克风语音增强技术具有更优的效果。但是麦克风阵列语音增强技术需要采用多个麦克风同时进行拾音,同时这些麦克风之间的间距不可过小,因此麦克风阵列一般具有较大的尺寸,不利于开发低功耗、小型化的拾音设备。
技术实现要素:
3.本发明提供了一种基于矢量语音传感器阵列的语音增强方法及装置,以解决现有技术中不能在小型化的前提下实现语音增强技术的问题。
4.第一方面,本发明提供了一种基于矢量语音传感器阵列的语音增强方法,该方法包括:利用两个相互正交的矢量语音传感器和一个全向麦克风作为原始声信号采集单元进行带噪语音信号采集,其中,所述矢量语音传感器和所述全向麦克风是同点布置的;对所述带噪语音信号进行分帧与加窗,并进行单帧信号快速傅里叶变换fft,然后计算各频点信号来向,对空间噪声进行去除,最后进行快速傅里叶逆变换ifft与时域增强语音生成,得到增强的语音信号。
5.可选地,所述两个相互正交的矢量语音传感器分别是第一矢量语音传感器v1和第二矢量语音传感器v2,所述第一矢量语音传感器v1的敏感方向为0
°
,所述第二矢量语音传感器v2的敏感方向为90
°
,所述第一矢量语音传感器v1和所述第二矢量语音传感器v2所在平面的角度范围为[
‑
180,180];
[0006]
所述第一矢量语音传感器v1采集到第一声矢量信号x,所述第二矢量语音传感器v2采集到第二声矢量信号y,其中,所述第一矢量语音传感器v1与所述第二矢量语音传感器所采集到的声矢量信号是正交的,所述全向麦克风采集到声标量信号p。
[0007]
可选地,对所述带噪语音信号进行分帧与加窗,包括:对所述第一矢量语音传感器v1采集到第一声矢量信号x、所述第二矢量语音传感器v2采集到第二声矢量信号y,以及所述全向麦克风采集到的声标量信号p进行分帧加窗,得到第一声矢量时域单帧信号x
win
(l)、第二声矢量时域单帧信号y
win
(l)、声标量时域单帧信号p
win
(l),其中,l=1,2,
…
,l,l为单帧时域带噪语音信号长度。
[0008]
可选地,所述分帧加窗的帧长为20ms,帧移为10ms,窗函数为汉宁窗。
[0009]
可选地,所述进行单帧信号快速傅里叶变换,包括:
[0010]
对第一声矢量时域单帧信号x
win
(l)、第二声矢量时域单帧信号y
win
(l)、声标量时域单帧信号p
win
(l)进行如下处理,
[0011][0012][0013][0014]
其中,ceil表示向上取整,x
fwin
(l),y
fwin
(l),p
fwin
(l)分别为对应v1、v2、u的第一声矢量待变换时域单帧信号、第二声矢量待变换时域单帧信号、声标量待变换时域单帧信号;
[0015]
得到x
fwin
(l),y
fwin
(l),p
fwin
(l)后,利用fft将其转换到频域,得到频域单帧信号,
[0016]
x
win
(k)=fft(x
fwin
(l))
ꢀꢀꢀ
(4)
[0017]
y
win
(k)=fft(y
fwin
(l))
ꢀꢀꢀ
(5)
[0018]
p
win
(k)=fft(p
fwin
(l))
ꢀꢀꢀ
(6)
[0019]
其中,x
win
(k),y
win
(k),p
win
(k)分别为对应v1、v2、u的第一声矢量频域单帧信号、第二声矢量频域单帧信号、声标量频域单帧信号,k为频点序号,fft为快速傅里叶变换算子。
[0020]
可选地,所述计算各频点信号来向,包括:
[0021]
利用第一声矢量待变换时域单帧信号x
fwin
(l)、第二声矢量待变换时域单帧信号y
fwin
(l)、声标量待变换时域单帧信号p
fwin
(l)快速傅里叶变换后的第一声矢量频域单帧信号x
win
(k)、第二声矢量频域单帧信号y
win
(k)、声标量频域单帧信号p
win
(k),对各个频点的信号进行定向,确定各个频点信号的来向,判断其是否属于目标语音;
[0022]
采用标量声场与矢量声场组成的复声强器进行定向,以减少环境噪声对定向结果的影响,提高定向精度,复声强器的定义为,
[0023][0024][0025]
其中,i
px
(k),i
py
(k)分别代表频点k处,p分量与x分量、p分量与y分量组成的复声强器,
*
代表复共轭,re代表取实部;
[0026]
得到i
px
(k),i
py
(k)后,各频点信号的来向可由下式计算求得,
[0027][0028]
其中,θ(k)代表频点k处的信号来向,arctan代表反正切算子。
[0029]
可选地,所述方法还包括:通过滤波器对空间噪声进行去除,以及根据所述第一矢量语音传感器v1采集到第一声矢量信号x、所述第二矢量语音传感器v2采集到第二声矢量信号y,以及所述全向麦克风采集到的声标量信号p设计所述滤波器。
[0030]
可选地,根据所述第一矢量语音传感器v1采集到第一声矢量信号x、所述第二矢量语音传感器v2采集到第二声矢量信号y,以及所述全向麦克风采集到的声标量信号p设计所述滤波器,包括:
[0031]
对信号来向位于[
‑
15
°
,15
°
]范围内的所有频点信号进行保留,据此,滤波器设计公式为:
[0032][0033]
其中,g(k)为滤波器增益函数;
[0034]
得到滤波器增益函数g(k)后,将v1所对应的第一声矢量频域单帧信号x
win
(k)与g(k)相乘,可得到频域单帧增强语音信号,
[0035]
x
enhwin
(k)=x
win
(k)
×
g(ω)
ꢀꢀꢀ
(11)
[0036]
其中,x
enhwin
(k)为频域单帧增强语音信号。
[0037]
可选地,所述进行快速傅里叶逆变换与时域增强语音生成,得到增强的语音信号,包括:对去除空间噪声的频域单帧增强语音信号x
enhwin
(k)进行ifft,得到对应的时域单帧增强语音信号,
[0038]
x
enhwin
(k)=ifft(x
enhwin
(k))
ꢀꢀꢀ
(12)
[0039]
其中,x
enhwin
(k)为时域单帧增强语音信号,ifft为ifft算子;
[0040]
得到所有时域单帧增强语音后,按照叠接相加法将其按分帧和加窗参数进行合成得到整段带噪语音的增强结果。
[0041]
第二方面,本发明提供了一种基于矢量语音传感器阵列的语音增强装置,该装置包括:
[0042]
采集单元,用于采集带噪语音信号,其中,所述采集单元是由两个相互正交的矢量语音传感器和一个全向麦克风作为原始声信号构成,且所述矢量语音传感器和所述全向麦克风是同点布置的;
[0043]
处理单元,用于对所述带噪语音信号进行分帧与加窗,并进行单帧信号快速傅里叶变换fft,然后计算各频点信号来向,对空间噪声进行去除,最后进行快速傅里叶逆变换ifft与时域增强语音生成,得到增强的语音信号。
[0044]
本发明有益效果如下:
[0045]
本发明利用两个相互正交的矢量语音传感器组成阵列,可以利用麦克风阵列语音增强技术进行语音增强,且由于阵元可以同点布置,因此具有小型化的特点。此外,矢量语音传感器本身即具有天然的抑制漫反射噪声的能力,可以进一步提升拾音效果。因此,采用矢量语音传感器阵列来进行拾音,结合对应的语音增强技术,可以在小型化的前提下降低噪声干扰,有效提升拾音效果。
[0046]
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
[0047]
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
[0048]
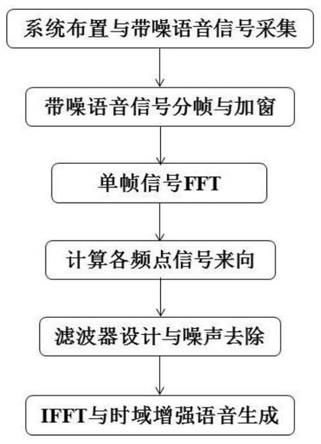
图1是本发明第一实施例提供的一种基于矢量语音传感器阵列的语音增强方法的流程示意图;
[0049]
图2是本发明第一实施例提供的采集单元的结构示意图;
[0050]
图3是本发明第二实施例提供的一种基于矢量语音传感器阵列的语音增强装置的流程示意图。
具体实施方式
[0051]
本发明实施例针对现有不能在小型化的前提下实现语音增强技术的问题,通过利用两个相互正交的矢量语音传感器组成阵列,可以利用麦克风阵列语音增强技术进行语音增强,且由于阵元可以同点布置,因此具有小型化的特点。此外,矢量语音传感器本身即具有天然的抑制漫反射噪声的能力,可以进一步提升拾音效果。因此,采用矢量语音传感器阵列来进行拾音,结合对应的语音增强技术,可以在小型化的前提下降低噪声干扰,有效提升拾音效果。以下结合附图以及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不限定本发明。
[0052]
本发明第一实施例提供了一种基于矢量语音传感器阵列的语音增强方法,参见图1,该方法包括:
[0053]
s101、利用两个相互正交的矢量语音传感器和一个全向麦克风作为原始声信号采集单元进行带噪语音信号采集,其中,所述矢量语音传感器和所述全向麦克风是同点布置的;
[0054]
也即,本发明实施例中的所述两个相互正交的矢量语音传感器分别是第一矢量语音传感器v1和第二矢量语音传感器v2,所述第一矢量语音传感器v1的敏感方向为0
°
,所述第二矢量语音传感器v2的敏感方向为90
°
,第一矢量语音传感器v1和所述第二矢量语音传感器v2所在平面的角度范围为[
‑
180,180];
[0055]
所述第一矢量语音传感器v1采集到第一声矢量信号x,所述第二矢量语音传感器v2采集到第二声矢量信号y,其中,所述第一矢量语音传感器v1与所述第二矢量语音传感器所采集到的声矢量信号是正交的,所述全向麦克风采集到声标量信号p。
[0056]
s102、对所述带噪语音信号进行分帧与加窗;
[0057]
具体来说,本发明实施例是对所述第一矢量语音传感器v1采集到第一声矢量信号x、所述第二矢量语音传感器v2采集到第二声矢量信号y,以及所述全向麦克风采集到的声标量信号p进行分帧加窗,得到对应的单帧时域带噪语音信号,即第一声矢量单帧信号x
win
(l)、第二声矢量单帧信号y
win
(l)、声标量单帧信号p
win
(l),其中,l=1,2,
…
,l,l为单帧时域带噪语音信号长度。
[0058]
其中,本发明实施例中分帧加窗的帧长为20ms,帧移为10ms,窗函数为汉宁窗。当然在具体实施时,本领域技术人员也可以根据实际需要采用其他分帧加窗参数,本发明对此不作详细限定。
[0059]
s103、进行单帧信号快速傅里叶变换fft;
[0060]
也即,是对单帧时域带噪语音信号x
win
(l),y
win
(l),p
win
(l)进行如下处理,
[0061][0062][0063]
[0064]
其中,ceil表示向上取整,x
fwin
(l),y
fwin
(l),p
fwin
(l)分别为对应v1、v2、u的第一声矢量待变换时域单帧信号、第二声矢量待变换时域单帧信号、声标量待变换时域单帧信号;
[0065]
得到x
fwin
(l),y
fwin
(l),p
fwin
(l)后,利用fft将其转换到频域,得到单帧频域带噪语音信号,
[0066]
x
win
(k)=fft(x
fwin
(l))
ꢀꢀꢀ
(4)
[0067]
y
win
(k)=fft(y
fwin
(l))
ꢀꢀꢀ
(5)
[0068]
p
win
(k)=fft(p
fwin
(l))
ꢀꢀꢀ
(6)
[0069]
其中,x
win
(k),y
win
(k),p
win
(k)分别为对应v1、v2、u的单帧频域带噪语音信号,k为频点序号,fft为快速傅里叶变换算子。
[0070]
s104、计算各频点信号来向;
[0071]
具体实施时,本发明实施例是利用第一声矢量待变换时域单帧信号x
fwin
(l)、第二声矢量待变换时域单帧信号y
fwin
(l)、声标量待变换时域单帧信号p
fwin
(l)快速傅里叶变换后的第一声矢量频域单帧信号x
win
(k)、第二声矢量频域单帧信号y
win
(k)、声标量频域单帧信号p
win
(k),对各个频点的信号进行定向,确定各个频点信号的来向,判断其是否属于目标语音;
[0072]
采用标量声场与矢量声场组成的复声强器进行定向,以减少环境噪声对定向结果的影响,提高定向精度,复声强器的定义为,
[0073][0074][0075]
其中,i
px
(k),i
py
(k)分别代表频点k处,p分量与x分量、p分量与y分量组成的复声强器,
*
代表复共轭,re代表取实部;
[0076]
得到i
px
(k),i
py
(k)后,各频点信号的来向可由下式计算求得,
[0077][0078]
其中,θ(k)代表频点k处的信号来向,arctan代表反正切算子。
[0079]
s105、对空间噪声进行去除;
[0080]
本发明实施例是通过滤波器对空间噪声进行去除,以及根据所述第一矢量语音传感器v1采集到第一声矢量信号x、所述第二矢量语音传感器v2采集到第二声矢量信号y,以及所述全向麦克风采集到的声标量信号p设计所述滤波器。
[0081]
具体来说,本发明实施例是对信号来向位于[
‑
15
°
,15
°
]范围内的所有频点信号进行保留,据此,滤波器设计公式为:
[0082][0083]
其中,g(k)为滤波器增益函数;
[0084]
得到滤波器增益函数g(k)后,将v1所对应的单帧频域带噪语音信号x
win
(k)与g(k)相乘,可得到频域单帧增强语音信号,
[0085]
x
enhwin
(k)=x
win
(k)
×
g(ω)
ꢀꢀꢀ
(11)
[0086]
其中,x
enhwin
(k)为频域单帧增强语音信号。
[0087]
s106、进行快速傅里叶逆变换ifft与时域增强语音生成,得到增强的语音信号。
[0088]
该步骤具体包括:对去除空间噪声的频域单帧增强语音信号x
enhwin
(k)进行ifft,得到对应的时域单帧增强语音信号,
[0089]
x
enhwin
(k)=ifft(x
enhwin
(k))
ꢀꢀꢀ
(12)
[0090]
其中,x
enhwin
(k)为时域单帧增强语音信号,ifft为ifft算子;
[0091]
得到所有时域单帧增强语音后,按照叠接相加法将其按分帧和加窗参数进行合成得到整段带噪语音的增强结果。
[0092]
也就是说,本发明实施例是通过利用两个相互正交的矢量语音传感器组成阵列,可以利用麦克风阵列语音增强技术进行语音增强,且由于阵元可以同点布置,因此具有小型化的特点。此外,矢量语音传感器本身即具有天然的抑制漫反射噪声的能力,可以进一步提升拾音效果。因此,采用矢量语音传感器阵列来进行拾音,结合对应的语音增强技术,可以在小型化的前提下降低噪声干扰,有效提升拾音效果。
[0093]
下面将通过一个具体的例子来对本发明所述的方法进行详细的解释和说明:
[0094]
本发明利用两个相互正交的矢量语音传感器和一个全向麦克风作为原始声信号采集单元(三个阵元同点布置),根据采集到的声矢量信号和声标量信号设计滤波器,对空间噪声进行去除。具体包括:1)系统布置与带噪语音信号采集;2)带噪语音信号分帧与加窗;3)单帧信号fft(fast fourier transform,快速傅里叶变换);4)计算各频点信号来向;5)滤波器设计与噪声去除;6)ifft(inverse fast fourier transform,快速傅里叶逆变换)与时域增强语音生成。
[0095]
模块1进行信号采集:
[0096]
如图2所示为本发明的采集采集单元的布置图,由图2可知,本发明实施例的矢量语音传感器阵列所在平面的角度范围定义为[
‑
180,180);v1和v2分别代表矢量语音传感器阵列中的两个矢量语音传感器,用于采集声矢量信号,其敏感方向分别为0
°
和90
°
;u代表矢量语音传感器阵列中的全向麦克风,用于采集标量声场;目标声源方向角为0
°
。阵列中添加全向麦克风的目的在于利用复声强器进行声源定向,以此达到提高定向精度的目的。全系统的目的为尽量保留来自于目标声源方向(0
°
)的目标语音信号,而对其它角度范围内的非目标语音信号(噪声)进行抑制。
[0097]
按照图2所示布置完毕后,利用矢量语音传感器阵列对带噪语音信号采集,v1、v2、u采集到的信号分别记为x,y,p,然后进入下一步骤。
[0098]
模块2带噪语音信号分帧与加窗:
[0099]
分帧和加窗是语音信号处理中的基本预处理过程,其目的是保证所处理的语音信号为近似平稳信号。对模块1中的x,y,p进行分帧加窗,得到对应的单帧时域带噪语音信号x
win
(l),y
win
(l),p
win
(l)(l=1,2,
…
,l,l为单帧时域带噪语音信号长度)。分帧加窗参数选择如下:帧长:20ms;帧移:10ms;窗函数:汉宁窗。
[0100]
模块3是单帧信号fft:
[0101]
本模块目的是将单帧时域带噪语音信号转换到频域。由于fft要求信号长度为2的整数次幂,而对于采样率不同的信号,根据模块2的帧长参数选择,单帧时域带噪语音信号的长度不一定满足该条件。为此,对单帧时域带噪语音信号x
win
(l),y
win
(l),p
win
(l)进行如
下处理,
[0102][0103][0104][0105]
其中,ceil表示向上取整,x
fwin
(l),y
fwin
(l),p
fwin
(l)分别为对应v1、v2、u的第一声矢量待变换时域单帧信号、第二声矢量待变换时域单帧信号、声标量待变换时域单帧信号。
[0106]
得到x
fwin
(l),y
fwin
(l),p
fwin
(l)后,就可以利用fft将其转换到频域,得到单帧频域带噪语音信号,
[0107]
x
win
(k)=fft(x
fwin
(l))
ꢀꢀꢀ
(4)
[0108]
y
win
(k)=fft(y
fwin
(l))
ꢀꢀꢀ
(5)
[0109]
p
win
(k)=fft(p
fwin
(l))
ꢀꢀꢀ
(6)
[0110]
其中,x
win
(k),y
win
(k),p
win
(k)分别为对应v1、v2、u的第一声矢量频域单帧信号、第二声矢量频域单帧信号、声标量频域单帧信号,k为频点序号,fft为快速傅里叶变换算子。
[0111]
模块4计算各频点信号来向具体是:
[0112]
本模块目的是根据模块1,模块2,模块3得到的x
win
(k),y
win
(k),p
win
(k),对各个频点的信号进行定向,确定各个频点信号的来向,判断其是否属于目标语音。
[0113]
为减少环境噪声对定向结果的影响,提高定向精度,采用标量声场与矢量声场组成的复声强器进行定向,复声强器的定义为,
[0114][0115][0116]
其中,i
px
(k),i
py
(k)分别代表频点k处,p分量与x分量、p分量与y分量组成的复声强器,
*
代表复共轭,re代表取实部。
[0117]
得到i
px
(k),i
py
(k)后,各频点信号的来向可由下式计算求得,
[0118][0119]
其中,θ(k)代表频点k处的信号来向,arctan代表反正切算子。
[0120]
模块5是滤波器设计与噪声去除:通过模块1,模块2,模块3,模块4得到各频点的信号来向后,即可根据信号来向设计滤波器。滤波器的设计原则为:在实际操作中,定向结果会存在误差,同时目标声源不一定完全的位于0
°
方向,因此为提高系统鲁棒性,设置15
°
的缓冲区间,即对信号来向位于[
‑
15
°
,15
°
]范围内的所有频点信号进行保留。据此,滤波器设计可由以下公式表征:
[0121][0122]
其中,g(k)为滤波器增益函数。
[0123]
得到滤波器增益函数g(k)后,将v1所对应的单帧频域带噪语音信号x
win
(k)与g(k)相乘,可得到频域单帧增强语音信号,
[0124]
x
enhwin
(k)=x
win
(k)
×
g(ω)
ꢀꢀꢀ
(11)
[0125]
其中,x
enhwin
(k)为频域单帧增强语音信号。
[0126]
模块6是ifft与时域增强语音生成:通过模块1,模块2,模块3,模块4,模块5得到频域单帧增强语音信号x
enhwin
(k)后,对x
enhwin
(k)进行ifft,可以得到对应的单帧时域增强语音信号,
[0127]
x
enhwin
(k)=ifft(x
enhwin
(k))
ꢀꢀꢀ
(12)
[0128]
其中,x
enhwin
(k)为单帧时域增强语音信号,ifft为ifft算子。
[0129]
得到所有单帧时域增强语音后,按照叠接相加法(ola,overlap
‑
and
‑
add)将其按分帧和加窗参数进行合成,即可得到整段带噪语音的增强结果。
[0130]
总体来说,本发明实施例是利用矢量语音传感器阵列进行语音信号采集,通过复声强器对每个频点的声信号进行定向,并根据定向结果设计滤波器,实现对噪声的去除。相对于单麦克风语音增强技术,本发明可以去除空间中的非平稳噪声;相对于传统的麦克风阵列语音增强技术,本发明具有更小的尺寸。此外,本发明可以充分利用矢量语音传感器本身的噪声抑制特性,进一步提高拾音效果。
[0131]
本发明第二实施例提供了一种基于矢量语音传感器阵列的语音增强装置,参见图3,包括:采集单元,用于采集带噪语音信号,其中,所述采集单元是由两个相互正交的矢量语音传感器和一个全向麦克风作为原始声信号构成,且所述矢量语音传感器和所述全向麦克风是同点布置的;处理单元,用于对所述带噪语音信号进行分帧与加窗,并进行单帧信号快速傅里叶变换fft,然后计算各频点信号来向,对空间噪声进行去除,最后进行快速傅里叶逆变换ifft与时域增强语音生成,得到增强的语音信号。
[0132]
总体来说,本发明实施例是通过利用两个相互正交的矢量语音传感器组成阵列,可以利用麦克风阵列语音增强技术进行语音增强,且由于阵元可以同点布置,因此具有小型化的特点。此外,矢量语音传感器本身即具有天然的抑制漫反射噪声的能力,可以进一步提升拾音效果。因此,采用矢量语音传感器阵列来进行拾音,结合对应的语音增强技术,可以在小型化的前提下降低噪声干扰,有效提升拾音效果。
[0133]
本发明实施例的相关内容可参见本发明第一实施例进行理解,在此不做详细论述。
[0134]
尽管为示例目的,已经公开了本发明的优选实施例,本领域的技术人员将意识到各种改进、增加和取代也是可能的,因此,本发明的范围应当不限于上述实施例。