1.本发明涉及语音合成技术领域,尤其涉及一种声学模型训练集的优化生成方法、系统、存储介质及其计算机设备。
背景技术:
2.随着语音技术的发展,人们对tts(text to speech,从文本到语音)合成的声音的要求也逐渐提高;对身边的人,有时需要在某个时刻有一个特别温柔的声音;例如,辅导小孩写作业与智能终端设备如音箱的互动可能是较为严肃的,这时候人机互动涉及到的意图可能有“查询题目”,晚上睡觉前为了哄孩子睡觉,可能会播放儿歌,这个时候说话的声音也会比较温柔。所以总的而言,面对不同的场景,具体到同领域的不同意图,客户都存在着音色、音调的区别。
3.如何让tts播报的声音更容易让家庭身边的人“陶醉”、烘托或者缓和气氛,毕竟大家都喜欢听播放儿歌时的音色,而不是查询题目的音色;是现存需要解决的一大难题。而现有的大多数语音技术方案商都未能提供相应的解决方案。
4.综上可知,现有的方法在实际使用上,存在着较多的问题,所以有必要加以改进。
技术实现要素:
5.针对上述的缺陷,本发明的目的在于提供一种声学模型训练集的优化生成方法,系统、存储介质及其计算机设备,通过优化生成的训练集能够使得语音合成播报的声音更容易烘托或者缓和气氛,可避免僵硬的播报方式。
6.为了实现上述目的,本发明提供一种声学模型训练集的优化生成方法,包括有:
7.采集转化步骤,采集语音输入信号并转化成文本数据;
8.第一分析步骤,分析所述文本数据所对应的领域和意图信息,并根据所述领域和所述意图信息以生成对应的反馈信息;
9.第二分析步骤,分析所述意图信息对应的音频特征,并根据所述音频特征以生成所述反馈信息对应的反馈音频;
10.优化生成步骤,根据所述反馈音频以优化生成声学模型的训练集。
11.所述优化生成步骤进一步包括:
12.分析所述反馈音频的特征向量,并将所述特征向量对应的参数作为所述声学模型的所述训练集。
13.可选的,所述优化生成步骤包括:
14.特征向量步骤,分析至少两个所述意图信息对应的所述反馈音频的所述特征向量;
15.差值比对步骤,比对所述至少两个所述意图信息对应的所述特征向量之间的差值;
16.优化项选取步骤,根据所述差值与预置的录入规则以选取对应的所述意图信息的所述反馈音频,并将选取的所述反馈音频设为用于优化生成所述训练集的优化项。
17.可选的,所述优化生成步骤包括:
18.判断所述意图信息是否为预置信息,若是则将所述意图信息对应的所述反馈音频设为用于优化生成所述训练集的优化项。
19.还提供了一种声学模型训练集的优化生成系统,包括有:
20.采集转化单元,用于采集语音输入信号并转化成文本数据;
21.第一分析单元,用于分析所述文本数据所对应的领域和意图信息,并根据所述领域和所述意图信息以生成对应的反馈信息;
22.第二分析单元,用于分析所述意图信息对应的音频特征,并根据所述音频特征以生成所述反馈信息对应的反馈音频;
23.优化生成单元,用于根据所述反馈音频以优化生成声学模型的训练集。
24.所述优化生成单元进一步用于:
25.分析所述反馈音频的特征向量,并将所述特征向量对应的参数作为所述声学模型的所述训练集。
26.可选的,所述优化生成单元包括:
27.特征向量子单元,用于分析至少两个所述意图信息对应的所述反馈音频的所述特征向量;
28.差值比对子单元,用于比对所述至少两个所述意图信息对应的所述特征向量之间的差值;
29.优化项选取子单元,用于根据所述差值与预置的录入规则以选取对应的所述意图信息的所述反馈音频,并将选取的所述反馈音频设为用于优化生成所述训练集的优化项。
30.可选的,所述优化生成单元用于:
31.判断所述意图信息是否为预置信息,若是则将所述意图信息对应的所述反馈音频设为用于优化生成所述训练集的优化项。
32.另外,还提供了一种存储介质和计算机设备,所述存储介质用于存储一种用于执行上述声学模型训练集的优化生成方法的计算机程序。
33.所述计算机设备包括存储介质、处理器以及存储在所述存储介质上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述的声学模型训练集的优化生成方法。
34.本发明所述的声学模型训练集的优化生成方法及其系统,通过分析出语音输入信号所对应的领域和意图信息,并根据意图信息分析对应的音频特征,将所述音频特征对应传入语音合成的反馈语音作为声学模型的训练集的优化项进行优化。从而使得本发明可根据对应的领域和意图信息,在处理数据时,偏向性的训练,以优化相对应的声学模型,最后通过声学模型参数的改变,将数据传入声码器,转化为对应的语音合成的播报声音,使得语音合成播报的声音更容易烘托或者缓和气氛,可避免僵硬的播报方式。
附图说明
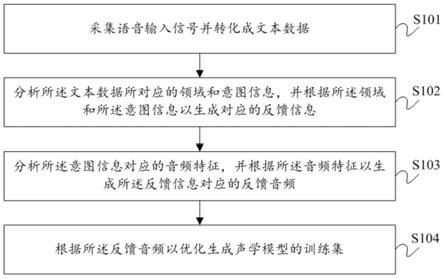
35.图1为本发明优选实施例所述声学模型训练集的优化生成方法的步骤流程图;
36.图2为本发明所述声学模型训练集的优化生成方法的所述采集转化步骤可选的具体步骤流程图;
37.图3为本发明所述声学模型训练集的优化生成方法的所述第一分析步骤可选的第一种具体步骤流程图;
38.图4为本发明所述声学模型训练集的优化生成方法的所述第一分析步骤可选的第二种具体步骤流程图;
39.图5为本发明所述声学模型训练集的优化生成方法的所述第二分析步骤可选的具体步骤流程图;
40.图6为本发明所述声学模型训练集的优化生成方法的所述优化生成步骤可选的具体步骤流程图;
41.图7为本发明优选实施例所述声学模型训练集的优化生成系统的结构框图;
42.图8为本发明所述声学模型训练集的优化生成系统的所述采集转化单元可选的具体结构框图;
43.图9为本发明所述声学模型训练集的优化生成系统的所述第一分析单元可选的具体结构框图;
44.图10为本发明所述声学模型训练集的优化生成系统的所述第二分析单元可选的具体结构框图;
45.图11为本发明所述声学模型训练集的优化生成系统的所述优化生成单元可选的具体结构框图;
46.图12为语音合成技术的原理示意图。
具体实施方式
47.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
48.需要说明的,本说明书中针对“一个实施例”、“实施例”、“示例实施例”等的引用,指的是描述的该实施例可包括特定的特征、结构或特性,但是不是每个实施例必须包含这些特定特征、结构或特性。此外,这样的表述并非指的是同一个实施例。进一步,在结合实施例描述特定的特征、结构或特性时,不管有没有明确的描述,已经表明将这样的特征、结构或特性结合到其它实施例中是在本领域技术人员的知识范围内的。
49.此外,在说明书及后续的权利要求当中使用了某些词汇来指称特定组件或部件,所属领域中具有通常知识者应可理解,制造商可以用不同的名词或术语来称呼同一个组件或部件。本说明书及后续的权利要求并不以名称的差异来作为区分组件或部件的方式,而是以组件或部件在功能上的差异来作为区分的准则。在通篇说明书及后续的权利要求书中所提及的“包括”和“包含”为一开放式的用语,故应解释成“包含但不限定于”。以外,“连接”一词在此系包含任何直接及间接的电性连接手段。间接的电性连接手段包括通过其它装置进行连接。
50.图1示出本发明所述声学模型训练集的优化生成方法,包括有:
51.s101:采集语音输入信号并转化成文本数据。该过程是将音频转化为文本的过程,
采集的语音输入信号为录入音频,具体可以是用户跟机器交互所输入的语音或用户对机器的命令语音等。
52.s102:分析所述文本数据所对应的领域和意图信息,并根据所述领域和所述意图信息以生成对应的反馈信息。在实际的语音交互场景中,领域和意图往往能反馈绝大多数的交互场景或者人们的需求;本实施例通过分析该文本数据的内容,获取该内容所对应的领域和意图;例如,文本数据为:通过歌曲哄孩子入睡;则经分析获得对应的领域为:音乐;意图信息为:播放安眠儿歌。进而根据对应的领域和意图信息生成对应的反馈信息,在上述例子中,对应的反馈信息即为开启音乐播放功能以播放哄儿童的安眠曲。
53.s103:分析所述意图信息对应的音频特征,并根据所述音频特征以生成所述反馈信息对应的反馈音频。其中,音频特征包括但不限于声音的特征向量如性别、高低音、韵律等信息;所述反馈音频与对应的意图信息相关联;通过分析所述文本数据的意图信息,获取该意图信息与之匹配的音频特征;例如,辅导小孩写作业与智能终端设备如音箱的互动,则对应的音频特征可能是较为严肃的,这时候人机互动涉及到的意图可能有“查询题目”;或者,晚上睡觉前为了哄孩子睡觉,可能会播放儿歌,这个时候说话的声音也会比较温柔。具体根据意图信息的区别,为其通过音频特征如性别、高低音、韵律等来配置不同的音色和/或音调,使得语音合成的播报音频更具有针对性,避免其播放语调的固定僵硬化。
54.s104:根据所述反馈音频以优化生成声学模型的训练集。根据领域和意图的不同,在经语音合成的处理数据时,偏向性的训练,以优化相对应的声学模型(声码器),最后通过声学模型参数的改变,将数据传入声码器,转化为对应的语音合成的播报声音。本实施例通过基于领域和意图的分析而生成对应该意图信息的音频来对tts训练集进行优化,能使所述训练集的选取更具有目的性;使tts播报的声音更容易让家庭身边的人“陶醉”、烘托或者缓和气氛,毕竟大家都喜欢听播放儿歌时的音色,而不是查询题目的音色。
55.tts技术本质上解决的是:从文本转化为语音的问题,通过这种方式让机器开口说话。但这个过程并不容易,为了降低机器理解的难度,科学家们将这个转化过程拆分成了两个部分:前端系统和后端系统,如图12所示;前端负责把输入的文本转化为一个中间结果,然后把这个中间结果送给后端,由后端生成声音;前端系统生成“语言学规格书”。
56.目前主流的后端系统有两种方法:一种是基于波形拼接的方法,一种是基于参数生成的方法。参数生成法的系统直接使用数学的方法,先从音频里总结出音频最明显的特征,然后使用学习算法来学习一个如何把前端语言学规格书映射到这些音频特征的转换器。一但我们有了这个从语言学规格书到音频特征的转换器,例如合成《你真好看》这四个字的时候,我们先使用这个转换器转换出音频特征,然后用另一个组件,把这些音频特征还原成我们可以听到的声音。在本领域里,这个转换器叫:声学模型,把声音特征转化为声音的组件叫声码器。
57.本实施例的所述步骤s104进一步包括:分析所述反馈音频的特征向量,并将所述特征向量对应的参数作为所述声学模型的所述训练集。当训练集对应的云服务器收到该对应的音频时,则分析对应音频的特征向量,并将其特征向量对应的参数作为声学模型的训练集。
58.参见图6,可选的,步骤s104包括:
59.s1041:分析至少两个所述意图信息对应的所述反馈音频的所述特征向量;
60.s1042:比对所述至少两个所述意图信息对应的所述特征向量之间的差值;
61.s1043:根据所述差值与预置的录入规则以选取对应的所述意图信息的所述反馈音频,并将选取的所述反馈音频设为用于优化生成所述训练集的优化项。将不同意图的音频收集后,则分析这些音频对应的音频特征包括但不限于声音的特征向量,一般而言,通过对应声音之间特征向量的差值来选取,如我们认为女性高音会比女性低音相对来说更好听,则找到女性相对高音对应的意图作为以后意图的音频的主要收集项,并将其音频纳入到训练集。
62.在另一实施例中,可选的,所述步骤s104包括:判断所述意图信息是否为预置信息,若是则将所述意图信息对应的所述反馈音频设为用于优化生成所述训练集的优化项。具体由语音技术方案提供商对于特定的意图进行事先定义,在收集训练集的同时只收集固定的意图对应的音频并对音频进行分析来优化tts的声学模型。当然,意图与音频之间关系包括但不限于以上两种方式,凡是通过意图的区别来进行tts训练集的优化项均属于本专利的保护范围内。
63.参见图2,可选的,步骤s101包括:
64.s1011:采集外部输入的语音输入信号;具体通过上述的语音合成的前端和asr(自动语音识别技术)收集语音输入信号。
65.s1012:通过语音识别技术以将所述语音输入信号转化成文本数据。
66.进一步的,步骤s101之后包括:
67.发送步骤,将所述文本数据发送至nlp(natural language processing,自然语言处理)引擎;
68.步骤s102包括:通过所述nlp引擎分析所述文本数据以获得对应的领域以及意图信息,并根据所述领域和所述意图信息以生成对应的反馈信息。
69.参见图3,可选的,步骤s102包括:
70.s1021:将所述文本数据转化为机器语言;
71.s1022:分析所述机器语言中对应的领域和意图信息;
72.s1023:根据所述领域和所述意图信息以生成对应的反馈信息。
73.进一步的,参见图4,在另一实施例中,可选的,步骤s102还包括:
74.s1024:根据所述机器语言以填充所述意图信息对应的意图槽位;
75.s1025:根据所述领域、所述意图信息以及所述意图槽位以匹配生成对应的反馈信息。
76.首先nlu(natural language understanding,自然语言理解)需要去理解传入文本的意图;例如,nlu服务器将该文本转化为机器可以理解的语言并分析出对话a的意图为播放儿歌,同时填充该意图槽位歌手、歌曲名称为贝瓦儿歌、小兔子乖乖等。将以上领域、意图及相关槽位发送至对话管理系统和语言生成系统,找到与对应意图相关的信息再发送到tts训练集对应的服务器。
77.参见图5,可选的,步骤s103包括:
78.s1031:分析所述意图信息对应的音频特征;
79.s1032:将所述音频特征与所述反馈信息结合以生成对应的反馈音频。
80.分析该意图对应的音频特征,声音的音频特征包括但不限于声音的特征向量如性
别、高低音、韵律等信息;并将经分析所得的音频特征对应的音频作为tts的训练集。训练集优化项的收集方式优选为上述的事先定义或者对比声音之间特征向量的差值的方式。tts训练集对应的云服务器收到该对应的音频时,则分析对应音频的特征向量,并将其特征向量对应的参数作为声学模型的训练集。当意图对应的音频越多,则特征向量越具有代表性,则对声学模型的训练影响越大。
81.图7示出本发明优选实施例所述的声学模型训练集的优化生成系统100,包括有采集转化单元10、第一分析单元20、第二分析单元30以及优化生成单元40,其中:
82.采集转化单元10用于采集语音输入信号并转化成文本数据;第一分析单元20用于分析所述文本数据所对应的领域和意图信息,并根据所述领域和所述意图信息以生成对应的反馈信息;具体可采用自然语言理解技术或者人工智能技术等方式分析对应的领域和意图信息;第二分析单元30用于分析所述意图信息对应的音频特征,并根据所述音频特征以生成所述反馈信息对应的反馈音频;可以是通过预先定义的匹配规则,结合对意图信息的分析来获取对应匹配的音频特征,如意图是哄小孩入睡,则对应音频特征的韵律可以是温柔、轻声调等音频特征;优化生成单元40用于根据所述反馈音频以优化生成声学模型的训练集。根据领域和意图的不同,在经语音合成的处理数据时,偏向性的训练,以优化相对应的声学模型(声码器),最后通过声学模型参数的改变,将数据传入声码器,转化为对应的语音合成的播报声音。
83.本实施例通过基于领域和意图的分析而生成对应该意图信息的音频来对tts(text to speech,从文本到语音)训练集进行优化,能使所述训练集的选取更具有目的性;使tts播报的声音更容易让家庭身边的人“陶醉”、烘托或者缓和气氛,毕竟大家都喜欢听播放儿歌时的音色,而不是查询题目的音色。
84.优选的是,本实施例的优化生成单元40进一步用于分析所述反馈音频的特征向量,并将所述特征向量对应的参数作为所述声学模型的所述训练集。当训练集对应的云服务器收到该对应的音频时,则分析对应音频的特征向量,并将其特征向量对应的参数作为声学模型的训练集。
85.参见图11,可选的,优化生成单元40包括有特征向量子单元41、差值比对子单元42和优化项选取子单元43,其中:
86.特征向量子单元41用于分析至少两个所述意图信息对应的所述反馈音频的所述特征向量;差值比对子单元42用于比对所述至少两个所述意图信息对应的所述特征向量之间的差值;优化项选取子单元43用于根据所述差值与预置的录入规则以选取对应的所述意图信息的所述反馈音频,并将选取的所述反馈音频设为用于优化生成所述训练集的优化项。将不同意图的音频收集后,则分析这些音频对应的音频特征包括但不限于声音的特征向量,一般而言,通过对应声音之间特征向量的差值来选取,如我们认为女性高音会比女性低音相对来说更好听,则找到女性相对高音对应的意图作为以后意图的音频的主要收集项,并将其音频纳入到训练集。
87.其他实施例中,优化生成单元40可用于判断所述意图信息是否为预置信息,若是则将所述意图信息对应的所述反馈音频设为用于优化生成所述训练集的优化项。具体由语音技术方案提供商对于特定的意图进行事先定义,在收集训练集的同时只收集固定的意图对应的音频并对音频进行分析来优化tts的声学模型。
88.参见图8,可选的,采集转化单元10包括采集子单元11和转化子单元12,其中:
89.采集子单元11用于采集外部输入的语音输入信号;转化子单元12用于通过语音识别技术以将所述语音输入信号转化成文本数据。
90.可选的,还包括有发送单元,发送单元用于将文本数据发送至nlp引擎;
91.所述第一分析单元20用于:通过所述nlp引擎分析所述文本数据以获得对应的领域以及意图信息,并根据所述领域和所述意图信息以生成对应的反馈信息。
92.参见图9,可选的,第一分析单元20包括有转化子单元21、领域意图分析子单元22以及反馈生成子单元24;其中:
93.转化子单元21用于将所述文本数据转化为机器语言;领域意图分析子单元22用于分析所述机器语言中对应的领域和意图信息;反馈生成子单元23用于根据所述领域和所述意图信息以生成对应的反馈信息。
94.进一步的,第一分析单元20还包括有槽位填充子单元23,槽位填充子单元23用于根据所述机器语言以填充所述意图信息对应的意图槽位;反馈生成子单元24还用于根据所述领域、所述意图信息以及所述意图槽位以匹配生成对应的反馈信息。首先nlu需要去理解传入文本的意图;例如,nlu服务器将该文本转化为机器可以理解的语言并分析出对话a的意图为播放儿歌,同时填充该意图槽位歌手、歌曲名称为贝瓦儿歌、小兔子乖乖等。将以上领域、意图及相关槽位发送至对话管理系统和语言生成系统,找到与对应意图相关的信息再发送到tts训练集对应的服务器。
95.参见图10,第二分析单元30包括有音频特征分析子单元31和反馈音频生成子单元32,其中:
96.音频特征分析子单元31用于分析所述意图信息对应的音频特征;反馈音频生成子单元32用于将所述音频特征与所述反馈信息结合以生成对应的反馈音频。训练集优化项的收集方式优选为上述的事先定义或者对比声音之间特征向量的差值的方式。tts训练集对应的云服务器收到该对应的音频时,则分析对应音频的特征向量,并将其特征向量对应的参数作为声学模型的训练集。当意图对应的音频越多,则特征向量越具有代表性,则对声学模型的训练影响越大。
97.本发明还提供一种存储介质,用于存储如图1~图6所述声学模型训练集的优化生成方法的计算机程序。例如计算机程序指令,当其被计算机执行时,通过该计算机的操作,可以调用或提供根据本技术的方法和/或技术方案。而调用本技术的方法的程序指令,可能被存储在固定的或可移动的存储介质中,和/或通过广播或其他信号承载媒体中的数据流而被传输和/或被存储在根据程序指令运行的计算机设备的存储介质中。在此,根据本技术的一个实施例包括如图7所示声学模型训练集的优化生成系统的计算机设备,所述计算机设备优选包括用于存储计算机程序的存储介质和用于执行计算机程序的处理器,其中,当该计算机程序被该处理器执行时,触发该计算机设备执行基于前述多个实施例中的方法和/或技术方案。
98.需要注意的是,本技术可在软件和/或软件与硬件的组合体中被实施,例如,可采用专用集成电路(asic)、通用目的计算机或任何其他类似硬件设备来实现。在一个实施例中,本技术的软件程序可以通过处理器执行以实现上文步骤或功能。同样地,本技术的软件程序(包括相关的数据结构)可以被存储到计算机可读记录介质中,例如,ram存储器,磁或
光驱动器或软磁盘及类似设备。另外,本技术的一些步骤或功能可采用硬件来实现,例如,作为与处理器配合从而执行各个步骤或功能的电路。
99.根据本发明的方法可以作为计算机实现方法在计算机上实现、或者在专用硬件中实现、或以两者的组合的方式实现。用于根据本发明的方法的可执行代码或其部分可以存储在计算机程序产品上。计算机程序产品的示例包括存储器设备、光学存储设备、集成电路、服务器、在线软件等。优选地,计算机程序产品包括存储在计算机可读介质上以便当所述程序产品在计算机上执行时执行根据本发明的方法的非临时程序代码部件。
100.在优选实施例中,计算机程序包括适合于当计算机程序在计算机上运行时执行根据本发明的方法的所有步骤的计算机程序代码部件。优选地,在计算机可读介质上体现计算机程序。
101.综上所述,本发明所述的声学模型训练集的优化生成方法及其系统,通过分析出语音输入信号所对应的领域和意图信息,并根据意图信息分析对应的音频特征,将所述音频特征对应传入语音合成的反馈语音作为声学模型的训练集的优化项进行优化。从而使得本发明可根据对应的领域和意图信息,在处理数据时,偏向性的训练,以优化相对应的声学模型,最后通过声学模型参数的改变,将数据传入声码器,转化为对应的语音合成的播报声音,使得语音合成播报的声音更容易烘托或者缓和气氛,可避免僵硬的播报方式。
102.当然,本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,熟悉本领域的技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
103.还提供了a1、一种声学模型训练集的优化生成方法,包括有:
104.采集转化步骤,采集语音输入信号并转化成文本数据;
105.第一分析步骤,分析所述文本数据所对应的领域和意图信息,并根据所述领域和所述意图信息以生成对应的反馈信息;
106.第二分析步骤,分析所述意图信息对应的音频特征,并根据所述音频特征以生成所述反馈信息对应的反馈音频;
107.优化生成步骤,根据所述反馈音频以优化生成声学模型的训练集。
108.a2、根据a1所述的声学模型训练集的优化生成方法,所述优化生成步骤进一步包括:
109.分析所述反馈音频的特征向量,并将所述特征向量对应的参数作为所述声学模型的所述训练集。
110.a3、根据a2所述的声学模型训练集的优化生成方法,所述优化生成步骤包括:
111.特征向量步骤,分析至少两个所述意图信息对应的所述反馈音频的所述特征向量;
112.差值比对步骤,比对所述至少两个所述意图信息对应的所述特征向量之间的差值;
113.优化项选取步骤,根据所述差值与预置的录入规则以选取对应的所述意图信息的所述反馈音频,并将选取的所述反馈音频设为用于优化生成所述训练集的优化项。
114.a4、根据a1所述的声学模型训练集的优化生成方法,所述优化生成步骤包括:
115.判断所述意图信息是否为预置信息,若是则将所述意图信息对应的所述反馈音频
设为用于优化生成所述训练集的优化项。
116.a5、根据a1所述的声学模型训练集的优化生成方法,所述采集转化步骤包括:
117.采集步骤,采集外部输入的语音输入信号;
118.转化步骤,通过语音识别技术以将所述语音输入信号转化成所述文本数据。
119.a6、根据a1所述的声学模型训练集的优化生成方法,所述采集转化步骤之后包括:
120.发送步骤,将所述文本数据发送至nlp引擎;
121.所述第一分析步骤包括:
122.通过所述nlp引擎分析所述文本数据以获得对应的领域以及意图信息,并根据所述领域和所述意图信息以生成对应的反馈信息。
123.a7、根据a1所述的声学模型训练集的优化生成方法,所述第一分析步骤包括:
124.转化步骤,将所述文本数据转化为机器语言;
125.领域意图分析步骤,分析所述机器语言中对应的领域和意图信息;
126.反馈生成步骤,根据所述领域和所述意图信息以生成对应的反馈信息。
127.a8、根据a7所述的声学模型训练集的优化生成方法,所述第一分析步骤还包括:
128.槽位填充步骤,根据所述机器语言以填充所述意图信息对应的意图槽位;
129.所述反馈生成步骤,根据所述领域、所述意图信息以及所述意图槽位以匹配生成对应的反馈信息。
130.a9、根据a1所述的声学模型训练集的优化生成方法,所述第二分析步骤包括:
131.音频特征分析步骤,分析所述意图信息对应的音频特征;
132.反馈音频生成步骤,将所述音频特征与所述反馈信息结合以生成对应的反馈音频。
133.还提供了b10、一种声学模型训练集的优化生成系统,包括有:
134.采集转化单元,用于采集语音输入信号并转化成文本数据;
135.第一分析单元,用于分析所述文本数据所对应的领域和意图信息,并根据所述领域和所述意图信息以生成对应的反馈信息;
136.第二分析单元,用于分析所述意图信息对应的音频特征,并根据所述音频特征以生成所述反馈信息对应的反馈音频;
137.优化生成单元,用于根据所述反馈音频以优化生成声学模型的训练集。
138.b11、根据b10所述的声学模型训练集的优化生成系统,所述优化生成单元进一步用于:
139.分析所述反馈音频的特征向量,并将所述特征向量对应的参数作为所述声学模型的所述训练集。
140.b12、根据b11所述的声学模型训练集的优化生成系统,所述优化生成单元包括:
141.特征向量子单元,用于分析至少两个所述意图信息对应的所述反馈音频的所述特征向量;
142.差值比对子单元,用于比对所述至少两个所述意图信息对应的所述特征向量之间的差值;
143.优化项选取子单元,用于根据所述差值与预置的录入规则以选取对应的所述意图信息的所述反馈音频,并将选取的所述反馈音频设为用于优化生成所述训练集的优化项。
144.b13、根据b10所述的声学模型训练集的优化生成系统,所述优化生成单元用于:
145.判断所述意图信息是否为预置信息,若是则将所述意图信息对应的所述反馈音频设为用于优化生成所述训练集的优化项。
146.b14、根据b10所述的声学模型训练集的优化生成系统,所述采集转化单元包括:
147.采集子单元,用于采集外部输入的语音输入信号;
148.转化子单元,用于通过语音识别技术以将所述语音输入信号转化成所述文本数据。
149.b15、根据b10所述的声学模型训练集的优化生成系统,还包括:
150.发送单元,用于将所述文本数据发送至nlp引擎;
151.所述第一分析单元用于:
152.通过所述nlp引擎分析所述文本数据以获得对应的领域以及意图信息,并根据所述领域和所述意图信息以生成对应的反馈信息。
153.b16、根据b10所述的声学模型训练集的优化生成系统,所述第一分析单元包括:
154.转化子单元,用于将所述文本数据转化为机器语言;
155.领域意图分析子单元,用于分析所述机器语言中对应的领域和意图信息;
156.反馈生成子单元,用于根据所述领域和所述意图信息以生成对应的反馈信息。
157.b17、根据b16所述的声学模型训练集的优化生成系统,所述第一分析单元还包括:
158.槽位填充子单元,用于根据所述机器语言以填充所述意图信息对应的意图槽位;
159.所述反馈生成子单元,还用于根据所述领域、所述意图信息以及所述意图槽位以匹配生成对应的反馈信息。
160.b18、根据b10所述的声学模型训练集的优化生成系统,所述第二分析单元包括:
161.音频特征分析子单元,用于分析所述意图信息对应的音频特征;
162.反馈音频生成子单元,用于将所述音频特征与所述反馈信息结合以生成对应的反馈音频。
163.还提供了c19、一种存储介质,用于存储一种用于执行a1~a9中任意一种所述声学模型训练集的优化生成方法的计算机程序。
164.还提供了d20、一种计算机设备,包括存储介质、处理器以及存储在所述存储介质上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现a1~a9任一项所述的声学模型训练集的优化生成方法。