1.本技术涉及计算领域,更具体地,涉及一种从多个说话者中分离目标语音的方法和装置、非易失性计算机可读介质以及计算机设备。
背景技术:
2.目标语音分离从观察到的语音混合中提取感兴趣的语音。随着深度学习时代的到来,现有的大多数监督方法都是基于声谱图掩码(spectrogram masking)的,其中估计目标说话者在混合声谱图的每个时频(t
‑
f)窗口(bin)处的权重(掩码)。结果,混合声谱图和预测掩码之间的乘积被用作目标语音声谱图。
技术实现要素:
3.本技术实施例提供一种从多个说话者中分离目标语音的方法和装置、非易失性计算机可读介质以及计算机设备,旨在解决现有的纯音频方法在复杂的声学环境中经常会受到严重干扰,从而导致声学目标信息模糊的问题。
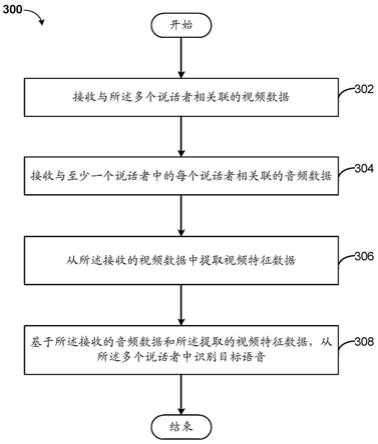
4.根据一个方面,提供一种从多个说话者中分离目标语音的方法,所述方法可以包括:接收与所述多个说话者相关联的视频数据;接收与至少一个说话者中的每个说话者相关联的音频数据;从所述接收的视频数据中提取视频特征数据;基于所述接收的音频数据和所述提取的视频特征数据从所述多个说话者中识别所述目标语音。
5.根据另一方面,提供一种从多个说话者中分离目标语音的装置,所述装置可以包括:第一接收模块,被配置为接收与所述多个说话者相关联的视频数据;第二接收模块,被配置为接收与至少一个说话者中的每个说话者相关联的音频数据;提取模块,被配置为从所述接收的视频数据中提取视频特征数据;识别模块,被配置为基于所述接收的音频数据和所述提取的视频特征数据从所述多个说话者中识别所述目标语音。
6.根据又一方面,提供一种非易失性计算机可读介质,其上存储计算机程序,当所述计算机程序被至少一个计算机处理器执行时,使得所述至少一个计算机处理器执行所述从多个说话者中分离目标语音的方法。
7.根据再一方面,提供一种计算机设备,包括至少一个处理器和至少一个存储器,所述至少一个存储器中存储有至少一条程序指令,所述至少一条程序指令由所述至少一个处理器加载并执行,以实现所述从多个说话者中分离目标语音的方法。
8.在本技术实施例中,利用多模态框架能够提取被噪声和混响损坏的同步视频和多通道音频中的目标说话者的语音,从而获得更完整、更稳健的目标声学表示。
附图说明
9.从下面结合附图对示例性实施例的详细描述中,本技术上述的和其它目的、特征和优点将变得显而易见。附图的各种特征未按比例绘制,因为图示是为了清楚起见,以便于本领域技术人员结合详细描述对本技术技术方案进行理解。在附图中:
10.图1示出了根据至少一个实施例的联网计算机环境;
11.图2是根据至少一个实施例的用于从多个说话者中分离目标语音的系统的框图;
12.图3是根据至少一个实施例的操作流程图,其示出了由程序执行的、从多个说话者中分离目标语音的操作;
13.图4是根据至少一个实施例的图1中所示的计算机和服务器的内部组件和外部组件的框图;
14.图5是根据至少一个实施例的包括图1所示的计算机系统的示例性云计算环境的框图;以及
15.图6是根据至少一个实施例的图5所示的示例性云计算环境的功能层的框图。
具体实施方式
16.本技术公开了所要求保护的结构和方法的具体实施例。然而,应当理解的是,所公开的实施例仅是可以以各种形式体现的所要求保护的结构和方法的示例。然而,这些结构和方法可以以许多不同的形式来体现,并且不应被解释为限于本技术所描述的示例性实施例。相反,提供这些示例性实施例是为了使本技术更加全面和完整,并且将范围完全传达给本领域技术人员。在说明书中,可以省略公知的特征和技术的细节,以避免不必要地混淆所呈现的实施例。
17.实施例总体上涉及计算领域,更具体地,涉及语音识别。以下描述的示例性实施例提供了一种装置(系统)、方法和计算机程序,以便从多个说话者中分离目标语音。因此,通过允许基于从数据中提取音频和视频特征而从包含多个说话者的语音的数据中分离出单个说话者的语音,一些实施例具有了改进计算领域的能力。
18.如前所述,目标语音分离从观察到的语音混合中提取感兴趣的语音。随着深度学习时代的到来,现有的大多数监督方法都是基于声谱图掩码的,其中估计目标说话者在混合声谱图的每个时频(t
‑
f)窗口处的权重(掩码)。结果,混合声谱图和预测掩码之间的乘积被用作目标语音声谱图。然而,这些方法仅使用音频信息(称为纯音频(audio
‑
only)方法),其在复杂的声学环境(例如噪声和混响)中经常会受到严重干扰。由于声学目标信息在具有挑战性的声学环境中可能是模糊的,所以其他模态可以提供互补且稳定的信息,以增加稳健性。因此,使用通用的多模态框架可能是有利的,该框架旨在提取被噪声和混响损坏的同步视频和多通道音频中的期望说话者的语音。
19.参考各个实施例的方法、装置(系统)和计算机可读介质的流程图和/或框图来描述各个方面。应当理解,流程图和/或框图中的每个框、以及流程图和/或框图中的框的组合可以由计算机可读程序指令来实现。
20.以下描述的示例性实施例提供了一种系统、方法和计算机程序,其从多通道语音混合、目标说话者的唇部运动和语音记录中提取并集成多模态分离提示,以提高性能。此外,为了有效地探索和利用模态之间的高度相关性,可以将基于因式分解注意力(factorized attention)的多模态融合方法用于目标语音分离。具体地,多流结构可以将多通道混合、从同步视频修剪出的嘴部图像、以及目标说话者的登记话语(enrollment utterance)作为输入,并且可以在抑制所有其他干扰信号的情况下提取目标语音。通过利用基于麦克风阵列的信号处理技术,音频流可以充分利用多通道语音信号的频谱和空间特
性,以获得更完整、更稳健的目标相关声学表示。视频流可以捕获嘴部运动的时空动态并产生唇部嵌入(lip embeddings)。说话者嵌入流可以将目标说话者的纯净参考音频映射到包含说话者特定信息的特征向量。基于因式分解注意力的聚合方法可以用于在嵌入级别融合多模态的高级语义信息。
21.现在参照图1,其是一种联网计算机环境的功能框图,示出了一种用于从多个说话者中分离目标语音的目标语音分离系统100(以下称为“系统”)。应当理解,图1仅提供了一种实施方式的图示,并不暗示对可以实现不同实施例的环境的任何限制。基于设计和实现要求,可以对所描述的环境进行各种修改。
22.系统100可以包括计算机102和服务器计算机114。计算机102可以经由通信网络110(以下称为“网络”)与服务器计算机114进行通信。计算机102可以包括处理器104和软件程序108,该软件程序108存储在数据存储设备106中,并且能够与用户接口并与服务器计算机114通信。如下面将参考图4所讨论的,计算机102可以分别包括内部组件800a和外部组件900a,服务器计算机114可以分别包括内部组件800b和外部组件900b。计算机102可以是,例如移动设备、电话、个人数字助理、上网本、膝上型计算机、平板计算机、台式计算机、或能够运行程序、访问网络、并访问数据库的任何类型的计算设备。
23.服务器计算机114还可以在云计算服务模型中运行,例如软件即服务(saas)、平台即服务(paas)或基础设施即服务(laas),如下文参照图5和图6所讨论的。服务器计算机114还可以位于云计算部署模型中,例如私有云、社区云、公共云或混合云。
24.用于从多个说话者中分离目标语音的服务器计算机114能够运行目标语音分离程序116(以下称为“程序”),该程序116可以与数据库112交互。下面参照图3更详细地解释目标语音分离程序方法。在一个实施例中,计算机102可以作为包括用户界面的输入设备运行,而程序116可以主要在服务器计算机114上运行。在一可选的实施例中,程序116可以主要在至少一个计算机102上运行,而服务器计算机114可以用于处理和存储程序116所使用的数据。应当注意,程序116可以是独立程序,或者可以集成到更大的目标语音分离程序中。
25.然而,应当注意,在某些情况下,可以在计算机102和服务器计算机114之间以任何比率共享程序116的处理。在另一实施例中,程序116可以在一个以上的计算机、服务器计算机、或计算机和服务器计算机的某种组合上运行,例如,通过网络110与单个服务器计算机114进行通信的多个计算机102。在另一实施例中,例如,程序116可以在通过网络110与多个客户端计算机通信的多个服务器计算机114上运行。可选地,程序可以在通过网络与服务器和多个客户端计算机通信的网络服务器上运行。
26.网络110可以包括有线连接、无线连接、光纤连接或其某种组合。通常,网络110可以是支持在计算机102与服务器计算机114之间进行通信的连接和协议的任何组合。网络110可以包括各种类型的网络,例如局域网(lan)、诸如因特网的广域网(wan)、诸如公共交换电话网(pstn)的电信网络、无线网络、公共交换网络、卫星网络、蜂窝网络(例如第五代(5g)网络、长期演进(lte)网络、第三代(3g)网络、码分多址(cdma)网络等)、公共陆地移动网络(plmn)、城域网(man)、专用网、自组织网络、内联网、基于光纤的网络等,以及/或这些或其它类型网络的组合。
27.图1所示的设备和网络的数量和布置是作为示例来提供的。实际上,与图1所示的设备和网络相比,可以有更多的设备和/或网络、更少的设备和/或网络、不同的设备和/或
网络,或布置不同的设备和/或网络。此外,图1所示的两个或更多个设备可以在单个设备中实现,或者图1所示的单个设备可以作为多个分布式设备实现。另外或可选地,系统100的一组设备(例如,至少一个设备)可以执行描述为由系统100的另一组设备执行的至少一个功能。
28.现在参考图2,其示出了多模态目标语音分离系统的框图200。多模态目标语音分离系统可以包括方向特征提取器202、唇部嵌入网络204、说话者嵌入网络206和多模态分离网络208。多模态语音分离系统可以接收视频数据210和音频数据212作为输入。多模态分离网络208可以输出目标语音数据214。
29.方向特征提取器202可以将噪声、多通道语音混合和目标说话者的方向作为输入,以便提取声学嵌入。短时傅立叶变换(stft)卷积1d层可用于将多通道混合波形映射到复杂频谱图(complex spectrogram)。基于该复杂频谱图,可以提取单通道频谱特征(即,对数功率谱(lps))和多通道空间特征(即,耳间相位差(ipd))。除了与目标说话者无关的频谱和空间特征外,可以根据目标说话者的空间方向提取方向特征。所有特征可以被级联并馈送到音频块中,音频块可以包括堆叠扩展卷积层,其具有指数增长的扩展因子(dilation factor)。音频块的输出可以包括至少一个声学嵌入。在系统输出端,istft卷积1d层可用于将估计的目标说话者复杂频谱图转换回波形。
30.唇部嵌入网络204可以从视频数据210中提取帧级别唇部嵌入。唇部嵌入网络204可以接收目标说话者的修剪后的嘴部图像作为输入。唇部嵌入网络204可以包括时空卷积层和18层的resnet。监督信息可以从音频域形成,其可以使用视频数据210来发现目标语音和唇部运动之间的至少一个跨域相关性。唇部嵌入网络204可以利用至少一个视频块,每个视频块可以包含具有残差连接的几个扩展的时间卷积层。视频块的输出可以包括至少一个唇部嵌入。由于视频流和音频流的分辨率可能不同,因此可以通过最近邻插值对唇部嵌入进行上采样以与音频流同步。
31.说话者嵌入网络206可以处理目标说话者的登记音频,例如音频数据212,并且可以生成话语级别说话者嵌入。说话者嵌入可以是偏置信号,该偏置信号可以通知多模态分离网络208执行和增强目标说话者的分离。可以引入预训练的说话者模型用其产生说话者嵌入,以表征目标说话者。可以使用至少一个卷积层(其后面是全连接层)在说话者验证任务上对说话者模型进行预训练。说话者模型的输入可以是目标说话者的登记话语,例如在参加电话会议时说出自己的名字。说话者嵌入网络206可以输出话语级别的说话者嵌入。
32.多模态分离网络208可以将声学、唇部和说话者嵌入组合起来并馈送到至少一个融合块中,该融合块可以为目标说话者输出t
‑
f掩码。t
‑
f掩码可用于估计目标语音波形。如上所述,可以从一组媒体源中导出三种目标信息,包括来自多通道语音的声学嵌入、来自视频的唇部嵌入和来自目标说话者的登记话语的说话者嵌入。为了从多模态信息中学习有效的目标语音提取,可以使用因式分解层来快速适应声学上下文。在语音识别中,一个因子可以是一组说话者或特定的声学环境。因式分解层可以使用一组不同的参数来处理每个声学类别,这可以取决于表示声学条件的外部因素。根据至少一个实施例,声学嵌入可以被因式分解为一组声学子空间(例如,电话子空间、说话者子空间),并且可以利用来自其他模态的信息选择性地聚合它们。其他模态也可以提供与声学条件相关的信息,例如根据嘴巴的张开和闭合所诠释的语音活动、以及包含在说话者嵌入中的目标说话者语音特征。具体地,可
以利用并行线性变换将声学嵌入a因式分解为不同的声学子空间,其中h可以是子空间的数量,并且在第t个时间步长的第h个子空间中的声学表示可以表示为其中p是线性变换的输出维度。唇部嵌入v也可以从d维空间映射到h维空间,其中每个维度h可以包含偏置信息,该偏置信息可以对应于第h个声学子空间。映射的唇部嵌入可以被传递到softmax层,并且可以在每个时间步长为每个子空间生成估计后验,计算如下:
33.v=softmax(vw
v
)=[v1,v2,...,v
h
]∈
□
t
×
h
。融合的视听嵌入(ave)可以通过对不同声学子空间的加权贡献求和来获得:
[0034][0035]
其中,σ可以是s形激活函数。声学嵌入和说话者嵌入可以类似地组合,并且可以计算如下:
[0036][0037]
其中ws可以是权重矩阵,该权重矩阵可以将说话者嵌入s从说话者空间转换为声学子空间。
[0038]
现在参考图3,其示出了一个操作流程图300,该操作流程图300示出了由程序执行的、从多个说话者中分离目标语音的操作。可以借助图1和图2来描述图3。如前所述,目标语音分离程序116(图1)可以快速、有效地利用音频和视频特征数据,以从多个其他说话者的语音中分离目标说话者的语音。
[0039]
在步骤302处,接收与所述多个说话者相关联的视频数据。可以理解,任何数量的说话者可以被任何数量的相机捕获。在实施例中,服务器计算机114上的目标语音分离程序116(图1)可以通过通信网络110(图1)从至少一个计算机102(图1)接收视频数据210(图2)。
[0040]
在步骤304处,接收与至少一个说话者中的每个说话者相关联的音频数据。该音频数据可以包括登记话语,例如说话者在参加电话会议时说出他们的名字。在实施例中,服务器计算机114上的目标语音分离程序116(图1)可以通过通信网络110(图1)从至少一个计算机102(图1)接收音频数据212(图2)。音频数据212可以被传递到说话者嵌入网络206(图2)。
[0041]
在步骤306处,从所述接收的视频数据中提取视频特征数据。该视频特征数据可以包括与捕获所述至少一个说话者的相机相关联的方向、以及与所述至少一个说话者中的每个说话者相关联的唇部运动图像数据。在实施例中,方向特征提取器202(图2)可以从视频数据210(图2)中提取方向数据。唇部嵌入网络204(图2)可以进一步从视频210中提取唇部运动数据。
[0042]
在步骤308处,基于所述接收的音频数据和所述提取的视频特征数据,从所述多个说话者中识别目标语音。在实施例中,多模态分离网络208(图2)可以从方向特征提取器202(图2)接收提取的方向数据,从唇部嵌入网络204(图2)接收提取的唇部运动数据,以及接收从说话者嵌入网络206(图2)的音频数据212(图2)提取的特征。多模态分离网络208可以分离目标说话者的语音,并且可以输出目标语音数据214(图2)。
[0043]
应当理解,图3仅提供了一种实施方式的图示,并不暗示关于如何实现不同实施例
的任何限制。基于设计和实现要求,可以对所描述的环境进行各种修改。
[0044]
图4是根据示例性实施例的图1中所描绘的计算机的内部组件和外部组件的框图400。应当理解,图4仅提供了一种实施方式的图示,并不暗示对可以实施不同实施例的环境的任何限制。基于设计和实现要求,可以对所描述的环境进行各种修改。
[0045]
计算机102(图1)和服务器计算机114(图1)可以包括图4所示的内部组件800a、800b和外部组件900a、900b的相应集合。每组内部组件800包括连接在至少一个总线826上的至少一个处理器820、至少一个计算机可读随机存取存储器(ram)822和至少一个计算机可读只读存储器(rom)824,包括至少一个操作系统828、以及至少一个计算机可读有形存储设备830。
[0046]
处理器820以硬件、固件或硬件与软件的组合来实现。处理器820是中央处理单元(cpu)、图形处理单元(gpu)、加速处理单元(apu)、微处理器、微控制器、数字信号处理器(dsp)、现场可编程门阵列(fpga)、专用集成电路(asic)或其它类型的处理组件。在一些实施方式中,处理器820包括至少一个能够被编程以执行功能的处理器。总线826包括允许在内部组件800a与800b之间进行通信的组件。
[0047]
至少一个操作系统828、以及服务器计算机114(图1)上的软件程序108(图1)和目标语音分离程序116(图1)都存储在至少一个相应的计算机可读有形存储设备830上,用于由至少一个相应的处理器820通过至少一个相应的ram 822(其通常包括高速缓冲存储器)执行。在图4所示的实施例中,每个计算机可读有形存储设备830是内部硬盘驱动器的磁盘存储设备。可选地,每个计算机可读有形存储设备830是半导体存储设备,例如rom 824、可擦可编程只读存储器(eprom)、快闪存储器、光盘、磁光盘、固态盘、光碟(cd)、数字通用光盘(dvd)、软盘、盒式磁带、磁带,和/或能够存储计算机程序和数字信息的其它类型的非易失性计算机可读有形存储设备。
[0048]
每组内部组件800a、800b还包括读写(r/w)驱动器或接口832,以便从至少一个便携式计算机可读有形存储设备936(例如cd
‑
rom、dvd、记忆棒、磁带、磁盘、光盘或半导体存储设备)读取或向其写入。诸如软件程序108(图1)和目标语音分离程序116(图1)的软件程序可以存储在至少一个相应的便携式计算机可读有形存储设备936上,经由相应的r/w驱动器或接口832读取并加载到相应的硬盘驱动器830中。
[0049]
每组内部组件800a、800b还包括网络适配器或接口836,例如tcp/ip适配器卡、无线wi
‑
fi接口卡、或3g、4g或5g无线接口卡或其它有线或无线通信链路。服务器计算机114(图1)上的软件程序108(图1)和目标语音分离程序116(图1)可经由网络(例如,因特网、局域网或其它网络、广域网)和相应的网络适配器或接口836从外部计算机下载到计算机102(图1)和服务器计算机114。从网络适配器或接口836,将服务器计算机114上的软件程序108和目标语音分离程序116加载到相应的硬盘驱动器830中。网络可以包括铜线、光纤、无线传输、路由器、防火墙、交换机、网关计算机和/或边缘服务器。
[0050]
每组外部组件900a、900b可以包括计算机显示器920、键盘930和计算机鼠标934。外部组件900a、900b还可以包括触摸屏、虚拟键盘、触摸板、定点设备和其它人机接口设备。每组内部组件800a、800b还包括设备驱动器840,以与计算机显示器920、键盘930和计算机鼠标934接口。设备驱动器840、r/w驱动器或接口832和网络适配器或接口836包括硬件和软件(存储在存储设备830和/或rom 824中)。
[0051]
应当理解的是,尽管本技术包括对云计算的详细描述,但是本文所列举的实施方式并不限于云计算环境。相反,某些实施例能够结合现在已知的或以后开发的任何其它类型的计算环境来实现。
[0052]
云计算是一种服务交付模型,用于实现对可配置计算资源(例如,网络、网络带宽、服务器、处理、内存、存储、应用程序、虚拟机和服务)共享池的方便、按需的网络访问,这些资源可以用最少的管理工作或与服务提供商的交互来快速配置和发布。云模型可以包括至少五个特征、至少三个服务模型和至少四个部署模型。
[0053]
特征如下:
[0054]
按需自助服务(on
‑
demand self
‑
service):云用户可以根据需要自动单方面提供计算功能,例如服务器时间和网络存储,而无需与服务提供商进行人工交互。
[0055]
广泛的网络接入(broad network access):功能可以通过网络获得,并通过标准机制进行访问,这些机制可以促进异构的瘦或胖客户端平台(例如,移动电话、笔记本电脑和个人数字助理)的使用。
[0056]
资源池(resource pooling):使用多租户模型(multi
‑
tenant model)将提供商的计算资源汇集起来以服务多个用户,并根据需求动态地分配和重新分配不同的物理和虚拟资源。位置独立的意义在于,用户通常对所提供的资源的确切位置没有控制权或知识,但能够在更高的抽象级别(例如,国家、州或数据中心)上指定位置。
[0057]
快速弹性(rapid elasticity):可以快速且弹性地进行配置的功能,在某些情况下可以自动配置以快速向外扩展,并快速释放以快速向内扩展。对于用户来说,可用于配置的功能通常看起来是无限的,并且可以在任何时间以任何数量购买。
[0058]
可计量的服务(measured service):云系统通过在适于服务类型(例如,存储、处理、带宽和活跃用户帐户)的某种抽象级别上利用计量功能,自动控制和优化资源使用。可以监视、控制和报告资源使用情况,从而为所使用服务的提供商和用户提供透明度。
[0059]
服务模型如下:
[0060]
软件即服务(saas):向用户提供的功能是使用在云基础设施上运行的提供商的应用程序。可以通过诸如网页浏览器(例如,基于网页的电子邮件)的瘦客户端接口从各种客户端设备访问应用程序。用户不管理或控制包括网络、服务器、操作系统、存储或甚至单个应用程序功能在内的底层云基础设施,但可能会限制用户特定的应用程序配置设置。
[0061]
平台即服务(paas):提供给用户的功能是将用户创建或获取的应用程序部署到云基础设施上,该用户创建或获取的应用程序是使用提供商支持的编程语言和工具创建的。用户不管理或控制包括网络、服务器、操作系统或存储在内的底层云基础设施,而是控制所部署的应用程序和可能的应用程序托管环境配置。
[0062]
基础设施即服务(laas):向用户提供的功能是提供处理、存储、网络和其他基本计算资源,其中用户能够部署和运行包括操作系统和应用程序在内的任意软件。用户不管理或控制底层云基础设施,而是控制操作系统、存储、部署的应用程序、以及可能对选择的网络组件(例如,主机防火墙)进行有限的控制。
[0063]
部署模型如下:
[0064]
私有云(private cloud):云基础设施仅为组织运行。它可以由组织或第三方来管理,并且可以存在于内部或外部。
[0065]
社区云(community cloud):云基础设施由多个组织共享,并且支持具有共享关注点(例如,任务、安全要求、策略和服从性考虑)的特定社区。它可以由组织或第三方管理,并且可以存在于内部或外部。
[0066]
公共云(public cloud):云基础设施可供一般公众或大型工业集团使用,并由出售云服务的组织所拥有。
[0067]
混合云(hybrid cloud):云基础设施是由两个或更多个云(私有、社区或公共)组成的,这些云保持唯一的实体,但是通过标准化或专有技术绑定在一起,从而实现数据和应用程序的可移植性(例如,用于在云之间进行负载平衡的云爆发)。
[0068]
云计算环境是面向服务的,着重于无状态、低耦合、模块化和语义互操作性。云计算的核心是包括互连节点的网络的基础设施。
[0069]
参照图5,其示出了示例性的云计算环境500。如图所示,云计算环境500包括至少一个云计算节点10,云用户所使用的本地计算设备(例如个人数字助理(pda)或蜂窝电话54a、台式计算机54b、膝上型计算机54c和/或汽车计算机系统54n)可以与这些云计算节点10通信。云计算节点10之间可以彼此通信。可以在至少一个网络中,例如上文所述的私有云、社区云、公共云、混合云、或其组合中,对它们进行物理或虚拟分组(未示出)。这允许云计算环境500提供基础设施、平台和/或软件作为服务,而云用户不需要在本地计算设备上为这些服务维护资源。应当理解,图5所示的计算设备54a
‑
n的类型仅是示例性的,并且云计算节点10和云计算环境500可以通过任何类型的网络和/或网络可寻址连接(例如,使用网页浏览器)与任何类型的计算机设备通信。
[0070]
参照图6,其示出了由云计算环境500(图5)提供的一组功能抽象层600。应当理解的是,图6所示的组件、层和功能仅是示例性的,并且实施例不限于此。如图所示,提供了以下层和相应功能:
[0071]
硬件和软件层60包括硬件和软件组件。硬件组件的示例包括:主机61、基于risc(精简指令集计算机,reduced instruction set computer)架构的服务器62、服务器63、刀锋服务器(blade server)64、存储设备65、以及网络和网络组件66。在一些实施例中,软件组件包括网络应用服务器软件67和数据库软件68。
[0072]
虚拟层70提供抽象层,从该抽象层可以提供以下虚拟实体的示例:虚拟服务器71、虚拟存储器72、包括虚拟专用网络的虚拟网络73、虚拟应用程序和操作系统74、以及虚拟客户端75。
[0073]
在一个示例中,管理层80可以提供下述功能。资源供应81提供用于在云计算环境中执行任务的计算资源和其它资源的动态采购。当在云计算环境中利用资源时,计量和定价82提供成本跟踪,并为这些资源的消耗开具帐单或发票。在一个示例中,这些资源可包括应用软件许可证。安全性为云用户和任务提供身份验证,并为数据和其他资源提供保护。用户入口83为用户和系统管理员提供对云计算环境的访问。服务级别管理84提供云计算资源的分配和管理,从而满足所需的服务级别。服务水平协议(sla,service level agreement)计划和实现85为根据sla预期的未来需求的云计算资源提供预先安排和获取。
[0074]
工作负载层90提供可以利用云计算环境的功能的示例。可以从该层提供的工作负载和功能的示例包括:映射和导航91、软件开发和生命周期管理92、虚拟课堂教学实施93、数据分析处理94、交易处理95、以及目标语音分离96。目标语音分离96可以从多个说话者中
分离目标语音。
[0075]
本技术实施例还提供了一种从多个说话者中分离目标语音的装置。该装置包括:第一接收模块,被配置为接收与所述多个说话者相关联的视频数据;第二接收模块,被配置为接收与至少一个说话者中的每个说话者相关联的音频数据;提取模块,被配置为从所述接收的视频数据中提取视频特征数据;识别模块,被配置为基于所述接收的音频数据和所述提取的视频特征数据从所述多个说话者中识别所述目标语音。
[0076]
本技术实施例还提供了一种计算机设备,所述设备包括至少一个处理器和至少一个存储器,所述至少一个存储器中存储有至少一条程序指令,所述至少一条程序指令由所述至少一个处理器加载并执行以实现如上所述的从多个说话者中分离目标语音的方法。
[0077]
一些实施例可以涉及处于任何可能的技术细节集成水平的系统、方法和/或计算机可读介质。在本技术实施例,计算机可读介质可以包括非易失性计算机可读存储介质(或媒介),其上存储有使处理器执行操作的计算机可读程序指令。当所述程序指令被至少一个处理器执行时,使得所述至少一个处理器执行如上所述的目标语音分离的方法。
[0078]
计算机可读存储介质可以是有形设备,其可以保留和存储指令以供指令执行设备使用。计算机可读存储介质可以是,例如,但不限于,电子存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或前述的任任意适当组合。计算机可读存储介质的更具体示例的非详尽列表包括以下:便携式计算机磁盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦除可编程只读存储器(eprom或快闪存储器)、静态随机存取存储器(sram)、便携式光盘只读存储器(cd
‑
rom)、数字通用光盘(dvd)、记忆棒、软盘、机械编码装置(如其上记录有指令的穿孔卡(punch
‑
card)或槽内凸起的结构)、以及上述的任意适当组合。本文所使用的计算机可读存储介质不应被解释为本身是易失信号,例如无线电波或其他自由传播的电磁波、通过波导或其他传输介质传播的电磁波(例如,通过光纤电缆的光脉冲)、或通过电线传输的电信号。
[0079]
本文所述的计算机可读程序指令可以从计算机可读存储介质下载到相应的计算/处理设备,或者通过网络(例如,因特网、局域网、广域网和/或无线网络)下载到外部计算机或外部存储设备。所述网络可以包括铜传输电缆、光传输光纤、无线传输、路由器、防火墙、交换机、网关计算机和/或边缘服务器。每个计算/处理设备中的网络适配器卡或网络接口从网络接收计算机可读程序指令,并转发所述计算机可读程序指令,以将其存储在相应计算/处理设备内的计算机可读存储介质中。
[0080]
用于执行操作的计算机可读程序代码/指令可以是汇编指令、指令集架构(isa,instruction
‑
set
‑
architecture)指令、机器指令、机器相关指令、微代码、固件指令、状态设置数据、用于集成电路的配置数据、或者以一种或多种编程语言的任意组合编写的源代码或目标代码,所述编程语言包括诸如smalltalk、c++等的面向对象的编程语言、以及程序化程序语言(例如“c”编程语言)或类似的编程语言。计算机可读程序指令可以完全在用户的计算机上执行,部分在用户的计算机上执行,作为独立的软件包执行,部分在用户的计算机上执行而部分在远程计算机上执行,或者完全在远程计算机或服务器上执行。在后一种情况下,远程计算机可以通过任何类型的网络(包括局域网(lan)或广域网(wan))连接到用户的计算机上,或者可以连接到外部计算机(例如,通过使用互联网服务提供商的互联网)。在一些实施例中,包括例如可编程逻辑电路、现场可编程门阵列(fpga)或可编程逻辑阵列
(pla)的电子电路可以通过利用计算机可读程序指令的状态信息来执行计算机可读程序指令,以使得电子电路个性化,从而执行方面或操作。
[0081]
可以将这些计算机程序指令提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器,以产生机器,使得该指令经由计算机或其他可编程数据处理装置的处理器执行,以创建用于实现流程图和/或框图中的至少一个框指定的功能/动作的装置。这些计算机可读程序指令还可以存储在计算机可读存储介质中,所述计算机可读存储介质可以指导计算机、可编程数据处理装置和/或其他设备以特定方式运行,从而使得其中存储有指令的计算机可读存储介质包含制品,所述制品包括实现流程图和/或框图中的至少一个框指定的功能/动作的各方面的指令。
[0082]
计算机可读程序指令也可以加载到计算机、其他可编程数据处理装置或其他设备上,以使得在计算机、其他可编程装置或其他设备上执行一系列操作步骤,从而产生计算机实现的过程,使得在计算机、其他可编程装置或其他设备上执行的指令实现流程图和/或框图的至少一个框指定的功能/动作。
[0083]
附图中的流程图和框图示出了根据各种实施例的系统、方法和计算机可读介质的可能的实实施方式的架构、功能和操作。就这一点而言,流程图或框图中的每个框可以表示指令的模块、片段或部分,其包括用于实现指定逻辑功能的至少一个可执行指令。相比于图中所描绘的,所述方法、计算机系统和计算机可读介质可以包括更多的块、更少的块、不同的块或不同布置的块。在一些可选实施方式中,框中标注的功能可以不按附图中标注的顺序发生。例如,取决于所涉及的功能,连续示出的两个框实际上可以同时或基本上同时执行,或者所述框有时可以以相反的顺序执行。还应注意的是,框图和/或流程图的每个框以及框图和/或流程图的框的组合可以由执行指定功能或动作的或者执行专用硬件和计算机指令的组合的基于专用硬件的系统来实施。
[0084]
很明显,本文所述的系统和/或方法可以以不同形式的硬件、固件或硬件和软件的组合来实现。用于实现这些系统和/或方法的实际专用控制硬件或软件代码并不受这些实施方式的限制。因此,本文描述了这些系统和/或方法的操作和行为而没有参考具体的软件代码——应当理解,可以基于本文的描述来设计软件和硬件以实现这些系统和/或方法。
[0085]
除非明确说明,否则本文中使用的元件、动作或指令均不得解释为关键或必要的。另外,如本文所使用的,冠词“一(a)”和“一个(an)”旨在包括至少一个项,并且可以与“至少一个”互换使用。此外,如本文所使用的,术语“集合”旨在包括至少一个项(例如,相关项、不相关项、相关项和不相关项的组合等),并且可以与“至少一个”互换使用。在仅希望一个项的情况下,则使用术语“一个”或类似语言。另外,如本文所使用的,术语“具有(has)”,“具有(have)”,“具有(having)”等旨在是开放式术语。进一步,短语“基于”旨在表示“至少部分地基于”,除非另外明确说明。
[0086]
已经出于说明的目的给出了各个方面和实施例的描述,但是并不旨在穷举或限于所公开的实施例。即使权利要求中叙述了特征的组合和/或说明书中公开了特征的组合,这些组合也不旨在限制可能的实施方式的公开。实际上,这些特征中的许多特征可以以权利要求中未具体描述和/或说明书中未公开的方式组合。虽然下文列出的每个从属权利要求可以直接从属于仅一个权利要求,但是可能的实施方式的公开包括每个从属权利要求与权利要求集中的每个其他权利要求的组合。在不脱离所描述的实施例的范围的情况下,许多
修改和变化对于本领域普通技术人员来说将是显而易见的。选择本文使用的术语是为了最好地解释本技术实施例的原理、对市场上发现的技术的实际应用或技术改进,或使本领域其他普通技术人员能够理解本文公开的实施例。