1.本发明涉及语音识别技术领域,具体涉及基于音频增强的语音识别方法及装置。
背景技术:
2.相对于单个麦克风,麦克风阵列具有更高的增益、波束灵活性、抗干扰能力强等优点,例如,在对远距离语音信号进行拾音时,由于麦克风阵列的高增益特性,更有利于获取远场环境下的弱语音信号。此外,麦克风阵列本身具有空域滤波特性,可以灵活抑制不同方向上的干扰,而且在盲源分离和声源定位等领域也应用广泛。
3.由于音频数据中存在的各种噪声,不同程度地影响着语音通话和人机交互的质量,由于应用场景的复杂性和噪声的多样性,现有的算法在某些特定场景下仍不能达到理想的效果,因此研制鲁棒性强的麦克风阵列语音增强算法显得尤为重要。
技术实现要素:
4.针对上述现有技术存在的问题,本发明提供了一种基于音频增强的语音识别方法,包括:
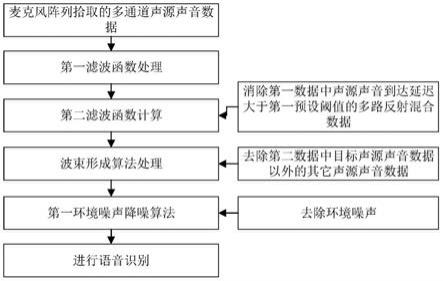
5.将麦克风阵列拾取的多通道声源声音数据经过第一滤波函数计算获得第一数据,该第一滤波函数具有能够满足输出信号与第一期望信号的均方误差最小的滤波参数;
6.将第一数据经过第二滤波函数计算以消除第一数据中声源声音到达延迟大于第一预设阈值的多路反射混合数据,获得第二数据,该第二滤波函数具有能够使输出信号的第二期望信号的时域相关性最小的滤波参数;
7.将第二数据通过波束形成算法处理得到单通道音频信号;
8.将单通道音频信号经过基于第一环境噪声降噪算法进行处理以去除其中的环境噪声,获得第三数据;
9.将第三数据通过语音识别模型进行识别。
10.优选的,所述第一环境噪声降噪算法,包括:
11.将单通道音频信号输入第一深度学习网络模型获得单通道音频信号中环境噪声的音频特征;
12.基于单通道音频信号和所述音频特征获得单通道音频信号中干净语音数据。
13.优选的,所述第一深度学习网络模型包括多个lstm网络模型,第1到n个 lstm网络模型的第a层输出共同连接到第n个lstm网络模型的第a+1层的输入。
14.优选的,所述第二滤波函数的获取方法包括:
15.基于当前时刻前的所有时刻的第一数据中声源声音到达延迟大于第一预设阈值的多路反射混合数据进行线性组合获取当前时刻的第一数据中声源声音到达延迟大于第一预设阈值的多路反射混合数据的估计值;
16.采用加权最小二乘算法获取该线性组合的系数矩阵以使估计值满足输出信号的第二期望信号的时域相关性最小,即:
[0017][0018]
其中,为第二期望信号的估计值,
[0019]
加权最小二乘算法的权重估计值为:
[0020]020]
为第二期望信号的功率谱密度估计值,m 为麦克风阵列中麦克风的个数,ε是一个常数;
[0021]
线性组合的系数矩阵的估计值为:
[0022]
其中
[0023]
为第一数据中声源声音到达延迟大于第一预设阈值的多路反射混合数据的自相关矩阵的逆矩阵。
[0024]
优选的,所述第二期望信号的功率谱密度估计值采用基于第二深度学习网络的功率谱密度估计模型获取,该第二深度学习网络在训练时以第一数据的功率谱密度为输入,学习第一数据的功率谱密度到第二期望信号功率谱密度的映射关系以输出第二期望信号功率谱密度的估计值。
[0025]
优选的,所述第二深度学习网络采用lstm网络,所述lstm网络的每个cell 的输出数据经过投影处理输入到下一cell的输入。
[0026]
本发明还提供了一种基于音频增强的语音识别装置,包括:
[0027]
第一数据生成模块,用于将麦克风阵列拾取的多通道声源声音数据经过第一滤波函数计算获得第一数据,该第一滤波函数具有能够满足输出信号与第一期望信号的均方误差最小的滤波参数;
[0028]
第二数据生成模块,用于将第一数据经过第二滤波函数计算以消除第一数据中声源声音到达延迟大于第一预设阈值的多路反射混合数据,获得第二数据,该第二滤波函数具有能够使输出信号的第二期望信号的时域相关性最小的滤波参数;
[0029]
单通道音频信号生成模块,用于将第二数据通过波束形成算法处理得到单通道音频信号;
[0030]
第三数据生成模块,用于将单通道音频信号经过基于第一环境噪声降噪算法进行处理以去除其中的环境噪声,获得第三数据;
[0031]
语音识别模块,用于将第三数据通过语音识别模型进行识别。
[0032]
作为上述方案的进一步优化,所述第二数据生成模块包括第二滤波函数单元,所述第二滤波函数基于当前时刻前的所有时刻的第一数据中声源声音到达延迟大于第一预设阈值的多路反射混合数据进行线性组合获取当前时刻的第一数据中声源声音到达延迟大于第一预设阈值的多路反射混合数据的估计值,并采用加权最小二乘算法获取该线性组合的系数矩阵以使估计值满足输出信号的第二期望信号的时域相关性最小。
[0033]
本发明还提供了一种电子设备,所述电子设备包括:
[0034]
存储器,用于存储可执行指令;
[0035]
处理器,用于运行所述存储器存储的可执行指令时,实现上述的一种基于音频增强的语音识别方法。
[0036]
一种计算机可读存储介质,存储有可执行指令,所述可执行指令被处理器执行时实现上述的一种基于音频增强的语音识别方法。
[0037]
本发明的一种基于音频增强的语音识别方法及装置,具备如下有益效果:
[0038]
1、将麦克风阵列拾取的多通道语音数据先消除由于声源声音遇到不同障碍物反射和吸收造成的与直达麦克风的声音数据具有不同延时的多路反射混合语音数据,然后去除第二数据中目标声源声音数据以外的其它声源声音数据,最后去除环境噪声,实现对声源声音数据的增强处理,提高语音识别的准确性。
[0039]
2、第一深度学习网络模型中的多个lstm网络模型连接结构,采用第1到n 个lstm网络模型的第a层输出共同连接到第n个lstm网络模型的第a+1层的输入,实现第n个lstm网络模型的第a+1层基于第1到n
‑
1个lstm网络模型的提供的先验知识进行学习,能够获得更准确的学习方向,有效缩短神经网络训练时间,提高第一深度学习网络模型提取干净语音的第一类型音频特征的准确性。
附图说明
[0040]
图1是本发明一种基于音频增强的语音识别方法的整体流程图;
[0041]
图2是本发明一种基于音频增强的语音识别装置的结构框图。
具体实施方式
[0042]
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述,所描述的实施例不应视为对本发明的限制,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0043]
本实施例提供的一种基于音频增强的语音识别方法,包括如下步骤:
[0044]
将麦克风阵列拾取的多通道声源声音数据经过第一滤波函数计算获得第一数据,该第一滤波函数具有能够满足输出信号与第一期望信号的均方误差最小的滤波参数;
[0045]
将第一数据经过第二滤波函数计算以消除第一数据中声源声音到达延迟大于第一预设阈值的多路反射混合数据,获得第二数据,该第二滤波函数具有能够使输出信号的第二期望信号的时域相关性最小的滤波参数;
[0046]
将第二数据通过波束形成算法处理得到单通道音频信号;
[0047]
将单通道音频信号经过基于第一环境噪声降噪算法进行处理以去除其中的环境噪声,获得第三数据;
[0048]
将第三数据通过语音识别模型进行识别。
[0049]
本实施例中,将麦克风阵列拾取的多通道语音数据先消除由于声源声音遇到不同障碍物反射和吸收造成的与直达麦克风的声音数据具有不同延时的多路反射混合语音数据,然后去除第二数据中目标声源声音数据以外的其它声源声音数据,最后去除环境噪声,实现对声源声音数据的增强处理,提高语音识别的准确性。
[0050]
其中,第一环境噪声降噪算法,包括:
[0051]
第一步,将单通道音频信号输入第一深度学习网络模型获得单通道音频信号中环境噪声的音频特征;
[0052]
第二步,基于单通道音频信号和所述音频特征获得单通道音频信号中干净语音数据。
[0053]
其中,第一步中,第一深度学习网络模型采用多个lstm网络模型组成,第一深度学习网络模型的输入为单通道音频信号,每个lstm网络模型用于基于单通道音频信号的第一类型音频特征输出不同信噪比条件下的干净语音的第一类型音频特征,
[0054]
第二步中,基于不同信噪比条件下的干净语音的第一类型音频特征,经过均值计算将多个第一类型音频特征进行融合获得第一类型融合音频特征,基于该融合音频特征进行得到频谱重构,进而得到重构的语音数据。
[0055]
上述音频特征的类型可以为对数功率谱或者干净语音和带噪语音的功率谱掩蔽特征等。
[0056]
上述第一深度学习网络模型包括多个lstm网络模型,第1到n个lstm网络模型的第a层输出共同连接到第n个lstm网络模型的第a+1层的输入。
[0057]
采用这种连接结构,第n个lstm网络模型的第a+1层基于第1到n
‑
1个lstm 网络模型的提供的先验知识进行学习,能够获得更准确的学习方向,有效缩短神经网络训练时间,提高第一深度学习网络模型提取干净语音的第一类型音频特征的准确性。
[0058]
在训练时,按照不同信噪比将干净语音数据和噪声数据混合作为训练数据,将训练数据的第一类型音频特征输入lstm网络模型进行单个模型的训练,每个 lstm网络模型训练完成开始下一个lstm网络模型的训练过程。
[0059]
其中,第二滤波函数的获取方法包括:
[0060]
基于当前时刻前的所有时刻的第一数据中声源声音到达延迟大于第一预设阈值的多路反射混合数据进行线性组合获取当前时刻的第一数据中声源声音到达延迟大于第一预设阈值的多路反射混合数据的估计值;
[0061]
采用加权最小二乘算法获取该线性组合的系数矩阵以使估计值满足输出信号的第二期望信号的时域相关性最小,即:
[0062][0063]
其中,为第二期望信号的估计值,
[0064]
加权最小二乘算法的权重估计值为:
[0065][0065]
为第二期望信号的功率谱密度估计值,m 为麦克风阵列中麦克风的个数,ε是一个常数;
[0066]
线性组合的系数矩阵的估计值为:
[0067]
其中
[0068]
为第一数据中声源声音到达延迟大于第一预设阈值的多路反射混合数据的自相关矩阵的逆矩阵。
[0069]
其中,x(n)为当前时刻的第一数据,为当前时刻前的所有时刻的第一数据中声源声音到达延迟大于第一预设阈值的多路反射混合数据。
[0070]
上述获取第二滤波函数过程中的第二期望信号的功率谱密度估计值采用基于第二深度学习网络的功率谱密度估计模型获取,该第二深度学习网络在训练时以第一数据的功率谱密度为输入,学习第一数据的功率谱密度到第二期望信号功率谱密度的映射关系以输出第二期望信号功率谱密度的估计值,该第二深度学习网络采用lstm网络,所述lstm网络的每个cell的输出数据经过投影处理输入到下一cell的输入。
[0071]
具体的,每个单元基于输入数据x
t
,在遗忘门选择丢弃部分数据f
t
,在输入门基于上一cell的输出h
t
‑1和当前输入数据x
t
进行更新cell的状态c
t
,在输出门基于输出门输出o
t
和更新的细胞状态c
t
得到输出数据m
t
,基于输出数据进行投影处理即:经过循环单元进行处理m
t
*w1得到r
t
以及经过非循环单元处理 m
t
*w2得到p
t
,继而输入到下一cell的数据为:w3*r
t
+w4*p
t
+b,其中w1、w2、 w3、w4为权重参数,b参数是偏置参数,经过该cell之间的输入输出关系有效降低模型的复杂度,减少训练时间。
[0072]
本实施例还提供了一种基于音频增强的语音识别装置,包括:
[0073]
第一数据生成模块,用于将麦克风阵列拾取的多通道声源声音数据经过第一滤波函数计算获得第一数据,该第一滤波函数具有能够满足输出信号与第一期望信号的均方误差最小的滤波参数;
[0074]
第二数据生成模块,用于将第一数据经过第二滤波函数计算以消除第一数据中声源声音到达延迟大于第一预设阈值的多路反射混合数据,获得第二数据,该第二滤波函数具有能够使输出信号的第二期望信号的时域相关性最小的滤波参数;
[0075]
单通道音频信号生成模块,用于将第二数据通过波束形成算法处理得到单通道音频信号;
[0076]
第三数据生成模块,用于将单通道音频信号经过基于第一环境噪声降噪算法进行处理以去除其中的环境噪声,获得第三数据;
[0077]
语音识别模块,用于将第三数据通过语音识别模型进行识别。
[0078]
上述第二数据生成模块包括第二滤波函数单元,所述第二滤波函数基于当前时刻前的所有时刻的第一数据中声源声音到达延迟大于第一预设阈值的多路反射混合数据进行线性组合获取当前时刻的第一数据中声源声音到达延迟大于第一预设阈值的多路反射混合数据的估计值,并采用加权最小二乘算法获取该线性组合的系数矩阵以使估计值满足输出信号的第二期望信号的时域相关性最小。
[0079]
关于语音识别装置的具体限定可以参见上文中对于语音识别方法的限定,在此不再赘述。上述语音识别装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
[0080]
本实施例还提供了一种电子设备,所述电子设备包括:
[0081]
存储器,用于存储可执行指令;
[0082]
处理器,用于运行所述存储器存储的可执行指令时,实现上述的一种基于音频增强的语音识别方法。
[0083]
本实施例还提供了一种计算机可读存储介质,存储有可执行指令,所述可执行指令被处理器执行时实现上述的一种基于音频增强的语音识别方法。
[0084]
上述电子设备包括:至少一个处理器、存储器、用户接口和至少一个网络接口。电子设备中的各个组件通过总线系统耦合在一起。可以理解,总线系统用于实现这些组件之间的连接通信。总线系统除包括数据总线之外,还包括电源总线、控制总线和状态信号总线。其中,用户接口可以包括显示器、键盘、鼠标、轨迹球、点击轮、按键、按钮、触感板或者触摸屏等。该电子设备的处理器用于提供计算和控制能力,电子设备的存储器可以是易失性存储器或非易失性存储器,也可包括易失性和非易失性存储器两者,本实施例中的存储器存储有操作系统、计算机程序和数据库,该计算机程序被处理器执行时以实现上述一种基于音频增强的语音识别方法。
[0085]
本发明不局限于上述具体的实施方式,本领域的普通技术人员从上述构思出发,不经过创造性的劳动,所做出的种种变换,均落在本发明的保护范围之内。