1.本发明属于语音处理技术领域。涉及一种语音特征融合的说话人识别方法。
背景技术:
2.语音特征的提取和融合技术可广泛用于语音识别和说话人识别等领域。语音信号主要有两大类时域特征和频域特征。时域特征是指在时域,直接从语音信号中提取语音特征,如短时能量、短时振幅、短时过零率、短时自相关、线性预测编码(linear predictive codings,lpcs)等。频域特征是指通过傅里叶变换将语音信号从时域转换到频域,在频域提取语音信号的特征,如梅尔频率倒谱系数(mel
‑
frequency cepstral coefficients,mfccs)、对数振幅谱(log
‑
magnitude spectral feature,log
‑
mag)、感知线性预测(perceptual linear prediction,plp)等。语音特征的融合是指将不同类型的语音信号的特征按一定的方法组合构成一个新的特征集,也就是融合特征,利用语音信号的融合特征可以提高说话人识别系统的性能。目前,语音信号特征的融合方法通常是将提取出的不同的语音特征直接级联构成语音的融合特征,不同类特征之间具有互补性,但是,同类特征之间具有一定的相关性,会降低说话人识别系统的性能。
技术实现要素:
3.本发明的目的在于提供一种基于独立向量分析的语音特征融合的说话人识别方法,以解决上述背景技术中提出的问题。
4.该方法利用汉明窗将语音信号分成多个相互重叠的帧,假设帧的个数为t,从这些语音帧中,提取语音的不同种类的特征,即时域特征(lpcs)和频域特征(mfccs)。将语音信号的时域特征或频域特征分别看作是由多个未知独立变量和未知的混合系统的线性混合,可表示为:
5.x
[k]
(t)=a
[k]
s
[k]
(t)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0006]
上式中,为第t帧、第k类的特征向量,k∈{1,...,k},k为不同类语音特征的个数;t∈{1,...,t};为未知的混合矩阵,即混合系统。为未知第t帧、第k类语音信号的未知的独立向量,也可以看作独立的源信号。上标t表示转置。将提取的所有帧的同一类型的特征向量构成特征矩阵,即再将这些不同类特征矩阵构成一个特征张量,即采用独立向量分析提取独立向量作为融合特征,同时得到解混张量作为说话人的模型。具体过程如下。
[0007]
①
将说话人的语音信号分帧,提取每一帧的时域特征向量和频域特征向量,将提取出的特征向量分别构成k个特征矩阵,即其中,x
[k]
(t)表示第k个特征类型的第t帧的特征向量,n表示特征的维数,t表示语音帧的个数。
[0008]
②
将k个矩阵x
[k]
并联成一个张量是一种没有使用独立向量分析的融合特征,为了和提出的融合特征相区别,被记为特征张量。对特征张量采用独立向量分析提取独立向量,即
[0009][0010]
上式中,为融合特征,其中,为独立向量的估计。是由k个解混矩阵w
[k]
并联构成的解混张量。由于对每个说话人是不同的,可以看作说话人模型。
[0011]
③
利用优化函数来估计独立向量和解混张量,即:
[0012][0013]
上式中,h[
·
]表示信息熵,det(
·
)表示行列式,为独立向量的估计,n∈{1,...,n},c=h[x
[1]
(t),...,x
[k]
(t)]是一个常数。
[0014]
采用牛顿算法同时更新k个解混矩阵的第n行采用牛顿算法同时更新k个解混矩阵的第n行表示第k个解混矩阵的第n行,n∈{1,...,n},即
[0015][0016]
其中,μ为学习率。表示损失函数对w
n
的导数。为hessian矩阵。
[0017]
本发明的有益效果是:
[0018]
本发明采用独立向量分析将语音信号的时域特征和频域特征融合,构成一个新的语音信号的融合特征和说话人的模型,增强不同类特征之间的相关性,同时减小同类特征之间的冗余性,提高说话人识别系统的性能。
附图说明
[0019]
图1为使用了此发明的说话人识别系统。
具体实施方式
[0020]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步的详细说明。此处所描述的具体实施例仅用于解释本发明技术方案,并不限于本发明。
[0021]
如图1所示,本发明提出了一种基于独立向量分析的语音特征融合的说话人识别方法。首先,利用汉明窗将说话人的语音划分成相互重叠的帧。提取每一帧的时域特征(如
lpcs)和频域特征(如mfccs)。其次,将提取出的时域特征和频域特征分别构成时域特征矩阵和频域特征矩阵。将时域特征矩阵和频域特征矩阵构成一个特征张量。最后,对特征张量做独立向量分析,得到融合特征,同时得到解混张量作为说话人模型。依次进行上述三个步骤可以得到融合特征。
[0022]
本发明将通过以下实施步骤例作进一步说明。
[0023]
①
用汉明窗将说话人的语音划分成相互重叠的帧,从每一帧中提取lpcs及其一阶导数和二阶导数、mfccs及其一阶导数和二阶导数。lpcs及其一阶导数和二阶导数构成时域特征向量,mfccs及其一阶导数和二阶导数构成频域特征向量。两个特征向量分别构成lpcs特征矩阵和mfccs特征矩阵x
[1]
(t)表示由lpcs及其一阶导数和二阶导数级联成的特征向量,x
[2]
(t)表示mfccs及其一阶导数和二阶导数级联成的特征向量,n表示特征的维数,t表示语音帧的个数。
[0024]
②
将x
[1]
和x
[2]
并联成一个张量是一种没有使用独立向量分析的融合特征,为了和提出的融合特征相区别,被记为特征张量。对特征张量使用独立向量分析提取独立向量,即
[0025][0026]
其中,表示融合特征,其中为独立向量的估计。其中为独立向量的估计。是由两个解混矩阵并联构成的解混张量。由于对每个说话人是不同的,可以看作说话人模型。
[0027]
利用优化函数来估计独立向量和解混张量,即:
[0028][0029]
其中,h[
·
]表示信息熵,det(
·
)表示行列式,为独立向量的估计,n∈{1,...,n},c=h[x
[1]
(t),x
[2]
(t)]是一个常数。
[0030]
③
采用牛顿算法同时更新两个解混矩阵的第n行采用牛顿算法同时更新两个解混矩阵的第n行表示第一个解混矩阵的第n行,表示第二个解混矩阵的第n行,n∈{1,...,n},即
[0031][0032]
其中,μ为学习率。表示损失函数对w
n
的导数,即
[0033]
[0034]
表示hessian矩阵。
[0035]
④
用式7)更新,得解混张量即说话人模型。使用式5)得到融合特征
[0036]
⑤
将融合特征输入到卷积神经网络识别此语音对应的说话人的身份。
[0037]
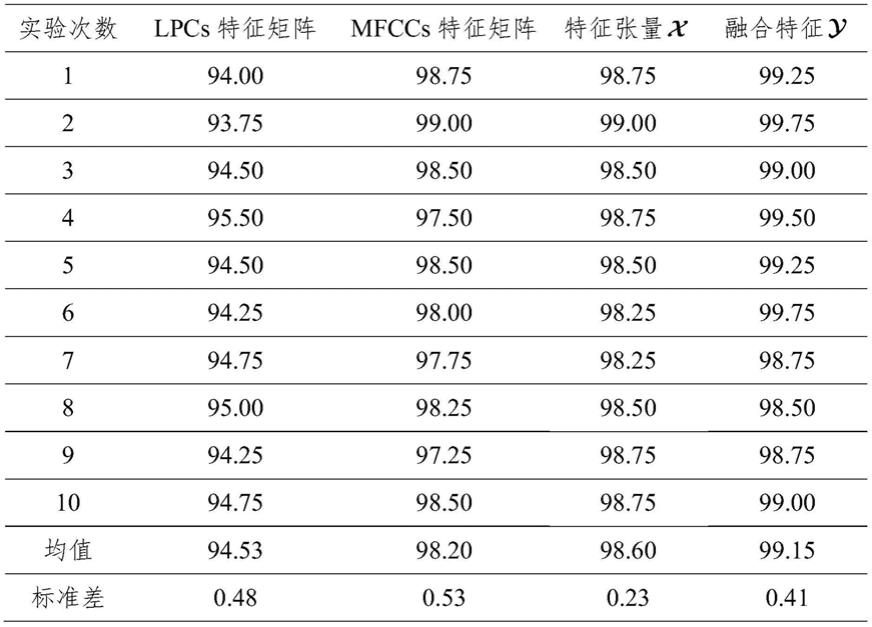
为验证融合特征的性能,设置了四组说话人识别实验,四组实验使用的语音特征分别为lpcs特征矩阵、mfccs特征矩阵、特征张量和融合特征每组实验进行10次,并计算10次实验说话人识别率的均值和标准差。10次实验说话人识别率的均值越大,标准差越小,说话人识别系统的性能越好,语音特征的性能越好。四个实验结果如表1所示。
[0038]
从表1中可知,使用特征张量或融合特征的说话人识别率均值分别为98.60%和99.15%,而使用lpcs特征矩阵和mfccs特征矩阵的说话人识别率均值为94.53%和98.20%。由此可得使用特征张量或融合特征的说话人识别率的均值比使用lpcs特征矩阵和mfccs特征矩阵的说话人识别率的均值高,使用融合特征的识别率比使用特征张量的识别率高。综上,此实验可以表明融合特征可以提高说话人识别系统的性能。
[0039]
表1四种特征10次实验的说话人识别率(%)
[0040][0041]
以上所述仅表达了本发明的优选实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形、改进及替代,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。