1.本发明涉及情感识别技术领域,具体涉及一种基于中文语音和文本的情感识别系统及方法。
背景技术:
2.情感识别是人机交互的重要组成部分,现阶段,不同的情感识别运用到不同领域,如远程教学,辅助驾驶,心理诊断等。准确的情感识别有利于更好的情感反馈和辅助相关任务的完成。然而人类情感的表达并不是由单一状态决定的,在复杂的多样的环境中,情感的表达方式也是多种多样,因此这给情感识别任务带来了极大的挑战。情感的持续时间长短不一并且不同人的表达和感知情绪的方式各异,有效地提升情感识别地鲁棒性和准确性是研究者追求的目标。中文相比于英文,结构复杂,表达多样化,情感关键词的提取也较为困难,且数据库较少。这些因素加大了对中文情感识别的困难,所以对中文进行情感识别具有一定的挑战性。
技术实现要素:
3.本发明的目的是针对现有技术存在的问题,提供一种基于中文语音和文本的情感识别系统及方法。
4.为了实现上述目的,本发明采用以下技术方案:
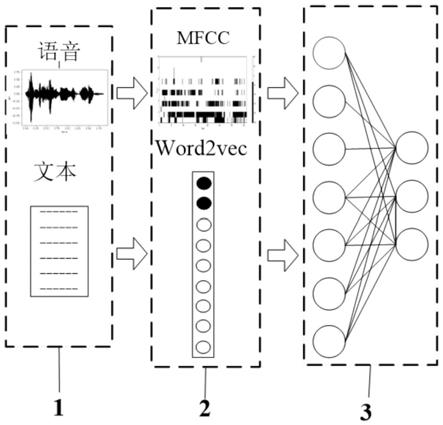
5.一种基于中文语音和文本的情感识别系统,包括依次连接的语音和文本信息提取单元、预处理操作单元和特征提取单元,语音和文本信息提取单元基于神经网络将获取的语音信息转换成相应的文本信息;预处理操作单元用于对原始的语音信息经过预加重、分帧和加窗处理被转换成梅尔频率倒谱系数mfcc,对文本信息进行分词和去停用词处理后,通过word2vec建立词典获得词向量;特征提取单元3用于梅尔频率倒谱系数mfcc和词向量的特征提取和融合,从而获取最后的情感识别结果。
6.进一步地,所述特征提取单元包括依次连接的主模块、并联卷积模块和记忆网络,其中,主模块包括语音预处理单元和文本预处理单元,语音预处理单元用于对梅尔频率倒谱系数mfcc进行处理得到语音信息的浅层特征,文本预处理单元用于对词向量的进行处理得到文本信息的浅层特征,语音信息的浅层特征和文本信息的浅层特征的输出通道和大小保持一致,并联卷积模块包括结构相同的第一并联卷积模块、第二并联卷积模块和第三并联卷积模块,第一并联卷积模块与语音预处理单元连接,用于对语音信息的浅层特征进行进一步的语音特征提取,第二并联卷积模块与文本预处理单元连接,用于对文本信息的浅层特征进行进一步的文本特征提取,第一并联卷积模块、第二并联卷积模块输出端均与第三并联卷积模块连接,第三并联卷积模块用于将第一并联卷积模块和第二并联卷积模块提取的特征拼接后进行深层特征提取。
7.进一步地,所述语音预处理单元由传统卷积层、第一深度可分离卷积层、池化层和第二深度可分离卷积层依次连接而成。
8.进一步地,文本预处理单元由依次连接的嵌入层和双向长短时记忆网络组成。
9.进一步地,第一并联卷积模块、第二并联卷积模块和第三并联卷积模块结构相同,均包括并联的深度卷积模块、普通卷积模块和池化卷积模块,所述深度卷积模块包括深度可分离卷积层、leakyrelu激活函数和批量归一化层,所述普通卷积模块包括传统卷积层、leakyrelu激活函数和批量归一化层,池化卷积模块包括池化层,普通卷积模块和池化卷积模块提取到的特征通过拼接融合方式得到新的特征,拼接后的特征和深度卷积模块提取到的特征通过相加融合的方式提取到最终的特征。
10.记忆网络其包括依次连接的第一双向长短时记忆网络、第二双向长短时记忆网络和注意力机制,第一双向长短时记忆网络和第二双向长短时记忆网络结构相同,用于获取上下文信息,确保时序信息的连续性,注意力机制用于突出需要注意的部分,抑制其他无用信息,快速提取重要的数据特征。
11.一种基于中文语音和文本的情感识别方法,具备包括以下步骤:
12.s1、语音和文本信息提取单元通过麦克风获取外界输入的声音并经过简单的神经网络提取出相应的语音信息,利用神经网络将获取到的声音转换成相应的文本信息;
13.s2、然后,将获取的语音信息和文本信息分别送入相应的预处理操作单元进行预处理操作;语音信息经过预加重、分帧和加窗处理被转换成梅尔频率倒谱系数mfcc;原始的文本信号经过分词和去停用词处理后,通过word2vec建立词典获得词向量。
14.s3、最后,将处理后的语音和文本信息送入特征提取单元中,进行相应的特征提取,从而获取最后的情感识别结果。
15.步骤s3又具体细分为以下步骤:
16.s301、将接收到的梅尔频率倒谱系数mfcc送入主模块中,在主模块中依次经过传统卷积层、深度可分离卷积层、池化层和深度可分离卷积层的作用实现对梅尔频率倒谱系数mfcc的浅层特征提取,得到语音信息的浅层特征;
17.s302、将接收到的词向量送入主模块中,在主模块中依次经过嵌入层和双向长短时记忆网络实现对词向量的浅层特征提取,得到文本信息的浅层特征;
18.s303、语音信息的浅层特征输入到第一并联卷积模块中,在第一并联卷积模块中同时进入深度卷积模块、普通卷积模块和池化卷积模块进行深度特征提取,在深度卷积模块中,语音信息的浅层特征经过深度可分离卷积层的特征提取,然后再利用leakyrelu激活函数增强模块的表达能力,最后送入批量归一化层做归一化处理;在普通卷积模块中,语音信息的浅层特征经过传统卷积层的特征提取,然后利用leakyrelu激活函数增强其表达能力,最后送入批量归一化层做归一化处理;在池化模块中,语音信息的浅层特征只需经过池化层进行特征提取然后输出;最终普通卷积模块输出的特征与池化模块输出的特征通过拼接的方式相融合,融合后的特征再与深度卷积模块输出的特征进行相加融合,从而输出对上一层信息做的最终特征提取,得到语音信息的深度特征;
19.s304、与步骤s303同时,文本信息的浅层特征输入到第二并联卷积模块,在第二并联卷积模块中同时进入深度卷积模块、普通卷积模块和池化卷积模块进行深度特征提取,在深度卷积模块中,文本信息的浅层特征经过深度可分离卷积层的特征提取,然后再利用leakyrelu激活函数增强模块的表达能力,最后送入批量归一化层做归一化处理;在普通卷积模块中,文本信息的浅层特征经过传统卷积层的特征提取,然后利用leakyrelu激活函数
增强其表达能力,最后送入批量归一化层做归一化处理;在池化模块中,文本信息的浅层特征只需经过池化层进行特征提取然后输出;最终普通卷积模块输出的特征与池化模块输出的特征通过拼接的方式相融合,融合后的特征再与深度卷积模块输出的特征进行相加融合,从而输出对上一层信息做的最终特征提取,得到文本信息的深度特征;
20.s305、步骤s303和步骤s305最终输出的语音信息的深度特征和文本信息的深度特征均输入到第三并联卷积模块,在第三并联卷积模块中同时进入深度卷积模块、普通卷积模块和池化卷积模块进行深度特征提取,在深度卷积模块中,经过深度可分离卷积层的特征提取,然后再利用leakyrelu激活函数增强模块的表达能力,最后送入批量归一化层做归一化处理;在普通卷积模块中,经过传统卷积层的特征提取,然后利用leakyrelu激活函数增强其表达能力,最后送入批量归一化层n做归一化处理;在池化模块中,只需经过池化层进行特征提取然后输出;最终普通卷积模块输出的特征与池化模块输出的特征通过拼接的方式相融合,融合后的特征再与深度卷积模块输出的特征进行相加融合,从而输出对上一层信息做的最终特征提取,得到融合信息的深度特征;
21.s306、步骤s305输出的融合信息的深度特征通过两层双向长短时记忆网络获取上下文信息,确保时序信息的连续性,然后通过添加注意力机制,突出需要注意的部分,抑制其他无用信息,快速提取重要的数据特征。
22.本发明与现有技术相比,具有如下优点:
23.(1)特征提取单元将卷积神经网络与循环神经网络相结合,卷积神经网络通过挖掘局部信息聚合获取整体信息,相比于循环神经网络减少训练参数,防止梯度消失;循环神经网络则可以对整个序列建模并捕捉获取长期依赖关系,从而获取连续信息的相关信息;
24.(2)设计了并联卷积模块,该模块包含第一并联卷积模块,第二并联卷积模块和第三并联卷积模块,这些模块均是将深度卷积模块、普通卷积模块和池化模块并联,实现对相同数据同时进行特征提取;然后将普通卷积模块和池化模块所提取的特征进行拼接融合,从而充分提取该层的特征信息,增加了最终输出特征的多样性;最后将拼接后的特征与深度卷积模块所提取的信息进行相加融合,对每个维度的特征进行增强和补充,突出重要特征信息,确保充分提取上层信息;此外,池化层删除了前一层的冗余信息;深度可分离卷积层相比于传统卷积层减少了训练参数,从而进一步实现网络轻量化;
25.(3)为确保模型的鲁棒性和识别准确率,选择在并联卷积模块进行语音信息和文本信息的融合,在该模块进行融合既保证了相关信息的充分融合,同时,又因已使用卷积神经网络对原始输入信号进行浅层特征提取,防止冗余信息对识别的干扰,并且,相对于在双向长短时记忆网络中融合,还可以减少训练参数,确保了模型的轻量化。
附图说明
26.图1为本发明的涉及的基于中文语音和文本的情感识别系统的模型结构示意图。
27.图2为本发明涉及的特征提取单元的网络结构图。
28.图3为本发明涉及的并联模块结构示意图。
29.图标符号说明:
30.1:语音和文本信息提取单元,2:预处理操作单元,3:特征提取单元,31:主模块,32:并联卷积模块,33:记忆模块,32a:第一并联卷积,32b:第二并联卷积,32c:第三并联卷
积,321:深度卷积模块,322:普通卷积模块,323:池化模块,mfcc:梅尔频率倒谱系数,b:双向长短时记忆网络,a:注意力机制,c:传统卷积层,s:深度可分离卷积层,p:池化层,e:嵌入层,n:批量归一化层,l:leakyrelu激活函数
具体实施方式
31.下面给出的实施例以对本发明作进一步说明。有必要在此指出的是以下实施例不能理解为对本发明保护范围的限制,如果该领域的技术熟练人员根据上述本发明内容对本发明做出一些非本质的改进和调整,仍属于本发明保护范围。
32.实施例1
33.本实施涉及的一种基于中文语音和文本的情感识别系统,包括依次连接的语音和文本信息提取单元1、预处理操作单元2和特征提取单元3,语音和文本信息提取单元1基于神经网络将获取的语音信息转换成相应的文本信息;预处理操作单元2用于对原始的语音信息经过预加重、分帧和加窗处理被转换成梅尔频率倒谱系数mfcc,其中,梅尔频率倒谱系数mfcc是一种在进行自动语音识别和说话人判断中广泛运用的特征,其是根据人耳听觉特征提取出来的,与赫兹频率成非线性对应关系;对文本信息进行分词和去停用词处理后,通过word2vec建立词典获得词向量;特征提取单元3用于梅尔频率倒谱系数mfcc和词向量的特征提取和融合,从而获取最后的情感识别结果。
34.进一步地,所述特征提取单元3包括依次连接的主模块31、并联卷积模块32和记忆网络33,其中,主模块31包括语音预处理单元和文本预处理单元,语音预处理单元用于对梅尔频率倒谱系数mfcc进行处理得到语音信息的浅层特征,文本预处理单元用于对词向量的进行处理得到文本信息的浅层特征,语音信息的浅层特征和文本信息的浅层特征的输出通道和大小保持一致,并联卷积模块32包括结构相同的第一并联卷积模块32a、第二并联卷积模块32b和第三并联卷积模块32c,第一并联卷积模块32a与语音预处理单元连接,用于对语音信息的浅层特征进行进一步的语音特征提取,第二并联卷积模块32b与文本预处理单元连接,用于对文本信息的浅层特征进行进一步的文本特征提取,第一并联卷积模块32a、第二并联卷积模块32b输出端均与第三并联卷积模块32c连接,第三并联卷积模块32c用于将第一并联卷积模块32a和第二并联卷积模块32b提取的特征拼接后进行深层特征提取,从而最终获取较为准确的情感状态,并且保证了输入信息的连续性。
35.进一步地,所述语音预处理单元由传统卷积层c、第一深度可分离卷积层s、池化层p和第二深度可分离卷积层s依次连接而成,其中,传统卷积层c通过参数共享、局部感知的方式提取所需要的特征,同时降低了网络参数和保障了网络的稀疏性;而第一深度可分离卷积层s和第二深度可分离卷积层s则是在传统卷积层c的基础上进行了很小的改动,即将上一层的多通道的特征,首先将其拆分为单通道的特征,然后对他们分别进行卷积,最后重新堆叠到一起,从而进一步减少训练参数;对于池化层p,通过汇合操作使网络更关注于是否存在某些特征,同时还起到特征降维和防止过拟合发生的作用。
36.进一步地,文本预处理单元由依次连接的嵌入层e和双向长短时记忆网络b组成,其中,嵌入层e的作用是增加特征之间的关联性,提高网络的识别准确率;双向长短时记忆网络b可以有效地学习时间序列中的动态信息,避免了长期依赖和梯度爆炸地问题,从而能更好地理解上下文信息对该时刻状态的影响;因此,嵌入层e后增加双向长短时记忆网络b
可以维持文本之间的序列关系。所述嵌入层e的增加可以增强特征之间的相关性,为保证语音和文本信息融合的可行性,经过主模块31进行浅层特征提取后的语音和文本的输出维度和通道数保持一致,然后再送入并联卷积模块32中。
37.进一步地,第一并联卷积模块32a、第二并联卷积模块32b和第三并联卷积模块32c结构相同,均包括并联的深度卷积模块321、普通卷积模块322和池化卷积模块323,所述深度卷积模块321包括深度可分离卷积层s、leakyrelu激活函数l和批量归一化层n,深度可分离卷积层s用于提取输入信息的特征,并且相比于采用传统卷积还可以减少训练参数,保障模型的轻量化,leakyrelu激活函数l用于增强模块的表达能力,批量归一化层n用于归一化处理,所述普通卷积模块322包括传统卷积层c、leakyrelu激活函数l和批量归一化层n,传统卷积层c用于提取输入信息的特征,充分挖掘并提取输入信息的特征,保证了信息的完整性和可靠性,leakyrelu激活函数l用于增强模块的表达能力,批量归一化层n用于归一化处理,池化卷积模块323包括池化层p,池化层p用于提取输入信息的特征,通过过池化的作用提取相邻信息间的重要信息,并且在一定程度上防止过拟合发生,普通卷积模块322和池化卷积模块323提取到的特征通过拼接融合方式得到新的特征,拼接后的特征和深度卷积模块321提取到的特征通过相加融合的方式提取到最终的特征,融合后的新特征既增加了特征的多样性,同时也保证了信息的准确性;除此之外,第一并联卷积模块32a和第二并联卷积模块32b分别对语音和文本进行深度特征提取,然后将提取到的特征进行融合后输入第三并联卷积32c,通过第三并联卷积32c对融合后的信息再进行特征提取,既保障了融合后相关特征的充分提取,并且相比于将融合后的信息直接输入到记忆网络中,还能防止信息冗余和错乱,提高模型最终的识别准确率;
38.记忆网络33为基于注意力机制的双向长短时记忆网络,其包括两层相同的双向长短时记忆网络b和注意力机制a,双向长短时记忆网络b用于获取上下文信息,确保时序信息的连续性,注意力机制a用于突出需要注意的部分,抑制其他无用信息,快速提取重要的数据特征。
39.一种基于中文语音和文本的情感识别方法,具备包括以下步骤:
40.s1、语音和文本信息提取单元1通过麦克风获取外界输入的声音并经过简单的神经网络提取出相应的语音信息,利用神经网络将获取到的声音转换成相应的文本信息。
41.具体地,进行情感识别时,被识别者利用麦克风以普通话的方式表达当时的情感,从麦克风收集到的声音信号通过麦克风将声音信号输入到该情感识别系统中。
42.s2、然后,将获取的语音信息和文本信息分别送入相应的预处理操作单元2进行预处理操作。
43.具体地,语音信息经过预加重、分帧和加窗处理被转换成梅尔频率倒谱系数mfcc;原始的文本信号经过分词和去停用词处理后,通过word2vec建立词典获得词向量。
44.s3、最后,将处理后的语音和文本信息送入特征提取单元3中,进行相应的特征提取,从而获取最后的情感识别结果。
45.步骤s3又具体细分为以下步骤:
46.s301、将接收到的梅尔频率倒谱系数mfcc送入主模块31中,在主模块31中依次经过传统卷积层c、深度可分离卷积层s、池化层p和深度可分离卷积层s的作用实现对梅尔频率倒谱系数mfcc的浅层特征提取,得到语音信息的浅层特征;
47.s302、将接收到的词向量送入主模块31中,在主模块31中依次经过嵌入层e和双向长短时记忆网络b实现对词向量的浅层特征提取,得到文本信息的浅层特征;
48.s303、语音信息的浅层特征输入到第一并联卷积模块32a中,在第一并联卷积模块32a中同时进入深度卷积模块321、普通卷积模块322和池化卷积模块323进行深度特征提取,在深度卷积模块321中,语音信息的浅层特征经过深度可分离卷积层s的特征提取,然后再利用leakyrelu激活函数l增强模块的表达能力,最后送入批量归一化层n做归一化处理;在普通卷积模块322中,语音信息的浅层特征经过传统卷积层c的特征提取,然后利用leakyrelu激活函数l增强其表达能力,最后送入批量归一化层n做归一化处理;在池化模块323中,语音信息的浅层特征只需经过池化层p进行特征提取然后输出;最终普通卷积模块322输出的特征与池化模块323输出的特征通过拼接的方式相融合,融合后的特征再与深度卷积模块321输出的特征进行相加融合,从而输出对上一层信息做的最终特征提取,得到语音信息的深度特征;
49.s304、与步骤s303同时,文本信息的浅层特征输入到第二并联卷积模块32b,在第二并联卷积模块32b中同时进入深度卷积模块321、普通卷积模块322和池化卷积模块323进行深度特征提取,在深度卷积模块321中,文本信息的浅层特征经过深度可分离卷积层s的特征提取,然后再利用leakyrelu激活函数l增强模块的表达能力,最后送入批量归一化层n做归一化处理;在普通卷积模块322中,文本信息的浅层特征经过传统卷积层c的特征提取,然后利用leakyrelu激活函数l增强其表达能力,最后送入批量归一化层n做归一化处理;在池化模块323中,文本信息的浅层特征只需经过池化层p进行特征提取然后输出;最终普通卷积模块322输出的特征与池化模块323输出的特征通过拼接的方式相融合,融合后的特征再与深度卷积模块321输出的特征进行相加融合,从而输出对上一层信息做的最终特征提取,得到文本信息的深度特征;
50.s305、步骤s303和步骤s305最终输出的语音信息的深度特征和文本信息的深度特征均输入到第三并联卷积模块32c,在第三并联卷积模块32c中同时进入深度卷积模块321、普通卷积模块322和池化卷积模块323进行深度特征提取,在深度卷积模块321中,经过深度可分离卷积层s的特征提取,然后再利用leakyrelu激活函数l增强模块的表达能力,最后送入批量归一化层n做归一化处理;在普通卷积模块322中,经过传统卷积层c的特征提取,然后利用leakyrelu激活函数l增强其表达能力,最后送入批量归一化层n做归一化处理;在池化模块323中,只需经过池化层p进行特征提取然后输出;最终普通卷积模块322输出的特征与池化模块323输出的特征通过拼接的方式相融合,融合后的特征再与深度卷积模块321输出的特征进行相加融合,从而输出对上一层信息做的最终特征提取,得到融合信息的深度特征;
51.s306、步骤s305输出的融合信息的深度特征通过两层双向长短时记忆网络b获取上下文信息,确保时序信息的连续性,然后通过添加注意力机制a,突出需要注意的部分,抑制其他无用信息,快速提取重要的数据特征,最终识别出被识别者当时的情感状态。通过实验验证最终识别准确率达到90.02%,相比于传统的双模态情感识别网络,在相同数据集的情况下,准确率提高了7.5%。