1.本发明涉及语言清晰度技术领域,特别是指一种语言清晰度的优化方法及装置。
背景技术:
2.语言清晰度是指一个或几个发音人所发的、经过通信系统能被一个或几个听音人所确定的意义不连贯的语言单位百分数。
3.目前语言清晰度(articulation index)分析现状如下:多通过lms(非学习管理系统)、head等软件进行计算,得出语言清晰度曲线或平均值;通过滤波器的手段对信号进行滤波,得出部分频率/频带优化后的信号;计算滤波后信号的语言清晰度曲线/平均值。但此方法较为繁琐、易受到信号分析人员的处理方式的影响、且滤波过程中容易影响其相邻频带,频程边界不易控制;并且此方法无法给出特定频程对语言清晰度的权重。
技术实现要素:
4.本发明要解决的技术问题是提供一种语言清晰度的优化方法及装置,以解决现有语言清晰度方法较为繁琐的问题。
5.为解决上述技术问题,本发明的技术方案如下:
6.根据本发明的一个方面,提供一种一种语言清晰度的优化方法,包括:
7.获取噪声的频谱分量,所述频谱分量包括至少一个能量水平等级,每一能量水平等级对应至少一个频率,一个能量水平等级和一个频率构成的频谱组合,对应一个预设的语言清晰度权重值;
8.根据所述频谱分量包括的频谱组合对应的预设语言清晰度权重值的最大值,获取语言清晰度权重精度值;
9.根据语言清晰度权重精度值,获取所述噪声的频谱分量的至少一个频谱组合对应的当前语言清晰度权重值;
10.根据所述噪声的频谱分量的所有频谱组合对应的当前语言清晰度权重值,获得最终的清晰度值;
11.根据目标语言清晰度值,对噪声的频谱分量进行优化。
12.可选的,根据所述频谱分量包括的频谱组合对应的预设语言清晰度权重值的最大值,获取语言清晰度权重精度值,包括:
13.将所述预设语言清晰度权重值的最大值分成n份,将每份权重值作为语言清晰度权重精度值,所述n大于所述频谱分量包括的能量水平等级的个数。
14.可选的,根据语言清晰度权重精度值,获取所述噪声的频谱分量的至少一个频谱组合对应的当前语言清晰度权重值,包括:
15.根据输入的所述噪声的频谱分量的至少一个频谱组合,按照每个频谱组合对应的预设语言清晰度权重值,加上语言清晰度权重精度值,得到所述噪声的频谱分量的至少一个频谱组合对应的当前语言清晰度权重值。
16.可选的,根据所述噪声的频谱分量的所有频谱组合对应的当前语言清晰度权重值,获得最终的清晰度值,包括:
17.将所述频谱分量包括的所有频谱组合对应的当前语言清晰度权重值求和,获得最终的语言清晰度值。
18.可选的,根据目标语言清晰度值,对噪声的频谱分量进行优化,包括:
19.从所述频谱分量的频谱组合中,选择一部分频谱组合;
20.对该选择的一部分频谱组合对应的当前语言清晰度权重值,按照目标语言清晰度值,得到优化值;
21.按照优化值对噪声的频谱分量进行优化。
22.可选的,按照目标语言清晰度值,得到优化值,包括:
23.按照所述目标语言清晰度减去当前语言清晰度权重值,得到优化值。
24.本发明的实施例还提供一种语言清晰度的优化装置,包括:
25.频谱分量获取模块,用于获取噪声的频谱分量,所述频谱分量包括至少一个能量水平等级,每一能量水平等级对应至少一个频率,一个能量水平等级和一个频率构成的频谱组合,对应一个预设的语言清晰度权重值;
26.精度值获取模块,用于根据所述频谱分量包括的频谱组合对应的预设语言清晰度权重值的最大值,获取语言清晰度权重精度值;
27.权重值获取模块,用于根据语言清晰度权重精度值,获取所述噪声的频谱分量的至少一个频谱组合对应的当前语言清晰度权重值;
28.清晰度值获取模块,用于根据所述噪声的频谱分量的所有频谱组合对应的当前语言清晰度权重值,获得最终的清晰度值;
29.优化模块,用于根据目标语言清晰度值,对噪声的频谱分量进行优化。
30.可选的,精度值获取模块,具体用于:将所述预设语言清晰度权重值的最大值分成n份,将每份权重值作为语言清晰度权重精度值,所述n大于所述频谱分量包括的能量水平等级的个数。
31.可选的,权重值获取模块,具体用于:根据输入的所述噪声的频谱分量的至少一个频谱组合,按照每个频谱组合对应的预设语言清晰度权重值,加上语言清晰度权重精度值,得到所述噪声的频谱分量的至少一个频谱组合对应的当前语言清晰度权重值。
32.可选的,清晰度值获取模块,具体用于:将所述频谱分量包括的所有频谱组合对应的当前语言清晰度权重值求和,获得最终的语言清晰度值。
33.可选的,优化模块,具体用于:从所述频谱分量的频谱组合中,选择一部分频谱组合;
34.对该选择的一部分频谱组合对应的当前语言清晰度权重值,按照目标语言清晰度值得到优化值;
35.按照优化值对噪声的频谱分量进行优化。
36.可选的,按照目标语言清晰度值,得到优化值,包括:
37.按照所述目标语言清晰度减去当前语言清晰度权重值,得到优化值。
38.本发明的上述方案至少包括以下有益效果:
39.本发明的上述方案,通过获取噪声的频谱分量和预设的语言清晰度权重值,进而
获取语言清晰度权重精度值、频谱组合对应的当前语言清晰度权重值、最终的清晰度值、目标语言清晰度值,能够方便快捷的对噪声的频谱分量进行优化,具有方法操作简单、成本较低的优点。
附图说明
40.图1是本发明的一种语言清晰度的优化方法的步骤图;
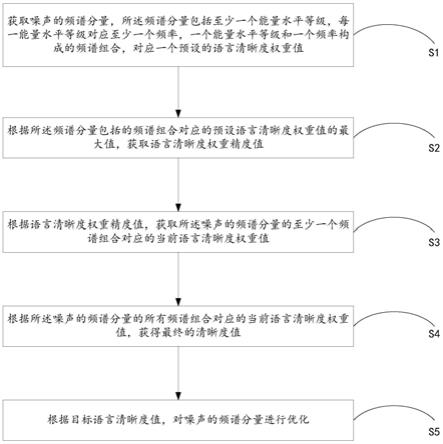
41.图2是本发明的一种语言清晰度的优化装置的器件连接图;
42.图3是语言区域示意图。
具体实施方式
43.下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
44.如图1所示,本发明的实施例提出一种语言清晰度的优化方法,包括:
45.s1、获取噪声的频谱分量,所述频谱分量包括至少一个能量水平等级,每一能量水平等级对应至少一个频率,一个能量水平等级和一个频率构成的频谱组合,对应一个预设的语言清晰度权重值;
46.s2、根据所述频谱分量包括的频谱组合对应的预设语言清晰度权重值的最大值,获取语言清晰度权重精度值;
47.s3、根据语言清晰度权重精度值,获取所述噪声的频谱分量的至少一个频谱组合对应的当前语言清晰度权重值;
48.s4、根据所述噪声的频谱分量的所有频谱组合对应的当前语言清晰度权重值,获得最终的清晰度值;
49.s5、根据目标语言清晰度值,对噪声的频谱分量进行优化。
50.本发明通过获取噪声的频谱分量和预设的语言清晰度权重值,进而获取语言清晰度权重精度值、频谱组合对应的当前语言清晰度权重值、最终的清晰度值、目标语言清晰度值,能够方便快捷的对噪声的频谱分量进行优化,具有方法操作简单、成本较低的优点。
51.本发明的一可选实施例中,步骤s2根据所述频谱分量包括的频谱组合对应的预设语言清晰度权重值的最大值,获取语言清晰度权重精度值,包括:
52.将所述预设语言清晰度权重值的最大值分成n份,将每份权重值作为语言清晰度权重精度值,所述n大于所述频谱分量包括的能量水平等级的个数。
53.方便后续当前语言清晰度权重值的计算,提高方法的工作效率和准确性。
54.本发明的一可选实施例中,步骤s3根据语言清晰度权重精度值,获取所述噪声的频谱分量的至少一个频谱组合对应的当前语言清晰度权重值,包括:
55.根据输入的所述噪声的频谱分量的至少一个频谱组合,按照每个频谱组合对应的预设语言清晰度权重值,加上语言清晰度权重精度值,得到所述噪声的频谱分量的至少一个频谱组合对应的当前语言清晰度权重值。
56.本发明的一可选实施例中,步骤s4根据所述噪声的频谱分量的所有频谱组合对应
的当前语言清晰度权重值,获得最终的清晰度值,包括:
57.将所述频谱分量包括的所有频谱组合对应的当前语言清晰度权重值求和,获得最终的语言清晰度值。
58.本发明的一可选实施例中,步骤s5根据目标语言清晰度值,以及所述最终的清晰度值,对噪声的频谱分量进行优化,包括:
59.从所述频谱分量的频谱组合中,选择一部分频谱组合;
60.对该选择的一部分频谱组合对应的当前语言清晰度权重值,按照目标语言清晰度值,得到优化值;
61.按照优化值对噪声的频谱分量进行优化。
62.本发明的一可选实施例中,按照目标语言清晰度值,得到优化值,包括:按照所述目标语言清晰度减去当前语言清晰度权重值,得到优化值。
63.如图2所示,本发明的实施例提出一种语言清晰度的优化装置,包括:
64.频谱分量获取模块,用于获取噪声的频谱分量,所述频谱分量包括至少一个能量水平等级,每一能量水平等级对应至少一个频率,一个能量水平等级和一个频率构成的频谱组合,对应一个预设的语言清晰度权重值;
65.精度值获取模块,用于根据所述频谱分量包括的频谱组合对应的预设语言清晰度权重值的最大值,获取语言清晰度权重精度值;
66.权重值获取模块,用于根据语言清晰度权重精度值,获取所述噪声的频谱分量的至少一个频谱组合对应的当前语言清晰度权重值;
67.清晰度值获取模块,用于根据所述噪声的频谱分量的所有频谱组合对应的当前语言清晰度权重值,获得最终的清晰度值;
68.优化模块,用于根据目标语言清晰度值,对噪声的频谱分量进行优化。
69.本发明通过获取噪声的频谱分量和预设的语言清晰度权重值,进而获取语言清晰度权重精度值、频谱组合对应的当前语言清晰度权重值、最终的清晰度值、目标语言清晰度值,能够方便快捷的对噪声的频谱分量进行优化,具有装置结构操作简单、成本较低的优点。
70.本发明的一可选实施例中,精度值获取模块,具体用于:
71.将所述预设语言清晰度权重值的最大值分成n份,将每份权重值作为语言清晰度权重精度值,所述n大于所述频谱分量包括的能量水平等级的个数。
72.方便后续当前语言清晰度权重值的计算,提高方法的工作效率和准确性。
73.本发明的一可选实施例中,权重值获取模块,具体用于:
74.根据输入的所述噪声的频谱分量的至少一个频谱组合,按照每个频谱组合对应的预设语言清晰度权重值,加上语言清晰度权重精度值,得到所述噪声的频谱分量的至少一个频谱组合对应的当前语言清晰度权重值。
75.本发明的一可选实施例中,清晰度值获取模块,具体用于:
76.将所述频谱分量包括的所有频谱组合对应的当前语言清晰度权重值求和,获得最终的语言清晰度值。
77.本发明的一可选实施例中,优化模块,具体用于:
78.从所述频谱分量的频谱组合中,选择一部分频谱组合;
79.对该选择的一部分频谱组合对应的当前语言清晰度权重值,按照目标语言清晰度值得到优化值;
80.按照优化值对噪声的频谱分量进行优化。
81.本发明的一可选实施例中,按照目标语言清晰度值,得到优化值,包括:按照所述目标语言清晰度减去当前语言清晰度权重值,得到优化值。
82.需要说明的是,该装置是与上述图1所述的方法对应的装置,所示方法中的所有实现方式均适用于该装置的实施例中,也能达到同样的技术效果。
83.本发明的实施例的一种语言清晰度的优化方法的工作流程为:获取噪声的频谱分量,所述频谱分量包括至少一个能量水平等级,每一能量水平等级对应至少一个频率,一个能量水平等级和一个频率构成的频谱组合,对应一个预设的语言清晰度权重值;语言清晰度权重值可以通过表1查到:
84.表1语言清晰度指数图表(简略版)
[0085][0086][0087]
根据所述频谱分量包括的频谱组合对应的预设语言清晰度权重值的最大值,获取语言清晰度权重精度值;清晰度指数ai在nvh(噪声noise、振动vibration与声振粗糙度harshness)行业是0-100%范围内的值。如图3,横轴表示噪声频率,纵轴表示噪声能量水平等级,如果噪声频谱(distrubance speetrum)位于语音区域(speech area)的下部,则交谈只会稍有干扰,清晰度指数达到高值(≈100%);如果噪声谱在语音区域的上部,交流变得更加困难,清晰度指数达到低值(≈0%)。根据语言清晰度权重精度值,获取所述噪声的频谱分量的至少一个频谱组合对应的当前语言清晰度权重值;根据所述噪声的频谱分量的所有频谱组合对应的当前语言清晰度权重值,获得最终的清晰度值;根据用户需求,设定目标语言清晰度值,根据目标语言清晰度值,以及所述最终的清晰度值,对噪声的频谱分量进行优化。
[0088]
本发明的实施例是根据标准规定1/3倍频程法计算语言清晰度值。首先,根据输入的1/3倍频程level(能量水平等级),对其进行四舍五入,取整小数点后两位数与计算精度
相同(计算精度小数位数记为n)。
[0089]
其次,根据各频带声压级大小计算其对应的语言清晰度指数ai贡献,如表1,公式逻辑如下:
[0090]
若level≤level_min,则ai=ai_max;
[0091]
若level≥level_max,则ai=0;
[0092]
若level在level_min与level_max之间,则ai计算公式如下:
[0093][0094]
表2各频噪声频率及其对应的最大/小能量水平等级、最大/小语言清晰度指数
[0095] level_minai_maxlevel_maxai_min噪声频率(hz)ai-100%(db)ai-100%(%)ai-0%(db)ai-0%(%)200341.00640.00250392.00690.00315413.25710.00400434.25730.00500454.50750.00630455.25750.00800456.50750.001000447.25740.001250428.50720.0016004011.50700.0020003711.00670.002500359.50650.003150339.00630.004000307.75600.005000266.25560.006300212.50510.00
[0096]
如,通过潜在优化空间分析可知,2500hz、3150hz、4000hz、5000hz、6300hz优化潜力接近0%,其5个频带优化至极限后仅能使得总ai提升0.3%,空间小非重点频带,在测试优化时应有限调节其他频带;如为达成80%目标,可假定如下方案:
[0097]
1、从所述频谱分量的频谱组合中,选择一部分频谱组合;对该选择的一部分频谱组合对应的当前语言清晰度权重值,按照目标语言清晰度值以及所述最终的语言清晰度值,进行优化,得到优化后的语言清晰度权重值;按照优化后的语言清晰度权重值对噪声的频谱分量进行优化。
[0098]
如优化800hz、1000hz、1250hz、1600hz;该选择的一部分频谱组合每3db指数分别为0.65%、0.725%、0.9%、1.15%,每频程优化3db后即可保证达到80%目标(优化后ai为80.4%);
[0099]
2、对所有频谱组合对应的当前语言清晰度权重值,按照目标语言清晰度值以及所
述最终的语言清晰度值,进行优化,得到优化后的语言清晰度权重值;按照优化后的语言清晰度权重值对噪声的频谱分量进行优化。
[0100]
如优化200hz、250hz、315hz、400hz、500hz、630hz、800hz、1000hz、1250hz、1600hz、2000hz,每频带优化1.5db后亦可保证达到80%目标(优化后ai为80.3%);
[0101]
3、如此可假定多种方案,根据频谱特性快速得出所需潜在优化空间结果,给出语音区域在噪声谱下部的优化开展方案。
[0102]
根据fft(快速傅里叶变换)频谱特性,评价多种方案组合可行性后可确认频带重要度排序,进而开展下步调校。按照指数分布情况,频谱组合有两种优化方案,最终可以会选择第一种方案进行优化。
[0103]
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。