强方法,所述方法包括:
7.获取原始的带噪信号;
8.从预先建立好的多通道口-双耳房间脉冲响应数据库中提取若干组多通道口-双 耳房间脉冲响应;将多通道口-双耳房间脉冲响应经傅里叶变换转换为频域传递函数, 由频域传递函数充当导向矢量,组成导向矢量矩阵;对导向矢量矩阵进行特征值分 解,在最小化输出信号能量的同时对主要的特征向量进行约束,通过求解凸优化问题 计算得到波束形成权向量;
9.利用波束形成权向量对原始的带噪信号进行加权求和,输出增强后的语音信号。
10.作为上述方法的一种改进,所述方法还包括搭建双耳佩戴式传声器阵列实验平 台,该双耳佩戴式传声器阵列实验平台包括人工头及躯干模拟器、无线耳机、支架、 三个mems双传声器阵列芯片、数据采集板和处理模块;其中,
11.无线耳机佩戴在人工头及躯干模拟器上;
12.支架设置在人工头及躯干模拟器的人工嘴前端,该支架位置和水平偏转角度可 调节;人工嘴用于播放经前置功率放大器放大的扫频信号;
13.三个mems双传声器阵列芯片分别固定在无线耳机和支架上,每个mems双 传声器阵列芯片包括两个传声器;固定在无线耳机左耳的mems双传声器阵列芯片 提供了两个左耳传声器,固定在无线耳机右耳的mems双传声器阵列芯片提供了两 个右耳传声器;固定在支架上的mems双传声器阵列芯片提供了两个口前传声器; 两个左耳传声器和两个右耳传声器与人工嘴近似在同一条直线上;
14.数据采集板,用于接收人工嘴播放的扫频信号、两个左耳传声器采集的信号、两 个右耳传声器采集的信号和两个口前传声器采集的信号,并转发至处理模块;
15.处理模块,用于对接收的信号进行解卷积,得到多通道口-双耳房间脉冲响应。
16.作为上述方法的一种改进,所述处理模块的具体实现包括:
17.对人工嘴两个口前传声器采集的信号x5(n)和x6(n)进行延迟波束形成,构成一 个虚拟指向性传声器,得到增强后信号的时域表示x0(n):
[0018][0019]
其中,n表示时域采样;
[0020]
人工嘴到所述虚拟指向性传声器的脉冲响应函数h0(n)表示为:
[0021]
h0(n)=x0(n)*i(n)
[0022]
其中,i(n)为扫频信号p(n)的逆扫频信号,*表示卷积;
[0023]
人工嘴到两个左耳传声器和两个右耳传声器的脉冲响应函数h
m
(n)表示为:
[0024]
h
m
(n)=x
m
(n)*i(n),m=1,...,4
[0025]
其中,x
m
(n),m=1,...,4分别为两个左耳传声器和两个右耳传声器采集的信号;
[0026]
对h0(n)和h
m
(n)分别进行傅里叶变换得到频域传递函数h0(k)和h
m
(k),由此计 算虚拟指向性传声器到两个左耳传声器和两个右耳传声器的频域传递函数h
m,0
(k):
[0027]
h
m,0
(k)=h
m
(k)/h0(k),m=1,...,4
[0028]
其中,k表示频域采样;
[0029]
通过逆傅里叶变换,得到多通道口-双耳房间脉冲响应h
m,0
(n),m=1,...,4。
[0030]
作为上述方法的一种改进,所述方法还包括:建立多通道口-双耳房间脉冲响应 数据库的步骤,具体包括:
[0031]
由人工嘴播放经放大的扫频信号p(n);
[0032]
两个左耳传声器、两个右耳传声器和两个口前传声器采集的信号分别为 x
m
(n),m=1,...,6;
[0033]
数据采集板将收到的p(n)和x
m
(n)发送至处理模块;
[0034]
处理模块经解卷积得到两个口前传声器在该位置点的多通道口-双耳房间脉冲响 应;
[0035]
调节设置在人工嘴前端的支架的位置和水平偏转角度,重复上述步骤得到嘴前 端局部区域内若干个位置点的多通道口-双耳房间脉冲响应;
[0036]
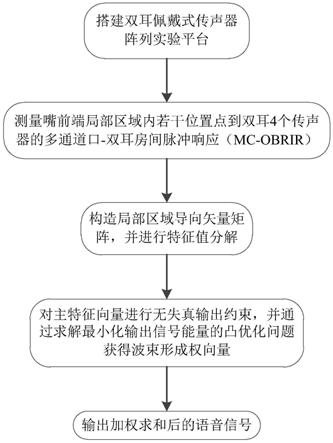
将上述若干个位置点的多通道口-双耳房间脉冲响应分别存入数据库。
[0037]
作为上述方法的一种改进,所述从预先建立好的多通道口-双耳房间脉冲响应数 据库中提取若干组多通道口-双耳房间脉冲响应;将多通道口-双耳房间脉冲响应经傅 里叶变换转换为频域传递函数,由频域传递函数充当导向矢量,组成导向矢量矩阵; 对导向矢量矩阵进行特征值分解,在最小化输出信号能量的同时对主要的特征向量 进行约束,通过求解凸优化问题计算得到波束形成权向量;具体包括:
[0038]
从预先建立好的多通道口-双耳房间脉冲响应数据库中提取若干组多通道口-双 耳房间脉冲响应将多通道口-双耳房间脉冲响应经傅里叶变换转换 为频域传递函数由频域传递函数充当导向矢量,组成导向矢量矩 阵a为:
[0039]
a=[a1(k),a2(k),...,a
j
(k),...,a
j
(k)]
[0040][0041]
其中,j为导向矢量的个数,a
j
(k)为频域传递函数,j=1,2,...,j,t表示转置;
[0042]
对导向矢量矩阵a进行特征值分解:
[0043]
a=uσv
h
[0044]
其中,σ为特征值构成的对角矩阵,u为左奇异矢量矩阵,v为右奇异矢量矩 阵,h表示共轭转置;
[0045]
选择前l个最大的特征值组成对角矩阵σ
l
,结合其对应的左奇异矩阵的l列u
l
和右奇异矩阵的l列v
l
,得到导向矢量矩阵a的近似矩阵a
l
:
[0046][0047]
通过上式以及无失真约束条件得到:
[0048][0049]
其中,g表示期望的幅度响应,无失真输出约束,g=1,1表示由1构成的 j
×
1维向量;
[0050]
联合lcmv凸优化问题,得到波束形成权向量w:
[0051][0052]
其中,r
zz
为带噪信号的功率谱密度矩阵:
[0053]
r
zz
=e{zz
h
}
[0054]
其中,e{
·
}为期望算子,z为频率表示的带噪信号。
[0055]
作为上述方法的一种改进,所述利用波束形成权向量对原始的带噪信号进行加 权求和,输出增强后的语音信号,具体包括:
[0056]
对波束形成权向量w和频域表示的带噪信号z进行加权求和,得到增强后的 语音信号的频域表示y:
[0057]
y=w
h
z
[0058]
对y进行逆傅里叶变换,得到增强后的语音信号的时域表示y(n)。
[0059]
本发明还提出了一种基于口-双耳房间脉冲响应的鲁棒语音增强系统,所述系统 包括:信号采集模块、权向量计算模块和增强输出模块;
[0060]
所述信号采集模块,用于获取原始的带噪信号;
[0061]
所述权向量计算模块,用于从预先建立好的多通道口-双耳房间脉冲响应数据库 中提取若干组多通道口-双耳房间脉冲响应;将多通道口-双耳房间脉冲响应经傅里叶 变换转换为频域传递函数,由频域传递函数充当导向矢量,组成导向矢量矩阵;对导 向矢量矩阵进行特征值分解,在最小化输出信号能量的同时对主要的特征向量进行 约束,通过求解凸优化问题计算得到波束形成权向量;
[0062]
所述增强输出模块,用于利用波束形成权向量对原始的带噪信号进行加权求 和,输出增强后的语音信号。
[0063]
与现有技术相比,本发明的优势在于:
[0064]
1、本发明的方法可以有效抑制远场同向干扰声源,并且相对于传统近场波束形 成器具有更高的鲁棒性。
[0065]
2、本发明的方法可有效解决传统近场波束形成器对目标声源的方位估计误差和 位置扰动过于敏感的问题。
附图说明
[0066]
图1(a)是本发明的耳机传声器阵列系统构型示意图的正视图;
[0067]
图1(b)是本发明的耳机传声器阵列系统构型示意图的侧视图;
[0068]
图1(c)是本发明的耳机传声器阵列系统构型示意图的俯视图;
[0069]
图2是本发明口-双耳房间脉冲响应测量装置系统连接图;
[0070]
图3是本发明实施例1在不同环境下测得的口-双耳房间脉冲响应曲线图;
[0071]
图4是本发明实施例1基于口-双耳房间脉冲响应的鲁棒语音增强方法的流程图;
[0072]
图5(a)是纯净语音的语谱图;
[0073]
图5(b)是带噪语音的语谱图;
[0074]
图5(c)是在环境匹配条件下带噪语音经现有技术近场线性约束最小方差算法增 强后的语谱图;
[0075]
图5(d)是在环境匹配条件下带噪语音经本发明实施例1的方法增强后的语谱图;
[0076]
图5(e)是在环境不匹配条件下带噪语音经现有技术近场线性约束最小方差算法 增强后的语谱图;
[0077]
图5(f)是在环境不匹配条件下带噪语音经本发明实施例1的方法增强后的语 谱图。
具体实施方式
[0078]
本发明针对双耳佩戴式传声器阵列语音增强问题,提供一种口-双耳房间脉冲响 应测量装置,并利用测量的多通道口-双耳房间脉冲响应(mc-obrir)数据库构造 口附近局部区域内口-双耳传递函数,在此基础上提出一种基于近场区域约束的双耳 svd-lcmv算法(svd-blcmv),即运用lcmv波束形成技术,在最小化输出信 号能量的同时对不同房间测量的人嘴前端区域内房间脉冲响应的主特征向量进行约 束。由于局部区域内导向矢量的特征向量包含了该区域内的通用性方向信息,因此本 发明所提方法可以有效提高传统近场自适应波束形成方法的鲁棒性。
[0079]
口-双耳房间脉冲响应测量装置:将mems双传声器阵列芯片固定在无线耳机外 侧,将无线耳机佩戴在人工头上,使左右两耳的双传声器与人嘴近似在同一条直线 上,人工嘴前端支架上固定另一个mems双传声器阵列芯片,构成虚拟指向性传声 器,其特征在于:该装置双耳各有2个传声器,属于双边耳机装置,并且嘴前端采用 双传声器阵列形成指向性波束形成器,可在一定程度上降低环境噪声。
[0080]
使用人工嘴到双耳4个传声器的传递函数与人工嘴到嘴前端传声器的传递函数 相除的方式获得口-双耳传递函数,再通过逆傅里叶变换得到口-双耳房间脉冲响应, 使用两个传递函数相除的方式获得口-双耳传递函数可以避免人工嘴对声波的散射作 用,使测量的口-双耳房间脉冲响应更接近真实房间脉冲响应。
[0081]
一种基于区域约束的鲁棒自适应波束形成方法:对人嘴前端局部区域内若干位 置点到双耳的导向矢量矩阵进行特征值分解,并对主特征向量进行无失真输出约束, 并结合线性约束最小方差波束形成方法,得到波束形成权向量。将测量的传递函数充 当导向矢量,对局部区域内导向矢量矩阵的主特征向量进行约束,不仅可以减少计算 量,还可以增加自适应波束形成的鲁棒性。
[0082]
本发明提供的多通道口-双耳房间脉冲响应(mc-obrir)测量方法:使用biuel &kjaer 4128c人工头及躯干模拟器(head and torso simulator,hats)和一对孔径 约为1.5cm的mems双传声器阵列测量多通道口-双耳房间脉冲响应。首先,将双 传声器阵列芯片固定在两个无线耳机上,分别佩戴在人工头的双耳上,同时在人工嘴 前侧某个测量点另放置一个传声器,佩戴示意图如图1所示,图1(a)、图1(b)和图 1(c)分别是正视、侧视和俯视图。其次,通过人工嘴播放频率范围为50hz-15khz,时 长为15s,采样率为16khz的对数扫频信号。最后,通过解卷积方法分别得到人工 嘴到口前传声器的房间脉冲响应以及人工嘴到双耳4个传声器的房间脉冲响应,将 两种房间脉冲响应进行傅里叶变换得到传递函数,并将传递函数相除即可得到多通 道口-双耳传递函数以及多通道口-双耳房间脉冲响应。图2给出了多通道口-双耳房 间脉冲响应(mc-obrir)测量系统平台。
[0083]
该方法的有益效果:使用biuel&kjaer 4128c人工头及躯干模拟器(head andtorso simulator,hats)以及双耳佩戴式无线耳机测量装置,充分考虑了人头、躯干 和耳廓等局部散射体对声波传播的影响,可以较逼真的模拟双耳近场声学模型。另 外,采用人工嘴到双耳的声学传递函数与人工嘴到口前传声器的声学传递函数相除 的方式计算口-双耳房间脉冲响应可以避免人工嘴对声波的散射效应,使测量得到的 多通道口-双耳房间脉冲响应(mc-obrir)尽可能地逼近真实的多通道口-双耳房间 脉冲响应(mc-obrir)。
[0084]
本发明所提方法均在频域内处理,假设z(k)为带噪信号的频域表示,w(k)为阵 列
的加权向量,其中k为频率采样点,本发明通过求解下列凸优化问题来计算波束 形成器的权向量,注意为了行文简洁,后文在不引起混淆的情况下将省略频率采样点 k:
[0085][0086]
其中r
zz
=e{z(k)z
h
(k)}为带噪信号的功率谱密度矩阵,e{
·
}为期望算子,c为约 束矩阵,h为期望响应向量。通过上式可以得到最优lcmv滤波器权向量:
[0087][0088]
本发明中,目标声源到双耳传声器阵列的导向矢量a
s
由测量得到的多通道口-双耳房 间脉冲响应(mc-obrir)来代替,干扰声源到双耳传声器阵列的导向矢量a
i
由相同 配置下测量得到的远场多通道双耳房间脉冲响应来代替。令a=[a1,a2,...,a
j
]表示某 频率下目标声源周围空间内若干导向矢量组成的矩阵,其中j为导向矢量的个数。通 过对该区域内的导向矢量进行约束,使区域内的语音信号得到无失真输出:
[0089]
a
h
w=g
ꢀꢀꢀꢀꢀꢀꢀ
(3)
[0090]
其中g表示期望的幅度响应,本发明对目标区域内的约束条件均为无失真输出约束, 因此g=1,1表示由1构成的j
×
1维向量。svd-blcmv算法首先对导向矢量组成的 矩阵a进行特征值分解:
[0091]
a=uσv
h
ꢀꢀꢀꢀꢀꢀꢀ
(4)
[0092]
其中u为左奇异矢量矩阵,v为右奇异矢量矩阵,然后选择前l个最大的特征值组 成对角矩阵σ
l
,以及其对应的l列左奇异矩阵u
l
和l列右奇异矩阵v
l
,由此计算 得到导向矢量a的近似矩阵a
l
:
[0093][0094]
通过上式结合公式(3)的无失真约束条件可得:
[0095][0096]
联合lcmv凸优化问题,可得特征向量的约束条件:
[0097][0098]
最终,可推导出svd-blcmv波束形成器的权向量:
[0099][0100]
利用波束权向量w对带噪信号z进行加权求和,得到增强后的语音信号的频域表示 y:
[0101]
y=w
h
z
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0102]
对y进行逆傅里叶变换,得到增强后的语音信号的时域表示y(n)。
[0103]
该方法的有益效果:采用测量的符合双耳近场模型的多通道口-双耳房间脉冲响 应(mc-obrir)构造声学传递函数,从而构造导向矢量进行算法设计,使其适用于 双耳佩戴式传声器阵列的语音增强应用。本发明对口前局部区域内的导向矢量进行 特征值分解,其主特征向量包含了该局部区域内的主要空间信息,因此对主特征向量 进行无失真输出约束,可有效提高自适应波束形成器的鲁棒性。
[0104]
本发明提出了一种口-双耳房间脉冲响应测量装置及基于区域约束的双耳近场自 适应波束形成算法,该算法将目标信号及其附近区域内的若干个导向矢量组成的矩 阵进行特征值分解,并在最小化输出信号能量的同时对主要的特征向量进行约束,从 而有效解决传统近场波束形成器对目标声源的方位估计误差和位置扰动过于敏感的 问题。
[0105]
下面结合附图和实施例对本发明的技术方案进行详细的说明。
[0106]
实施例1
[0107]
如图1和图2所示,本发明的实施例1提供了一种基于口-双耳房间脉冲响应的 鲁棒语音增强方法。采用br
ü
el&kjaer 4128c人工头及躯干模拟器(head and torsosimulator,hats)和3个孔径约为1.5cm的mems双传声器阵列测量多通道口-双 耳房间脉冲响应。两个双mems传声器芯片固定在无线耳机外侧,无线耳机佩戴在 人工耳中。其中人工头右耳的前后侧传声器分别为1号传声器和2号传声器,人工 头左耳的前后侧传声器分别为3号传声器和4号传声器。在人工嘴前端支架处固定 了另一个双mems传声器芯片,芯片左右侧分别是5号传声器和6号传声器。如图 1所示,左右耳的双传声器阵列与人嘴可近似在同一条直线上。测量过程如图2所 示,在adobe audition音频软件中准备频率范围为50hz-15khz,时长为15s,采样 率为16khz的对数扫频信号,通过前置功率放大器后用人工嘴播放,并采用数据采 集板同时接收6个传声器采集的信号,采集的信号通过adobe audition音频软件录 制并保存。
[0108]
假设6个传声器接收到的信号分别为x
m
(n),m=1,...,6,首先用5号和6号两个传 声器进行延迟求和波束形成,构成一个虚拟指向性传声器,该传声器用于接收人嘴播 放的信号,即其次,假设人工嘴播放的原始扫频信号为p(n), 该扫频信号的逆扫频信号为i(n),满足p(n)*i(n)=δ(n),其中*为卷积,δ(n)为狄克 拉函数,则人工嘴到人嘴前传声器的脉冲响应函数可表示为h0(n)=x0(n)*i(n),人工 嘴到传声器1~4的脉冲响应函数可表示为h
m
(n)=x
m
(n)*i(n),m=1,...,4。对h0(n)和 h
m
(n)分别进行傅里叶变换得到传递函数h0(k)和h
m
(k),由此可计算虚拟指向性传 声器到双耳4个传声器的传递函数h
m,0
(k)=h
m
(k)/h0(k),m=1,...,4。最终,通过逆 傅里叶变换,就可以得到多通道口-双耳房间脉冲响应h
m,0
(n),m=1,...,4。图3给出了 在半消声室、全消声室和普通办公室环境下测量的嘴前端距离1cm处,水平偏转角 度为0
°
的位置点的多通道口-双耳房间脉冲响应(mc-obrir),需要说明的是图中仅 展示了左耳1通道的测量结果。
[0109]
鲁棒自适应波束形成方法实施案例:分别在中国科学院声学研究所全消声室、半 消声室以及普通办公室环境下,采用br
ü
el&kjaer 4128c人工头及躯干模拟器(headand torso simulator,hats)搭建双耳佩戴式传声器阵列实验平台。在距离人工嘴0.5 cm,1cm,2cm,水平偏转角度
±
45
°
,
±
30
°
,
±
15
°
,
±
7.5
°
,0
°
位置处测量多通道口-双耳房 间脉冲响应,在三个房间内一共测量了29组数据。另外,在距离人工头1m,2m, 水平角度0
°
,
±
90
°
,180
°
处放置扬声器,通过扬声器播放noisex-92数据库中的babble 噪声或白噪声,并记录1~4号双耳传声器采集到的噪声信号n
m
(n),m=1,...,4。
[0110]
从thchs30 2015数据库中随机挑选一个纯净语音s(n),合成双耳佩戴式传声 器阵列采集的带噪语音信号的方法如下:
[0111]
z
m
(n)=s(n)*h
m,0
(n)+n
m
(n),m=1,...,4
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0112]
其中h
m,0
(n)为在半消声室内采集到的口-双耳房间脉冲响应,则带噪语音信号的 矩阵形式可表示为z(n)=[z1(n),z2(n),z3(n),z4(n)]
t
,该信号在短时傅里叶变换域可表示 为z(k,l),其瞬时功率谱密度矩阵可表示为r
zz
(k,l)=z(k,l)z
h
(k,l)。另外,从29组多 通道口-双耳房间脉冲响应(mc-obrir)数据库中选择24组房间脉冲响应,将其频 域传递函数组成矩阵a=[a1,a2,...,a
24
],其中j=1,2,...,24, 并利用公式(4)对矩阵a进行特征值分解,对其第一个主特征向量施加无失真输出约 束条件,即l=1。利用公式(7),公式(8),即可获得svd-blcmv波束形成的权向量。 利用测量的多通道口-双耳房间脉冲响应(mc-obrir)实施svd-blcmv算法的整 体流程图如图4所示。
[0113]
本发明对所提方法进行的测试,按照选用的房间脉冲响应数据集是否包含测试 环境下测量的房间脉冲响应,将测试条件分为环境匹配条件和环境不匹配条件。测量 的纯净语音选自清华大学中文语料库thchs30 2015,如图5(a)所示为纯净语音的语 谱图。干扰声源选自noisex-92数据库中babble噪声,信噪比为0db,如图5(b)所 示为带噪语音的语谱图。测试环境为中国科学院声学研究所半消声实验室。干扰声源 与人头的距离为2m,干扰声的角度为0
°
。图5(c)给出了环境匹配条件下输入带噪语 音经传统近场lcmv算法增强后的语音增强结果,图5(d)给出了环境匹配条件下 输入带噪语音经本发明提出的方法svd-blcmv算法增强后的语音增强结果。图5(c) 和图5(d)采用的多组多通道口-双耳房间脉冲响应中包含中国科学院声学研究所半消 声实验室的测量数据。从图5(c)和图5(d)可以看出在多通道口-双耳房间脉冲响应 (mc-obrir)与测试环境匹配时,传统近场lcmv和svd-blcmv都具备良好的 语音增强效果。图5(e)给出了环境不匹配条件下输入带噪语音经传统近场lcmv算 法增强后的语音增强结果,图5(f)给出了环境不匹配条件下输入带噪语音经本发明 提出的方法svd-blcmv算法增强后的语音增强结果。实验配置与图5(c)和图5(d) 相同,不同的是,svd-blcmv所采用的房间脉冲响应不包含半消声室所测量的房 间脉冲响应。从图5(e)可以看出,由于导向矢量与语音场景不匹配,近场lcmv算 法对导向矢量变化较为敏感,与图5(c)相比残留噪声增加较多,从图5(f)可以看出, svd-blcmv比传统近场lcmv的降噪效果好。说明svd-blcmv算法受到环境 变化产生的影响较小,仍有较为稳定的语音增强效果。
[0114]
实施例2
[0115]
本发明的实施例2提供了一种基于口-双耳房间脉冲响应的鲁棒语音增强系统。 该系统包括:信号采集模块、权向量计算模块和增强输出模块;
[0116]
信号采集模块,用于获取原始的带噪信号;
[0117]
权向量计算模块,用于从预先建立好的多通道口-双耳房间脉冲响应数据库中提 取若干组多通道口-双耳房间脉冲响应;将多通道口-双耳房间脉冲响应经傅里叶变换 转换为频域传递函数,由频域传递函数充当导向矢量,组成导向矢量矩阵;对导向矢 量矩阵进行特征值分解,在最小化输出信号能量的同时对主要的特征向量进行约束, 通过求解凸优化问题计算得到波束形成权向量;
[0118]
增强输出模块,用于利用波束形成权向量对原始的带噪信号进行加权求和,输出 增强后的语音信号。
[0119]
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参 照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技 术方
案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖 在本发明的权利要求范围当中。