1.本发明属于声景观监测技术领域,具体涉及一种值得保护的城市声景观品质自动监测方法。
背景技术:
2.城市声环境是城市品质的重要体现,长期以来,噪声指标如等效连续声压级laeq、累计百分数声级ln等被作为声环境的重要评价方式。kang jian等在文章[acoustic comfort evaluation in urban open public spaces]中指出,人对于声环境的主观舒适度不仅仅受到声级大小的影响,还受到其他因素诸如声源类型等方面的影响。因此,相比于传统的噪声评价方式,声景观的评价方法更具有与人的主观感受相契合的特征,引入声景观的概念对声环境进行评价具有重要意义。声景观的品质不仅受到噪声的影响,也涉及其原有的好的声音元素的保留,而随着当今城市化进程推进,城市噪声问题不断暴露的同时,美好的声音也正在消失和改变。因此,保护具有城市特点和时代特征的声景观是亟待解决的问题,而建立有效的监测方法预警系统,是对这些声景观进行科学评估,以便开展预防性保护工作的首要任务。
[0003]
对值得保护的声景观的监测方法存在以下技术问题和难点:
[0004]
(1)大量文献如o.axellson等人在文章[a principal components model ofsoundscapeperception]中指出人的主观声舒适与声源的类型呈现密切的关系。传统的噪声评价指标如laeq、累计百分数声级ln等更多的从声级的大小以及时间分布的角度对声环境进行评价,而无法携带声源的信息,因此仅使用基于声级大小评价的参量来衡量声景观品质具有一定的片面性。此外,目前对于值得保护的声景观的评价标准并不明确,现有的声学指标如心理声学指标响度、粗糙度、尖锐度、波动度等指标参量也缺乏对值得保护的声景观的特征表征。
[0005]
(2)值得保护的声景观往往自身存在一定的特征,而对于不同类型的值得保护的声景观,其特征可能各不相同。在对某一个特定的值得保护的声景观品质进行监测时,监测应当符合该声景观自身的原始特征,而该监测标准则不能用于其他的声景观品质监测。这就决定了难以用一个或一组固定的参量限值适用于对所有值得保护声景观品质的监测。
[0006]
针对于对值得保护的声景观品质监测方法存在上述不足和难点,希望开发一种新的声景观品质监测方法。近年来出现针对于声景观的客观预测指标的研究,包括b.yu在文章[development ofindicators for the soundscape in urban shopping streets]中开发的动态频谱重心指标,文章[ten questions on the soundscapes ofthe built environment]也证实心理声学指标也被证明与人的主观感受关系密切。然而,一个参量并不能描述声景观的完整特征,本发明在常用的声学物理指标中,选取了13个与声景观品质呈现显著的相关性的指标,包括声事件频谱重心方差、声事件频谱重心方差改变、响度、响度改变、尖锐度、尖锐度改变、响度波动、响度波动改变、phi_1、phi_1改变、tau_e改变、节奏改变和粗糙度改变。基于此基础,本发明考虑用多指标组合的方式,并结合最新的算法模
型,用于单个场景的客观物理指标与主观评价的对应,具有更强的科学性和可信度。
技术实现要素:
[0007]
本发明的目的在于克服现有技术的不足,提供一种值得保护的城市声景观品质自动监测方法。本发明在多个物理指标结合的思想下,结合主客观评价的对应性特征,采用决策树算法训练模型,模型能够包括表征声景观品质的指标的组合特性,从而达到对声景观品质进行监测和分类的功能。在实际应用过程中,可以在本发明提出的方法的基础上建立声景观品质自动监测系统,用于实现对值得保护的城市声景观品质的监测、分类和预警。方法在实现自动监测分类的同时,保证科学化、人性化,可以解决用传统指标进行测量存在的与人实际的听闻体验差距大,测量结果误差较大,获取的监测数据实时性、代表性较差的问题;以自动监测代替人工监测,在有效解决人工监测存在的人为因素影响测量结果准确度的问题之外,还可以对实际监测工作提供便利,节省大量的人力资源。
[0008]
本发明是通过以下技术方案实现的:
[0009]
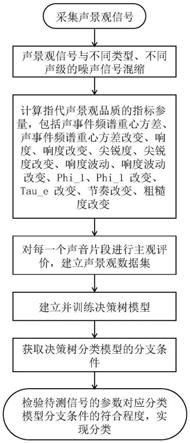
一种值得保护的城市声景观品质自动监测方法,包括步骤:
[0010]
步骤一:对值得保护的城市声景观的不同品质状态进行录音采集;
[0011]
步骤二:把步骤一采集到的声音信号转换为数字信号得到原声景观信号,将原声景观信号与不同类型、不同声级大小的噪声信号进行混缩,得到多个被噪声干扰的混缩噪声信号;对所有信号指代声景观品质的指标进行计算,从而获得每一个采集片段的指标参量;
[0012]
步骤三、以未混缩噪声的原声景观信号作为对照组,以混缩噪声后的混缩噪声信号作为评价组,将二者进行配对比较评价,得到每一个采集片段中声景观品质受到影响程度的评价等级;
[0013]
步骤四、基于步骤二和步骤三的数据集,建立决策树分类模型,该步骤进而分为以下步骤;
[0014]4‑
1、读取数据集及数据集预处理;
[0015]4‑
2、训练决策树模型,将数据集中一部分数据作为训练数据,另一部分数据作为测试数据,输入决策树模型进行训练;决策树模型的训练分为以下过程:首先,设第一个结点的训练数据集为d,计算现有特征对该数据集的基尼指数;其次,在所有可能的特征a以及他们所有可能的切分点a中,选择基尼系数最小的特征及其对应的切分点作为最优特征与最优切分点,再次,依最优特征与最优切分点,从现节点生成两个子节点,将训练数据集依特征分配到两个子结点中去;之后,对两个子节点递归地调用上述两个步骤,直至满足停止条件;最终,生成决策树模型;
[0016]4‑
3、数据集中声景观品质的改变程度3个等级分类,将其记为无影响、轻微影响、严重影响;生成后,决策树上的每个节点都标示了分支条件;
[0017]
步骤五:基于步骤四中的得到的决策树分类模型的分支条件,获取指代声景观品质的指标的不同组合方式与声景观品质受影响程度之间的关系,用于实践中对声景观品质监测,对声景观的受影响程度进行分类识别。
[0018]
在上述技术方案中,步骤一中,采集点设在值得保护的声景观场景中的典型位置;采集时间为15秒,采样频率为44.1khz。
[0019]
在上述技术方案中,步骤二中,噪声信号的类型包括两类:交通噪声和人群噪声;噪声信号的声级大小用信噪比表示,信噪比包括:
‑
5db、0db、5db、10db和15db五种情况。
[0020]
在上述技术方案中,步骤二中,指代声景观品质的指标包括:声事件频谱重心方差、声事件频谱重心方差改变量、响度、响度改变量、尖锐度、尖锐度改变量、响度波动、响度波动改变量、phi_1、phi_1改变量、tau_e改变量、节奏改变量以及粗糙度改变量;其中,声事件频谱重心方差用于描述混缩噪声信号和原声景观信号的背景声和声事件成分的特征,单位为hz2;响度用于指代人耳对于混缩噪声信号和原声景观信号的强度,单位为sone;响度改变量为混缩噪声信号相对于原声景观信号的响度改变量,单位为sone;尖锐度用于描述人耳对于混缩噪声信号和原声景观信号的音高感,反映声信号的频率分布情况,单位为acum;尖锐度改变量为混缩噪声信号相对于原声景观信号的尖锐度改变量,单位为acum;响度波动用于描述混缩噪声信号和原声景观信号的波动情况,单位为db;响度波动改变量为混缩噪声信号相对于原声景观信号的响度波动改变量,单位为db;phi_1、tau_e为自相关函数的重要参数,用于描述声信号在事件上的重复性,phi_1单位为db,tau_e单位为ms;节奏改变量为混缩噪声信号相对于原声景观信号的节奏改变量,单位为bpm;粗糙度改变量为混缩噪声信号相对于原声景观信号的粗糙度改变量,单位为asper,粗糙度用于描述声信号由于周期性时域波动所引起的主观听感。
[0021]
在上述技术方案中,步骤三中,声景观品质受到影响程度的评价等级包括:无影响、轻微影响和严重影响三个等级。
[0022]
在上述技术方案中,步骤四中,决策树模型的构建基于cart算法,在构建cart决策树时使用“基尼指数”准则来选择和划分属性;使用max_depth作为剪枝参数;在确定深度时,分别设置1
‑
20不同深度,比较不同深度的拟合效果,选择效果最佳的深度设定为最大深度构建决策树模型;在确定分类效果时,采用准确率作为分类效果评价的参照,其表达式为其中tp指模型将正例预测准确的个数,tn指反例预测准确的个数,p和n分别是正和反的样本数总数。
[0023]
本发明的优点和有益效果为:
[0024]
1)引入声景观概念,考虑到多个物理指标的组合效应,建立算法模型,提高声景观的品质与客观物理指标对应的科学性和严谨性,解决传统的声压级和频谱进行声环境测量存在的与人实际听闻体验差距大、测量结果误差大、代表性差的问题。在声景观保护工作中可以利用声景观品质的预测模型建立城市声景观监测预警体系,对城市中值得保护的声景观的品质进行科学地评估,以便开展预防性的保护工作;
[0025]
2)自动检测系统可以代替人工监测,在有效解决人工监测存在的人为因素影响测量结果准确度的问题之外,还可以对实际监测工作提供便利,节省大量的人力资源。
附图说明
[0026]
图1是本发明值得保护的城市声景观品质监测方法的流程图。
[0027]
对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,可以根据以上附图获得其他的相关附图。
具体实施方式
[0028]
为了使本技术领域的人员更好地理解本发明方案,下面结合具体实施例进一步说明本发明的技术方案。
[0029]
本发明是一种基于决策树模型的值得保护的城市声景观品质自动监测方法,包括步骤:
[0030]
步骤一:对值得保护的城市声景观的不同品质状态进行录音采集。采集点设在值得保护的声景观所在的场景中,采集的时间为该声景观的典型时段,对于该场景具有典型性和代表性,周边没有噪声的干扰。采集时长至少为15秒;采集点附近应没有大的反射面;所用的采集声音信号的设备为数字录音机或相同功能的录音设备,采样频率为44.1khz。
[0031]
步骤二:把步骤一采集到的声音信号转换为数字信号得到原声景观信号,将原声景观信号与不同类型、不同声级大小的噪声信号进行混缩,得到多个被噪声干扰的混缩噪声信号;其中混缩用的噪声信号包括交通声和人群噪声;交通声素材选择城市主干路的昼间平峰时段(9:30
‑
11:30)录制;人群噪声素材选择城市繁华商业街录制峰值客流时段(周末15:00
‑
17:00)录制;噪声录制所使用的仪器和参数设定与步骤一中声景观信号采集的方式保持一致;混缩操作可在daw软件如adobe audition中完成。噪声信号的声级大小用信噪比表示,信噪比包括:
‑
5db、0db、5db、10db和15db五种情况,原始声景观信号与不同类型和不同信噪比的噪声混缩后,得到10个被噪声干扰的声景观信号。
[0032]
完成混缩噪声信号制作后,对指代声景观品质的物理指标进行计算,从而获得每一个采集片段的指标参量,包括:
[0033]
声事件频谱重心方差:声景观中的背景声和声事件成分的特征,单位为hz2;声事件频谱重心方差改变为混缩噪声信号相对于原声景观信号的声事件频谱重心方差改变量;
[0034]
响度:人耳对于声信号的强度,单位为sone;响度改变为混缩噪声信号相对于原声景观信号的响度改变量,单位为sone;
[0035]
尖锐度:声信号的音高感,单位为acum;尖锐度改变为混缩噪声信号相对于原声景观信号的尖锐度改变量,单位为acum;
[0036]
响度波动:统计百分数声级l10与l90的差值,反映声音大小的波动情况,单位为db;响度波动改变为混缩噪声信号相对于原声景观信号的响度波动改变量;
[0037]
phi_1:acf曲线中的第一个峰值,单位为db;phi_1改变为混缩噪声信号相对于原声景观信号的phi_1改变量;
[0038]
tau_e:acf曲线中的第一个峰值所对应的时延,单位为ms;tau_e改变为混缩噪声信号相对于原声景观信号的tau_e改变量;
[0039]
节奏:声信号的节奏快慢程度,单位为bpm;节奏改变为混缩噪声信号相对于原声景观信号的节奏改变量;
[0040]
粗糙度改变:为声音由于周期性时域波动所引起的主观听感,单位为asper;粗糙度改变为混缩噪声信号相对于原声景观信号的粗糙度改变量;
[0041]
步骤三:对每一个声音信号片段进行主观评价。具体而言,以未加入干扰声源的声景观作为对照组,以加入干扰声源后的声景观作为评价组,将二者进行配对比较。每个声景观播放15秒,播放结束后被试回答问题:“如果对照组声景观品质为原始状态,那么与之相比该声景观品质属于哪个等级?”最终得到每一个采集片段中声景观品质受到影响程度的
评价,包括:无影响、轻微影响和严重影响三个等级;
[0042]
步骤四:基于步骤二和步骤三的数据集,建立决策树分类模型,该步骤进而分为以下步骤;
[0043]4‑
1:读取数据集及数据集预处理;
[0044]4‑
2:训练决策树模型,将数据集中70%的数据作为训练数据,将30%的数据作为测试数据,输入决策树模型进行训练。决策树模型的训练分为以下过程:首先,设第一个结点的训练数据集为d,计算现有特征对该数据集的基尼指数;其次,在所有可能的特征a以及他们所有可能的切分点a中,选择基尼系数最小的特征及其对应的切分点作为最优特征与最优切分点,再次,依最优特征与最优切分点,从现节点生成两个子节点,将训练数据集依特征分配到两个子结点中去;之后,对两个子节点递归地调用上述两个步骤,直至满足停止条件;最终,生成决策树模型。
[0045]4‑
3:数据集中声景观品质的改变程度3个等级分类,将其记为无影响、轻微影响、严重影响。生成后,决策树上的每个节点都标示了分支条件;
[0046]
步骤五:基于步骤四中的得到的决策树分类模型的分支条件,获取指代性指标的不同组合方式与声景观品质受影响程度之间的关系,用于实践中对声景观品质监测,对声景观的受影响程度进行分类识别。
[0047]
下面结合附图和具体实施例对本发明技术方案作进一步详细描述。
[0048]
实施例1:
[0049]
步骤1:所选监测对象为公园声景观。用使用sony pcm
‑
d50型数字录音机进行声音录制。录音机安置在地面以上1.5米的高度上,并且远离明显的噪声源,以获得较为真实并且质量较高的声音信号,采集时长是15s,采样频率为44.1khz。
[0050]
步骤2:把步骤1采集到的声音信号转换为数字信号,将该信号与不同类型、不同声级大小的噪声信号混缩成多个信号,混缩操作在daw软件adobe audition中完成。
[0051]
对指代声景观品质的物理指标进行计算分析,获得所有信号的指标参量:声事件频谱重心方差、声事件频谱重心方差改变、响度、响度改变、尖锐度、尖锐度改变、响度波动、响度波动改变、phi_1、phi_1改变、tau_e改变、节奏改变、粗糙度改变的所有数据,部分数据见表1。
[0052]
表1
[0053][0054][0055]
步骤3:对每一个采集片段的声音信号进行主观评价。具体而言,以未加入干扰声源的声景观作为对照组,以加入干扰声源后的声景观作为评价组,将二者进行配对比较。每个声景观播放15秒,播放结束后被试回答问题:“如果对照组声景观品质为原始状态,那么与之相比该声景观品质属于哪个等级?”最终得到每一个采集片段中声景观品质受到影响程度的评价,包括:无影响、轻微影响和严重影响三个等级。主观评价被试人数为30人。部分数据见表2。表中主观评价等级列,数字1代表无影响;数字2代表轻微影响;数字3代表严重影响。
[0056]
表2
[0057][0058][0059]
步骤4:基于步骤二和步骤三的数据集,建立决策树分类模型,建立决策树分类模型,该步骤进而分为以下几个步骤;
[0060]
4.1:读取数据集及数据集预处理;
[0061]
4.2:训练决策树模型。决策树模型的构建基于cart算法,在构建cart决策树时使用“基尼指数”准则来选择和划分属性;使用max_depth作为剪枝参数;在确定深度时,分别设置1
‑
20不同深度,比较不同深度的拟合效果,选择效果最佳的深度设定为最大深度构建决策树模型;在确定分类效果时,采用准确率作为分类效果评价的参照,其表达式为其中tp指模型将正例预测准确的个数,tn指反例预测准确的个数,p和n分别是正和反的样本数总数。进行模型训练时,将数据集中70%的数据作为训练数据,将30%的数据作为测试数据,输入决策树模型进行训练决策树。模型的训练分为以下过程:首先,设第一个结点的训练数据集为d,计算现有特征对该数据集的基尼指数;其次,在所有可能的特征a以及他们所有可能的切分点a中,选择基尼系数最小的特征及其对应的切分点作为最优特征与最优切分点,再次,依最优特征与最优切分点,从现节点生成两个子节点,将训练数据集依特征分配到两个子结点中去;之后,对两个子节点递归地调用上述两个步骤,直至满足停止条件;最终,生成决策树模型。
[0062]
4.3:数据集中声景观品质的改变程度3个等级分类,将其记为无影响、轻微影响、严重影响。生成后,决策树上的每个节点都标示了分支条件。
[0063]
步骤5:基于步骤四中的得到的决策树分类模型的分支条件,获取指代性指标的不同组合方式与声景观品质受影响程度之间的关系,用于实践中对声景观品质监测,对声景观的受影响程度进行分类识别。这个分支条件可以作为声景观监测指标的限值,所对应的变量被不同的临界值划分,分次进入最终监测模型。具体来说,根据分支条件可以获得这些指代性指标的不同组合方式与声景观品质受影响程度之间的关系。在实际对声景观品质进行监测时可以通过查表,方便地了解声景观品质的变化程度。本实施例中的决策树模型所得到的指代性指标的组合与声景观品质受影响程度之间的关系见表3。对于此场景,仅有指标参量粗糙度改变量起主导性作用。
[0064]
表3
[0065]
影响程度粗糙度改变无影响≤
‑
1.28轻微影响
‑
1.155~
‑
0.93严重影响>
‑
0.93
[0066]
在实施监测时,录制一段长度为15s的声景观信号片段,对该时刻声景观品质进行判断分类:
[0067]
计算这段声景观信号片段的声景观品质指代性指标值粗糙度改变的值为
‑
0.84asper:
[0068]
结合表3给出的指代性指标组合与声景观品质受应巡航程度之间的关系,判断该声景观品质所属分类为严重影响,应当对其采取保护措施。
[0069]
实施例2:
[0070]
步骤1:所选监测对象为意大利风情街声景观。用使用sony pcm
‑
d50型数字录音机进行声音录制。录音机安置在地面以上1.5米的高度上,并且远离明显的噪声源,以获得较为真实并且质量较高的声音信号,采集时长是15s,采样频率为44.1khz。
[0071]
步骤2:把步骤1采集到的声音信号转换为数字信号,将该信号与不同类型、不同声
级大小的噪声信号混缩成多个信号,混缩操作在daw软件adobe audition中完成。
[0072]
对指代声景观品质的物理指标进行计算分析,获得所有信号的指标参量:声事件频谱重心方差、声事件频谱重心方差改变、响度、响度改变、尖锐度、尖锐度改变、响度波动、响度波动改变、phi_1、phi_1改变、tau_e改变、节奏改变、粗糙度改变的所有数据,部分数据见表4。
[0073]
表4
[0074]
录音编号声时间频谱重心方差
……
粗糙度改变151.51
……
0.2278.93
……‑
0.033124.27
……‑
0.234178.93
……‑
0.385197.2
……‑
0.52683.89
……
0.197100.78
……‑
0.068196.06
……‑
0.269228.73
……‑
0.4410208.49
……‑
0.56
[0075]
步骤3:对每一个声音信号片段进行主观评价。具体而言,以未加入干扰声源的声景观作为对照组,以加入干扰声源后的声景观作为评价组,将二者进行配对比较。每个声景观播放15秒,播放结束后被试回答问题:“如果对照组声景观品质为原始状态,那么与之相比该声景观品质属于哪个等级?”最终得到每一个采集片段中声景观品质受到影响程度的评价,包括:无影响、轻微影响和严重影响三个等级。主观评价被试人数为30人。部分数据见表5。表中主观评价等级列,数字1代表无影响;数字2代表轻微影响;数字3代表严重影响。
[0076]
表5
[0077][0078][0079]
步骤4:基于步骤二和步骤三的数据集,建立决策树分类模型,建立决策树分类模型,该步骤进而分为以下几个步骤;
[0080]
4.1:读取数据集及数据集预处理;
[0081]
4.2:训练决策树模型。决策树模型的构建基于cart算法,在构建cart决策树时使用“基尼指数”准则来选择和划分属性;使用max_depth作为剪枝参数;在确定深度时,分别设置1
‑
20不同深度,比较不同深度的拟合效果,选择效果最佳的深度设定为最大深度构建决策树模型;在确定分类效果时,采用准确率作为分类效果评价的参照,其表达式为其中tp指模型将正例预测准确的个数,tn指反例预测准确的个数,p和n分别是正和反的样本数总数。进行模型训练时,将数据集中70%的数据作为训练数据,将30%的数据作为测试数据,输入决策树模型进行训练决策树。模型的训练分为以下过程:首先,设第一个结点的训练数据集为d,计算现有特征对该数据集的基尼指数;其次,在所有可能的特征a以及他们所有可能的切分点a中,选择基尼系数最小的特征及其对应的切分点作为最优特征与最优切分点,再次,依最优特征与最优切分点,从现节点生成两个子节点,将训练数据集依特征分配到两个子结点中去;之后,对两个子节点递归地调用上述两个步骤,直至满足停止条件;最终,生成决策树模型。
[0082]
4.3:数据集中声景观品质的改变程度3个等级分类,将其记为无影响、轻微影响、严重影响。生成后,决策树上的每个节点都标示了分支条件。
[0083]
步骤5:基于步骤四中的得到的决策树分类模型的分支条件,获取指代性指标的不同组合方式与声景观品质受影响程度之间的关系,用于实践中对声景观品质监测,对声景观的受影响程度进行分类识别。这个分支条件可以作为声景观监测指标的限值,所对应的变量被不同的临界值划分,分次进入最终监测模型。具体来说,根据分支条件可以获得这些指代性指标的不同组合方式与声景观品质受影响程度之间的关系。在实际对声景观品质进行监测时可以通过查表,方便地了解声景观品质的变化程度。本实施例中的决策树模型所得到的指代性指标的组合与声景观品质受影响程度之间的关系见表6。对于此场景,指标参量尖锐度改变量和响度起主导性作用。
[0084]
表6
[0085]
影响程度尖锐度改变响度无影响≤
‑
0.165 轻微影响>
‑
0.165≤11.75严重影响>
‑
0.165>11.75
[0086]
在实施监测时,录制一段长度为15s的声景观信号片段,对该时刻声景观品质进行判断分类:
[0087]
计算这段声景观信号片段的声景观品质指代性指标值尖锐度改变、响度的值分别为
‑
0.15acum和10.5sone:
[0088]
结合表6给出的指代性指标组合与声景观品质受应巡航程度之间的关系,判断该声景观品质所属分类为轻微影响,应当考虑对其采取保护措施,缓解其受破坏的程度。
[0089]
尽管上面结合实例对本发明进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨的情况下,还可以做出很多变形,这些均属于本发明的保护之内。
[0090]
以上对本发明做了示例性的描述,应该说明的是,在不脱离本发明的核心的情况
下,任何简单的变形、修改或者其他本领域技术人员能够不花费创造性劳动的等同替换均落入本发明的保护范围。