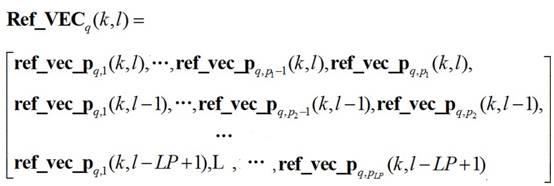
1.本发明属于音频处理技术领域,具体涉及一种回声消除方法。
背景技术:
2.在具有扬声器和麦克风的音频系统中,回声消除技术得到了广泛的应用,随着人工智能技术和物联网在飞速发展落地,实际的应用产品对回声消除的效果、算力、内存提出了更苛刻的要求。
3.一般常用的回声消除方法是通过自适应滤波器对回声通道进行估计,进而消除回声,该类方法的自适应滤波器若涉及求逆运算、非线性抑制往往会增大产品的硬件消耗;同时近年来出现了较多基于深度神经网络的回声消除方法,该类方法可进一步的提升回声消除的效果,对非线性失真、混响、环境噪音等问题上都有一定的处理效果,但考虑多样复杂的应用环境,训练集的筛选是一个挑战,会直接影响实际应用过程中的稳定性,同时基于深度学习的回声消除方法的算力、内存制约着其广泛应用。
技术实现要素:
4.为克服现有技术存在的缺陷,本发明公开了一种回声消除方法。
5.本发明所述回声消除方法,包括如下步骤:s1. 通过麦克风阵列获取模拟麦克风信号和模拟参考信号,将模拟麦克风信号和模拟参考信号转换成数字时域信号,分别获得数字麦克风信号和数字参考信号;其中模拟麦克风信号是扬声器发出后并被麦克风接收后输出的电学信号,模拟参考信号是输入扬声器的电学信号;s2. 采用短时傅里叶变换技术,将数字时域信号形式的数字麦克风信号和数字参考信号分别转换成麦克风频域信号和参考频域信号;s3. 对参考频域信号进行线性预测缓存和非线性扩展得到参考频域信号矩阵,所述参考频域信号矩阵由多个参考频域信号向量组成;对第q个参考通道第l帧第k个频点的参考频域信号向量ref_vec
q
(k,l)的计算过程为:s31.设置线性预测长度lp,进行缓存的第q个参考通道第l帧第k个频点的预测缓存向量ref_vec_pre
q
(k,l)=[ref
q
(k,l), ref
q
(k,l
‑
1),
…
ref
q
(k,l
‑
lp+1)]其中ref
q
(k,l)为第q个参考通道第l帧第k个频点的参考频域信号,其余类推;s32.对预测缓存向量ref_vec_pre
q
(k,l)中存储的参考频域信号进行非线性扩展可得非线性扩展后的参考频域信号向量ref_vec
q
(k,l)为:
p1,p2,
…
p
lp
为非线性扩展的阶数,ref_vec_p
q,p (k,l)表示第q个参考通道第l帧第k个频点的p阶扩展的参考频域信号,其余依此类推;通过奇次幂级数对第q个参考通道第l帧第k个频点的参考频域信号ref
q
(k,l)进行非线性扩展可得,具体为:ref_vec_p
q,p
(k,l)= ref
q
(k,l)
2*p
‑
1 ;其余依此类推;s33.遍历各个帧、频点和参考通道,组合全部参考频域信号向量得到参考频域信号矩阵ref_vec;s4. 计算参考频域信号矩阵ref_vec的自相关对角化矩阵r_ivm;s5. 计算每个频点的回声消除增益向量w,并对步骤s2得到的麦克风频域信号进行回声消除;s51.计算第l帧第n个麦克风通道第k个频点的麦克风频域信号mic
n
(k,l)和第q个通道第l帧第k个频点参考频域信号二者之间的互相关向量r_mic_ref
q
(k,l)s52.多次遍历全部参考频域信号向量ref_vec
q
(k,l),记第j次遍历的非线性扩展参考频域信号向量元素为ref_vec_n
q
(j),每次遍历具体过程为:s521.r_y_ref= y
n,j
‑1(k,l)*conj(ref_vec_n
q
(j));conj表示取共轭,y
n,j
‑1(k,l)为第j
‑
1次遍历第n个麦克风通道第l帧第k个频点残留语音频域信号,r_y_ref为遍历中间变量;j=1时,y
n,j
‑1(k,l) =mic
n
(k,l),s522.则第l帧第k个频点第j次遍历平滑后的互相关信号r_cm
q
(k,l,j)= λ* r_cm
q
(k,l
‑
1,j)+(1
‑
λ)*r_y_ref,λ为平滑因子;r_y_ref为遍历中间变量;s523.第j次遍历中回声消除增益:w(j)= r_cm
q
(k,l,j)/ [r_ivm
q
(k,l,j)+δ],δ为防止分母为零的极小值;其中r_ivm
q
(k,l,j) 为第j次遍历的第q个通道第l帧第k个频点参考频域信号自相关对角化信号,来自步骤s4得到的自相关对角化矩阵r_ivm;s524.进行回声消除处理,将上一次残留语音频域信号的遍历结果y
n,j
‑1(k,l)用于本次的遍历计算过程中,本次遍历过程中计算残留语音频域信号y
n,j
(k,l)为y
n,j
(k,l)= y
n,j
‑1(k,l)
‑
w(j)* ref_vec_n
q
(j);s6.全部遍历次数完成后,输出最后一次遍历得到的最终输出频域信号,转化为时域信号。
[0006]
优选的,所述步骤s4具体为:s41.参考频域信号矩阵ref_vec中第q个参考通道第l帧第k个频点的对角简化矩阵r_ref
q
(k,l)= ref_vec
q
(k,l)* ref_vec
q
(k,l)
h
其中ref_vec
q
(k,l)为第q个参考通道第l帧第k个频点进行非线性扩展后得到的参考频域信号向量,上标h表示共轭转置,*代表点乘;s42.第q个参考通道第l帧第k个频点的参考频域信号自相关对角化向量r_ ivm
q
(k,l)= λ* r_ ivm
q
(k,l) +(1
‑
λ)* r_ ref
q
(k,l);λ为所述平滑因子;s43.遍历各个帧、频点和参考通道,组合全部参考频域信号自相关对角化向量得到自相关对角化矩阵r_ivm。
[0007]
优选的,所述平滑因子λ取值为0.7
‑
0.99。
[0008]
优选的,所述步骤s6,采用短时傅立叶逆变换模块将回声消除处理后的频域信号转化为时域信号。
[0009]
本发明与传统的回声消除方法相比,本发明方案利用快速的回声消除算法,处理后的语音信号信噪比更高,可有效改善回声消除效果。
附图说明
[0010]
图1 为本发明所述回声消除方法的一个具体实现方式流程图;图2 为本发明所述回声消除方法的一个具体流程示意图;图3 为本发明一个具体实施例中回声消除处理前的时域信号波形图;图3(a1)部分信号为麦克风阵列获取的麦克风信号,(a2)部分信号为参考信号;图4 为采用现有技术和本发明对图3中信号进行回声消除处理后得到的波形对比示意图;图4(a3)部分为利用现有技术的回声消除方法处理得到的输出波形,(a4)部分为利用本发明图2所示回声消除装置处理后输出的波形图;图3和图4中横坐标均为时间,纵坐标为电压振幅。
具体实施方式
[0011]
下面对本发明的具体实施方式作进一步的详细说明。
[0012]
本发明所述回声消除方法,包括如下步骤:s1. 通过麦克风阵列获取模拟麦克风信号和模拟参考信号,将模拟麦克风信号和模拟参考信号转换成数字时域信号,分别获得数字麦克风信号和数字参考信号;其中模拟麦克风信号是扬声器发出后并被麦克风接收后输出的电学信号,模拟参考信号是输入扬声器的电学信号;s2. 采用短时傅里叶变换技术,将数字时域信号形式的数字麦克风信号和数字参考信号分别转换成麦克风频域信号和参考频域信号;s3. 对参考频域信号进行线性预测缓存和非线性扩展得到参考频域信号矩阵,所述参考频域信号矩阵由多个参考频域信号向量组成;对第q个参考通道第l帧第k个频点的参考频域信号向量ref_vec
q
(k,l)的计算过程为:s31.设置线性预测长度lp,进行缓存的预测缓存向量ref_vec_pre
q
(k,l)=[ref
q
(k,l), ref
q
(k,l
‑
1),
…
ref
q
(k,l
‑
lp+1)]
其中ref
q
(k,l)为第q个参考通道第l帧第k个频点的参考频域信号,其余类推;s32.对预测缓存向量ref_vec_pre
q
(k,l)中存储的参考频域信号进行非线性扩展可得非线性扩展后的参考频域信号向量ref_vec
q
(k,l)为:p1,p2,
…
p
lp
为非线性扩展的阶数,ref_vec_p
q,p (k,l)表示第q个参考通道第l帧第k个频点的p阶扩展的参考频域信号,其余依此类推;通过奇次幂级数对第q个参考通道第l帧第k个频点的参考频域信号ref
q
(k,l)进行非线性扩展可得,具体为:ref_vec_p
q,p
(k,l)= ref
q
(k,l)
2*p
‑
1 ;其余依此类推;s33.遍历各个帧、频点和参考通道,组合全部参考频域信号向量得到参考频域信号矩阵ref_vec;s4. 计算参考频域信号矩阵ref_vec的自相关对角化矩阵r_ivm;s5. 计算每个频点的回声消除增益向量w,并对步骤s2得到的麦克风频域信号进行回声消除;s51.计算第l帧第n个麦克风通道第k个频点的麦克风频域信号mic
n
(k,l)和第q个通道第l帧第k个频点参考频域信号二者之间的互相关向量r_mic_ref
q
(k,l)s52.多次遍历全部参考频域信号向量ref_vec
q
(k,l),记第j次遍历的非线性扩展参考频域信号向量元素为ref_vec_n
q
(j),每次遍历具体过程为:s521.遍历中间变量r_y_ref= y
n,j
‑1(k,l)*conj(ref_vec_n
q
(j));conj表示取共轭,y
n,j
‑1(k,l)为第j
‑
1次遍历第n个麦克风通道第l帧第k个频点残留语音频域信号,j=1时,y
n,j
‑1(k,l) =mic
n
(k,l),其中ref_vec_n
q
(j)为参考频域信号向量 ref_vec
q
(k,l)的第j个元素;s522.则第l帧第k个频点第j次遍历平滑后的互相关信号r_cm
q
(k,l,j)= λ* r_cm
q
(k,l
‑
1,j)+(1
‑
λ)*r_y_ref,λ为平滑因子;s523.第j次遍历中回声消除增益:w(j)= r_cm
q
(k,l,j)/ [r_ivm
q
(k,l,j)+δ],δ为防止分母为零的极小值;其中r_ivm
q
(k,l,j) 为第j次遍历的第q个通道第l帧第k个频点参考频域信号自相关对角化信号,来自步骤s4得到的自相关对角化矩阵r_ivm;s524.进行回声消除处理,将上一次残留语音频域信号的遍历结果y
n,j
‑1(k,l)用于本次的遍历计算过程中,本次遍历过程中计算残留语音频域信号y
n,j
(k,l)为y
n,j
(k,l)= y
n,j
‑1(k,l)
‑
w(j)* ref_vec_n
q
(j);s6.全部遍历次数完成后,输出最后一次遍历得到的最终输出频域信号,
转化为时域信号。
[0013]
一个具体实施方式,如图1所示,可以包括以下步骤实现:s1.通过麦克风阵列获取模拟麦克风信号和模拟参考信号,然后采用模数转换器adc将模拟麦克风信号和模拟参考信号转换成数字时域信号,获得数字麦克风信号和数字参考信号;其中模拟麦克风信号是扬声器发出后并被麦克风接收后输出的电学信号,模拟参考信号是输入扬声器的电学信号;s2.采用短时傅里叶变换技术,将数字时域信号转换成数字频域信号将s1步骤得到的数字麦克风信号和数字参考信号转换成k个频点的频域信号为对具体实施方式作进一步的详细说明,以最小系统为例,采用单麦克风单扬声器系统进行介绍,此时麦克风数n=1,参考通道数q=1,将当前第l帧数字麦克风信号的麦克风时域信号, 转换成麦克风频域信号;将当前第l帧的参考时域信号转换成参考频域信号;在一个具体实施方式中,采用512点的短时傅里叶变换,则此时频点数k=257,麦克风频域信号的维度为k=;参考频域信号的维度为; s3.对参考频域信号进行线性预测缓存和非线性扩展得到参考频域信号矩阵,所述参考频域信号矩阵由多个参考频域信号向量组成。
[0014]
为方便描述,对第q个参考通道第l帧第k个频点的参考频域信号向量ref_vec
q
(k,l)的计算过程进行详细描述,q值最小为1。
[0015]
由于麦克风采集的扬声器信号和原参考信号存在很强的线性相关性,因此可以采用线性预测的技术去逼近该相关性,而若要实现线性预测的技术需要对过去帧信号进行缓存,为此对第q个参考通道第l帧第k个频点的预测缓存向量ref_vec_pre
q
(k,l)进行缓存,在本具体实施方式中设线性预测长度lp=4可得:ref_vec_pre
q
(k,l)= [ ref
q
(k,l), ref
q
(k,l
‑
1),
…
ref
q
(k,l
‑
4+1)] ;ref
q
(k,l)为第q个参考通道第l帧第k个频点的参考频域信号,其余类推。
[0016]
在实际应用中,尤其是在使用微型扬声器的嵌入式设备中,非线性不可避免,为了减弱系统的非线性失真对回声消除效果的影响,通过奇次幂级数对第q个参考通道第l帧第k个频点参考频域信号进行非线性扩展可得非线性扩展后的参考频域信号ref_vec_p
q,i
(k,l)= ref
q
(k,l)
2*i
‑
1 ,i=1,2
…
m;其中m为扩展的阶数,设非线性扩展阶数的向量p=[2,2,1,1],为兼顾线性预测和非线性扩展的优势,对预测缓存向量ref_vec_pre
q
(k,l)中存储的参考频域信号进行非线性扩展可得非线性扩展后的参考频域信号向量ref_vec
q
(k,l)为:由于p=[2,2,1,1],因此各行从上到下分别进行2阶、2阶、1阶、1阶扩展,ref_vec_p
q,2
(k,l)表示第q个参考通道第l帧第k个频点的2阶扩展的参考频域信号,其余依次类推;
遍历各个帧、频点和参考通道,组合全部参考频域信号向量得到参考频域信号矩阵ref_vec;在本具体实施方式中,则可得ref_vec
q
(k,l)的维度为1*6。
[0017]
s4.计算参考频域信号矩阵ref_vec的自相关对角化矩阵r_ivm。
[0018]
为方便描述,对第q个参考通道第l帧第k个频点的自相关对角化向量r_ivm
q
(k,l)的计算过程进行详细描述。
[0019] 通常在自适应滤波器中会计算参考信号的自相关矩阵,用于分析麦克风信号与参考信号的相关性,因此需要计算第q个参考通道第l帧第k个频点预测缓存向量的自相关矩阵r_ref_vec
q
(k,l),由于向量ref_vec
q
(k,l)的维度为1*6,可计算得到矩阵r_ref_vec
q
(k,l)的维度为1*6*6,当为取得较好的回声消除效果,阶数设置比较大,其对后续的计算将产生巨大的挑战,此时系统所需的内存空间对实际的嵌入式产品而言是极其苛刻的,因此采用对角化序列近似简化矩阵r_ref_vec
q
(k,l),可得到简化后第q个参考通道第l帧第k个频点的对角简化矩阵r_ref
q
(k,l)= ref_vec
q
(k,l)* ref_vec
q
(k,l)
h
其中上标h表示共轭转置,*代表点乘。
[0020]
得到的r_ref
q
(k,l)的维度为1*6,相比较于矩阵r_ref_vec
q
(k,l)的维度为1*6*6,可以发现,采用对角化序列近似的方法可极大减少内存和后续的计算量。
[0021]
由于实际处理过程中参考信号的幅值波动比较大,考虑系统的稳定性,对r_ref
q
(k,l)进行平滑处理可得平滑后的参考频域信号自相关对角化向量r_ivm
q
(k,l)为:r_ ivm
q
(k,l)= λ* r_ ivm
q
(k,l) +(1
‑
λ)* r_ ref
q
(k,l)其中λ为平滑因子,一般取值0.7到0.999,本具体实施方式中取λ=0.99;s5. 计算每个频点的回声消除增益向量w,并对步骤s2得到的麦克风频域信号进行回声消除;s51.计算第l帧第n个麦克风通道第k个频点的麦克风频域信号mic
n
(k,l)和第q个通道第l帧第k个频点参考频域信号二者之间的互相关向量r_mic_ref
q
(k,l), 对单麦克风系统,n=1;s52.多次遍历全部参考频域信号向量ref_vec
q
(k,l),记第j次遍历的非线性扩展参考频域信号向量元素为ref_vec_n
q
(j),每次遍历具体过程为:s521.r_y_ref= y
n,j
‑1(k,l)*conj(ref_vec_n
q
(j));conj表示取共轭,y
n,j
‑1(k,l)为第j
‑
1次遍历第n个麦克风通道第l帧第k个频点残留语音频域信号,j=1时,y
n,j
‑1(k,l) =mic
n
(k,l),其中ref_vec_n
q
(j)为参考频域信号向量 ref_vec
q
(k,l)的第j个元素;s522.则第l帧第k个频点第j次遍历平滑后的互相关信号r_cm
q
(k,l,j)= λ* r_cm
q
(k,l
‑
1,j)+(1
‑
λ)*r_y_ref,λ为所述平滑因子;s523.第j次遍历中回声消除增益:w(j)= r_cm
q
(k,l,j)/ [r_ivm
q
(k,l,j)+δ],δ为防止分母为零的极小值,可取δ=10
‑6;其中r_ivm
q
(k,l,j) 为第j次遍历的第q个通道第l帧第k个频点参考频域信号自
相关对角化信号,来自步骤s4得到的自相关对角化矩阵r_ivm;s524.进行回声消除处理,将上一次残留语音频域信号的遍历结果y
n,j
‑1(k,l)用于本次的遍历计算过程中,本次遍历过程中计算残留语音频域信号y
n,j
(k,l)为y
n,j
(k,l)= y
n,j
‑1(k,l)
‑
w(j)* ref_vec_n
q
(j);s6.全部遍历次数完成后,输出最后一次遍历得到的最终输出频域信号,转化为时域信号。
[0022]
步骤s6中可采用短时傅立叶逆变换模块istft技术,将回声消除处理后的频域信号转化为时域信号,经过回声消除处理后的时域信号可通过系统直接传递给下一个处理模块。
[0023]
与传统的回声消除方法相比,本发明方案利用快速的回声消除算法,可有效改善回声消除效果,图3和图4所示给出本发明一个具体实施例,回声消除处理过程基于图2给出的回声消除装置进行。图3为回声消除处理前的时域信号,(a1)部分信号为麦克风阵列获取的麦克风信号,包括环境噪声、扬声器播放的声音和目标人声,其中目标人声为在距离麦克风3m处通过音响播放的命令词;(a2)部分信号为参考信号,即图2所示音频源输入到扬声器的信号。
[0024]
图4是回声消除处理后得到的波形图,图4中(a4) 部分为利用本发明图1所示回声消除装置处理后输出的波形图;(a3)部分为利用现有技术的基于rls(最小二乘法)的回声消除方法处理得到的输出波形图。由图4可见,本发明处理后的目标语音,即图4上下两波形中出现的多个电压振幅较大部分,与回声残留值即电压振幅较小部分的差别更大,即本发明处理后的语音信号信噪比更高,表明本发明对回声消除效果更好。
[0025]
前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书内容所作的等同结构变化,同理均应包含在本发明的保护范围内。