音频编解码器中的对话增强
1.相关申请的交叉引用
2.本技术要求以下优先权申请的优先权:2019年4月15日提交的美国临时申请62/833,855(编号:d18119usp1)、2019年4月15日提交的欧洲专利申请19169218.5(编号:d18119ep)、和2019年8月5日提交的美国临时申请62/882,722(编号:d18119usp2),这些申请通过引用结合于此。
技术领域
3.本公开涉及音频编码器
‑
解码器(编解码器)系统中的对话增强。
背景技术:
4.对于对话增强功能的支持通常包含在本技术的音频编码/解码系统中。
5.在双端系统中,用于增强对话的信息可以被包含在从编码器传输到解码器的比特流中。该信息通常被称为时变对话增强(de)参数集合,包括每个频带(和每个信道)一个参数。时隙与频带(在一个信道中)一起被称为“时频块(time
‑
frequency tile)”,de参数代表用于每个这样的时频块的时变增益。在解码器侧,de参数可以与用户确定的对话增益一起被应用以提供对话增强信号。
6.然而,此类系统中对话增强的效果可能被认为过于微小,因此需要进行改进处理。
7.在其他领域,已经提出了对话增强,包括均衡化和压缩的组合,参见例如us 2012/0209601。然而,这样的解决方案不能立即适用于音频编解码器系统。
技术实现要素:
8.因此,本公开的一个目的是在音频编解码器系统中提供改进的对话增强。
9.根据本公开,通过对所估计的对话分量进行附加处理,包括压缩(和可选的均衡化),从而能够实现改进的对话增强,可实现该目的和其他目的。本公开的实施例基于可以显著改进音频编解码器系统中的对话增强的实现。此外,在根据本发明的实施例的双端系统中,传统上作为线性增益直接应用于音频信号的对话增强(de)参数被替代地用于估计对话分量,从而允许进行附加处理。
10.根据本发明实施例的第一方面,所估计的对话分量的附加处理在解码器侧执行。
11.更具体地,第一方面涉及一种用于音频信号的对话增强的方法,包括接收包括音频信号的编码比特流,获得被配置为估计存在于所述音频信号中的对话分量的时变参数集合,从所述音频信号估计所述对话分量,仅对所估计的对话分量应用压缩器以生成经处理的对话分量,将用户确定的增益应用于经处理的对话分量以生成增强对话分量,以及将所述增强对话分量与所述音频信号组合以形成对话增强音频信号。
12.第一方面还涉及一种用于音频信号的对话增强的解码器,所述解码器获得了被配置为估计存在于所述音频信号中的对话分量的时变参数集合,所述解码器包括解码器元件,用于解码在编码比特流中接收的音频信号,对话估计器,用于从所述音频信号中估计所
述对话分量,压缩器,用于仅压缩所估计的对话分量以生成经处理的对话分量,增益元素,用于将用户确定的增益应用于经处理的对话分量,以提供增强对话分量,以及组合路径,用于将所述增强对话分量与所述音频信号进行组合以形成对话增强音频信号。
13.在单端系统中,用于估计对话分量的时变参数可以在解码器中确定,甚至可以预先设置。然而,在优选实施方式中,解码器是双端系统的一部分,在这种情况下,参数可以包括在编码比特流中(例如,对应于本领域已知的对话增强(de)参数)。
14.压缩器有利地仅应用于所估计的音频信号的对话分量。有利地,在应用用户确定的增益之前以及在组合增强对话分量与音频信号之前,应用压缩器。在常规解码器中,包括对话和非对话分量的整个音频信号通常可以在处理音频信号期间被提升(boost)。在常规解码器中,限幅器通常可应用于经提升信号以避免经提升信号进入饱和,从而防止经提升信号的削波。在本发明的实施例的第一方面中,压缩器具有不同于例如通常插入在解码器输出端的常规限幅器的用途。根据第一方面的压缩器用于仅增加音频信号的对话分量的平均功率,且保持音频信号的峰值水平不变。用户确定的增益应用于经处理(压缩)的对话分量并与音频信号组合,或者,如下文所述的实施例中的非对话分量,使得对话分量可以在经处理的音频信号中更清晰地突出。因此,根据第一方面,压缩器增加了音频信号的对话分量和非对话分量(例如背景)之间对话增强音频信号的信噪比。因此,根据第一方面的压缩器不用于防止信号的削波。
15.在一个实施例中,对话分量包括具有时变水平的对话。根据第一方面,压缩器可以使对话分量的较响亮部分的音频水平更接近于较安静部分的音频水平。
16.在一个实施例中,压缩器还可以被配置为将补偿增益(make
‑
up gain)应用于经处理(压缩的)对话分量以将经处理的对话分量的水平,例如峰值水平,增加回到所估计的对话分量的水平,例如峰值水平。应用补偿增益导致对话分量的水平整体增加,从而使经压缩的对话分量更加可听。
17.在下面进一步描述的实施例中,可以在解码器的输出端使用限幅器以防止经处理的音频信号被削波。在对话分量已通过简单增益被提升但未被压缩的情况下,限幅器可以显著减少甚至消除对话提升的感知效果。另一方面,通过压缩和提升对话分量,使得对话的平均功率增加,即使在限幅之后仍可以实现对话水平的感知增加。因此,仅对音频信号的对话分量应用压缩器提供了对于输出限幅器在感知上更鲁棒的对话增强系统。
18.可以理解,当在压缩之前也对所估计的对话分量应用均衡化时,对所估计的对话分量进行压缩是指对均衡化后的所估计的对话分量进行压缩。
19.根据本发明的实施例的第二方面,在双端系统的编码器侧执行对所估计的对话分量的附加处理,得到修改的对话增强(de)参数,该参数被编码并包括在比特流中。
20.应指出,虽然压缩是时变非线性操作,但只有增益值的计算是非线性的。计算出的增益值的实际应用实际上是线性运算。静态(时不变)均衡器曲线的应用也是线性的。发明人因此认识到,可替代地,根据本发明的实施例的对话分量的附加处理可以通过将均衡器系数和压缩增益(包括补偿)结合到对话增强(de)参数集合中来在编码器侧实现,生成修改的de参数集合。
21.更具体地,第二方面涉及一种对音频信号进行编码以实现对话增强的方法,包括提供音频信号,提供时变对话增强参数集合,其被配置为估计存在于所述音频信号中的对
话分量,通过将对话增强参数应用于音频信号来估计所估计的对话分量,仅对所估计的对话分量应用压缩器以生成经处理的对话分量,将经处理的对话分量除以所估计的对话分量以确定时变调整增益集合,将对话增强参数与调整增益相组合以提供修改的对话增强参数集合,以及将音频信号和修改的对话增强参数编码于比特流中。
22.第二方面还涉及一种用于对音频信号进行编码以实现对话增强的编码器,包括:对话估计器,用于通过将时变对话增强参数集合应用于音频信号来估计音频信号中存在的对话分量,压缩器,用于压缩所估计的对话分量以生成经处理的对话分量,除法器,用于将经处理的对话分量除以所估计的对话分量,以确定时变调整增益集合,组合器,用于将所述对话增强参数与所述调整增益组合,以提供修改的对话增强参数集合,以及编码器元件,用于将所述音频信号和所述修改的对话增强参数编码于比特流中。
23.参照本发明实施例的第一方面描述的压缩器的有利效果也可通过本发明的各种实施例的第二方面来实现。
24.两个方面(解码器和编码器)提供基本相同的技术效果。
25.第二方面(编码器中的处理)的一个优点是不需要修改解码器。压缩器可以衰减信号的超过给定阈值的部分,例如信号的具有高于给定阈值的峰值或rms水平的部分。压缩比可能约为5∶1甚至高达20∶1。可以应用补偿增益来保持对话信号的原始水平(例如峰值或rms水平)。
26.在双端系统中,编码比特流还可以包括用于配置压缩器的压缩参数。这样的参数可以包括例如阈值、压缩比、启动时间、释放时间和补偿增益。
27.对所估计的对话分量的附加处理优选地包括在应用压缩器之前将第一均衡器应用于所估计的对话分量。这种均衡化可用于进一步增强压缩效果。
28.术语“均衡器”应该被广义地解释并且可以包括例如时域中差分方程的应用。然而,在大多数实际示例中,均衡器是将频率相关(复数)增益应用于所估计的对话信号的元件,但是在某些情况下,实值增益可能就足够了。
29.均衡器可以包括在选定的频率范围内滚降较低频率(例如,低于500hz)并进行小宽幅提升。有关更详细的示例,请参见下文。
30.将增强对话分量与音频信号组合的步骤可以包括通过从音频信号中减去所估计的对话分量而形成所估计的非对话分量(有时被称为“音乐和效果”的m&e),然后将所估计的非对话分量与增强的对话分量相加。
31.在一些实施例中,在将所估计的非对话分量添加到增强对话分量之前,还通过应用第二均衡器对所估计的非对话分量进行均衡化。这样的第二均衡器可以在功能上与第一均衡器相互关联。例如,在所估计的对话被放大的频率区域中,m&e可能会被给予轻微的衰减。更详细的例子可参见实施例的描述。
32.在双端系统中,编码比特流还可以包括用于配置第一均衡器的、以及在存在第二均衡器的情况下配置第二均衡器的控制数据或引导数据。例如,解码器可以具有一组不同的均衡器预设,并且比特流中的控制数据可以选择应用哪个预设。
附图说明
33.将参考附图更详细地描述本发明的实施例。
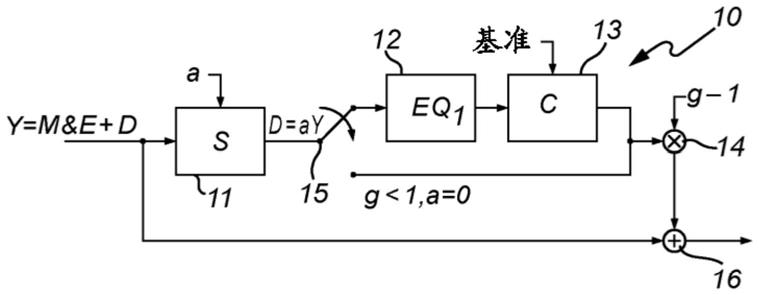
34.图1是根据本发明的实施例的解码器的框图。
35.图2是根据本发明的第二实施例的解码器的框图。
36.图3是根据本发明的实施例的编码器的一部分的框图。
37.图4是适合与图3中的编码器解决方案一起使用的解码器。
38.图5是图2中解码器的更详细实现的框图。
39.图6是示出根据本发明的一个实施例的图5中的对话增强组件的框图。
40.图7a和7b是示出了根据本发明的另一实施例的图5中的对话增强组件的两个示例的框图。
41.图8是示出根据本发明的又一实施例的图5中的对话增强组件的框图。
42.图9a和9b是图2中均衡器的均衡化功能的两个示例。
43.图10a示意性地示出了根据常规方法的对话增强的示例。
44.图10b示意性地示出了根据本发明的实施例的对话增强的示例。
45.图10c示意性地示出了根据本发明的另一实施例的对话增强的示例。
具体实施方式
46.下面公开的系统和方法可以实现为软件、固件、硬件或其组合。在硬件实现中,任务的划分不一定对应物理单元的划分;相反,一个物理组件可以具有多种功能,一个任务可以由多个物理组件协同完成。某些组件或所有组件可以实现为由数字信号处理器或微处理器执行的软件,或者实现为硬件或专用集成电路。这种软件可以分布在计算机可读介质上,计算机可读介质可以包括计算机存储介质(或非暂时性介质)和通信介质(或暂时性介质)。如本领域技术人员公知的,术语计算机存储介质包括以任何方法或技术实现的易失性和非易失性、可拆装和不可拆装介质,用于存储诸如计算机可读指令、数据结构、程序模块或其他数据的信息。计算机存储介质包括但不限于ram、rom、eeprom、闪存或其他存储技术、cd
‑
rom、数字多功能磁盘(dvd)或其他光盘存储、磁盒、磁带、磁盘存储设备或其他磁存储设备,或任何其他可用于存储所需的信息并且可以通过计算机访问的介质。此外,如本领域技术人员公知的,通信媒体通常在调制数据信号(例如载波或其他传输机制)中体现计算机可读指令、数据结构、程序模块或其他数据,并且包括任何信息传递媒体。
47.以下描述涉及双端编解码器系统中的各种解码器和编码器实施例。注意,本发明的实施例也可以在单端解码器中实现。在这样的实施例中,用于估计对话分量的时变参数a将不会在比特流中被接收,而是由解码器基于所接收的音频信号y被确定。
48.解码端实现
49.图1中的解码器10包括对话估计块11,其从比特流接收输入音频信号y以及时间相关对话增强(de)参数集合a。尽管未在图1中示出,音频信号y和参数集合a均从编码比特流中解码。参数a包括用于一组频带中的每一个的参数(当然也包括用于每个对话承载信道的参数)。时间相关性的分辨率通常由比特流的帧率确定,帧(m)和频带(k)的特定组合被称为时频块。根据这一术语,de参数包括用于每个时频块的一个或多个参数a(m,k)。应指出,de参数通常具有比音频信号更粗糙的频率分辨率,并且一个de频带可以包括音频信号的数个频率区段。de参数使对话估计块11能够根据d(m,k)=a(m,k)y(m,k)估计存在于音频信号y中的对话分量d。对于其他细节,可参考wo2017/132396,其通过引用并入此。
50.解码器还包括对话处理路径,在本实施例中该对话处理路径包括串联连接的第一均衡器12和压缩器13。压缩器13的输出连接到放大器14,其执行乘以因子g
‑
1,其中g是用户确定的线性增益。
51.用户确定的增益g一般可以表示应用的对话增益的程度。例如,用户可以将增益g设置为用户感到满意的水平,然后将其保持在该水平。如果用户觉得对话分量的水平太安静,用户可以通过增加增益g来提高水平。同样,如果用户觉得对话分量的水平太响,用户可以通过降低增益g来降低水平。然而,在大多数实际情况下,用户可能更喜欢更响亮的对话分量,并且增益通常可以设置为等于或大于1的值。
52.在均衡器12的上游布置了开关15,在该实施例中,开关15被配置为仅在满足两个条件时将所估计的对话信号d连接到处理路径(压缩器13和可选的均衡器12):
53.1)用户选择的增益因子g大于1,并且
54.2)时频块的对话增强参数a非零,即存在对话。
55.如果不满足这些条件中的任何一个,则所估计的对话分量d直接连接到乘法器14而无需任何处理。开关的其他设置也是可能的,例如不需要第二个条件。
56.最后,解码器包括求和点16,其被配置为将乘法器14的输出与输入音频信号y相加。
57.在使用中,当g>1时,图1中的均衡器将处理所估计的对话分量d(进行压缩和可选的均衡化),然后将其乘以g
‑
1,最后将其与原始音频信号y相加。当g≤1时,编码器将所估计的对话分量d(未经处理)乘以因子g
‑
1,并将其与原始音频信号y相加。应指出,后一种情况对应于衰减对话,因为因子g
‑
1将小于零。在这种情况下,点16中的求和将是减法。
58.图2示出了更详尽的实施例。这里,解码器20附加地还包括减法点21,其被配置为从输入音频信号y中减去所估计的对话d,从而形成所估计的“非对话”分量,常常称为m&e(音乐和效果)。图2中的解码器还包括具有第二均衡器22的处理路径,其输出连接到求和点24。第二均衡器22之前有第二开关23,在该实施例中,该第二开关23再次被配置为仅当满足两个条件时才将m&e信号提供给第二均衡器22:
59.1)用户选择的增益因子g大于1,并且
60.2)对于时频块,对话增强参数a(m,k)不为零,即存在对话。
61.在图2中,求和点24被连接以将来自均衡器22的经处理的m&e或直接来自开关23的未处理的m&e相加。求和的结果是对话增强音频信号。
62.图1和2中的均衡器12、22通常被配置为将频率相关的(复数)增益应用于输入信号(即,所估计的对话信号或m&e信号)。第一和第二均衡器12、22可以在功能上相互关联,例如从某种意义上说,当第一均衡器的增益函数提升时,第二均衡器的增益函数具有相应的(但通常更窄带)削减。这在图9a、9b中示出,例如均衡器增益函数eq1和eq2。此处的第一增益函数eq1在400hz左右以下有滚降(roll off),在3khz左右有一个轻微的谷值(即衰减),在5khz和10khz左右达到峰值。第二增益函数eq2在5khz和10khz附近有相应的削减。需要注意的是,这些增益函数只是示例,并且增益函数的细节将取决于实际应用和所希望的效果。
63.图1和图2中的压缩器13可以是具有诸如阈值、压缩比、启动(attack)时间、释放(release)时间和补偿增益等参数的单频带压缩器。压缩参数可以从比特流中解码,并且对于每一帧可能不同。例如,压缩比可以是5∶1、10∶1或20∶1。启动可能是10毫秒,释放可能是
250毫秒,相对阈值可能是
‑
6db,补充增益可能是10db。可以相对于长期或短期基准响度水平来设置阈值(即,要设置的压缩下限)。例如,它可以相对于对话归一化值来设置,该值可以是音频信号中平均对话响度的指示。对话归一化值可能基于附加信息针对局部偏差进行调整,附加信息也可以在比特流中提供。
64.作为矩阵乘法的实现
65.应指出,图1和2中的框图是解码器功能的示意性表示。一个更实际的实现通常将被实现为矩阵乘法z=h
·
y,其中y是输入音频信号,h是输入
‑
输出矩阵形式的传递函数,并且z是对话增强输出信号。
66.考虑正交镜像滤波器(qmf)域中的对话增强,输入音频信号y≡y(m,k),其中m是时隙索引,k是频带索引,以及所估计的对话分量(对于特定的时频块)是d=ay,其中a(m,k)可以在比特流更新之间被插值。进一步,令代表所有k的d的瞬时包络值。然后,如果a>0且g>1,对话增强输出z由下式给出:
67.z=g
·
c[eq1(d)]+eq2(m&e)
[0068]
z=g
·
c[q1·
d]+q2·
m&e
[0069]
z=g
·
f
·
q1·
d+q2·
m&e,
[0070]
其中q1和q2是eq系数,f是压缩增益,其是的包络值的函数。
[0071]
给定
[0072]
d=a
·
y,
[0073]
m&e=(1
‑
a)
·
y,
[0074]
输出z可以写为
[0075]
z=g
·
f
·
q1·
a
·
y+q2·
(1
‑
a)
·
y
[0076]
z=[g
·
f
·
q1·
a+q2·
(1
‑
a)]
·
y
[0077]
z=[(g
·
f
·
q1‑
q2)
·
a+q2]
·
y,
[0078]
或简单地为
[0079]
z=h
de_on
·
y
[0080]
其中h
de_on
=(g
·
f
·
q1‑
q2)
·
a+q2是根据本发明实施例的对话增强的完整传递函数。因此,在实际实现中,静态eq曲线的系数可以存储在查找表中,并且在将h可被应用于y之前,只需从计算压缩增益f。
[0081]
在多通道设置中,通过分别计算每个通道的增益并将最小增益取作所有通道的公共增益,以类似的方式获得压缩增益f。这等同于分别计算每个通道的瞬时包络值并从最大的包络值推导出增益。
[0082]
在所估计的对话d的附加处理被关闭的情况下(g<1),则f=q1=q2=1并且输出z变为
[0083]
z=[(g
‑
1)
·
a+1]
·
y,
[0084]
或者等同地,
[0085]
z=h
de_off
·
y
[0086]
其中,h
de_off
=(g
‑
1)
·
a+1。
[0087]
d和/或具有额外缓冲器的需求可通过如下地计算包络来消除:
[0088][0089]
其中a(m,k)再次可以在比特流更新之间被插值。
[0090]
编码器侧实现
[0091]
参考图2描述的方法也可以应用于编码器侧,如图3所示。
[0092]
双端系统的编码器包括用于计算时变对话增强参数集合a的数字处理电路(未示出),这些参数将包含在比特流中,以便解码器能够从音频信号估计对话分量。
[0093]
图3示出了编码器的一部分,包括对话估计块31(类似于上面的对话估计块11),其用于使用先前在编码器中计算的参数a来估计存在于音频信号y中的对话分量d。编码器还包括具有均衡器32和压缩器33的处理路径,其接收所估计的对话分量d并将处理结果提供给乘法器34。编码器还包括x
‑1反相器35,其接收所估计的对话分量d并输出反相对话分量d
‑1,其被提供给乘法器34。乘法器的输出连接到第二乘法器36,该第二乘法器也接收对话增强参数a。
[0094]
在使用中,乘法器34将接收经处理的对话分量并将其乘以1/d,即它将提供经处理的对话分量与所估计的对话分量之间的比率r。比率r通常特定于一个时频块。因此,比率r表示针对特定时频块处理路径32、33关于所估计的对话分量的贡献。对于每个时频块,乘法器36将de参数a与比率r相乘并输出修改的de参数b。修改后的de参数b的完整集合然后与音频信号一起编码于比特流中。
[0095]
当在编码器侧实现本发明的实施例时(如图3所示),它向后兼容现有解码器,例如图4中所示的解码器。通过将接收信号y乘以修改后的de参数b的集合,解码器能够再现从图3中编码器的压缩器33输出的经处理的对话信号。当这样的经处理的对话信号按g
‑
1缩放然后加回到y中时,如图4的解码器所示,即使在现有解码器中仍有可能产生改进的对话增强信号。
[0096]
实际实现
[0097]
图5示意性地图示了如何在现有解码器拓扑中实现根据本发明的实际实施例的对话增强。如图5所示,解码器50通常包括用于对接收的比特流进行解码的核心解码器51,可选的变换52例如双耳变换t、包括矩阵变换53和反馈延迟网络(fdn)块54的可选的后期混响处理路径。编码器还包括对话增强(de)块55,向两个求和点56、57(对应于图2中的两个求和点21、24)提供输出。最后,解码器50包括提供例如音量控制的后处理块58、和限幅器59。
[0098]
图6示出了图5中的对话增强块55针对立体声音频的特定情况的示例。块55包括使用变换a
core
来估计对话分量的对话估计块61(对应于图1和2中的块11),还包括用于提供所估计对话的均衡化和压缩的处理块62。在没有对m&e信号应用均衡化的情况下,块62中的变换等同于f(m)
·
q1(k),并且q2(k)=1。乘法点64(对应于图1和2中的乘法器14)将经处理后的对话与用户确定的增益g相乘。
[0099]
在所示的实施例中,块62中的压缩被设置有侧链63,侧链63基于所估计的对话信号计算适当的压缩器增益。应指出,块62中的均衡化也可以被提供到侧链分支的上游,使得侧链63的输入也经受均衡化。另一选项是在侧链63中应用单独的均衡器。该均衡器然后可
以与块62中的均衡器不同。
[0100]
对于立体声音频,并使用qmf组符号,从loro y(m,k)=[y1(m,k)y2(m,k)]
t
(索引“1”代表立体声通道对中的左声道和索引“2”代表立体声通道对中的右声道)到对话增强的loro z(m,k)=[z1(m,k)z2(m,k)]
t
的映射可以表达为
[0101]
z(m,k)=h
de_on
(m,k)
·
y(m,k)
[0102]
其中m是时隙索引,k是频带索引,并且
[0103]
h
de_on
=[g
·
f(m)
·
q1(k)
·
i2‑
q2(k)
·
i2]
·
a
core
(m,k)+q2(k)
·
i2[0104]
这里,
[0105]
‑
a
core
是一个2
×
2矩阵,它从loro完全主要估计loro对话。通常,a
core
划分为八个频带,并在标称帧速率下每2048个样本发生的比特流更新之间被插值。
[0106]
‑
g是确定对话提升量的用户增益。它可能因帧而异,并且可能需要帧之间插值。
[0107]
‑
f(m)是对于每个时隙m计算的压缩器增益。增益是宽带。因此,不依赖于k。此外,对于每个通道通常使用相同的压缩器增益。因此,f(m)是标量。
[0108]
‑
q1(k)是应用于对话信号的时不变eq曲线。
[0109]
‑
q2(k)是应用于音乐和效果信号的时不变eq曲线。
[0110]
‑
i2是一个2
×
2单位矩阵。
[0111]
5.1环绕声情况容易从立体声情况得出。唯一的区别在于,根据本发明的实施例的对话增强仅处理三个前向通道l/r/c(左/右/中)。与前面描述的双通道示例类似,通常对于三个前向通道中的每一个使用相同的压缩器增益。在图6中,块61中的变换“acore”现在是一个3
×
3(对角线)矩阵,其中相应的de参数作为其元素,并且其仅应用于5.1环绕信号的三个前向通道以估计对话信号。
[0112]
图7a示出了用于可替代的立体声实现的对话增强块55
′
的另一个例子,这里包括双耳变换52。关于双耳变换的细节,参见wo2017/035281和wo2017/035163,两者均通过引用方式并入此。
[0113]
在图中,有三个不同的对话估计块71、72和73,它们代表变换a的不同模式(也称为“配置”),标记为a
cfgo
、a
cfgi
和a
cfg2
(详情参见wo2017/132396,通过引用并入此)。应指出,a
cfg2
等同于图6中的a
core
。块62和63类似于图6中的那些块。
[0114]
在这个替代立体声实现中,再次使用qmf组符号,从loro y(m,k)=[y1(m,k)y2(m,k)]t到对话增强的lara(双耳)z(m,k)=[z1(m,k)z2(m,k)]
t
的映射可以表达为
[0115]
z(m,k)=h
de_on
(m,k)
·
y(m,k)
[0116]
这里,
[0117]
h
de_on
=g
·
f(m)
·
q1(k)
·
a
cfgx
(m,k)+q2(k)
·
t(m,k)
·
[i2‑
a
cfg2
(m,k)]
[0118]
‑
t是一个2
×
2矩阵,可将立体声信号转换为双耳信号。t在标称帧速率下每4096个样本发生的比特流更新之间被插值。
[0119]
‑
a
cfgx
是一个2
×
2矩阵,其从loro完全主要估计对话,其中x表示模式(配置)。一些模式包括双耳变换。应指出,在图7a中a
cfg2
=a
core
用于生成m&e信号。
[0120]
作为替代,图7a中的对话增强55
′
可以在立体声信号转换为双耳信号之后(即在块52之后)应用。这在图7b中公开,其中类似的元件被赋予与图7a中相同的附图标记。应指出,在图示的情况下,a
cfg0
用于生成(双耳)m&e信号。
[0121]
仅当比特流中存在对话的双耳版本时,从立体声信号中减去所估计的对话才有意义。减法过程可以以降低性能为代价被省略。如果省略减法,则用户增益g的解释会发生变化。在这种情况下,用户增益等于0意味着没有对话增强,而用户增益等于1会产生6
‑
db的提升。g的负值将导致衰减,但由于对话增强后的对话与立体声信号中的对话不同,衰减不佳是可以预料到的,因此输出的对话增强信号会遭受失真。
[0122]
在又一个实施例中,对话增强55”可以在对话增强立体声信号转换成双耳信号之前被应用,如图8所示,其中类似的元件再次被赋予与图7a中相同的附图标记。在这种情况下,上述配置(cfg1、cfg2、cfg3)是多余的,只需要核心配置(a
core
)(块73)。实际上,该变型对应于1)具有对话增强功能55”、56、57的立体声解码器和2)双耳变换52的级联。
[0123]
淡入淡出
[0124]
在一些实施例中,解码器可以被配置为在常规对话增强(即,没有对话的压缩和均衡化)和根据本发明的对话增强之间切换。这种切换可以基于例如比特流中的引导数据。为简单起见,常规对话增强在这里缩写为de,而根据本发明的对话增强被称为ade(“先进”对话增强)。在de和ade之间切换可能会导致响度的可听跳跃,这可能会降低用户体验。
[0125]
为了减轻在被应用的对话增强中这种不连续的听觉效果,解码器可以包括过渡机制。过渡机制可以是淡入淡出,广泛用于无缝切换。一般来说,淡入淡出指的是输出在给定的时间段内从第一信号a逐渐切换到第二信号b。其可以表达为:
[0126]
cross_fade_output=f_smooth x a+(1
‑
f_smooth)x b,
[0127]
其中f_smooth是一个加权因子,其在输出从a切换到b的情况下从1斜降到0,当输出从b切换到a时从0斜升到1。
[0128]
在当前情况下,权重因子可以由以下函数定义,其在ade开启(on)时(ade
switch
=1)产生从0到1的斜坡,而在这种对话增强关闭(off)时产生从1到0的反向斜坡(ade
switch
=0)。
[0129][0130][0131]
斜坡的持续时间由时间常数τ确定。时间常数可以是一个或数个解码器处理帧。在给定的示例中,斜坡是线性的,但它可以是在时间τ内在0和1之间平滑过渡的任何函数。例如,它可以是对数、二次或余弦函数。
[0132]
图10a和10b示意性地图示了根据常规方法(图10a)和根据本发明的实施例(图10b)的沉浸式立体声系统中的对话增强。应指出,图10b基本上对应于上面讨论的图7a。然而,均衡器和压缩器级在这里被示出为在ade增益计算块105中计算的增益的应用。
[0133]
应指出,沉浸式立体声系统被用作示例,淡入淡出的原理也可以在其他在de和ade之间切换的应用中实现。
[0134]
在这两种情况下,处理输入的loro立体声信号以提供对话增强的沉浸lara信号。在图10a中,矩阵m
de
应用于loro信号,而在图10b中,矩阵m
ade
应用于loro信号。最后,fdn(反
馈延迟网络)100接收fdn馈送信号并生成fdn信号,该信号被混合以获得具有增强对话的最终耳机输出lbrb。
[0135]
从图10a并使用前文使用的符号,可以得出:
[0136]
m
de
=t+(g
‑
1)x a
cfgx
,
[0137]
其中t在块101中被应用,a
cfgx
在块102中被应用,并且适当的增益(g
‑
1)在乘法点103中被应用。
[0138]
从图10b并再次使用前文使用的符号,可以得出:
[0139]
m
ade
=tx(i2‑
a
cfg2
)+g x a
cfgx x ade_gain,
[0140]
其中t和a
cfgx
分别再次在块101和102中被应用,a
cfg2
在块104中被应用,ade_gain在块105中被计算,在乘法点106中受增益g影响,最后应用于乘法点103。
[0141]
应指出,在cqmf域实现对话增强时,m
ade
和m
de
都是时隙和cqmf
‑
频带变化2
×
2矩阵,loro和lara都是时隙和cqmf
‑
频带变化2
×
1矩阵(列向量)。如上所述,l2是一个2
×
2单位矩阵。
[0142]
淡入淡出的lara信号,即图10a中的lara信号和图10b中的lara信号的淡入淡出,可以通过根据下式将上文定义的加权函数f_smooth直接应用于矩阵m
ade
和m
de
来实现:
[0143]
lara
cross
‑
fade
=(m
ade x f_smooth+m
de x(1
‑
f_smooth))x loro
[0144]
图10c是将其示出为基于图10a和10b的示图的框图的示意图。
[0145]
在图10c中,权重f_smooth被应用于块104的输出,这样图10b中对话的减法随着f_smooth接近1而淡入。此外,权重f_smooth被应用到乘法点106并且权重(1
‑
f_smooth)被应用到增益(g
‑
1)。在连接到乘法点103之前,这两个加权增益然后在求和点107中求和。这意味着,对于f_smooth=0,乘法点103将接收与图10a相同的输入,而对于f_smooth=1,乘法点103将接收与图1b相同的输入。
[0146]
概述
[0147]
在整个说明书中对“一个实施例”、“一些实施例”或“实施例”的引用意味着结合实施例描述的特定特征、结构或特性被包括在本发明的至少一个实施例中。因此,在本说明书的各个地方出现的短语“在一个实施例中”、“在一些实施例中”或“在实施例中”不一定都指代相同的实施例。此外,在一个或多个实施例中,特定特征、结构或特性可以以任何合适的方式组合,如本领域普通技术人员从本公开中显而易见的。
[0148]
如本文所用,除非另有说明,使用序数形容词“第一”、“第二”、“第三”等描述共同的对象仅表明所指的是相似对象的不同实例,而不是意在暗示如此描述的对象必须在时间上、空间上、排名上或以任何其他方式处于给定的序列中。
[0149]
在下面的权利要求和本文的描述中,术语包括、由
…
组成或其包括中的任何一个术语是开放术语,意思是至少包括在后的元素/特征,但不排除其他元素/特征。因此,当在权利要求中使用时,术语包括不应被解释为局限于其后列出的手段或元件或步骤。例如,设备包括a和b这一表述的范围不应限于设备仅由元件a和b组成。本文所用的术语包含或其包含在内的任何一个也是开放术语,其也意味着至少包含该术语之后的元素/特征,但不排除其他元素/特征。因此,包含是同义词,意思是包括。
[0150]
如本文所用,术语“示例性”在提供示例的意义上使用,而不是指示质量。也就是说,“示例性实施例”是作为示例提供的实施例,而不是必然是示例性质量的实施例。
[0151]
应当理解,在本发明的示例性实施例的以上描述中,为了简化公开并帮助理解各种创造性方面中的一个或多个,各种特征有时被分组到单个实施例、附图或其描述中。然而,这种公开方法不应被解释为反映权利要求需要比其中明确记载的特征更多的特征的意图。相反,如以下权利要求所反映的,创造性方面在于少于单个前述公开的实施例的所有特征。因此,具体实施方式之后的权利要求特此明确并入该具体实施方式中,每个权利要求独立作为本发明的单独实施例。
[0152]
此外,虽然本文描述的一些实施例包括在其他实施例中包括的一些而非其他特征,但是如本领域技术人员将理解的,不同实施例的特征的组合形成不同的实施例。例如,在以下权利要求中,任何要求保护的实施例可被以任何组合使用。
[0153]
此外,一些实施例在本文中被描述为可以由计算机系统的处理器或由执行该功能的其他手段来实现的方法或方法的元素的组合。因此,具有用于执行这样的方法或方法的元素的必要指令的处理器形成了用于执行该方法或方法的元素的装置。此外,在此描述的设备实施例的元素是为了实施本发明的各种实施例的目的而执行由该元素执行的功能的手段的示例。
[0154]
在此处提供的描述中,阐述了许多具体细节。然而,应当理解,可以在没有这些具体细节的情况下实践本发明的实施例。在其他情况下,为了不混淆对本描述的理解,没有详细示出公知的方法、结构和技术。
[0155]
类似地,应当注意,当在权利要求中使用时,术语耦合不应被解释为仅限于直接连接。可以使用术语“耦合”和“连接”及其衍生词。应当理解,这些术语并非旨在作为彼此的同义词。因此,表述“设备a耦合到设备b”的范围不应限于其中设备a的输出直接连接到设备b的输入的设备或系统。这意味着在a的输出和b的输入之间的路径可以是包括其他设备或装置的路径。“耦合”可能意味着两个或多个元件直接物理或电接触,或者两个或多个元件彼此不直接接触但仍彼此协作或相互作用。
[0156]
因此,虽然已经描述了本发明的特定实施例,但是本领域技术人员将认识到可以对其进行其他和进一步的修改。例如,上面给出的任何公式仅仅是可以使用的程序的代表。可以从框图中添加或删除功能,并且操作可以在功能块之间互换。在本发明实施例的范围内,对于描述的方法可以增加或删除步骤。
[0157]
例如,实现本发明的解码器可以包括与图5所示的处理块不同的处理块。
[0158]
本发明的实施例涉及以下列举的示例性实施例(eee)。
[0159]
eee 1.一种用于音频信号的对话增强方法,包括:
[0160]
接收包括音频信号的编码比特流,
[0161]
获得被配置为估计存在于所述音频信号中的对话分量的时变参数集合,
[0162]
从所述音频信号估计所述对话分量,
[0163]
仅对所估计的对话分量应用压缩器,以生成经处理的对话分量,
[0164]
将用户确定的增益应用于经处理的对话分量,以提供增强对话分量,以及
[0165]
将所述增强对话分量与所述音频信号组合以形成对话增强音频信号。
[0166]
eee 2.如eee 1所述的方法,还包括在应用所述压缩器之前将第一均衡器应用于所估计的对话分量。
[0167]
eee 3.如eee 1或2所述的方法,其中将增强对话分量与音频信号组合的步骤包括
通过从音频信号中减去对话分量以形成非对话分量,并将所述非对话分量与所述增强对话分量相加。
[0168]
eee 4.如eee 3所述的方法,还包括在将所述非对话分量与所述增强对话分量相加之前将第二均衡器应用于所述非对话分量。
[0169]
eee 5.如eee 4所述的方法,其中所述第二均衡器在功能上与第一均衡器互相关联。
[0170]
eee 6.如前述eee中任一项所述的方法,其中所述时变参数集合包括用于一组频带中的每一个频带的一个参数。
[0171]
eee 7.如前述eee中任一项所述的方法,其中编码比特流包括所述时变参数。
[0172]
eee 8.如eee 7所述的方法,其中编码比特流还包括用于配置压缩器的压缩参数。
[0173]
eee 9.如eee 7或8所述的方法,其中编码比特流还包括用于配置所述第一均衡器的、以及在第二均衡器存在的情况下配置所述第二均衡器的引导数据。
[0174]
eee 10.如前述eee中任一项所述的方法,还包括应用淡入淡出以激活将增强对话分量与音频信号组合的步骤,并且在适用时激活从音频信号中减去所估计的对话的步骤。
[0175]
eee 11.一种对音频信号进行编码以实现对话增强的方法,包括:
[0176]
提供音频信号,
[0177]
提供时变对话增强参数集合,被配置为估计存在于所述音频信号中的对话分量,
[0178]
通过将对话增强参数应用于音频信号来估计所估计的对话分量,
[0179]
对所估计的对话分量应用压缩器,以生成经处理的对话分量,
[0180]
将所述经处理的对话分量除以所估计的对话分量,以确定时变调整增益集合,
[0181]
将所述对话增强参数与所述调整增益相组合,以提供修改的对话增强参数集合,以及
[0182]
将所述音频信号和所述修改的对话增强参数编码于比特流中。
[0183]
eee 12.如eee 11所述的方法,还包括在应用压缩器之前将均衡器应用于所估计的对话分量。
[0184]
eee 13.如eee 11或12之一所述的方法,其中所述时变参数集合包括用于一组频带中的每一个频带的一个参数。
[0185]
eee 14.一种用于音频信号的对话增强的解码器,所述解码器获得了被配置为估计存在于所述音频信号中的对话分量的时变参数集合,所述解码器包括:
[0186]
解码器元件,用于解码在编码比特流中接收的音频信号,
[0187]
对话估计器,用于从所述音频信号中估计所述对话分量,
[0188]
压缩器,用于压缩所估计的对话分量以生成经处理的对话分量,
[0189]
增益元素,用于将用户确定的增益应用于经处理的对话分量,以提供增强对话分量,以及
[0190]
组合路径,用于将所述增强对话分量与所述音频信号进行组合以形成对话增强音频信号。
[0191]
eee 15.如eee 14所述的解码器,还包括第一均衡器,其用于在应用压缩器之前均衡化所估计的对话分量。
[0192]
eee 16.如eee 14或eee 15所述的解码器,其中,所述组合路径包括用于从音频信
号中减去对话分量以形成非对话分量的减法器,以及用于将所述非对话分量与所述增强对话分量相加的求和点。
[0193]
eee 17.如eee 16所述的解码器,还包括第二均衡器,其用于在将非对话分量与所述增强对话分量相加之前对非对话分量进行均衡化。
[0194]
eee 18.如eee 17所述的解码器,其中所述第二均衡器在功能上与所述第一均衡器相互关联。
[0195]
eee 19.如eee 14
‑
18之一所述的解码器,其中,所述编码比特流包括时变参数,并且其中,所述解码器元件被配置为对所述时变参数进行解码。
[0196]
eee 20.如eee 19所述的解码器,其中,所述编码比特流包括用于配置所述压缩器的压缩参数。
[0197]
eee 21.如eee 19或eee 20所述的解码器,其中所述编码比特流包括用于配置所述第一均衡器的、以及在第二均衡器存在的话配置所述第二均衡器的引导数据。
[0198]
eee 22.一种用于对音频信号进行编码以实现对话增强的编码器,包括:
[0199]
对话估计器,用于通过将时变对话增强参数集合应用于音频信号来估计音频信号中存在的对话分量,
[0200]
压缩器,用于压缩所估计的对话分量以生成经处理的对话分量,
[0201]
除法器,用于将所述经处理的对话分量除以所估计的对话分量,以确定时变调整增益集合,
[0202]
组合器,用于将所述对话增强参数与所述调整增益组合,以提供修改的对话增强参数集合,以及
[0203]
编码器元件,用于将所述音频信号和所述修改的对话增强参数编码于比特流中。
[0204]
eee 23.如eee 22所述的编码器,还包括用于在应用压缩器之前均衡化所估计的对话分量的均衡器。
[0205]
eee 24.一种计算机程序产品,包括计算机代码部分,所述计算机代码部分被配置为当在一个或多个处理器上执行时使处理器执行如eee 1到eee 10中任一项所述的方法。
[0206]
eee 25.一种非暂态存储介质,存储如eee 24所述的计算机程序产品。
[0207]
eee 26.一种计算机程序产品,包括计算机代码部分,所述计算机代码部分被配置为当在一个或多个处理器上执行时使处理器执行如eee 11到eee 13中任一项所述的方法。
[0208]
eee 27.一种非暂态存储介质,存储如eee 26所述的计算机程序产品。